강의 리뷰
- TensorFlow와 PyTorch
- PyTorch : Dynamic Computation Graph
- TensorFlow : Define and Run
- Computational Graph
연산의 과정을 그래프로 표현,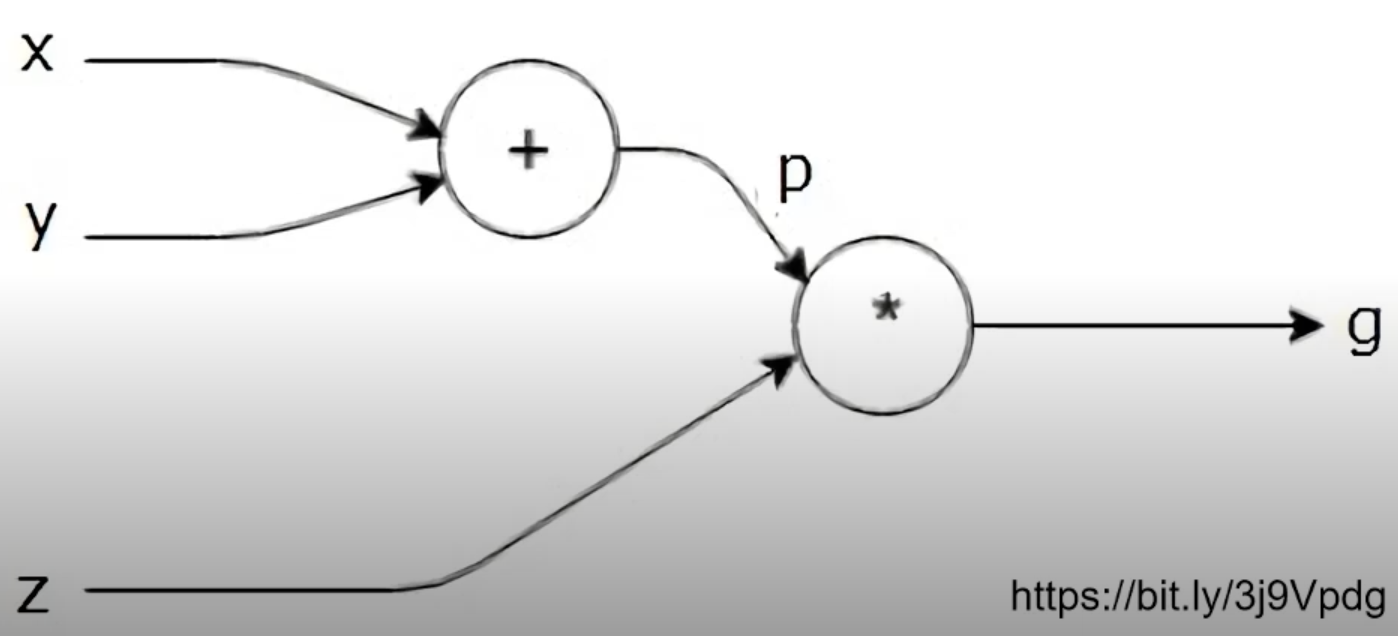
- Define and Run : 그래프를 먼저 정의 -> 실행시점에 데이터 feed (TensorFlow)
- production과 scalability의 장점
- Define by Run : 실행을 하면서 그래프를 생성하는 방식 (PyTorch)
- 즉시 확인 가능 : Pythonic code
- 사용하기 편한 장점
- Define and Run : 그래프를 먼저 정의 -> 실행시점에 데이터 feed (TensorFlow)
PyTorch : Numpy + AutoGrad + Function
-
Tensor handling
- view : reshape과 동일하게 tensor의 shape을 변환(얕은 복사)
- squeeze : 차원의 개수가 1인 차원을 삭제 (압축)
- unsqueeze : 차원의 개수가 1인 차원을 추가
- reshape : tensor의 shape을 변환(깊은 복사)
-
Tensor operations
행렬곱셈 연산은 함수는 dot이 아닌 mm 사용- dot : 내적, 보통 '@'연산자 사용 (numpy)
- mm : 행렬곱셈 연산, broadcasting 지원 X (Tensor)
- matmul : 행렬곱셈 연산, broadcasting 지원 O (Tensor)
-
Tensor operations for ML/DL formula
nn.functional 모듈을 통해 다양한 수식 변환을 지원함import torch import torch.nn.functional as F tensor = torch.FloatTensor([0.5,0.7,0.1]) h_tensor = F.softmax(tensor,dim=0) h_tensor # tensor([0.3458,0.4224,0.2318]) -
AutoGrad
PyTorch의 핵심은 자동 미분의 지원 : backward 함수 사용w = torch.tensor(2.0,requires_grad = True) y = w**2 z = 10*y+25 z.backward() w.grad -
torch.nn.Module
- layer는 블럭
- 딥러닝을 구성하는 Layer의 base class
- input,output,forward,backward 정의
- 학습의 대상이 되는 parameter(tensor) 정의
-
nn.Parameter
- Tensor 객체의 상속 객체
- nn.Module 내에 attribute가 될 때는 required_grad = True로 지정되어 학습 대상이 되는 Tensor
- 우리가 직접 지정할 일은 잘 없음
-
Backward
- Layer에 있는 Parameter들의 미분을 수행
- Forward의 결과값 (Model의 output=예측치)과 실제값간의 차이(loss)에 대해 미분을 수행
- 해당 값으로 Parameter 업데이트
for epoch in range(epochs): ... optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs,labels) loss.backward() optimizer.step() ... -
Dataset 클래스
- 데이터 입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따른 다른 입력정의
import torch import torch.utils.data import Dataset class CustomDataset(Dataset): def __init__(self,text,labels): #초기 데이터 생성 방법을 지정 self.labels = labels self.data = text def __len__(self): # 데이터의 전체 길이 return len(self.labels) def __getitem__(self,idx): # index 값을 주었을 때 반환되는 데이터의 형태 label = self.labels[idx] text = self.data[idx] sample = {"Text":text, "Class":label} return sample -
