colab : https://colab.research.google.com/drive/1YOSvu-INmjxNVYTS8-eB4QPyj7Ge1nyZ?usp=sharing
github : https://github.com/nalinzip/ml_study/blob/main/ML_week3.ipynb
- 머신러닝은 데이터 가공, 모델 학습/예측, 평가 프로세스로 구성
- 타이타닉 예제에서 정확도(Accuracy) 로 모델 성능 평가
성능 평가 지표는 분류와 회귀로 나뉨 - 회귀는 예측값과 실제값의 오차를 기반으로 평가
- 분류는 실제 결과와 예측 결과의 정확도를 기준으로 평가
- 이진 분류에서는 정확도보다는 다른 평가 지표가 중요함.
분류의 성능 평가 지표
- 정확도 (Accuracy)
- 오차행렬 (Confusion Matrix)
- 정밀도 (Precision)
- 재현율 (Recall)
- F1 스코어
- ROC AUC
분류
- 이진 분류
- 멀티 분류
성능 지표는 이진/멀티 분류 모두에 적용되지만, 이진 분류에서 더욱 중요함
1. 정확도 (Accuracy)
정확도란
정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표임.
정확도 (Accuracy) = 예측 결과가 동일한 데이터 건수 / 전체 예측 데이터 건수
- 정확도는 모델 예측 성능을 직관적으로 나타내는 평가 지표로, 맞춘 예측의 비율을 의미.
- 단, 이진 분류에서는 데이터 구성에 따라 정확도 수치만으로 성능을 평가하는 것이 부적절할 수도 있음.
- 예) 타이타닉 데이터에서 성별에 따라 생존 확률이 달라지므로, 성별만으로 생존 여부를 예측해도 높은 정확도를 얻을 수 있음. 예를 들어, 여자가 남자보다 생존 확률이 높다면, 성별을 기준으로 "여자"는 생존, "남자"는 사망으로 예측해도 높은 정확도가 나올 수 있음.
- 이와 같은 방식은 실제로 알고리즘이 학습을 하지 않고 성별만으로 예측하는 방식으로, 이는 모델의 진정한 성능을 반영하지 못함.
- BaseEstimator 클래스를 사용해 학습을 하지 않고 성별에 따라 생존 여부를 예측하는 단순한 Classifier클래스 를 만들 수 있음. 이 클래스는
fit()메서드를 사용하지 않으며,predict()메서드는 성별 피처만을 바탕으로 예측을 수행하는 방식. - 예) 정확도 지표가 어떻게 모델의 실제 성능을 왜곡할 수 있는지 보여주는 중요한 사례로, 정확도 외의 다른 평가 지표가 필요함을 강조.
from sklearn.base import BaseEstimator
class MyDummyClassifier(BaseEstimator):
# fit( ) 메서드는 아무것도 학습하지 않음.
def fit(self, X, y=None):
pass
# predict() 메서드는 단순히 Sex 피처가 1 이면 0, 그렇지 않으면 1 로 예측함.
def predict(self, X):
pred = np.zeros(( X.shape[0], 1))
for i in range (X. shape [0]) :
if X['Sex'].iloc[i] == 1: # iloc should use the current loop index i
pred[i] = 0
else:
pred[i] = 1
return predClassifier 를 이용해 학습/예측/평가를 적용
- 생성된
MyDummyClassifier를 이용해 앞 장의 타이타닉 생존자 예측을 수행해보기 - 타이타닉 데이터인 titanic_train.csv 파일을 새로운 주피터 노트북을 생성한 디렉터리로 복사해 이동하기
- 데이터를 가공하기
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 원본 데이터를 재로딩 , 데이터 가공 , 학습 데이터 / 테스트 데이터 분할.
titanic_df = pd.read_csv('sample_data/train.csv')
y_titanic_df = titanic_df ['Survived']
X_titanic_df= titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test=train_test_split(X_titanic_df, y_titanic_df,
test_size=0.2, random_state=0)
# 위에서 생성한 Dummy Classifier를 이용해 학습 / 예측 / 평가 수행.
myclf = MyDummyClassifier()
myclf.fit(X_train, y_train)
mypredictions = myclf.predict(X_test)
print('Dummy Classifier 의 정확도: {0:.4f}'.format(accuracy_score(y_test, mypredictions)))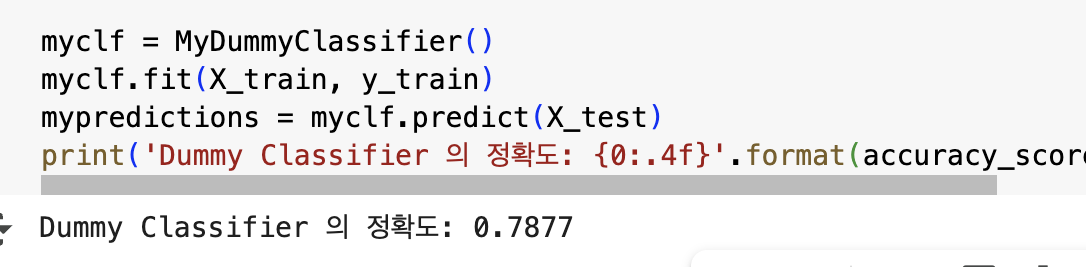
- 단순한 알고리즘으로 예측하더라도 데이터 구성에 따라 정확도가 78.77%처럼 높은 수치가 나올 수 있음. -> 정확도를 평가 지표로 사용할 때는 매우 신중해야 함!
- 정확도는 불균형한(imbalanced) 레이블 값 분포에서 모델 성능을 평가하기에 적합하지 않음.
- 예) 100개의 데이터 중 90개는 레이블 0, 10개는 레이블 1인 경우, 모델이 모두 0으로 예측해도 정확도는 90%가 될 수 있음.
- MNIST 데이터를 변형해 불균형한 데이터셋을 만들면 정확도가 잘못된 평가 지표로 작용할 수 있음을 알 수 있음.
- MNIST 데이터셋을 7을 True, 나머지를 False로 변환해 이진 분류 문제로 바꾸면, 90%의 데이터가 False가 되어 정확도가 왜곡됨.
MNIST 데이터셋을 multi classification에서 binary classification으로 변경

- 이렇게 불균형한 데이터 세트에 모든 데이터를 False
- 즉, 0 으로 예측하는 classifier 를 이용해 정확도를 측정하면 약 90% 에 가까운 예측 정확도를 나타냄
- 아무것도 하지 않고 무조건 특정한 결과로 찍어도 (?) 데이터 분포도가 균일하지 않은 경우 높은 수치가 나타날 수 있는 것이 정확도 평가 지표의 맹점
임 - 먼저 불균형한 데이터 세트와 Dummy Classifier 를 생성함
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
class MyFakeClassifier(BaseEstimator):
def fit(self, X, y):
pass
# 입력값으로 들어오는 X 데이터 세트의 크기만큼 모두 0 값으로 만들어서 반환
def predict(self, X):
return np.zeros( (len(X), 1), dtype=bool)
# 사이킷런의 내장 데이터 세트인 load_digits( ) 를 이용해 MNIST 데이터 로딩
digits = load_digits()
# digits 번호가 7 번이면 True 이고 이를 astype(int)로 1 로 변환 , 7 번이 아니면 False 이고 0 으로 변환.
y = (digits.target == 7).astype(int)
X_train, X_test, y_train, y_test = train_test_split(digits.data, y, random_state=11)다음으로 불균형한 데이터로 생성한 y_test의 데이터 분포도를 확인하고 MyFakeClassifier 를 이용해 예측과 평가를 수행해 보기
