RAG 처음부터 고도화까지 — 4편: Self-RAG · CRAG · Adaptive RAG + RAGAS 평가
이번 글의 목표
5축 중 ⑤ 생성 의 정교화와, 이 모든 개선이 정말 효과 있는지 측정 하는 도구.
핵심 메시지: 검색 결과를 무조건 믿지 않는 RAG 가 운영 환경의 다음 단계입니다. 2026 년 트렌드:
- Self-RAG — LLM 이 검색 필요/충분 여부를 스스로 판단
- CRAG — 별도 평가자가 검색 결과 품질을 채점, 부족하면 외부 폴백
- Adaptive RAG — 질문 난이도를 미리 라우팅
- RAGAS — 4지표 자동 평가
1. 생성 단계의 프롬프트 디자인
가장 단순한 프롬프트가 다음입니다:
근거:
[근거 1] ...
[근거 2] ...
질문: {q}
위 근거만 사용해서 한국어로 짧게 답해라.이 한 줄 ("근거만 사용해서") 이 환각의 1차 방어선. 그러나 부족합니다. 운영 RAG 의 프롬프트는 보통 다음을 명시적으로 박습니다:
| 지시 | 효과 |
|---|---|
| "근거에 없는 정보는 추측하지 말 것" | 환각 ↓ |
| "근거가 부족하면 '근거 없음'이라고만 답할 것" | 답변 보류 |
| "각 주장 끝에 출처 page 번호를 표시할 것" | 검증 가능성 ↑ |
| "한국어로 답할 것" | 영문 답변 방지 |
| "300자 이내" | 토큰 절약 + 산만함 방지 |
예시 프롬프트 (이게 baseline):
당신은 사내 문서 어시스턴트다. 다음 근거만 사용해서 한국어로 답하라.
규칙:
- 근거에 없는 정보는 절대 만들지 말 것. 모르면 "근거 없음"이라고만 답.
- 각 주장 뒤에 (page N) 으로 출처 표기.
- 300자 이내로 짧고 명확하게.
근거:
{evidence}
질문: {question}1.1. Citation 강제
LLM 이 페이지 번호를 빠뜨릴 때가 있습니다. 답변 후 파싱으로 강제:
answer = llm.chat(prompt)
if not re.search(r'\(page \d+\)', answer):
answer += f"\n\n(주의: 출처 표기 누락 - {[h.page for h in hits[:3]]} 참조 가능)"1.2. Chain-of-Thought
복잡한 추론이 필요한 질문이면 답변 직전에:
"먼저 근거를 정리한 뒤 답하라.
1) 관련 근거: ...
2) 추론: ...
3) 최종 답: ..."응답 토큰은 늘지만 정확도가 큰 폭으로 오릅니다.
2. Self-RAG — LLM 이 검색을 스스로 결정
기본 RAG 의 가정: 항상 검색하고, 검색 결과를 항상 믿는다. 두 가정 다 잘못된 경우가 많습니다.
Self-RAG (Asai et al., 2023) 는 LLM 을 fine-tune 해서 reflection 토큰 을 함께 생성하게 합니다:
[Retrieve?] = Yes / No
[Relevant?] = Relevant / Irrelevant / Partial
[Useful?] = 5 / 4 / 3 / 2 / 1흐름:
질문 → [Retrieve?]
├ No → 그냥 답 (예: "지금 몇 시?" 같은 일반 질문)
└ Yes → 검색 → [Relevant?]
