CNN 등장배경
일반 DNN은 기본적으로 1차원 형태의 데이터를 사용한다. 따라서 이미지가 입력될 경우, 이것을 flatten 시켜서 한줄의 데이터로 만들게 된다. 이 과정에서 이미지의 공간적 정보가 손실되어, 특징 추출과 학습이 비효율적이고 정확도의 한계가 발생한다는 문제가 있었다. 그래서 CNN(Convolutional Neural Network)을 통해 이미지를 raw input으로 받음으로써, 공간적/지역적 정보를 그대로 유지한채 특성들의 계층을 빌드업하게 된다.
CNN 작동원리

예를 들어 위 그림처럼, 2차원 이미지를 행렬로 표현할 수 있다. 그리고 CNN에는 필터(커널)이 존재하는데, 오른쪽에 표현된 것처럼 3x3크기의 필터가 있다고 생각한다. 이 필터를 이미지의 입력값에 전체적으로 훑어주면서 이미지의 패턴을 찾아 처리할 수 있다.
이때 훑어준다는 것은 연산처리를 해준다는 것이고, matrix와 matrix간의 inner product를 진행한다.
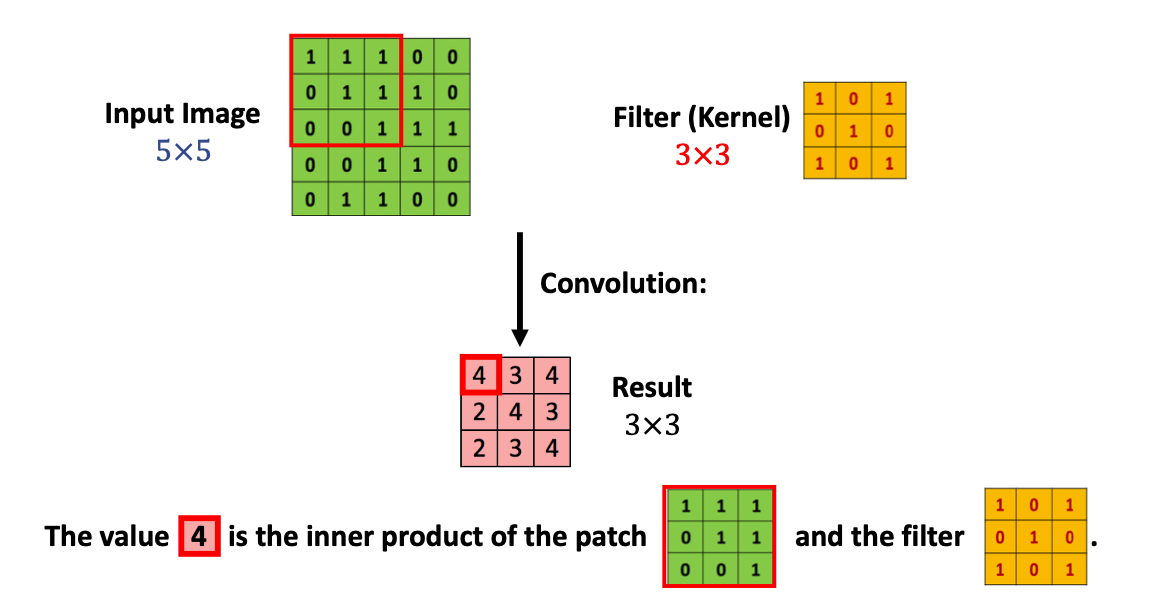
먼저 위 input image에서 순서대로 필터와 같은 크기 부분과 필터의 inner product 연산을 해주면 아래 빨간색 테두리 처럼 해당위치의 결과값은 4가 나온다. 이과정을 순서대로 위치를 옮겨가며 진행하게 되면,
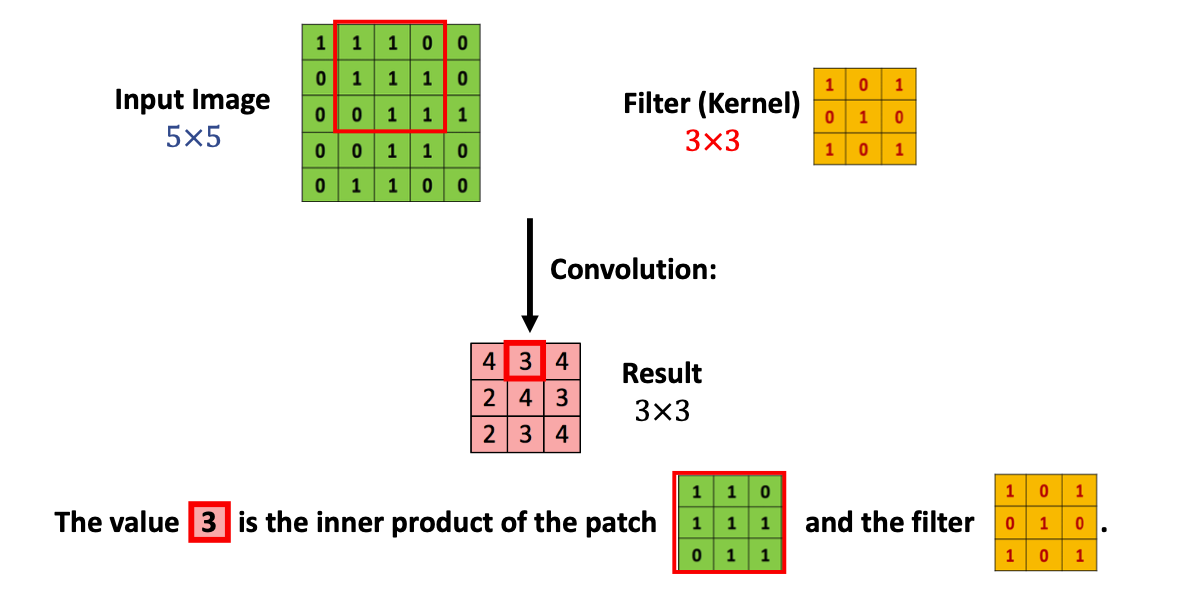
위 result에 나와 있는 것처럼, 3x3 의 결과 행렬이 나오게 된다.
CNN 전체구조
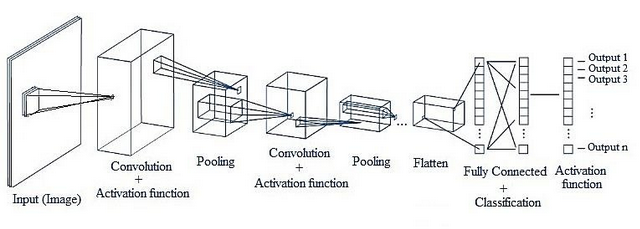
첫번째 Convolutional Layer
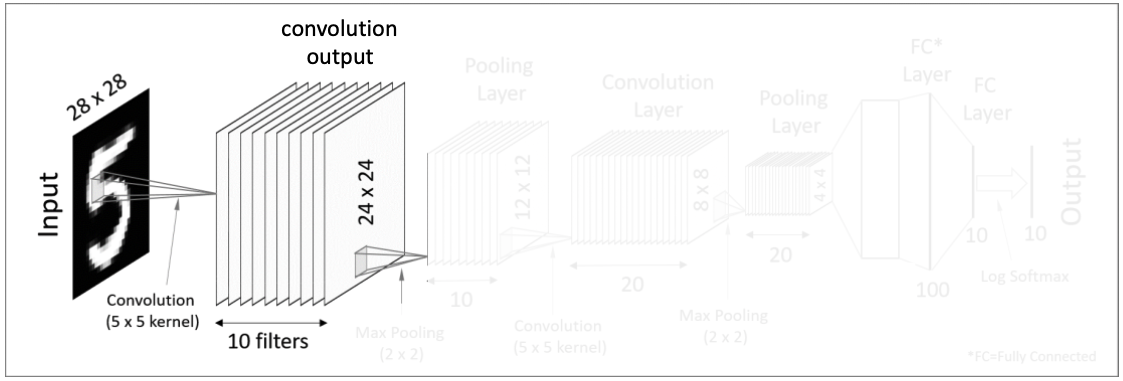
먼저 이미지를 대상으로 여러개의 필터를 사용해서 결과값을 얻는다. 위 그림에서는 28x28 이미지 입력값에 10개의 5x5필터를 사용해서 10의 24x24의 결과값들을 만들어냈다. 이 후에 활성화 함수를 적용하게 되면 첫번째 convolutional layer가 완성된다.
