
주제
- 저시력자를 위한 원화 화폐 분류
목표
- Object Detection을 위한 Data Preprocessing(1일차)
- Implement YOLO(2일차)
개인 목표
- yolo 모델에 대해 공부하기
1. 데이터 전처리
- zip파일로 주어진 데이터 -> 압축 풀기
- 데이터 구성: 이미지 파일 + Json 파일
- 이미지 파일 전처리
- Json파일로 label 데이터 만들기
데이터셋 불러오기
zipfile 모듈
- 파이썬 제공 표준 라이브러리
- zipfile을 처리하는 데 사용하는 모듈
- 파일 경로 등이 많이 사용되므로 주로 'os 모듈'과 함께 사용
import zipfile
zipfile.ZipFile(file, mode='r', compression=ZIP_STORED, allowZip64=True, compresslevel=None, *, strict_timestamps=True)
# 반환: ZipFile 객체- file : Zip 파일 이름 또는 경로
- mode : Zip 파일 열기 모드 (r - 읽기모드, w - 쓰기모드)
- compression : 압축 방법 (ZIP_STORED - 압축하지 않음, ZIP_DEFLATED - Deflate 알고리즘 사용)
- allowZip64 : True로 설정하면 4GB 이상의 큰 파일도 처리 가능
- compresslevel : 압축 레벨 (0~9)
압축 풀기
zip_ref = zipfile.ZipFile('/dataset.zip')
zip_ref.extractall('압축 해제할 디렉토리')- 다음과 같이 바꿀 수 있음
with zipfile.ZipFile('/dataset.zip') as zip_ref:
zip_ref.extractall('압축 해제할 디렉토리')
# '압축 해제할 디렉토리'가 존재하지 않으면 자동 생성데이터 이동
- 폴더 구조를 만들고 그에 맞게 데이터를 이동
- 모델(yolo)에서 요구하는 구조: Image, Label를 구분하여 저장
- Image: 이미지 데이터
- Label: Json 데이터
- 각 디렉토리에 Train, Validation를 구분하여 저장
- Train : Validation = 8 : 2
def split_files(file_list, src_path, val_data_num, dst_path):
for i, file_name in enumerate(file_list):
src_file = os.path.join(src_path, file_name)
if i < val_data_num:
shutil.move(src_file, dst_path + '/val')
else:
src_file = os.path.join(src_path, file_name)
shutil.move(src_file, dst_path + '/train')- 전체 중 20%를 'val'에 옮긴 후 나머지는 'train'에 이동
Json 데이터 정보 추출
- yolo 모델에서는 label 정보를 담은 'txt 파일'이 필요
- Json 데이터에서 필요한 정보를 추출하여 'txt 파일' 생성
- 필요한 정보:
- class
- x_center: 박스 중앙 x 좌표
- y_center: 박스 중앙 y 좌표
- width: 박스 너비
- height: 박스 높이
- yolo Train Custom Data - 1. Create Dataset
class 추출
- class는 zero-indexed(0부터 시작)
- Json의 'label'데이터에는 화폐의 앞, 뒤가 구분되어 있음 -> 구분을 없애고 class로 만들기 -> 8개 클래스(0~7)
class = {'Ten':0, 'Fifty':1,
'Hundred':2, 'Five_Hundred':3,
'Thousand':4, 'Five_Thousand':5,
'Ten_Thousand':6, 'Fifty_Thousand':7}x_center, y_center, width_norm, height_norm
- Bounding Box에 대한 정보
- 모든 정보는 normalized 가 필요(0-1사이의 값)
- 주어진 이미지는 Json에서와 달리 1/5 축소된 상태임을 주의
.txt 저장
with open(dst_file, 'w') as f:
f.write(f'{class[label]} {x_center} {y_center} {width_norm} {height_norm}')yaml 파일 만들기
- yolo에서 제공하는 예시
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes (80 COCO classes)
names:
0: person
1: bicycle
2: car
...
77: teddy bear
78: hair drier
79: toothbrush- 예시를 참고하여 yaml 파일 생성
data = {
'path': '/content/drive/MyDrive/Datasets',
'train': 'images/train',
'val': 'images/val',
'nc': 8,
'names': won_dict
}
yaml_file = os.path.join(dataset_path, 'money.yaml')
with open(yaml_file, 'w') as f:
yaml.dump(data, f)- 생성한 yaml 파일 확인
path: /content/drive/MyDrive/Datasets
train: images/train
val: images/val
nc: 8
names:
0: '10'
1: '50'
2: '100'
3: '500'
4: '1000'
5: '5000'
6: '10000'
7: '50000'어려웠던 부분
- 학습과정에서 cpu와 gpu의 차이는 매우 크다
마무리

- 전처리를 끝내고 남은 시간에 'yolov5n'을 약 1시간에 걸쳐 학습시킨 후, detect 해본 결과
- 10원을 50원으로 라벨링
- 100원을 500원으로 라벨링
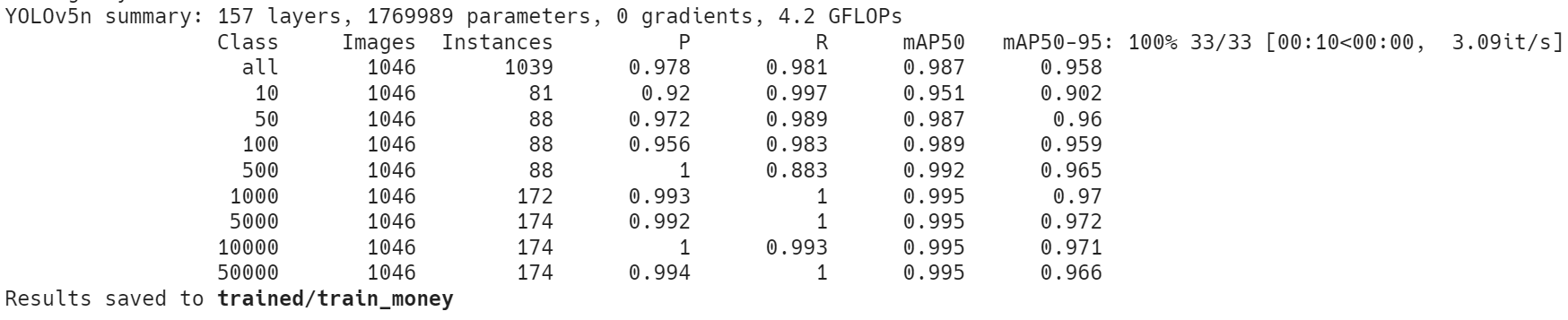
- 학습 시 좋은 성능을 보였더라도 실제에서는 다르게 탐지하는 결과를 보임: 원인이 무엇인지 확인해보기(모델 복잡도, 전처리 과정 등)
- 더 간단한 모델(v5s 등) 혹은 더 복잡한 모델(v5x 등), 최신 버전의 모델(v8)을 시도해볼 예정

A smooth sea never made a skilled sailor