정규표현식을 알아두면 쓸모가 많다. (특히 NLP에서)
모든 데이터가 전부 숫자로 만들어진 정형 데이터는 아니니까...
Regular expression
정규표현식 모듈
re| Doc
기본적으로 정규표현식은
1) 검색할 문자열의 패턴을 정의하고
2) 찾아서 처리하는
식으로 이루어진다.
파이썬에서는 표준 라이브러리 기능으로 제공한다.
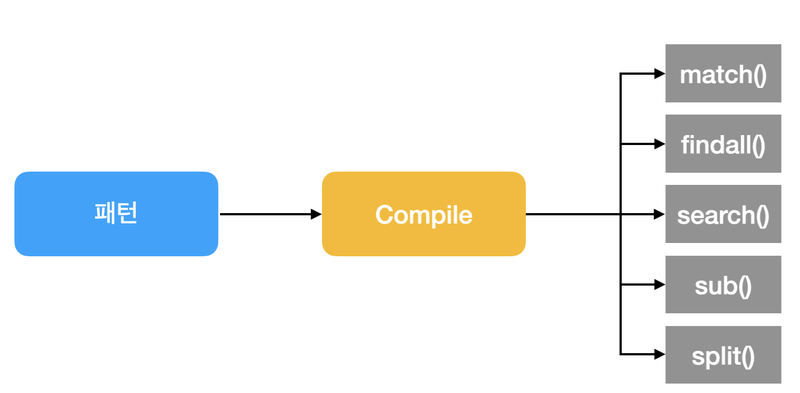
compile
# "the"라는 패턴을 컴파일한 후 패턴 객체를 리턴
pattern = re.compile("the")
# 컴파일된 패턴 객체를 활용하여 다른 텍스트에서 검색을 수행
pattern.findall('of the people, for the people, by the people')파이썬은 당연히(?) 자동 컴파일을 지원한다.
# 컴파일 명시 안해도 작동함
re.findall('the', 'of the people, for the people, by the people')물론 컴파일해서 객체를 명시해두면 재사용할때 편하다.
method
| 자주 쓰는 메소드 | 내용 |
|---|---|
| search() | 일치하는 패턴 검색 (일치하는 패턴이 있으면 MatchObject 반환) |
| match() | 일치하는 패턴 검색 (처음부터 패턴이 검색 대상과 일치해야 함) |
| findall() | 일치하는 모든 패턴 찾기 (모든 일치 패턴을 리스트에 담아서 반환) |
| split() | 패턴으로 나누기 |
| sub() | 일치하는 패턴으로 대체하기 |
특정 메소드로 리턴받은 MatchObject는 다음의 메소드를 가지고 있다.
group() : 실제 결과에 해당하는 문자열을 반환
import re
src = "My name is..."
regex = re.match("My", src)
print(regex)
if regex:
print(regex.group())
else:
print("No!")메타 문자 (특수 문자)
| 문자 | 내용 |
|---|---|
| [ ] | 문자 |
| - | 범위 |
| . | 하나의 문자 |
| ? | 0회 또는 1회 반복 |
| * | 0회 이상 반복 |
| + | 1회 이상 반복 |
| {m, n} | m ~ n |
| \d | 숫자, [0-9]와 동일 |
| \D | 비 숫자, [^0-9]와 동일 |
| \w | 알파벳 문자 + 숫자 + , [a-zA-Z0-9]와 동일 |
| \W | 비 알파벳 문자 + 비숫자, [^a-zA-Z0-9_]와 동일 |
| \s | 공백 문자, [ \t\n\r\f\v]와 동일 |
| \S | 비 공백 문자, [^ \t\n\r\f\v]와 동일 |
| \b | 단어 경계 |
| \B | 비 단어 경계 |
| \t | 가로 탭(tab) |
| \v | 세로 탭(vertical tab) |
| \f | 폼 피드 |
| \n | 라인 피드(개행문자) |
| \r | 캐리지 리턴(원시 문자열) |
#- 연도(숫자)
text = """
The first season of America Premiere League was played in 1993.
The second season was played in 1995 in South Africa.
Last season was played in 2019 and won by Chennai Super Kings (CSK).
CSK won the title in 2000 and 2002 as well.
Mumbai Indians (MI) has also won the title 3 times in 2013, 2015 and 2017.
"""
pattern = re.compile("[1-2]\d\d\d")
pattern.findall(text)
>>> ['1993', '1995', '2019', '2000', '2002', '2013', '2015', '2017']
#- 전화번호(숫자, 기호)
phonenumber = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
phone = phonenumber.search('This is my phone number 010-111-1111')
if phone:
print(phone.group())
print('------')
phone = phonenumber.match ('This is my phone number 010-111-1111')
if phone:
print(phone.group())
>>> 010-111-1111
#- 이메일(알파벳, 숫자, 기호)
text = "My e-mail adress is doingharu@aiffel.com, and tomorrow@aiffel.com"
pattern = re.compile("[0-9a-zA-Z]+@[0-9a-z]+\.[0-9a-z]+")
pattern.findall(text)
>>> ['doingharu@aiffel.com', 'tomorrow@aiffel.com']
------

재미있게 살고 싶은 대학원생