
Published in NIPS 2021
[요약]
-
MLP만 사용해서 transformer 기반 SOTA 급의 성능을 가진 모델 제안
-
성능을 다소 포기하고 확장성과 computational cost 측면에서 큰 이득을 취함
[서론]
0. Abstract
MLP만 사용해서 SOTA 급의 성능을 가진 모델을 만들어 낸 논문입니다. 이미지를 여러 patch로 쪼개고 2개의 MLP block을 이용해 학습시키는 방법을 사용했는데, 일종의 다차원 cnn처럼 작동하는 구조입니다. computational cost가 적고 구현이 간단한데 확장성이 좋아서 여기저기 가져다 쓰기 좋습니다.
(1) 토큰 방향으로 MLP를 적용 (Location feature mixing)
(2) 채널 방향으로 MLP를 적용 (Spatial information mixing)
Universial Approximation Theorem에 따라 MLP만으로도 transformer 기반 모델과 비슷하거나 그 이상의 성능을 낼 수 있다는 건 알 수 있지만, 실제로 그런 구조를 만들어 내는 것은 여간 어려운 일이 아니죠. 개인적으로 직관의 중요성을 새삼 상기시켜 주는 좋은 논문이라고 생각합니다.
1. Introduction
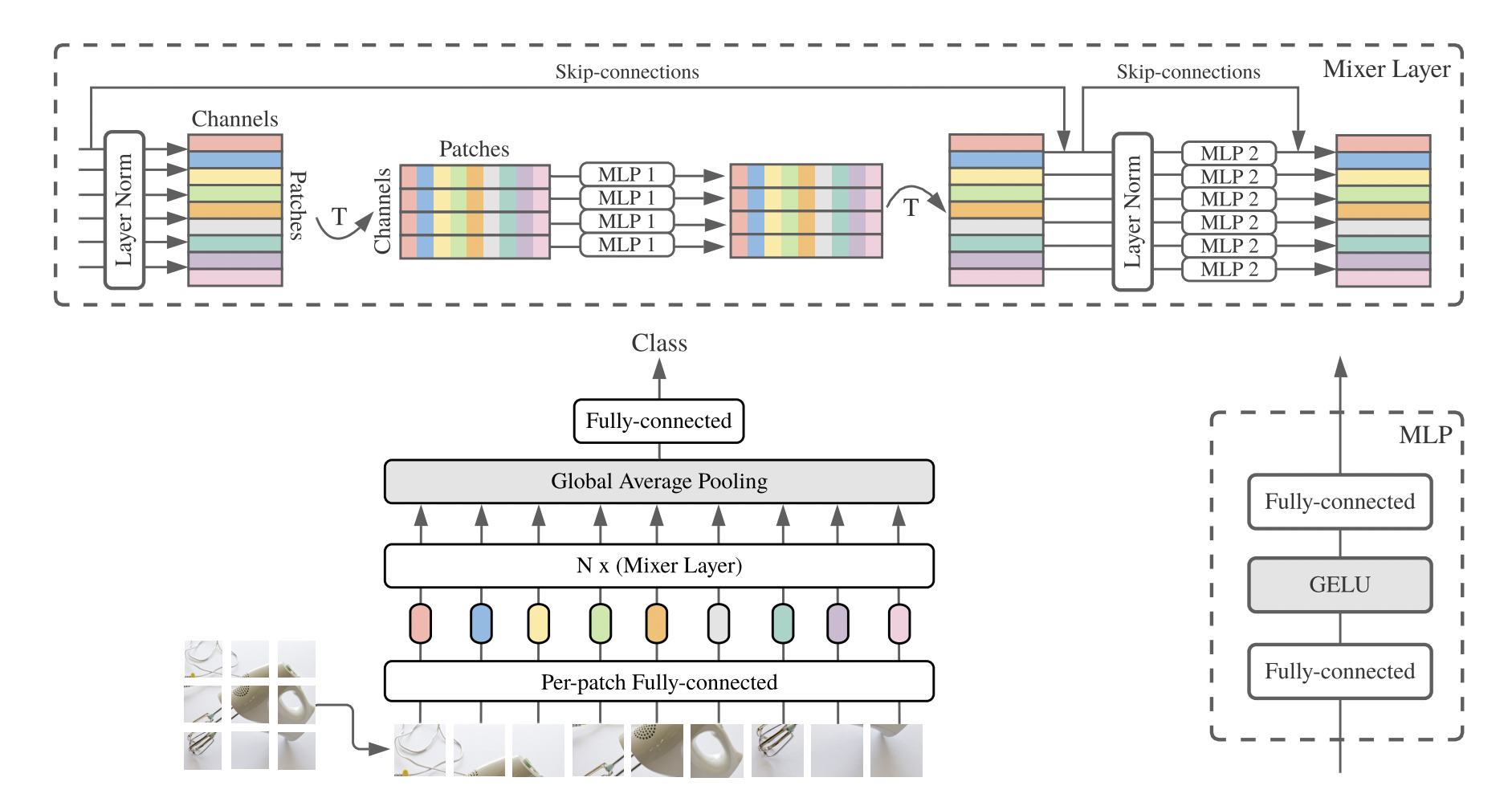
전체 모델의 구조입니다.
