Image Segmentation 모델인 SegFormer 모델 구조에 대해서 공부해 보았다.

Image segmentation을 거치면 다음과 같은 이미지를 얻게 되며,
어떻게 보면 Image segmentation은 픽셀단위로 Image classfication 하는 작업이라고 이해하면 되겠다.
SegFormer의 구조
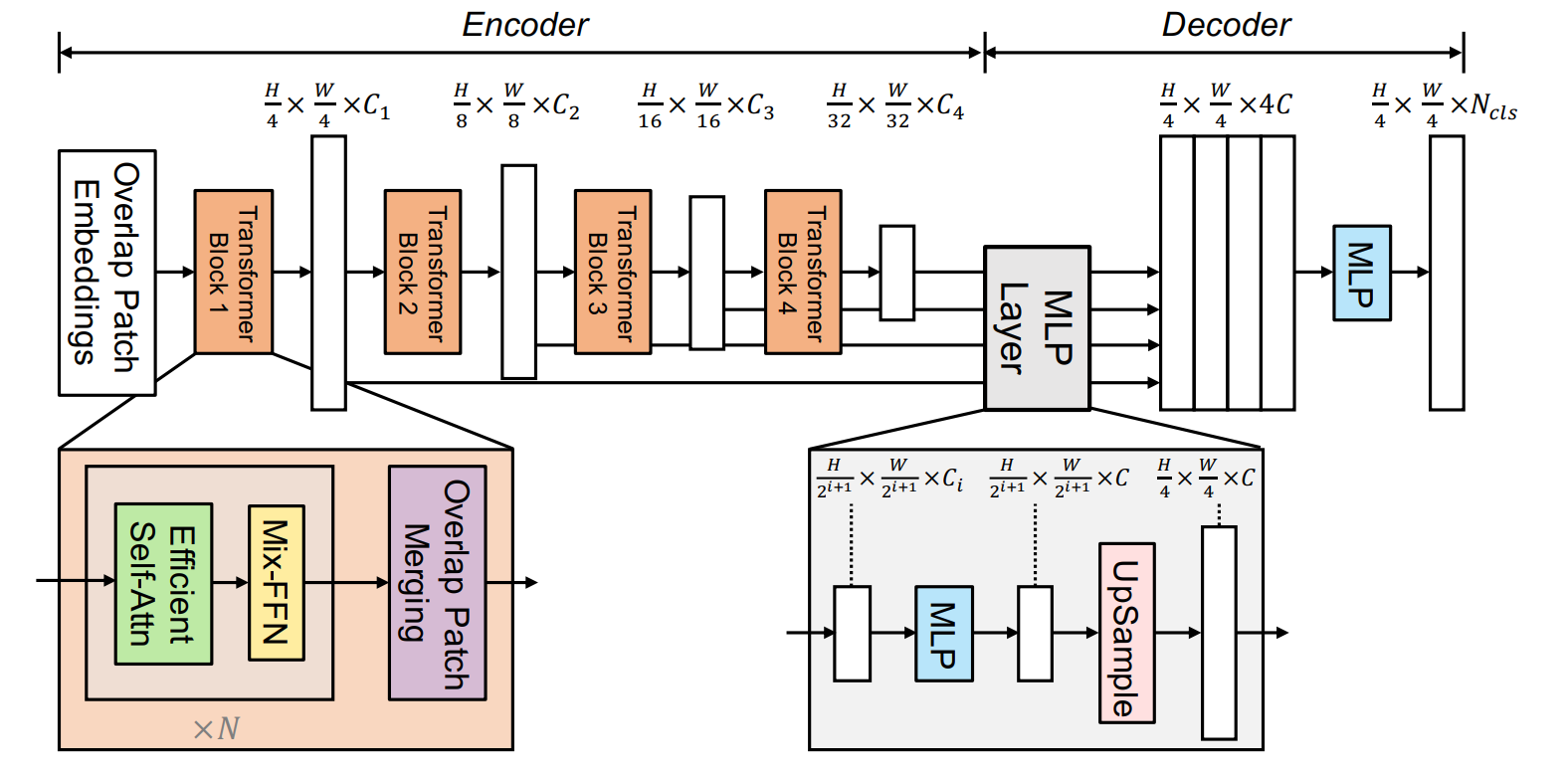
3 Method
전체적인 구조는 다음과 같다.
이미지를 인코더를 통해 원본 이미지 resolution의 1/4, 1/8, 1/16, 1/32에 해당하는 multi-level features를 구하게 된다고 한다.
위 모델 구조를 보게 되면 Transformer Block을 지난 뒤, 복사를 해서 하나는 다음 Transformer Block으로, 하나는 바로 Decoder로 향하는 것을 볼 수 있다.
Transforemer Block 내부에 Overlab Patch Merging을 통해 feature level이 감소하는 것으로 보이며,(뒷 부분에 설명)
결국 디코더는 원본 이미지 resolution의 1/4, 1/8, 1/16, 1/32에 해당하는 multi-level features를 입력받게 된다.
디코더를 통과하여 다음과 같은 크기의 텐서를 반환한다.
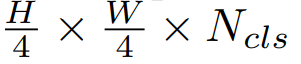
Ncls는 카테고리의 개수이다.
