
- 전체보기(53)
- 알고리즘(4)
- Java(4)
- sql(2)
- pintos(2)
- ms data school(2)
- PostgreSQL(2)
- queue(1)
- heap(1)
- 메모리 초과(1)
- StringBuilder(1)
- Infrastructure as Code(1)
- 소수 판별(1)
- 개발일지(1)
- 성능 최적화(1)
- Azure 인프라 코드(1)
- 에라토스테네스의 체(1)
- comparator(1)
- Hult prize national(1)
- ARM 템플릿(1)
- 입출력(1)
- langChain(1)
- 공부기록(1)
- PriorityQueue(1)
- Embedding(1)
- Priority Scheduling(1)
- Database(1)
- ms data school 4기(1)
- 부트캠프(1)
- OS design(1)
- Computer Network(1)
- 자료구조(1)
PySpark 6 - Query Optimization
13 Query OptimizationSpark는 코드를 실행하기 전에 Catalyst라는 최적화 엔진이 쿼리 계획을 자동으로 다듬어줌.비유: 내가 요리 순서를 비효율적으로 짜도, 주방장(Catalyst)이 알아서 더 효율적인 순서로 바꿔서 실행하는 것출력 순서:실무에
PySpark 5 - 날짜·배열·null처리·Join
9 Datetimes / 10 Complex Types / 11 Additional Functions비유: cast는 "형변환 캐스팅" — 배우(데이터)를 다른 역할(타입)로 바꾸는 것원시 데이터의 타임스탬프는 보통 마이크로초(μs) 단위 Long 숫자로 저장됨.초 단
PySpark 4 - Reader & Writer
비유: Reader는 "데이터를 가져오는 택배 수령", Writer는 "데이터를 보내는 택배 발송"두 방법은 동일한 결과. 취향에 따라 선택⚠️ inferSchema=True는 전체 데이터를 한 번 스캔하므로 느림. 대용량이면 스키마 직접 지정 권장비유: 테이블의 설계
PySpark 3 -집계
🗓️ 학습일: 2026.06📚 출처: Databricks 수업 자료 (5_Aggregation.ipynb)"데이터를 그룹으로 묶고(groupBy), 그 그룹에 집계를 적용한다(agg / count / sum / avg …)"집계는 여러 행(row)을 하나의 요약 값
PySpark 2 - DataFrame & Column 조작
컬럼 선택, 추가, 수정, 행 필터링, 정렬까지 DataFrame을 다루는 핵심 문법 정리DataFrame에서 컬럼을 가리킬 때 세 가지 방법이 있다. 결과는 모두 동일하다.select()와 차이:withColumn 규칙:filter()와 where()는 완전히 동일하
PySpark 1 - DataFrame 생성
SQL과 Python DataFrame API, 두 가지 방법으로 같은 쿼리를 표현하는 방법 정리Q. 내용은 PySpark인데 왜 제목이 Spark SQL이야?Spark SQL은 "SQL만 쓰는 것"이 아니라 구조화된 데이터를 처리하는 Spark 모듈 전체의 이름이다.