논문에서는 이미지를 조각낸 patch 단위를 token이라고 부릅니다. 먼저 토큰별로 MLP를 적용한 후(Token-Mixing MLPs), 이미지 채널별로 MLP를 하나씩 적용합니다(Channel-Mixing MLPs). Channel-Mixing MLPs는 각 채널끼리의 정보를 통합한 feature map을 생성합니다. 반대로 Token-Mixing MLPs는 각 토큰들의 정보를 통합한 feature map을 생성합니다.
[본론]
2. Mixer Architecture
현존하는 비전 모델들은 대부분 feature mixing 기능을 가지고 있습니다. Spatial location information을 capture하는 module(layer) 여러 개가 있고, 각각의 module(layer)에서 얻은 정보를 합쳐서 사용한다는 의미입니다. 예를 들어 CNN은 크기의 필터로 local information을 모아서 더 고차원의 정보를 내포하는 feature map으로 변환하죠.
MLP Mixer도 이런 기능에 초점을 두고 있습니다. 구체적으로는 per location하게 정보를 얻는 channel mixing mlps, cross location 하게 정보를 얻는 token mixing mlps를 사용해서 local information을 capture합니다.
모델 알고리즘은 다음과 같습니다.
-
크기의 이미지를 크기를 갖는 개의 patches로 변환합니다.
-
크기를 갖는 개의 patch들을 차원의 벡터들로 변환합니다. 는 임의로 지정한 hidden dimension 크기입니다.
-
결과적으로 input data는 차원을 가진 개의 patches로 이루어진 임베딩 테이블 가 됩니다.
-
token-mixing MLP block channel-mixing MLP block 순으로 데이터를 처리합니다. 각 block은 2개의 FC layer로 구성돼 있으며, 두 block을 묶어서 하나의 레이어로 취급합니다.
수식으로 나타내면 아래와 같습니다.
는 GELU activation function을 사용합니다.
Token mixing mlp와 channel mixing mlp의 width 는 input patch 수에 영향을 받지 않기 때문에 computational complexity가 ViT처럼 제곱으로 증가하지 않습니다. 오히려 CNN처럼 linear한 complexity를 갖습니다.
Token mixing MLP
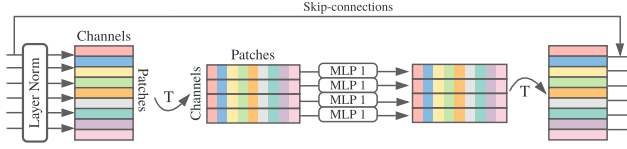
Token / Channel mixing MLP block은 동일한 MLP layer를 사용합니다.
input data 에 대해,
-
transpose 작업을 진행합니다.
-
LayerNorm을 진행합니다.
-
각 token 마다 MLP block을 통과시킵니다.
-
output을 transpose합니다.
-
skip connection을 진행합니다.
Channel mixing MLP
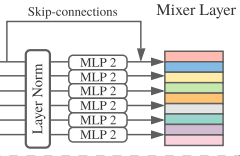
Channel mixing MLP의 경우 transpose 과정이 없습니다.
input data 에 대해,
-
LayerNorm을 진행합니다.
-
각 채널 마다 MLP block을 통과시킵니다.
-
skip connection을 적용합니다.