DataLoader 클래스
- Data의 Batch를 생성해주는 클래스
- 학습직전(GPU feed전) 데이터의 변환을 책임
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
from torch.utils.data import Dataset, DataLoader MyDataLoader = DataLoader(MyDataset, batch_size = 2, shuffle = True) next(iter(dataset_loader)) # 데이터가 나옴- option
- sampler : 데이터를 어떻게 뽑을지 index를 정해주는 기법
- batch_sampler
- collate_fn : Variable lenth 처리를 위해 사용, padding 할 때 사용
-
torchsummary
모델의 구조를 Keras 형태로 볼 수 있다.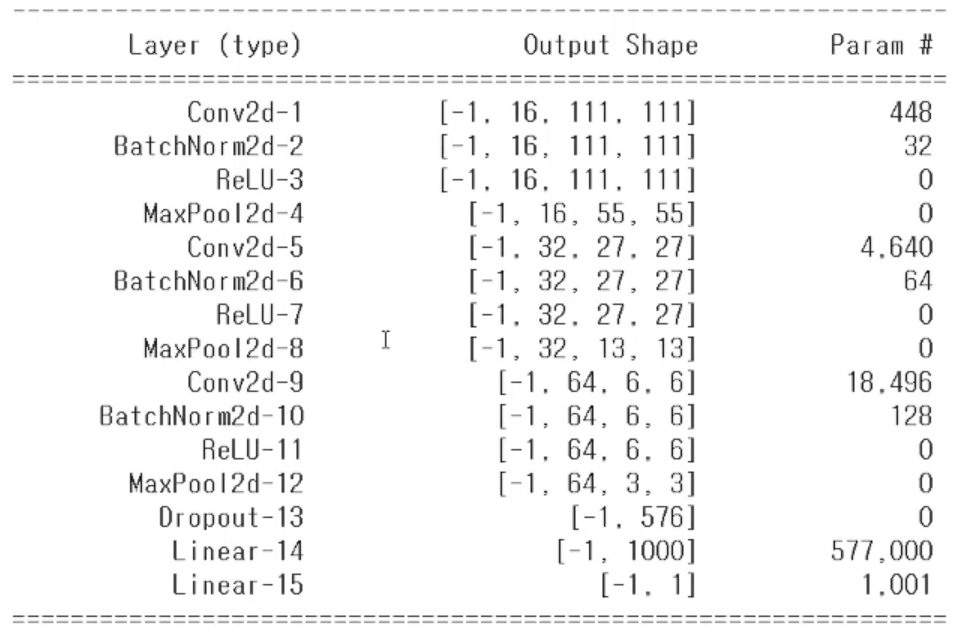
-
checkpoints
-
학습의 중간 결과를 저장하여 최선의 결과를 선택
-
earlystopping 기법 사용시 이전 학습의 결과물을 저장
-
loss와 metric 값을 지속적으로 확인 및 저장
-
일반적으로 epoch,loss,metric을 함께 저장하여 확인
# exmaple torch.save({ 'epoch' : e, 'model_state_dict' : model.state_dict(), 'potimizer_state_dict' : optimizer.state_dict(), 'loss' : epoch_loss,}, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt") checkpoint = torch.load(PATH) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss']
-
-
전이 학습
#example def binary_acc(y_pred, y_test): y_pred_tag = torch.round(torch.sigmoid(y_pred)) correct_results_sum = (y_pred_tag == y_test).sum().float() acc = correct_results_sum/y_test.shape[0] acc = torch.round(acc * 100) return acc my_model = MyNewNet() my_model = my_model.to(device) for param in my_model.parameters(): param.requires_grad = False for param in my_model.linear_layers.parameters(): param.requires_grad = True criterion = nn.BCEWithLogitsLoss() optimizer = optim.Adam(my_model.parameters(), lr=LEARNING_RATE) for e in range(1, EPOCHS+1): epoch_loss = 0 epoch_acc = 0 for X_batch, y_batch in dataloader: X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor) optimizer.zero_grad() y_pred = my_model(X_batch) loss = criterion(y_pred, y_batch.unsqueeze(1)) acc = binary_acc(y_pred, y_batch.unsqueeze(1)) loss.backward() optimizer.step() epoch_loss += loss.item() epoch_acc += acc.item() print(f'Epoch {e+0:03}: | Loss: {epoch_loss/len(dataloader):.5f} | Acc: {epoch_acc/len(dataloader):.3f}') -