# 불균형한 레이블 데이터 분포도 확인.
print('레이블 테스트 세트 크기 :', y_test.shape)
print('테스트 세트 레이블 0 과 1 의 분포도 ')
print(pd.Series(y_test).value_counts())
# Dummy Classifier로 학습 / 예측 / 정확도 평가
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train, y_train)
fakepred = fakeclf.predict(X_test)
print('모든 예측을 0 으로 하여도 정확도는 :{:.3f}'.format(accuracy_score(y_test, fakepred)))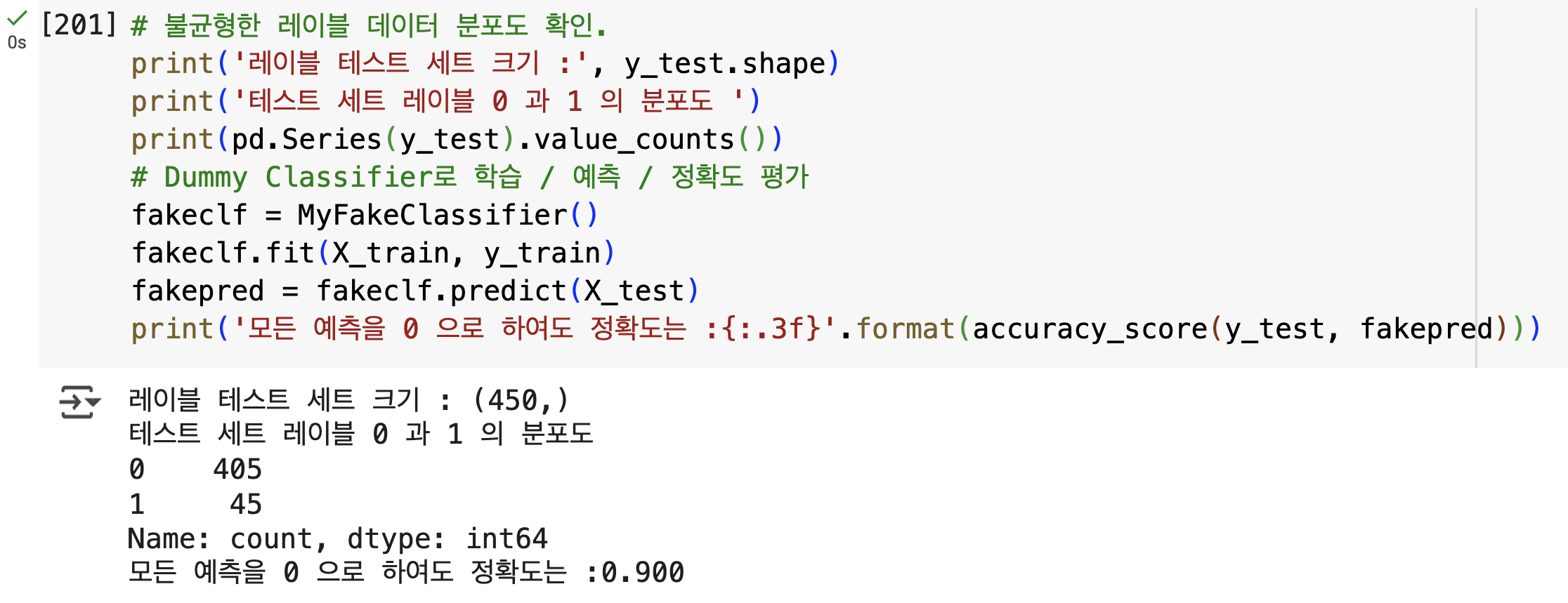
-단순히 predict()의 결과를 np.zeros()로 모두 0 값으로 반환함에도 불구하고 450 개의 테스트 데이터 세트에 수행한 예측 정확도는 90% 입니다.
- 단지 모든 것을 0 으로만 예측해도
MyFakeClassifier의
정확도가 90% 로 유수의 ML 알고리즘과 어깨를 겨룰 수 있다는 것은 말도 안 되는 결과입니다. - 이처럼 정확도 평가 지표는 불균형한 레이블 데이터 세트에서는 성능 수치로 사용돼서는 안 됩니다.
- 정확도가 가지는 분류 평가 지표로서 이러한 한계점을 극복하기 위해 여러 가지 분류 지표와 함께 적용하여 ML 모델 성능을 평가해야 함.
2. 오차 행렬
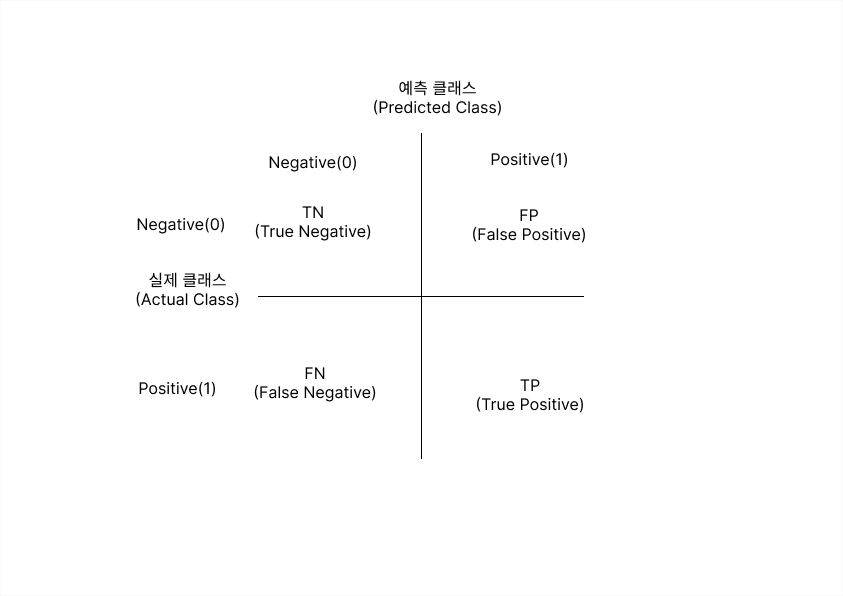
- 오차 행렬(confusion matrix, 혼동행렬)은 이진 분류에서 성능 지표로 사용되며, 모델이 예측을 수행하면서 얼마나 혼동(confused)되는지를 보여주는 지표임.
- 이 지표는 예측 오류, 어떤 유형의 예측 오류가 발생하는지도 함께 나타냄.
- 4분면 행렬에서 실제 레이블 클래스 값과 예측 레이블 클래스 값이 어떠한 유형을 가지고 매핑되는지를 나타냄.
- 4분면의 왼쪽, 오른쪽은 예측된 클래스 값 기준으로 Negative와 Positive로 분류됨
- 위, 아래는 실제 클래스 값 기준으로 Negative와 Positive로 분류됨.
- 오차 행렬의 4분면은 TN, FP, FN, TP로 채워지며, 이를 통해 예측 성능의 오류 유형 을 알 수 있음.
TN, FP, FN, TP는 예측 클래스와 실제 클래스의 Positive(1)와 Negative(0) 결정 값의 결합에 따라 결정됨.
-
TN 는 예측값을 Negative 값 0 으로 예측했고 실제 값 역시 Negative 값 0
-
FP 는 예측값을 Positive 값 1 로 예측했는데 실제 값은 Negative 값 0
-
FN 은 예측값을 Negative값 0 으로 예측했는데 실제 값은 Positive 값 1
-
TP 는 예측값을 Positive값 1 로 예측했는데 실제 값 역시 Positive 값 1
-
앞의 True/False는 예측값과 실제값이 '같은가/틀린가'를 의미하고, 뒤의 Negative/Positive는 예측값이 부정(0) 또는 긍정(1)을 의미.

- Scikit-learn 오차 행렬을 구하기 위해
confusion_matrix()API 를 제공. - 정확도 예제에서 다룬
MyFakeClassifier의 예측 성능 지표를 오차 행렬로 표현해 볼 예정임. - MyFakeClassifier 의 예측 결과인
fakepred와 실제 결과인y_test를confusion_matrix()의 인자로 입력해 오차 행렬을confusion_matrix()를 이용해 배열 형태로 출력
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, fakepred)
- 출력된 오차 행렬은 ndarray 형태로, 이진 분류의 TN, FP, FN, TP 값은 배열에서 특정 위치로 가져올 수 있음.
- 예) TN은 array[0,0]으로 405, FP는 array[0,1]으로 0, FN은 array[1,0]으로 45, TP는 array[1,1]으로 0.
- MyFakeClassifier는
load_digits()에서 target == 7인지 여부에 따라 이진 분류로 데이터를 변경하고, 무조건 Negative(0)로 예측하는 분류기. - 테스트 데이터의 클래스 분포는 0이 405건, 1이 45건.