픽셀단위로 Image classfication을 하는 작업이기 때문에 다음과 같은 shape의 텐서를 반환하게 된다.
3.1 Hierarchical Transformer Encoder
SegFormer의 인코더가 high-resolution coarse features와 low-resolution fine-grained features를 포착한다고 한다.
이게 무슨소리냐 하면
CNN의 아키텍쳐를 보면 다음과 같은 사진을 많이 볼 수 있을것이다.
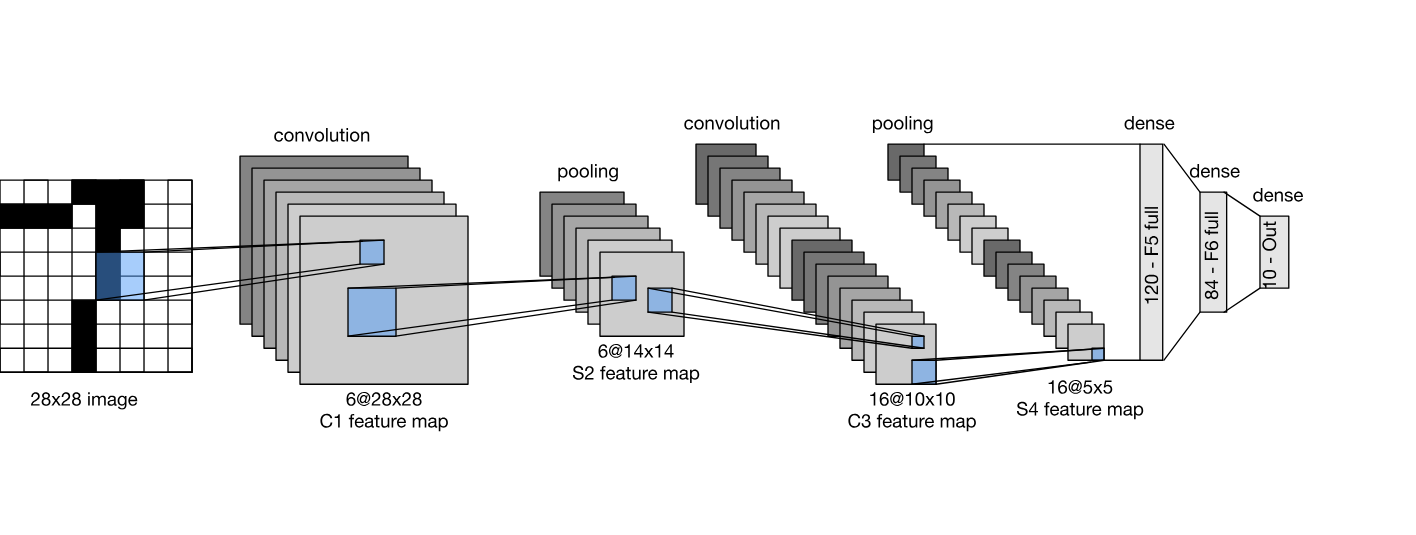
layer의 앞부분에서는 high-resolution coarse하며,
뒷부분으로 갈 수록 low-resolution fine-grained하다고 보면 된다.
위 모델 구조와 같이 4개를 모아서 디코더에 넣어준다고 보면 되며,
딱 봐도 local한, global한 부분을 모두 고려하기 좋은 구조처럼 느껴진다.
Overlapped Patch Merging
Convolution의 stride사이즈를 4나 2같은 크기로 하게 되면 사이즈가 줄어들게 된다.
이 논문에서는 K = 7, S = 4, P = 3와 K = 3, S = 2, P = 1를 사용했다고 한다.(Kernel, Stride Padding)
위에서 말한 '원본 이미지의 1/4, 1/8, 1/16, 1/32'과 맞아떨어진다.
3.2 Lightweight All-MLP Decoder
SegFormer는 MLP(Multilayer Perceptron)모듈만을 이용한 디코더를 사용한다고 하며, 다음과 같은 step으로 설명된다고 한다.
-
multi-level features가 MLP layer를 통과한다.
-
upsampling을 거친 뒤 concatenate된다.
-
두 개의 MLP layer통과하여 다음과 같은 텐서를 반환한다. (그림에서는 한개인디 생략했나 봄)
Test
Hugging face에서 SegFormer를 불러오고 테스트할 수 있는 코드이다.
from transformers import SegformerImageProcessor, AutoModelForSemanticSegmentation
from PIL import Image
import requests
import matplotlib.pyplot as plt
import torch.nn as nn
processor = SegformerImageProcessor.from_pretrained("mattmdjaga/segformer_b2_clothes")
model = AutoModelForSemanticSegmentation.from_pretrained("mattmdjaga/segformer_b2_clothes")
url = "https://plus.unsplash.com/premium_photo-1673210886161-bfcc40f54d1f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8MXx8cGVyc29uJTIwc3RhbmRpbmd8ZW58MHx8MHx8&w=1000&q=80"
image = Image.open(requests.get(url, stream=True).raw)
plt.imshow(image)
plt.show()
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits.cpu()
upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1],
mode="bilinear",
align_corners=False,
)
pred_seg = upsampled_logits.argmax(dim=1)[0]
plt.imshow(pred_seg)