├ Irrelevant → 다시 검색 or 답변 보류
└ Relevant → 답변 → [Useful?] 점수 부착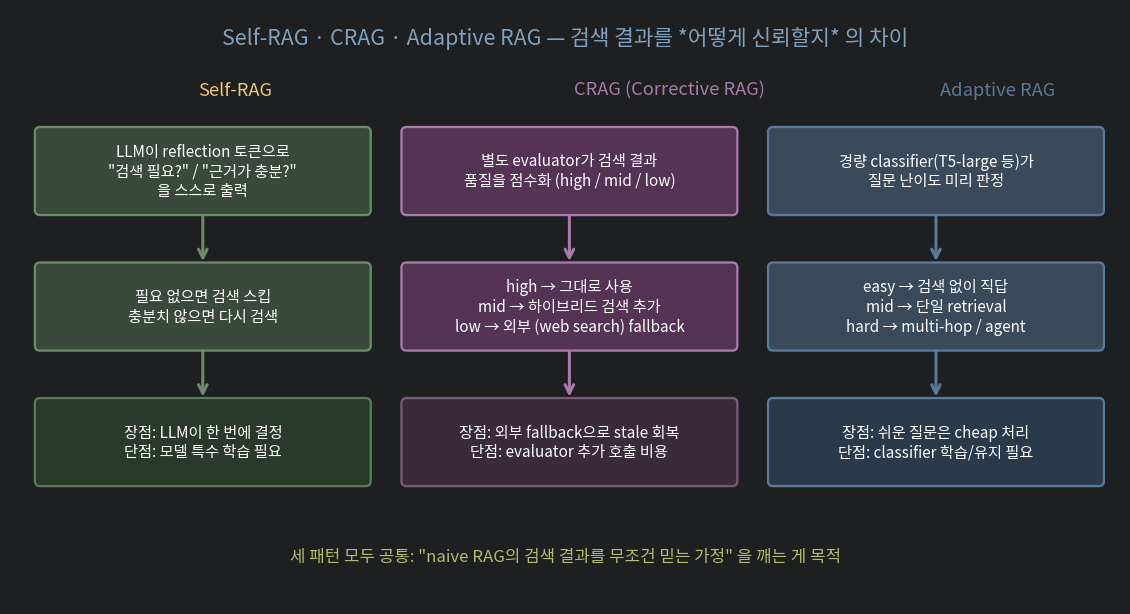
- 장점: 한 모델로 끝, 모든 결정이 LLM 안에 있음
- 단점: 모델을 특수 학습해야 함 (open weight
selfrag/selfrag_llama2_7b등). 일반 LLM에는 직접 적용 어려움
운영에서 Self-RAG 모델을 깔기 부담스러우면, 같은 효과를 일반 LLM + 명시적 프롬프트로 흉내 가능:
# 1단계: 검색 필요한 질문인가?
need_retrieve = llm.chat(
f"다음 질문이 사내 문서 검색이 필요한지 yes/no 로만 답하라: {q}"
) == "yes"
if not need_retrieve:
return llm.chat(q)
# 2단계: 검색 후 평가
hits = retriever.search(q)
relevant = llm.chat(
f"질문: {q}\n검색 결과:\n{format(hits)}\n"
"이 결과로 답이 가능한지 yes/no 로만 답하라."
) == "yes"
if not relevant:
return "근거 없음 — 답변 보류"
return generate_answer(q, hits)비용은 LLM 호출 +1~2 회 — 평가 단계 호출은 짧아서 큰 부담 아님.
3. CRAG — 검색 결과를 채점하고 폴백
CRAG (Corrective RAG) 는 별도의 작은 evaluator 가 검색 결과 품질을 점수화합니다:
검색 → evaluator: high / mid / low 판정
├ high → 그대로 사용
├ mid → 하이브리드 검색 추가 (BM25 보강 등)
└ low → 외부 (web search) 폴백- 장점: stale 정보 (사내 문서가 옛날 거) 를 외부로 메우는 자동 폴백
- 단점: evaluator 추가, 외부 검색 통합 필요
evaluator 도 자기 LLM 으로:
score = llm.chat(
"질문: {q}\n근거:\n{hits}\n"
"이 근거가 질문에 얼마나 도움 되는지 high / mid / low 로만 답하라."
)
if score == "low":
web_results = serper.search(q)
hits = merge(hits, web_results)운영 환경에서 Tavily / Serper 같은 검색 API 를 폴백 채널로 두는 경우가 많습니다. Higress-RAG (2026 enterprise framework) 의 핵심도 이 패턴 + semantic caching.
4. Adaptive RAG — 질문 난이도로 라우팅
모든 질문을 같은 파이프라인에 통과시키면 비효율적입니다. 간단한 질문은 가볍게, 복잡한 질문은 무겁게.