- 따라서 TN은 405건, FP는 0건, FN은 45건, TP는 0건.
- TN, FP, FN, TP 값은 모델 성능을 평가할 수 있는 기반 정보를 제공하며, 이를 조합해 정확도(Accuracy), 정밀도(Precision), 재현율(Recall) 등을 계산할 수 있음.
- 정확도는 예측값과 실제 값이 얼마나 동일한지 비율로 결정되며, 오차 행렬에서 TN과 TP에 의해 좌우됨.

정확도 = 예측 결과와 실제 값이 동일한 건수 / 전체 데이터 수 = (TN + TP)/(TN + FP + FN + TP)
- 불균형한 레이블 클래스를 가진 이진 분류 모델에서는 적은 수의 Positive 값을 1로 설정하고, 나머지는 Negative 값을 0으로 설정하는 경우가 많음.
- 예: 사기 예측 모델에서는 사기가 Positive(1), 정상 행위가 Negative(0), 암 검진에서는 암이 Positive(1), 암이 없는 경우 Negative(0).
- 불균형한 데이터 세트에서는 Positive 데이터가 매우 적기 때문에 모델은 Negative로 예측하는 경향이 강해짐.
- 예시: 10,000건 데이터 중 9,900건은 Negative, 100건은 Positive라면, 모델은 대부분 Negative(0)로 예측해 TN은 커지고 TP는 작아짐.
- 이 경우 FN와 FP는 작아짐.
- 정확도는 불균형한 데이터 세트에서 Negative 예측 정확도만 높게 나와서, Positive 예측 정확도는 제대로 평가되지 않음.
- 이로 인해 정확도만으로는 모델의 실제 성능을 제대로 평가할 수 없으며, 수치적인 판단 오류가 발생할 수 있음.
- 정확도는 모델 성능을 측정하는 하나의 지표일 뿐이며, 불균형한 데이터 세트에서는 정밀도(Precision)와 재현율(Recall)이 더 중요한 평가 지표로 선호됨.
3. 정밀도와 재현율
- 정밀도와 재현율은 Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표입니다.
- 앞서 만든 MyFakeClassifier 는 Positive로 예측한 TP 값이 하나도 없기 때문에 정밀도와 재현율 값이 모두 0 임.
정밀도와 재현율은 계산 (공식)
정밀도 = TP / (FP + TP)
재현율 = TP / (FN + TP)
정밀도(Precision)는 예측을 Positive로 한 대상 중에서 실제 값도 Positive인 데이터의 비율.
- 공식에서 FP + TP는 예측을 Positive로 한 모든 데이터 건수, TP는 예측과 실제 값이 Positive로 일치한 데이터 건수.
- 정밀도는 양성 예측도라고도 불림.
재현율(Recall)은 실제 값이 Positive인 대상 중에서 예측과 실제 값이 Positive로 일치한 데이터의 비율.
- 공식에서 FN + TP는 실제 값이 Positive인 모든 데이터 건수, TP는 예측과 실제 값이 Positive로 일치한 데이터 건수.
- 재현율은 민감도(Sensitivity) 또는 TPR(True Positive Rate)라고도 불림.
정밀도(Precision)와 재현율(Recall) 중 어떤 지표가 더 중요한지는 이진 분류 모델의 업무 특성에 따라 다름.
재현율이 중요한 경우: 재현율이 중요 지표인 경우는 실제 Positive 양성 데이터를 Negative 로 잘못 판
단하게 되면 업무상 큰 영향이 발생하는 경우입니다.
예: 암 진단 모델
- 실제 Positive인 암 환자를 Positive 양성이 아닌 Negative 음성으로 잘못 판단했을 경우
- 반면에 실제 Negative인 건강한 환자를 암 환자인 Positive 로 예측한 경우면 다시 한번 재검사를 하는 수준의 비용이 소모될 것임
- 재현율 중요함
예: 보험/금융 사기 탐지
- 실제 금융거래 사기인 Positive 건을 Negative 로 잘못 판단하게 되면 회사에 미치는 손해가 큼.
- 반면에 정상 금융거래인 Negative 를 금융사기인 Positive로 잘못 판단하더라도 다시 한번 금융 사기인지 재확인하는 절차를 가동하면 됨.
- 정밀도보다 재현율 더 중요함
예: 스팸 메일 필터링
- 스팸을 일반 메일로 분류하면 불편함 정도
- 일반 메일을 스팸으로 잘못 분류하면 중요한 메일을 받지 못함 → 정밀도 중요
- 재현율보다 정밀도가 더 중요함
재현율이 상대적으로 더 중요한 지표인 경우는 실제 Positive 양성인 데이터 예측을 Negative 로 잘못 판단하게 되면 업무
상 큰 영향이 발생하는 경우
정밀도가 상대적으로 더 중요한 지표인 경우는 실제 Positive 양성인 데이터 예측을 Negative 로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
재현율 공식: TP / (FN + TP)
정밀도 공식: TP / (FP + TP)
-
두 지표 모두 TP(예측 Positive이면서 실제도 Positive)를 높임.
-
재현율은 FN(실제 Positive, 예측 Negative)를 낮추는 데 초점을 맞춤.
-
정밀도는 FP(실제 Negative, 예측 Positive)를 낮추는 데 초점을 맞춤.
-
재현율과 정밀도는 서로 보완적인 지표로 함께 사용되어야 모델의 성능을 정확하게 평가 가능
-
한 쪽만 높고 다른 쪽이 낮은 경우는 X
-
이상적인 모델은 두 지표 모두 높은 수치를 가져야 함.
-
평가를 간편하게 적용하기 위해서 confusion_matrix, accuracy, precision, recall 등의 평가를 한꺼번에 호출하는
get_clf_eval()함수를 만들 예정.
이후 타이타닉 데이터셋을 다시 불러와 로지스틱 회귀 모델을 사용해 분류 수행.
scikit-learn에서는:
정밀도 계산: precision_score()
재현율 계산: recall_score()
오차 행렬 계산: confusion_matrix()
타이타닉 데이터를 다시 로드한 후 가공해 로지스틱 회귀로 분류를 수행하기
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
print('오차 행렬')
print(confusion)
print('정확도 : {0:.4f}, 정밀도 : {1:.4f}, 재현율 : {2:.4f}'.format(accuracy, precision, recall))
- 로지스틱 회귀 기반으로 타이타닉 생존자를 예측하고 confusion matrix, accuracy, precision.
recall 평가를 수행
- LogisticRegression객체 의 생성 인자로 입력되는 Solver='liblinear'는 로지스틱 회귀의 최적화 알고리즘 유형을 지정하는 것임
- 보통 작은 데이터 세트의 이진 분류인 경우 solver 는 liblinear가 약간 성능이 좋은 경향이 있음
- solver 의 기본값은 lbfgs 이며 데이터 세트
가 상대적으로 크고 다중 분류인 경우 적합함.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 원본 데이터를 재로딩 , 데이터 가공 , 학습 데이터 / 테스트 데이터 분할.