Databricks - Spark SQL 2
지저분한 데이터를 정리하고, 복잡한 구조를 다루고, 재사용 가능한 함수를 만드는 방법 정리count(컬럼)은 NULL을 건너뜀. count(\*)은 NULL이 있는 행도 포함.주의: DISTINCT는 NULL이 있는 행을 제외하지 않는다. 모든 값이 NULL인 행도 "
Databricks - Spark SQL 1
Spark SQL로 파일 직접 쿼리하는 것부터 Delta 테이블 생성, 외부 소스 연결, 테이블에 쓰기 방법까지 한 번에 정리Databricks에서는 테이블을 만들지 않아도 파일을 바로 쿼리할 수 있다.경로는 반드시 백틱(\`) 으로 감싸야 한다. 작은따옴표가 아님에
Databricks - Delta Lake
오픈소스!🌟시간 여행스키마 진화데이터 변경에 따라 테이블 스키마가 자동으로 조정!스키마 강제입력되는 데이터가 정의된 스키마와 일치하는지 확인vacuum -> 7일 미만 데이터는 안지워줌
Databricks - MLflow, SDP(Spark 선언적 파이프라인)
18가지 조합을 다 돌려봤는데, 어떤 조합이 얼마나 좋았는지 기억할 방법이 없으면 곤란하잖아요.MLflow = 매 실험마다 파라미터, 결과, 모델을 자동으로 저장해주는 도구크게 세 군데예요.① 실험 공간 설정② 그리드 서치 중 매 조합마다 기록 (숫자 결과만)ALS_G
Databricks - 추천시스템
협업 필터링 VS 콘텐츠 기반 필터링비슷한 취향을 가진 사용자 집단 행동 패턴을 분석아이템 자체의 특성과 메타데이터 분석01 유사 사용자 탐색코사인 유사도, 피어슨 상관계수 등으로 비슷한 평점 패턴을 가진 유저 그룹 발견02 이웃 선정유사도 상위 K명의 이웃 사용자를
공부 방향 조언
11-12시 영상 보고 다시 정리DE에게 요구되는 능력치의외로 RAG를 할 줄 알면 플러스자격증 나열보다 '증거'를 만들어라수치가 들어간 엔드투엔드 프로젝트 1-2개 > 자격증10개자격증 공부할때 외우는건 맞지만 시간이 된다면 기초를 이해하고 가져가는게 자격증이 더 의
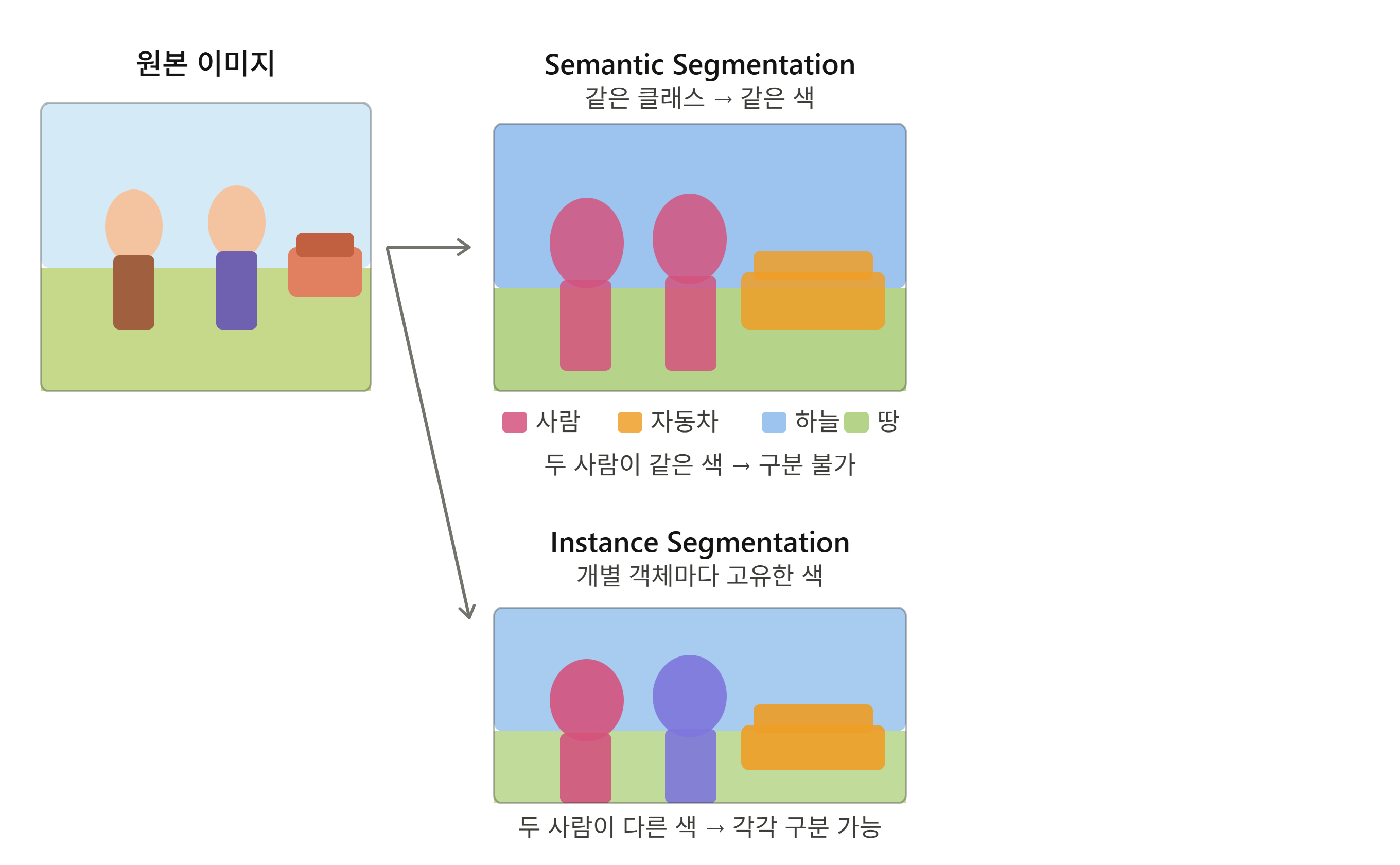
Databricks - 이미지 분류, Auto Loader