질문 → classifier
├ easy → 검색 없이 직답 (LLM 일반 지식)
├ mid → 단일 retrieval + 응답
└ hard → multi-hop / agent loopclassifier 는 작은 모델로 충분 (Adaptive RAG 논문은 T5-large 사용, 실전은 LLM 한 줄 호출로도 OK):
diff = llm.chat(
f"다음 질문의 난이도를 easy / mid / hard 로만 답하라: {q}"
)
match diff:
case "easy": return llm.chat(q)
case "mid": return rag(q)
case "hard": return agent_loop(q) # Part 5평균 비용 ↓, 평균 latency ↓, 어려운 질문의 정확도 ↑.
5. 측정 — 안 재면 모른다
지금까지 등장한 모든 개선:
"청킹을 Small-to-Big 으로", "Multi-Query 추가", "Cross-encoder rerank", "Self-RAG 흉내" ...
이게 본인의 도메인에서 정말 효과 있나 는 측정해야 압니다. 흔히 쓰는 도구가 RAGAS.
5.1. RAGAS 4지표
| 지표 | 의미 | 0~1 |
|---|---|---|
| faithfulness | 답변이 근거와 일치하나 — 환각 측정 | 높을수록 좋음 |
| answer_relevancy | 답변이 질문에 부합하나 | 높을수록 좋음 |
| context_precision | 검색된 컨텍스트 중 답에 쓸 부분 비율 | 높을수록 좋음 |
| context_recall | 정답에 필요한 정보가 컨텍스트에 다 있나 | 높을수록 좋음 |
faithfulness + answer_relevancy 는 출력의 품질. context_precision + context_recall 은 검색의 품질. 4지표가 다 균등하게 오를 때가 진짜 개선.
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
ds = Dataset.from_dict({
"question": [...],
"answer": [...],
"contexts": [[chunk_text, ...], ...],
"ground_truth": [...],
})
result = evaluate(ds, metrics=[faithfulness, answer_relevancy,
context_precision, context_recall])
print(result.to_pandas().mean(numeric_only=True))5.2. 평가셋 만들기
RAGAS 가 동작하려면 (question, ground_truth) 쌍이 필요합니다. 세 가지 방법:
| 방법 | 비용 | 정확도 |
|---|---|---|
| ① LLM 합성 — PDF 페이지에서 LLM 이 (Q, A) 자동 생성 | 낮음 | 노이즈 有 |
| ② 사용자 로그 — 실제 질문 + 만족도 라벨 | 중간 | 가장 정확 |
| ③ 도메인 전문가 — 페이지당 1~2 문항 직접 작성 | 높음 | 가장 정확 |
처음엔 ① 로 50~100 문항 빠르게 만들고, 운영 시작 후 ② 로 정확도 올리는 게 일반적.
LLM 합성 예시:
gen = llm.chat(
"다음 본문에 대해 한국어 짧은 사실 질문 1개와 정답 1개를 만들어라.\n"
"포맷:\nQ: ...\nA: ...\n\n본문:\n" + page_text
)
q, a = parse_qa(gen)5.3. A/B 비교
개선 전 → 개선 후 4지표 비교가 RAG 운영의 일상 업무입니다.