titanic_df = pd.read_csv('sample_data/train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df= titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df,
test_size=0.20, random_state=11)
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
get_clf_eval(y_test, pred)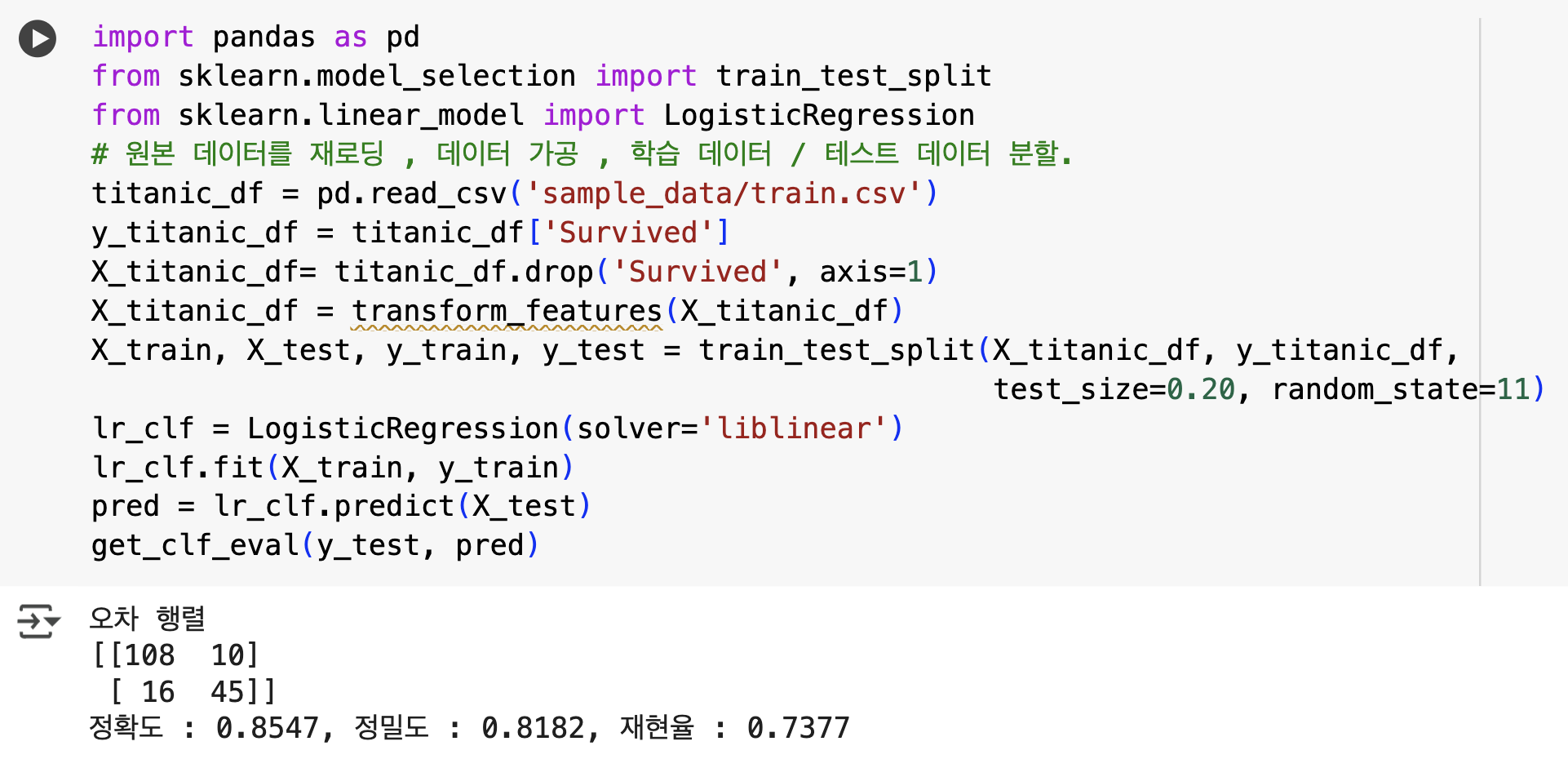
정밀도 / 재현율 트레이드오프
| 입력 파라미터 | predict() 메서드와 동일하게 보통 테스트 피처 데이터 세트를 입력 |
|---|---|
| 반환 값 | 개별 클래스의 예측 확률을 ndaray m x n (m: 입력값의 레코드 수 , n: 클래스 값 유형 ) 형태로 반환. 입력 테스트 데이터 세트의 표본 개수가 100 개이고 예측 클래스 값 유형이 2 개 ( 이진 분류 ) 라면 반환값은 100 x 2 ndarray임. 각 열은 개별 클래스의 예측 확률입니다. 이진 분류에서 첫 번째 칼럼은 O Negative 의 확률 , 두 번째 칼럼은 1 Positive 의 확률임. |
- 업무 특성상 정밀도 또는 재현율 중 하나가 더 중요할 경우, 분류 결정 임곗값(Threshold) 을 조정해 해당 지표를 높일 수 있음.
- 하지만 정밀도와 재현율은 서로 보완적 관계이므로, 한 쪽을 높이면 다른 쪽이 낮아질 수 있음 →정밀도/재현율 트레이드오프(Trade-off)라고 함
- 사이킷런의 분류 알고리즘은 예측 시 먼저 각 클래스에 대한 결정 확률(probability) 을 계산하고, 가장 확률이 높은 클래스를 최종 예측값으로 선택함
예: 클래스 0의 확률이 10%, 클래스 1의 확률이 90%이면, 클래스 1을 예측함.
- 일반적으로 이진 분류에서는 임곗값 0.5를 기준으로 0.5 이상이면 Positive(1), 이하면 Negative(0) 으로 분류.
predict()는 최종 클래스 값을 반환.
predict_proba()는 각 클래스에 대한 예측 확률을 반환.
predict_proba() 를 사용하면 임곗값을 조정하여 정밀도 또는 재현율을 직접 제어할 수 있음.
pred_proba = lr_clf.predict_proba(X_test)
pred = lr_clf.predict(X_test)
print('pred_proba() 결과 Shape : {0}'.format(pred_proba.shape))
print('pred_proba array에서 앞 3 개만 샘플로 추출 \n:', pred_proba[:3])
# 예측 확률 array 와 예측 결값 array 를 병합 (concatenate)해 예측 확률과 결괏값을 한눈에 확인
pred_proba_result = np.concatenate([pred_proba, pred.reshape(-1, 1)], axis=1)
print('두 개의 class 중에서 더 큰 확률을 클래스 값으로 예측\n', pred_proba_result[:3])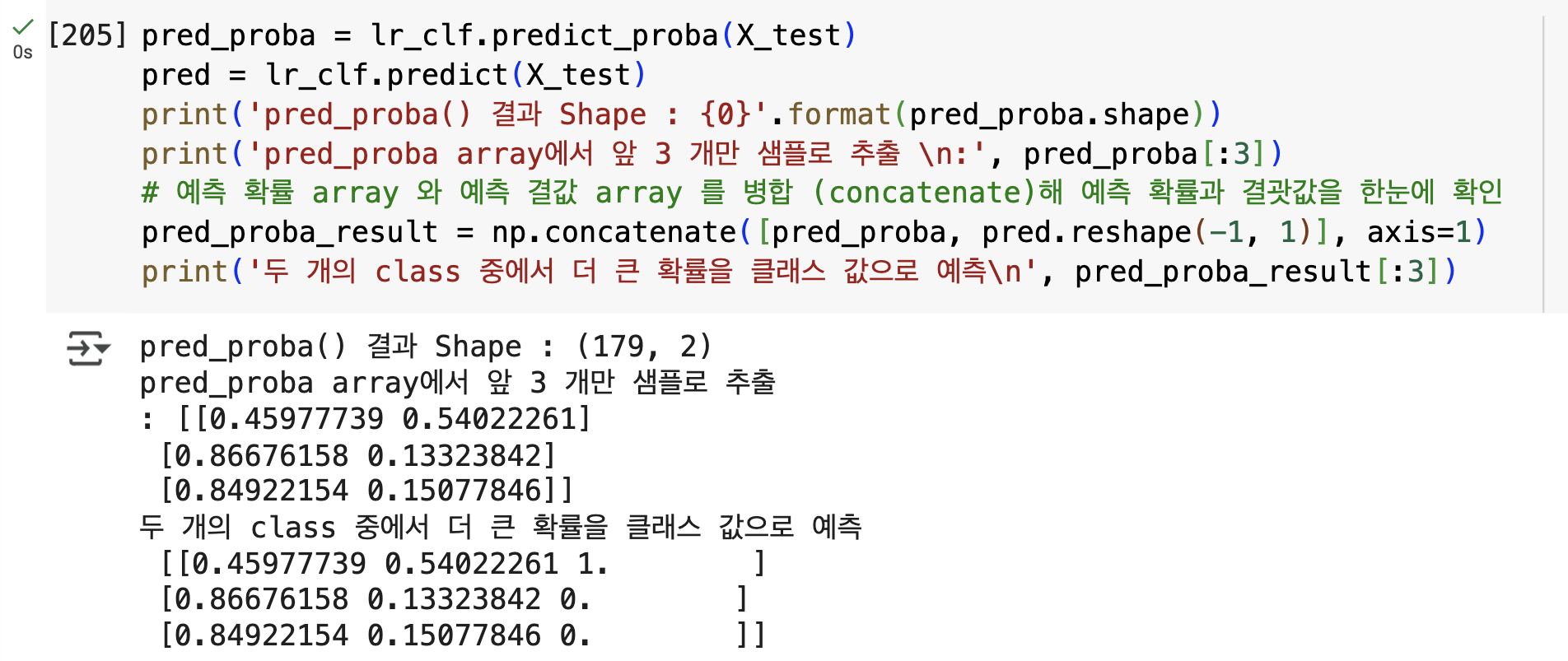
predict_proba()메서드의 반환 결과는 ndarray 형식으로, 클래스 0과 1 각각에 대한 확률을 나타냄.- 각 행의 두 칼럼 값을 더하면 항상 1이 됨.