핵심 차이는 "개별 객체를 구분하느냐" Semantic Segmentation은 픽셀마다 "클래스"를 붙이는 것. 사람이 두 명 있어도 둘 다 person 레이블이 붙기 때문에 "어디에 사람이 있나"는 알지만 "몇 명인지, 어디서 어디까지가 한 명인지"는 모름.Inst

Databricks - Feature Store
<6월 15일 9-11시 학습한거 다시 보기>카탈로그 > 스키마 > 테이블에서 '계보(Lineage)' 탭에서 업스트림(원본), 다운스트림(활용처)Data lake: 온갖 다양한 원시 데이터를 저장하는 호수와 같은 공간<-> Data warehouse: 정형

Azure Databricks - 기초, AutoML
Notebook: 주피터 노트북 상위호환. 동시 수정과 sql, python, md 언어 동시에 한 문서에서 사용가능 (ex. %sql)카탈로그: 프로젝트(카탈로그)마다 스키마와 테이블을 생성하는 곳.
Azure AI 서비스 모음
단일 서비스 리소스로 독립 생성이 가능.최근에는 Azure AI Foundry (Foundry Tools) 산하로 편입되는 방향으로 가고 있음.OCR/Read손글씨도 인식하는데 단어 순서를 반대로 추출하기로 함... 가장 기본적인 text 추출Layout테이블, fig
[시각화] PowerBI에 Stream Analytics에 연결하는 법
Stream Analytics에 연결하는 법PowerBI 웹사이트에서 '작업 영역' > '+새 작업 영역'작업 영역 생성URL 중 박스 쳐진 부분(작업 영역 ID) 저장해두기Stream Analytics에서 Power BI를 출력으로 추가할 때, '그룹 작업 영역'에

[2026 Hult prize national] 심사위원 피드백
<404팀 - Aequalis 시각장애인을 위한 점역 통합 플랫폼 솔루션>피드백 정리✅ 잘 된 부분발표 앞부분의 논리 흐름이 좋았어. 문제 제기와 Why Now까지의 흐름이 설득력 있었고 첫인상이 좋았다는 평가를 받았어.다른 팀 적용: 발표 초반 문제 정의와 감정
ARM 템플릿: Azure 인프라를 코드로 관리하기
Azure 콘솔에서 리소스를 하나씩 클릭해서 만들어본 적 있으신가요?개발 환경 하나 세팅하는 데 30분씩 클릭하고,팀원한테 "나랑 똑같이 만들어줘" 하면 어딘가 하나씩 빠져있고,운영 환경에 같은 구성을 다시 만들려니 뭘 먼저 만들었는지도 기억이 안 납니다.ARM 템플릿