REINFORCE 알고리즘과 TRPO 알고리즘을 공부하였다.
두 알고리즘을 비롯하여 다양한 알고리즘에서 비슷한 요소를 발견해서 비교 분석을 해보았다.
갱신 규칙
REINFORCE 갱신 규칙
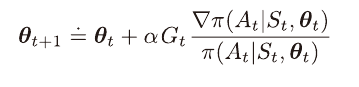
TRPO 갱신 규칙
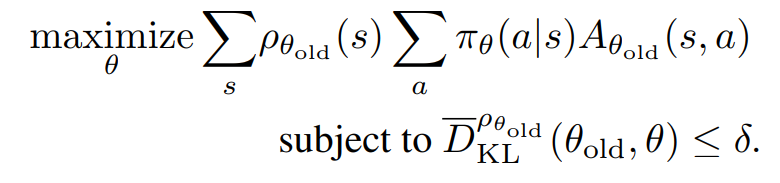
이때 실전에 적용할때에는 아래와 같은 수식을 이용한다.
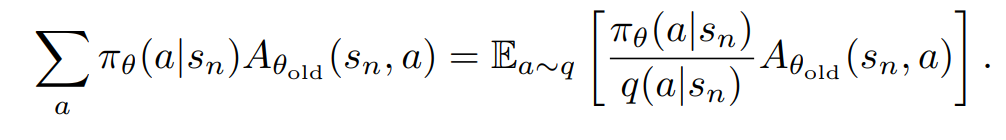
REINFORCE 갱신 규칙과 유사한 항이 존재한다.
두 항 모두 가치 혹은 advantage값이 큰 행동을 선택할 확률을 높이는 역할을 한다.
REINFORCE 알고리즘은 가치함수를 사용하여
가치가 큰 행동의 확률의 증가량이 가치가 작은 행동보다 높도록 하여 학습이 진행되고,
TRPO 알고리즘은 advantage funtion을 사용하여
advantage 값이 양수인 행동이 선택 될 확률은 높이며, 음수인 행동이 선택 될 확률은 줄이며 학습이 진행된다.
두 알고리즘 모두 증가량이 취해진 행동이 선택될 확률과는 반비례하도록 하는 공통점이 있다.
전개 과정
REINFORCE 알고리즘은 성능지표가 증가하는 방향으로 경사도를 계산하는 아이디어이다.
TRPO 알고리즘은 두 정책 사이의 관계를 나타내는 수식을 이용하며
이 값이 커지는 방향으로 경사도를 계산하는 아이디어이다.
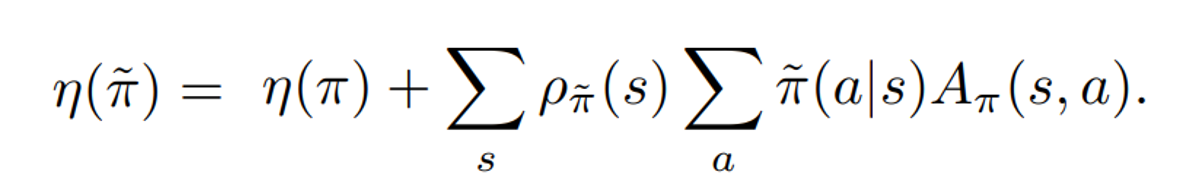
이때 계산의 편의를 위해 다음과 같이 수정된 수식을 사용한다.
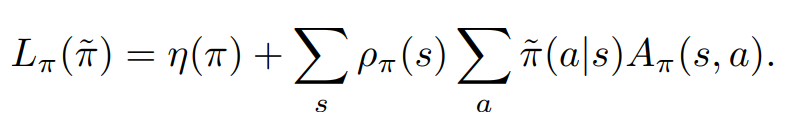
TRPO에서는 수식을 수정했음에도 불구하고 REINFORCE 알고리즘과 유사하다는 점이 신기했다.
TRPO에서는 정책 성능 향상의 보장을 위해 두 정책간의 거리, 변화량 개념을 명확히 하였다.
하지만 REINFORCE 알고리즘은 단순히 정책 성능이 향상하는 방향의 경사도를 계산하였다.
이때는 바뀌기 전 후 정책의 차이를 고려할 필요가 없기 때문에
이때의 수식이 TRPO에서는 수정한 수식과 같기 때문인듯 하다.
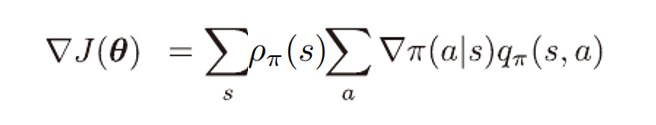
이를 보니 TRPO에서 설명한 두 정책이 같을때에는 η와 L이 같고,
충분히 작은 step 에서는 L의 증가가 η의 증가를 암시한다는 점이 훨씬 와닿는것 같다.