- 예측 시 두 확률 중 더 큰 값의 칼럼 위치에 해당하는 클래스가 최종 예측값이 됨.
- 내부적으로
predict_proba()로 얻은 확률 값 배열에서, 임곗값(threshold) 이상인 확률을 가진 칼럼의 인덱스를 사용해 최종 예측 클래스를 결정함. - 정해진 임곗값은 0.5
- 이 동작 원리를 이해하면 사이킷런이 정밀도/재현율 트레이드오프를 어떻게 구현하는지 이해하는 데 도움이 됨.
- 임곗값을 조정함으로써 정밀도와 재현율 간의 밸런스를 조절할 수 있음.
- 임곗값 조정 구현을 위해 Binarizer 클래스를 사용.
- 특정 threshold 값을 설정해 객체 생성.
fit_transform()메서드에 ndarray를 입력하면, threshold보다 크면 1, 같거나 작으면 0으로 변환해 반환.- 이 방식으로 예측 확률을 기준으로 임곗값을 조정해 정밀도 또는 재현율을 높이는 로직을 코드로 구현할 수 있음.
from sklearn.preprocessing import Binarizer
X = [[ 1, -1, 2],
[2, 0, 0],
[0,1.1, 1.2]]
#X 의 개별 원소들이 threshold 값보다 같거나 작으면 0 을 , 크면 1 을 반환
binarizer = Binarizer(threshold=1.1)
print(binarizer.fit_transform(X))
- 입력된 X 데이터 세트에서 Binarizer의 threshold 값이 1.1 보다 같거나 작으면 0, 크면 1 로 변환됨을알 수 있음.
- 이제 이 Binarizer 를 이용해 사이킷런
predict()의 의사 코드를 만들어 볼 예졔
- LogisticRegression 객체의
predict_proba()메서드를 사용해 각 클래스별 예측 확률값을 저장한 변수는 pred_proba임 - 여기에 Binarizer 클래스를 사용하여 임곗값(threshold)을 0.5로 설정하고 적용.
- 확률이 0.5보다 크면 1 (Positive), 작거나 같으면 0 (Negative)으로 변환해 최종 예측값 생성.
- 이렇게 생성된 예측 결과에 대해
get_clf_eval()함수를 호출하여 정확도, 정밀도, 재현율 등 평가 지표를 출력하게 됨
from sklearn.preprocessing import Binarizer
# Binarizer 의 threshold 설정값. 분류 결정 임곗값임.
custom_threshold = 0.5
# predict_proba() 반환값의 두 번째 칼럼 , 즉 Positive 클래스 칼럼 하나만 추출해 Binarizer를 적용
pred_proba_1 = pred_proba[:, 1].reshape(-1, 1)
binarizer = Binarizer (threshold=custom_threshold).fit(pred_proba_1)
custom_predict = binarizer.transform(pred_proba_1)
get_clf_eval(y_test, custom_predict)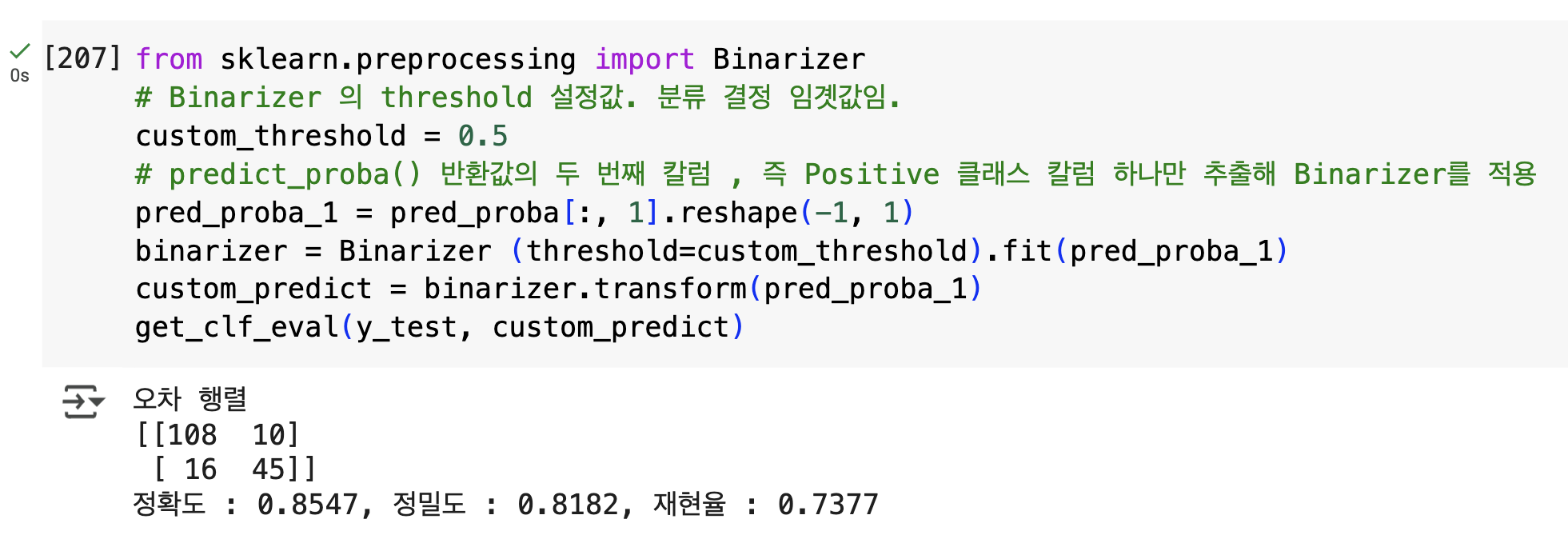
- 이 의사 코드로 계산된 평가 지표는 앞 예제의 타이타닉 데이터로 학습된 로지스틱 회귀
Classfier객
체에서 호출된predict()로 계산된 지표 값과 정확히 같습니다.predict()가predict_proba( )에 기반함을 알 수 있음.
임곗값을 0.4 로 낮춰보시면,
# Binarizer의 threshold 설정값을 0.4로 설정. 즉 분류 결정 임곗값을 0.5 에서 0.4 로 낮춤
custom_threshold = 0.4
pred_proba_1 = pred_proba[:, 1] .reshape(-1, 1)
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_1)
custom_predict = binarizer.transform(pred_proba_1)
get_clf_eval(y_test, custom_predict)
결과
- 임곗값을 낮추니 재현율 값이 올라감.
- 정밀도가 떨어졌음.
이유
- 분류 결정 임곗값은 Positive 예측값을 결정하는 확률의 기준이 됨
- 확률이 0.5 가 아닌 0.4 부터 Positive 로 예측을 더 너그럽게 하기 때문에 임곗값 값을 낮출수록 True 값이 많아지게 됨.

- Positive 예측값이 많아지면 상대적으로 재현율 값이 높아짐
- 양성 예측을 많이 하다 보니 실제 양 성을 음성으로 예측하는 횟수가 상대적으로 줄어들기 때문임.