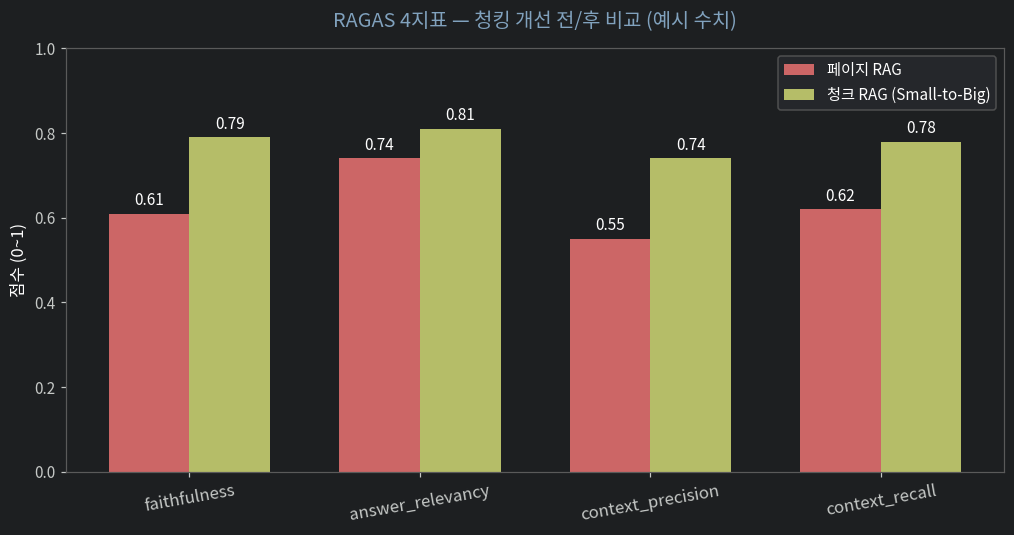
| 지표 | 페이지 RAG | 청크 RAG (Small-to-Big) | Δ |
|---|---|---|---|
| faithfulness | 0.61 | 0.79 | +0.18 |
| answer_relevancy | 0.74 | 0.81 | +0.07 |
| context_precision | 0.55 | 0.74 | +0.19 |
| context_recall | 0.62 | 0.78 | +0.16 |
이런 표 한 장이 "청킹 개선이 실제 의미 있다" 를 정량으로 보여줍니다. 운영에서 매 변경마다 같은 평가셋으로 채점 → 점수 떨어지면 롤백. 이게 RAG 의 CI/CD.
5.4. 다른 평가 프레임워크
| 도구 | 특징 |
|---|---|
| RAGAS | LLM-as-judge 4지표. 가장 흔함 |
| TruLens | Trace + 평가. 실시간 모니터링 친화적 |
| DeepEval | unit test 형태. CI 통합 좋음 |
| ARES | 사전 학습된 평가 모델 (LLM 호출 없이) |
6. 답변 후 검증 — Fact-Checking
RAGAS 가 오프라인 평가라면, 운영 중 실시간 검증 도 가능:
answer = llm.chat(prompt)
verify = llm.chat(
f"답변: {answer}\n근거:\n{contexts}\n"
"답변의 각 주장이 근거에서 지지되는지 확인. "
"지지되지 않는 주장이 있으면 그 문장만 인용. 없으면 'OK'."
)
if verify != "OK":
answer += f"\n\n[주의: 다음 주장은 근거가 부족함 — {verify}]"비용: LLM 호출 +1회. 사용자 신뢰가 결정적인 곳 (의료/법률) 에서 자주.
7. 운영 모니터링
- Drift 모니터링 — 사용자 질문 분포가 바뀌면 임베딩 인덱스가 stale 해짐. 주기적 재인덱싱 필요
- Freshness —
created_at기준 평균 문서 나이, 6개월 넘은 청크 비중 - Cache hit rate — semantic cache 도입 시 추적
- 답변 보류율 — "근거 없음" 답의 비율. 너무 높으면 검색 / 인덱스 점검 신호
- 사용자 피드백 — 답변 옆에 👍/👎, 답변 클릭 후 페이지 방문 추적
정리 — 5축의 마지막 한 축
| 기법 | 어디서 효과 |
|---|---|
| 명시적 프롬프트 ("근거만 / 추측 금지 / citation") | faithfulness ↑ |
| Self-RAG / CRAG | 환각 ↓ + stale 회복 |
| Adaptive RAG | 비용 ↓ + 어려운 질문 정확도 ↑ |
| RAGAS 4지표 평가 | 변경의 효과를 정량 확인 — 모든 다른 기법의 근거 |
| 사용자 로그 기반 평가셋 | 운영 RAG 가 안정적으로 개선되는 핵심 |
참고
- Self-RAG (Asai et al., 2023): arXiv:2310.11511
- Corrective RAG / CRAG (Yan et al., 2024): arXiv:2401.15884
- Adaptive RAG (Jeong et al., 2024): arXiv:2403.14403
- RAGAS — github.com/explodinggradients/ragas
- 김 카이도, Agentic RAG: Self-Correcting Retrieval: link