첫번째 Pooling Layer
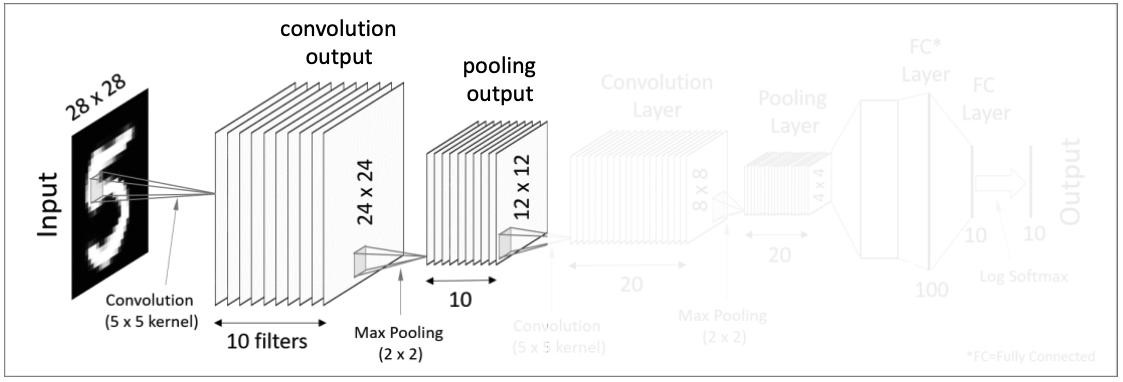
Pooling이란 결과값의 차원을 축소해주기 위한 작업으로, 각 결과값의 크기를 줄일 수 있다.
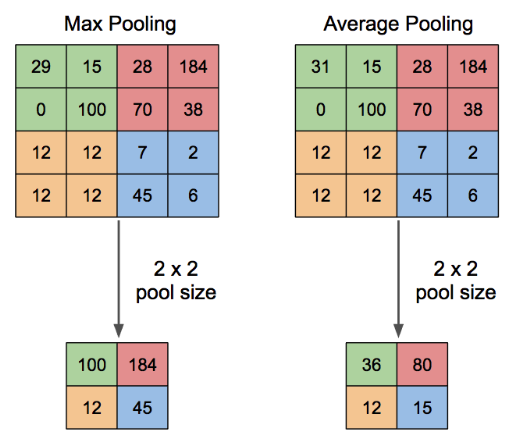
위 그림에서는 대표적으로 Max pooling 과 Average pooling을 소개하고 있으며, pool의 크기에 맞춰 matrix에서 가장 큰 값을 가져와 구성하거나, 평균을 내어 결과값의 크기를 줄여주는 작업이다.
따라서 pooling layer를 거치게 되면 결과값이 12x12 matrics가 된 것을 확인할 수 있다.
두번째 Covolutional Layer
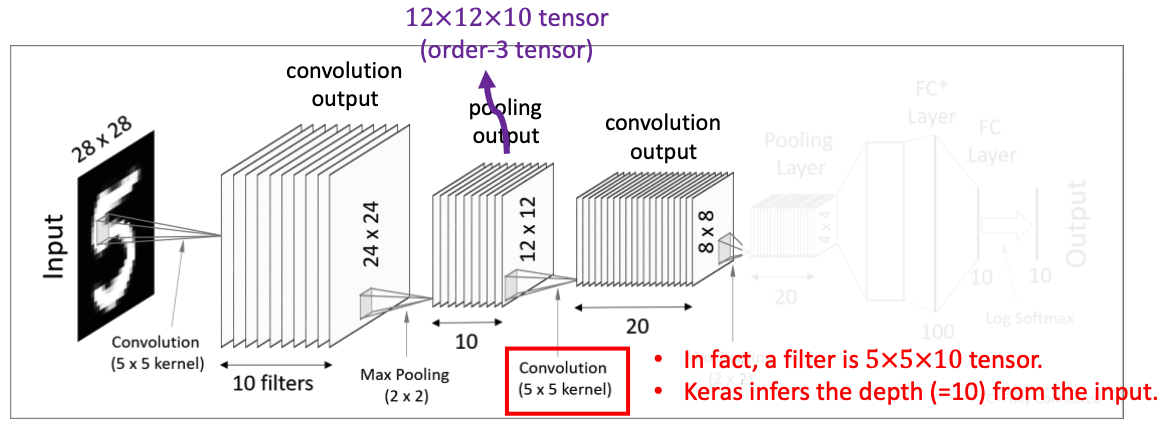
다음 Convolutional layer에서는 텐서 convolution을 적용한다. 이전 pooling layer에서 얻어낸 12x12x10텐서를 대상으로, 5x5x10크기의 텐서필터20개를 사용해준다. 그 결과 각각 8x8크기를 가진 결과값 20개를 얻어낼 수 있게된다.