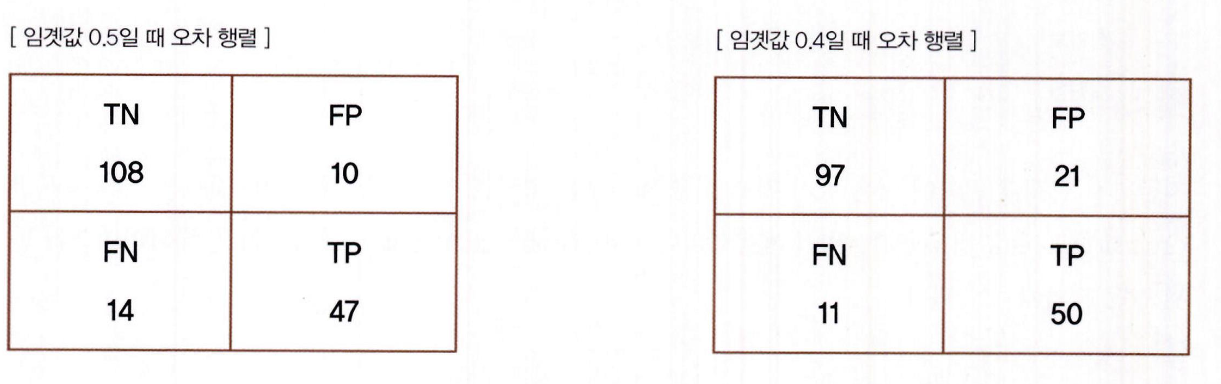
-
임곗값이 0.5 에서 0.4 로 낮아지면
-
TP 가 늘었음
-
FN 가 줄었음
-
그에 따라 재현율이 좋아졌습니다.
-
하지만 FP 는 늘면서 정밀도가 많이 나빠졌음.
-
그리고 정확도도 나빠졌음.
- 임곗값을 0.4 에서부터 0.6 까지 0.05 씩 증가시키며 평가 지표를 조사하보기
get_eval_by_threshold()함수를 만들어 보기
# 테스트를 수행할 모든 임곗값을 리스트 객체로 저장.
thresholds = [0.4, 0.45, 0.50, 0.55, 0.60]
def get_eval_by_threshold(y_test, pred_proba_c1, thresholds):
# thresholds list 객체 내의 값을 차례로 iteration 하면서 Evaluation 수행.
for custom_threshold in thresholds:
binarizer = Binarizer (threshold=custom_threshold).fit(pred_proba_c1)
custom_predict = binarizer.transform(pred_proba_c1)
print('임곗값:', custom_threshold)
get_clf_eval(y_test, custom_predict)
get_eval_by_threshold(y_test, pred_proba[:, 1].reshape(-1, 1), thresholds )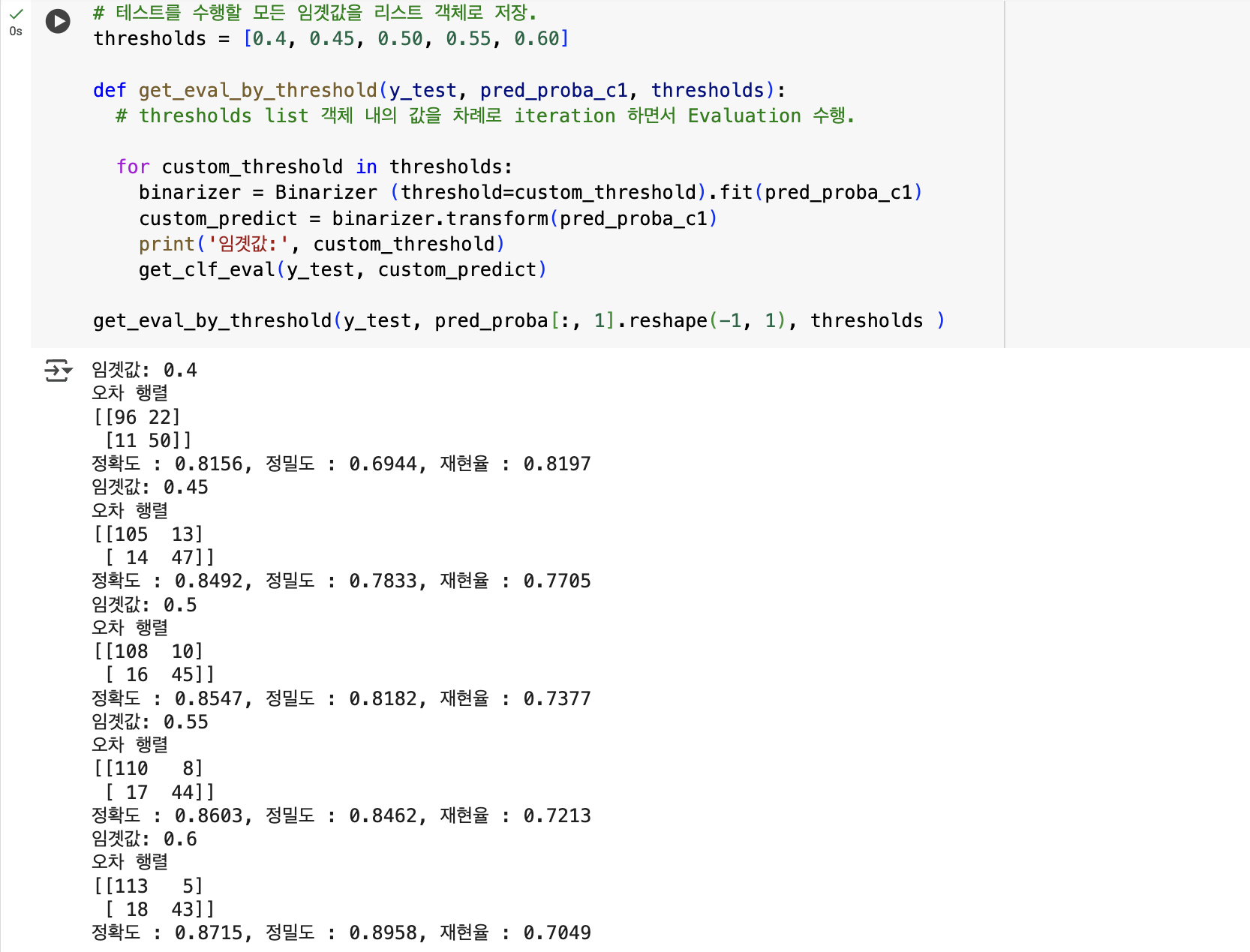
분류 결정 임곗값에 따른 평가 지표 별로 정리
- 임곗값이 0.45 일 경우에 디폴트 0.5 인 경우와 비교해서 정확도는 동일하고 정밀도는 약간 떨어졌으나 재현율이 올랐음.
- 재현율을 향상시키면서 다른 수치를 어느 정도 감소하는 희생을 해야 한다면 임곗값 0.45 가 가장 적당해 보임
| 0.4 | 0.45 | 0.5 | 0.55 | 0.6 | |
|---|---|---|---|---|---|
| 정확도 | 0.8156 | 0.8492 | 0.8547 | 0.8603 | 0.8715 |
| 정밀도 | 0.6944 | 0.7833 | 0.8182 | 0.8246 | 0.8958 |
| 재현율 | 0.7705 | 0.7377 | 0.7213 | 0.7049 | 0.7213 |
- 사이킷런은 이와 유사한
precision_recall_curve()API 를 제공함. precision_recall_curve()API 의 입력 파라미터와 반
환 값은 다음과 같음.
입력 파라미터
y_true: 실제 클래스값 배열 ( 배열 크기 = [ 데이터 건수 ])
probas_pred: Positive 칼럼의 예측 확률 배열 ( 배열 크기 = [ 데이터 건수 ])
반환 값
정밀도 : 임곗값별 정밀도 값을 배열로 반환
재현율 : 임곗값별 재현율 값을 배열로 반환
precision_recall_curve() 를 이용해 타이타닉 예측 모델의 임곗값별 정밀도와 재현율을 구하기
precision_recall_curve()의 인자로 실제 값 데이터 세트와 레이블 값이 1 일 때의 예측 확률 값을 입력함.- 레이블 값이 1 일 때의 예측 확률 값
predict_proba(X_test)[:, 1]로predict_proba()의 반환 ndarray의 두 번째 칼럼 ( 즉 , 칼럼 인덱스 1) 값에 해당하는 데이터 세트임. precision_recall_curve()는 일반적으로 0.11 ~ 0.95 정도의 임곗값을 담은 넘파이 ndarray 와 이 임계값에 해당하는 정밀도 및 재현율 값을 담은 넘파이 ndarray 를 반환함.- 반환된 임곗값(threshold)이 너무 작은 단위로 147건 구성됨.