Monitoring tools for PyTorch
-
Tensorboard
- TensorFlow의 프로젝트로 만들어진 시각화 도구
- 학습 그래프, metric, 학습 결과의 시각화 지원
- PyTorch도 연결 가능 -> DL 시각화 핵심 도구
- scalar : metric 등 상수 값의 연속(epoch)을 표시
- graph : 모델의 computational graph 표시
- histogram : weight 등 값의 분포를 표현
- image : 예측 값과 실제 값을 비교 표시
- mesh : 3d 형태의 데이터를 표현하는 도구
#example import os logs_base_dir = "logs" os.makedirs(logs_base_dir, exist_ok=True) from torch.utils.tensorboard import SummaryWriter import numpy as np writer = SummaryWriter(logs_base_dir) for n_iter in range(100): writer.add_scalar("Loss/train",np.random.random(),n_iter) writer.add_scalar("Loss/test",np.random.random(),n_iter) writer.add_scalar("Accuracy/train",np.random.random(),n_iter) writer.add_scalar("Accuracy/test",np.random.random(),n_iter) writer.flush() %load_ext tensorboard %tensorboard --logdir {logs_base_dir} -
weight & biases
- 머신러닝 실험을 원활히 지원하기 위한 상용도구
# example EPOCHS = 100 BATCH_SIZE = 32 LEARNING_RATE = 0.001 config={"epochs": EPOCHS, "batch_size": BATCH_SIZE, "learning_rate" : LEARNING_RATE} wandb.init(project="my-test-project", config=config) # wandb.config.batch_size = BATCH_SIZE # wandb.config.learning_rate = LEARNING_RATE # config={"epochs": EPOCHS, "batch_size": BATCH_SIZE, "learning_rate" : LEARNING_RATE} for e in range(1, EPOCHS+1): epoch_loss = 0 epoch_acc = 0 for X_batch, y_batch in train_dataset: X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor) optimizer.zero_grad() y_pred = model(X_batch) loss = criterion(y_pred, y_batch.unsqueeze(1)) acc = binary_acc(y_pred, y_batch.unsqueeze(1)) loss.backward() optimizer.step() epoch_loss += loss.item() epoch_acc += acc.item() train_loss = epoch_loss/len(train_dataset) train_acc = epoch_acc/len(train_dataset) print(f'Epoch {e+0:03}: | Loss: {train_loss:.5f} | Acc: {train_acc:.3f}') wandb.log({'accuracy': train_acc, 'loss': train_loss})
-