두번째 Pooling Layer

첫번째 Pooling과 같은 방식으로 처리해주면 더 크기가 작아진 20개의 4x4결과값을 얻게된다.
Flatten(Vectorization)
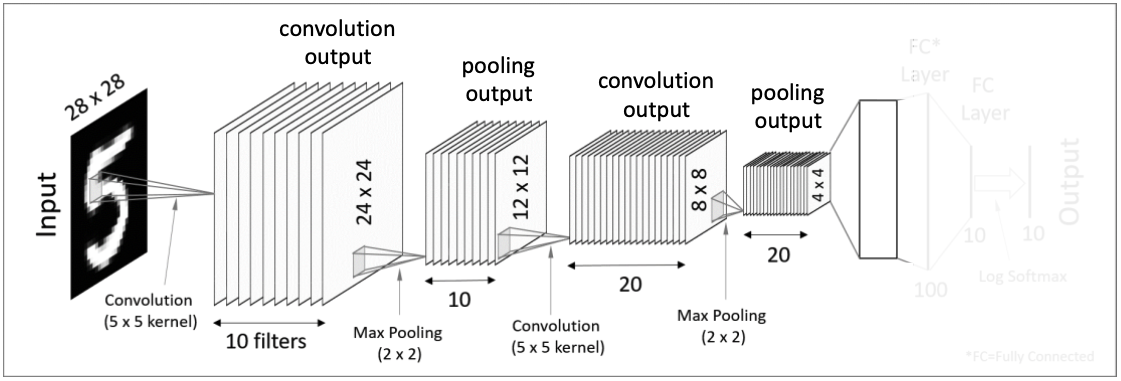
그 후 4x4x20텐서를 일자형태의 데이터로 쭉 펼쳐주는 Flatten 작업을 거친다. 최종적으로 320 차원을 가진 벡터형태가 완성된다.
이렇게 데이터를 펼쳐도 가능한 이유는 두번째 Pooling layer에서 얻어낸 4x4이미지가 입력된 이밈지에서 얻어온 특이점 데이터가 되기 때문이다.
Fully Connected Layers(Dense Layers)
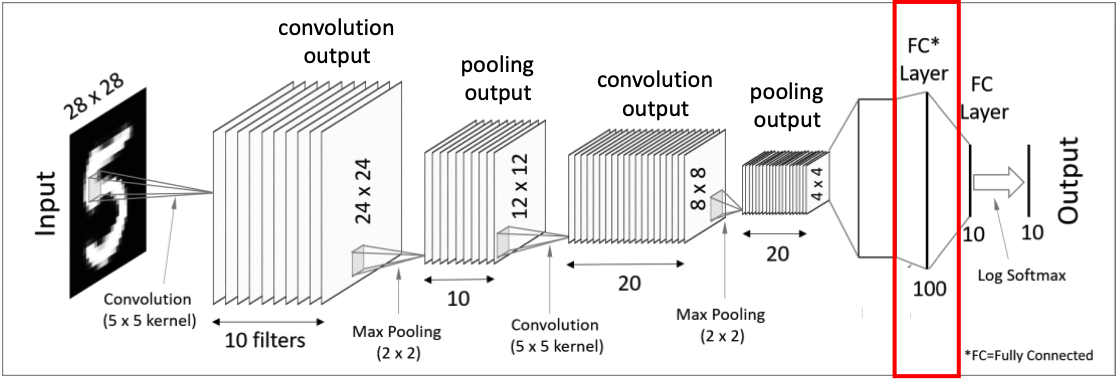
마지막으로 Fully-Connected Layer를 적용하고 softmax activation function을 적용하면 최종 결과값이 도출된다.
