
Git
-
프로젝트 폴더를 만든다.
# 폴더 세팅 >> mkdir project >> cd project >> code . -
저장소 만들기
>> git init -
파일을 만들고 2개의 커밋을 만든다.
# 파일 만들기 >> touch work1.txt >> touch work2.txt >> touch work3.txt # git 상태 보기 >> git status # Staging Area로 파일 보내기 >> git add work1.txt # Commit 하기 (To Repository) >> git commit -m "Work 1" -
시간여행
# git head와 master 찾기 및 Log 확인 >> git log --oneline --all # 원하는 버전으로 이동하기 >> git checkout COMMIT_ID # 마스터로 돌아가기 >> git checkout master -
브랜치 만들고 작업할 수 있도록 체크아웃
# branch 추가 git branch exp # 추가된 branch로 이동 git checkout exp # 한번에 하기 git checkout -b exp -
서로 다른 브랜치에서 작업한다.
# 서로 다른 branch에서 작업후 commit # exp 브랜치 : exp.txt # master 브랜치 : master.txt -
브랜치 합치기
# 합치길 원하는 곳으로 head를 설정 후 >> git merge exp
NLP
-
Trends of NLP
- Each word can be represented as a vector through a technique such as Word2Vec or GloVe
- RNN-family models(LSTMs and GRUs)
- attention modules and Transformer models, which replaced RNNs with self-attention
- In the early days, customized models for different NLP tasks had developed separately
- huge models, self-supervised training setting that does not require additional labels
- Models were applied to other tasks through transfer learning, and they outperformed all other customized models in each task
- NLP research become difficult with limited GPU resources
-
Bag-of-Words Representation
- Step 1. Constructing the vocabulary containing unique words
- step 2. Encoding unique words to one-hot vectors
- A sentence / document can be represented as the sum of one-hot vectors
- Bayes'Rule

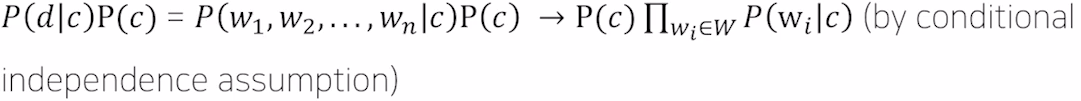
-
Naive Bayes classifier (실습) : Konlpy 패키지를 통해 한국어 형태소 분석이 가능
# 토큰화 from konlpy import tag from itertools import chain from collections import Counter, defaultdict tokenizer = tag.Okt() def make_tokenized(data): tokenized = [] for sent in tqdm(data): tokens = tokenizer.morphs(sent) tokenized.append(tokens) return tokenized train_tokenized = make_tokenized(train_data) i2w = list(set(chain.from_iterable(train_tokenized))) w2i = {w: i for i,w in enumerate(i2w)} -
Py-Hanspell : 한국어 맞춤법 교정 서비스, 네이버 한국어 맞춤법 검사기를 기반
# Py-Hanspell !pip install git+https://github.com/ssut/py-hanspell.git from hanspell import spell_checker sent = "맞춤법 틀리면 외 않되? 쓰고싶은대로쓰면돼지 " spelled_sent = spell_checker.check(sent) hanspell_sent = spelled_sent.checked print(hanspell_sent) -
정규 표현식
- "\"를 활용하면 특정 집합에 속한 문자 "하나"를 지칭할 수 있다.
- \w : 영숫자 + 언더스코어
- \W : (영숫자+"_")를 제외한 문자
- \d : 숫자
- \D : 숫자가 아닌 문자
- \s : 공백 문자
- \S : 공백이 아닌 문자
- \b : 단어 경계
.기호 : 아무 문자 하나를 지칭합니다.(공백 포함, \n제외)[ ]기호 : [] 안에 있는 문자들 중에서 하나의 문자와 매치- 범위 지정 가능 Ex) [A-Z]
^기호 : [^] 안에 있는 문자를 제외한 문자들 중에서 하나의 문자와 매치*기호 : * 는 바로 앞의 문자가 0개 이상일 경우를 나타낸다.+기호 : +는 바로 앞의 문자가 최소 1개 이상일 경우?기호 : ?는 바로 앞의 문자가 있을 수도 없을 수도 있는 경우{}기호 : {}는 {숫자} 형태로 사용되며, 바로 앞의 문자가 해당 숫자만큼 반복되는 경우를 나타낸다.^기호 : 글의 시작을 의미$기호 : 글의 끝을 의미|기호 : 일종의 or 기호()기호 : 텍스트을 캡쳐(?: )기호 : 일반 괄호, 캡쳐를 하지 않는다.(?= )기호 : 뒷 패턴을 확인(?<= )기호 : 앞 패턴을 확인, (?<=R)D 형태로 사용, R이 바로 앞에 있는 D를 매칭하며 R부분은 포함하지 않는다.
#정규식 import re for index, review in enumerate(reviews): reviews[index] = re.sub('[^ 가-힣]', '', review) # sub 함수를 사용하면 해당 패턴을 다른 텍스트로 대체가 가능합니다. for index, review in enumerate(reviews): reviews[index] = re.sub(' +', ' ', review) # sub 함수를 사용하면 해당 패턴을 다른 텍스트로 대체가 가능합니다.
출처 : Naver BoostCamp

AI 새싹