- 이 중에서 샘플로 10건만 추출하고,
- 임곗값을 15단계로 나누어 더 큰 간격의 임곗값을 기준으로
- 각 임곗값에서의 정밀도(Precision)와 재현율(Recall) 값을 함께 확인.
from sklearn.metrics import precision_recall_curve
# 레이블 값이 1 일 때의 예측 확률을 추출
pred_proba_class1 = lr_clf.predict_proba(X_test)[:, 1]
# 실제값 데이터 세트와 레이블 값이 1 일 때의 예측 확률을 precision_recall_curve 인자로 입력
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_class1)
print('반환된 분류 결정 곗값 배열의 Shape:', thresholds.shape)
# 반환된 임계값 배열 로우가 147 건이므로 샘플로 10 건만 추출하되 , 임곗값을 15 Step 으로 추출.
thr_index = np.arange(0, thresholds.shape[0], 15)
print('샘플 추출을 위한 임계값 배열의 index 10 개 :' , thr_index)
print(' 샘플용 10 개의 임곗값 :', np.round(thresholds[thr_index], 2))
# 15 step 단위로 추출된 임계값에 따른 정밀도와 재현율 값
print('샘플 임계값별 정밀도 :', np.round(precisions[thr_index], 3))
print('샘플 임계값별 재현율 :', np.round(recalls[thr_index], 3))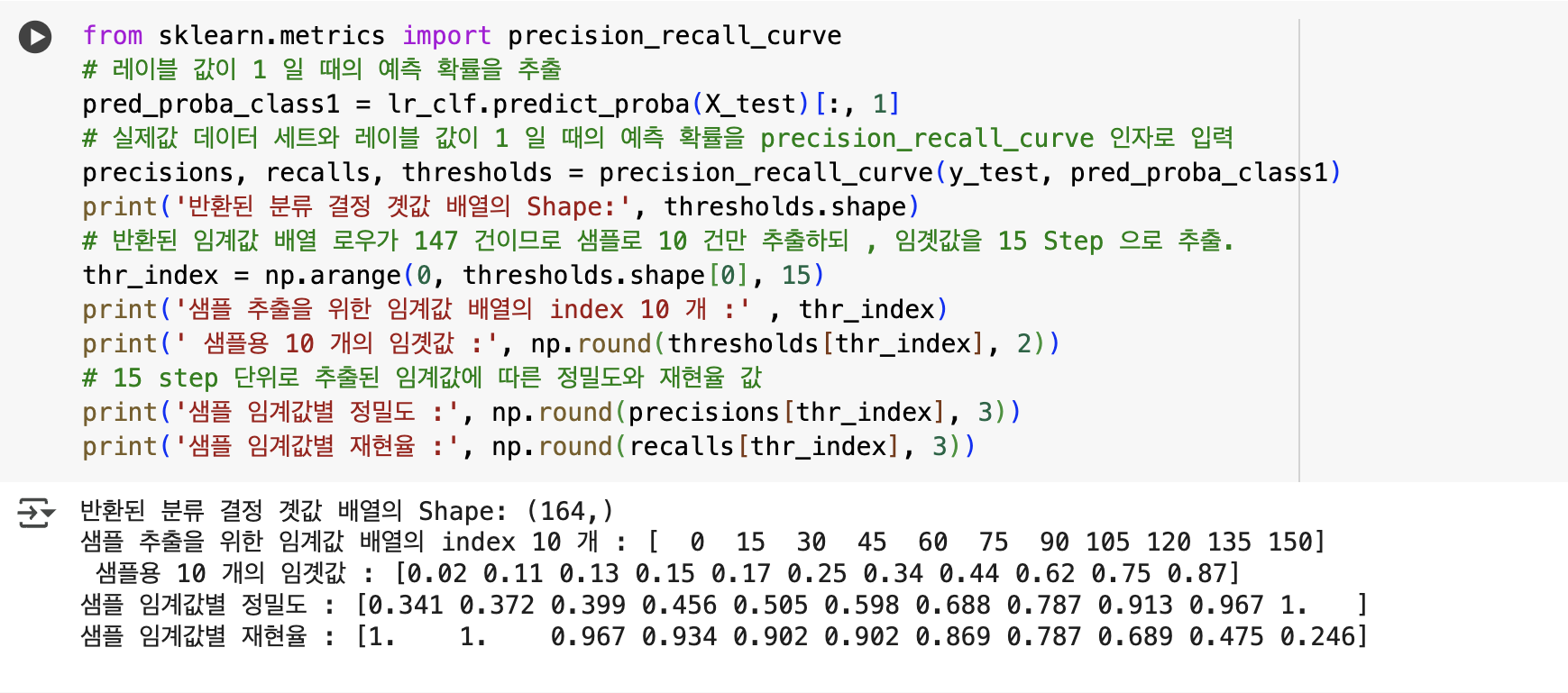
- 추출된 임곗값 샘플 10 개에 해당하는 정밀도 값과 재현율 값을 살펴보면
임곗값이 증가할수록 정밀도 값은 동시에 높아지나 재현율 값은 낮아짐을 알 수 있음.
precision_recall_curve()API 는 정밀 도와 재현율의 임곗값에 따른 값 변화를 곡선 형태의 그래프로 시각화하는 데 이용할 수 있음.
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
def precision_recall_curve_plot(y_test, pred_proba_c1):
# threshold ndarray 와 이 threshold에 따른 정밀도 , 재현율 ndarray 추출.
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba_c1)
# X 축을 threshold 값으로 , Y 축은 정밀도 , 재현율 값으로 각 Plot 수행. 정밀도는 점선으로 표시
plt.figure(figsize=(8, 6))
threshold_boundary = thresholds .shape[0]
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label='precision')
plt.plot(thresholds, recalls[0:threshold_boundary], label='recall')
# threshold 값 X 축의 Scale 을 0.1 단위로 변경
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
# x 축 , y 축 label 과 legend, 그리고 grid 설정
plt.xlabel('Threshold value'); plt.ylabel('Precision and Recall value')
plt.legend(); plt.grid()
plt.show()
precision_recall_curve_plot(y_test, lr_clf.predict_proba(X_test)[:, 1] )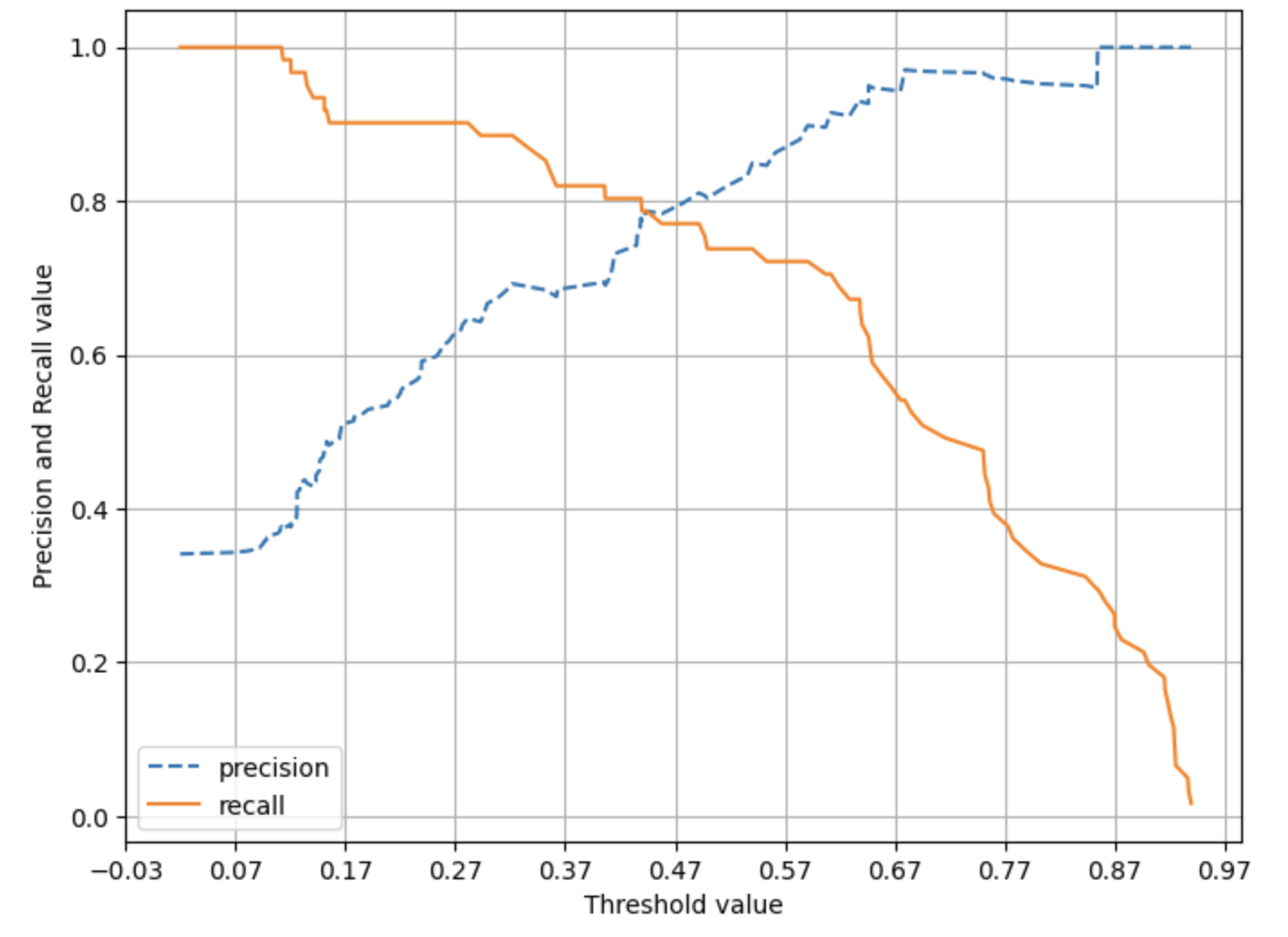
그래프 살펴보면
-
정밀도는 점선으로 , 재현율은 실선으로 표현
-
임곗값이 낮을수록 많은 수의 양성 예측으로 인해 재현율 값이 극도로 높아지고 정밀도 값이 극도로 낮아짐.