Advantages of MLP mixer
Channel mixing mlp의 경우 레이어간 가중치를 공유(parameter tying)하기 때문에 CNN처럼 positional invariant한 특성을 갖습니다. 하나의 레이어를 channel-wise하게 적용한다는 의미입니다. 가중치를 공유하면 hidden dim 또는 sequential length 가 증가한다고 해서 파라미터 수가 급격하게 늘어나지 않으므로 메모리를 절약할 수 있습니다.
사실 이미지 데이터의 채널은 각각 다른 정보를 포함한다는 것이 기본적인 전제 중 하나라는 점을 생각하면 channel-wise하게 가중치를 공유하는 레이어의 성능에 대한 의문이 들 수 있습니다. 하지만 논문에서는 실험 결과 parameter tying 여부는 성능에 큰 영향이 없었다고 합니다.
아마도 conv layer를 피라미드식으로 쌓아서 depth wise한 정보를 전달하는 CNN과 달리 token mixing mlp를 통해 이미 채널 간의 데이터를 어느 정도 반영해주었기 때문이 아닌가 싶네요.
Token mixing mlp는 input tokens의 순서에 민감하기 때문에 transformer 계열처럼 별도의 positional embedding이 필요 없는 것도 장점입니다. 모든 레이어가 동일한 크기의 입력을 받는 isotropic한 구조로 되어 있어 확장성도 뛰어납니다. 사실상 tensor나 matrix 형태의 데이터에는 거의 다 적용할 수 있습니다.
3. Experiments
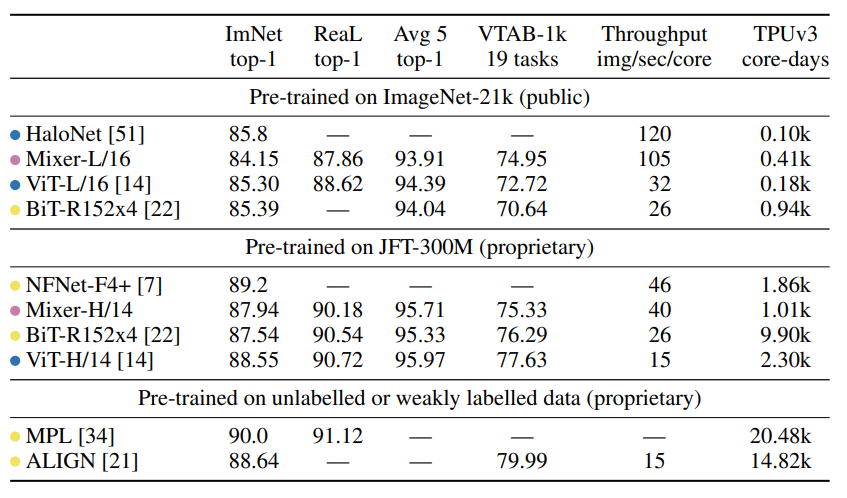
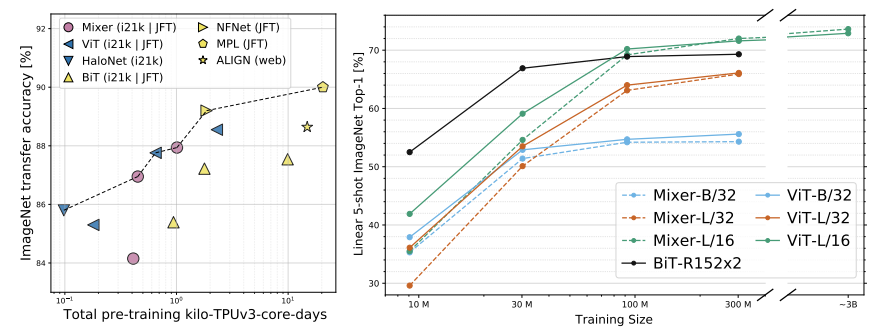
실험 결과입니다.
Vision 계열의 논문이다보니 주로 ViT와 비교하는데 성능 자체는 확실히 mlp mixer가 밀리는 감이 있습니다. 평가 기준도 주로 classification에 치중되어 있어서 다른 분야에 적용할 때에는 간단한 poc 실험을 해 보는 것이 좋습니다.
참고문헌