-
Multi-GPU
- Single vs. Multi : Gpu의 개수
- GPU vs. Node : 컴퓨터(system)의 개수
- ex) Single Node Multi GPU
- Data parallel
- 데이터를 나눠 GPU에 할당후 결과의 평균을 취하는 방법
- minibatch 수식과 유사, 한번에 여러 GPU에서 수행
- PyTorch에서는 두 가지 방법을 제공
- DataParallel : 단순히 데이터를 분배한 후 평균을 취함
- GPU사용 불균형, Batch 사이즈 감소 (한 GPU가 병목)
- DistributedDataParallel : 각 CPU마다 process 생성하여 개별 GPUdp gkfekd
- 기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 낸다.
# example parallel_model = torch.nn.DataParallel(model) ... loss.mean().backward() ... - DataParallel : 단순히 데이터를 분배한 후 평균을 취함
-
Hyperparameter Tuning
- 모델 스스로 학습하지 않는 값은 사람이 지정
- Learning Rate, 모델의 크기, Optimizer 등
- NAS(AutoML)을 통해 자동화 할 수도 있음
- 가장 기본적인 Grid, Random
- 최근은 베이지안 기반 기법이 주도
- Ray
- multi-node multi processing 지원 모듈
- ML/DL 병렬 처리를 위해 개발된 모듈
- Hyperparameter Search를 위해 다양한 모듈 지원
# config에 serach space 지정, 학습 스케줄링 알고리즘 지정 config = { "l1" : tune.sample_from(lambda _ : 2 ** np.random.randint(2,9)), "l2" : tune.sample_from(lambda _ : 2 ** np.random.randint(2,9)), "lr" : tune.loguniform(1e-4, 1e-1), "batch_size" : tune.choice([2,4,8,16]) } scheduler = ASHAScheduler( metric = "loss", mode = "min", max_t = max_num_epochs, grace_period = 1, reduction_factor = 2) reporter = CLIReporter( metric_columns = ["loss","accuracy","training_iteration"]) result = turn.run( partial(train_cifar, data_dir = data_dir), resources_per_tial = {"cpu":2,"gpu":gpus_per_trial}, config = config, num_samples = num_samples, scheduler = scheduler, progress_report = report)
- 모델 스스로 학습하지 않는 값은 사람이 지정
-
PyTorch Troubleshooting
-
Out Of Memory
- Batch Size를 down -> GPU clean -> Run
- Batch Size를 1로 설정해보고 실험해보기
-
GPUtil 사용하기
- GPU 상태를 보여준다.
# example import GPUtil GPUtil.showUtilization()
-
torch.cuda.empty_cache()
- 사용되지 않은 GPU상 cache를 정리
- 가용 메모리를 확보
- del 과는 구분이 필요
- reset 대신 쓰기 좋은 함수
-
torch.no_grad()
- backward pass 으로 인해 쌓이는 메모리에서 자유로움
-
과제 리뷰
-
벡터나 행렬의 norm을 계산하기 위해서 torch.linalg.norm을 사용한다.
- 계산하는 것이 벡터인지 행렬인지 더 명확하게 나타내기
- torch.linalg.vector_norm
- torch.linalg.matrix_norm
-
torch.tensor VS torch.Tensor
- torch.Tensor
- 클래스
- int 입력시 float로 변환
- torch 데이터 입력시 입력 받은 데이터의 메모리 공간을 사용
- list,numpy 데이터 입력 시 입력 받은 데이터를 복사하여 새롭게 torch.Tensor를 만든 후 사용
- torch.tensor
- 함수
- int 입력시 int 그대로 입력
- 입력 받은 데이터를 새로운 메모리 공간으로 복사 후 사용
- 클래스는 앞글자가 대문자로 시작, 함수은 앞글자가 소문자로 시작
- torch.Tensor
-
Set random seed
# Set random seed SEED = 2021 random.seed(SEED) np.random.seed(SEED) os.environ["PYTHONHASHSEED"] = str(SEED) torch.manual_seed(SEED) torch.cuda.manual_seed(SEED) # type: ignore torch.backends.cudnn.deterministic = True # type: ignore torch.backends.cudnn.benchmark = True # type: ignore # 중요하지 않은 에러 무시 warnings.filterwarnings(action='ignore') # 유니코드 깨짐현상 해결 mpl.rcParams['axes.unicode_minus'] = False -
Dataset의 기본 구성 요소
# 기본 요소 from torch.utils.data import Dataset class CustomDataset(Dataset): def __init__(self,): pass def __len__(self): pass def __getitem__(self,idx): passinit- 일반적으로 해당 메서드에서는 데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작합니다. 일반적으로 CSV파일이나 XML파일과 같은 데이터를 이때 불러옵니다. 이렇게 함으로서 모든 데이터를 메모리에 로드하지 않고 효율적으로 사용할 수 있습니다. 여기에 이미지를 처리할 transforms들을 Compose해서 정의해둡니다.
getitem- 해당 메서드는 데이터셋의 idx번째 데이터를 반환하는데 사용됩니다. 일반적으로 원본 데이터를 가져와서 전처리하고 데이터 증강하는 부분이 모두 여기에서 진행될 겁니다. 이는 이후 transform 하는 방법들에 대해서 간단히 알려드리겠습니다.
len- 해당 메서드는 Dataset의 최대 요소 수를 반환하는데 사용됩니다. 해당 메서드를 통해서 현재 불러오는 데이터의 인덱스가 적절한 범위 안에 있는지 확인할 수 있습니다.
-
PyTorch의 DataLoader
- DataLoader의 기본 구성 요소
DataLoader(dataset, batch_size=1,shuffle=False,sampler=None,batch_sampler=None, num_workers=0, collate_fn = None, pin_memory = False, drop+last = False, timeout = 0, worker_init-fn = None) dataset: Dataset 인스턴스가 들어감batch_size: batch_sizeshuffle: 데이터를 DataLoader에서 섞어서 사용하는지sampler, batch_sampler: index를 컨트롤 하는 방법, index를 원하는 방식대로 조정함. 그렇기에 shuffle 파라미터는 False(기본값)여야 함- SequetialSampler : 항상 같은 순서
- RandomSampler : 랜덤, 개수 선택 가능, replacemetn 여부 선택 가능
- WeightRandomSampler : 가중치에 따른 확률
- SubsetRandomSampler : 랜덤 리스트
- BatchSampler : batch단위로 sampling 가능
- DistributedSampler : 분산처리 (torch.nn.parallel.DistributedDataParallel과 함께 사용)
- 불균형 데이터셋의 경우, 클래스의 비율에 맞게끔 데이터를 제공해야할 필요가 있다. 이 때 사용하는 옵션
num_workers: 데이터를 불러올 때 사용하는 서브 프로세스 개수- 무작정 num_workers를 높인다고 좋진 않다. 데이터를 불러 CPU와 GPU 사이에서 많은 교류가 일어나면 오히려 병목이 생길 수 있다.
collate_fn: zero-padding이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해 많이 사용
- DataLoader의 기본 구성 요소