-
임곗값을 계속 증가시킬수록 재현율 값이 낮아지고 정밀도 값이 높아지는 반대의 양상이 됨
-
로지스틱 회귀 기반의 타이타닉 생존자 예측 모델의 경우 임곗값이 약 0.45 지점에서 재현율과 정밀도가 비슷해지는 모습을 보였음.
정밀도와 재현율의 맹점
- 앞에서도 봤듯이 Positive 예측의 임곗값을 변경함에 따라 정밀도와 재현율의 수치가 변경됨
- 변경은 업무 목적에 맞게 균형 있게 적용해야 함
- 한 지표만 높이기 위한 임곗값 조정은 바람직하지 않음
- 지표 수치를 극단적으로 높이는 방법은 숫자 놀음에 불과함
정밀도가 100% 가 되는 방법 ?
- 확실한 기준이 되는 경우만 Positive로 예측하고 나머지는 모두 Negative로 예측
- 전체 1000명 중 확실한 Positive 징후를 가진 1명만 Positive로 예측 → TP = 1, FP = 0임
- 정밀도 = TP / (TP + FP) = 1 / (1 + 0) = 100%임
- 극단적 조건으로 인해 정밀도 수치를 인위적으로 높인 사례임
재현율이 100% 가 되는 방법 ?
- 모든 환자를 Positive로 예측하면 (전체 환자 1000 명을 다
Positive 로 예측) - 이 중 실제 양성인 사람이 30 명
재현율 = = = 100%
-
FN이 0이 되기 때문에 재현율은 극단적으로 높아짐
-
하지만 TN은 고려되지 않으며, 정밀도는 낮아질 수 있음
-
정밀도 또는 재현율 중 하나만 참조하면 극단적인 수치 조작이 가능
-
한 지표만 높고 다른 하나는 낮은 분류는 성능이 좋지 않은 분류
따라서 -
정밀도 또는 재현율 중 하나만 스코어가 좋고 다른 하나는 스코어가 나쁜 분류는 성능이 좋지 않은 분류로 간주 가능.
-
물론 앞의 예제에서와 같이 분류가 정밀도 또는 재현율 중 하나에 상대적인 중요도를 부여해 각 예측 상황에 맞는 분류 알고리즘을 튜닝할 수 있지만 , 그렇다고 정밀도 / 재현율 중 하나만 강조하는 상황이 돼서는 안 됨
예: 암 예측 모델에서 재현율을 높인다고 걸핏하면
양성으로 판단할 경우 환자의 부담과 불평이 커지게 됨
정밀도와 재현율의 수치가 적절하게 조합돼 분류의 종합적인 성능 평가에 사용될 수 있는 평가 필요.
4. F1 스코어
- F1 스코어 (Score) 는 정밀도와 재현율을 결합한 지표임.
- F1 스코어는 정밀도와 재현율이 어느 한쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가짐.
F1 = =
- A 예측 모델: 정밀도 0.9, 재현율 0.1 → F1 스코어 = 0.18
- B 예측 모델: 정밀도 0.5, 재현율 0.5 → F1 스코어 = 0.5
- B 모델이 A 모델보다 훨씬 우수한 F1 스코어를 가짐
- 사이킷런은 F1 스코어 계산을 위해
f1_score()API 제공 - 이를 활용해 로지스틱 회귀 기반 타이타닉 생존자 모델의 F1 스코어를 계산
from sklearn.metrics import f1_score
f1 = f1_score(y_test, pred)
print('F1 스코어 : {0: 4f}'.format(f1))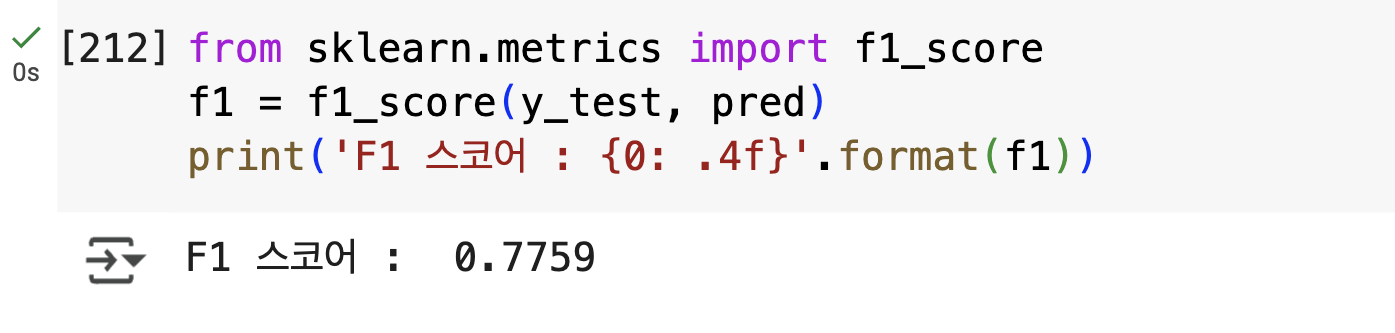
타이타닉 생존자 예측에서 임곗값을 변화시키면서 F1 스코어를 포함한 평가 지표를 구하기
- get_clf_eval() 함수에 F1 스코어를 구하는 로직을 추가 그리고 앞에서 작성한
get_eval_by_threshold()함수를 이용해 임곗값 0.4 ~ 0.6 별로 정확도,정밀도 , 재현율 , F1 스코어를 알아볼 목적
def get_clf_eval (y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
# F1 스코어 추가
f1 = f1_score(y_test, pred)
print('오차 행렬')
print(confusion)
#f1 score print 추가
print('정확도 : {0: .4f}, 정밀도 : {1: .4f}, 재현율 : {2:.4f}, F1:{3:.4f}'
.format(accuracy, precision, recall, f1))
print('------------------------------------------------------------')
thresholds = [0.4, 0.45, 0.50, 0.55, 0.60]
pred_proba = lr_clf.predict_proba(X_test)
get_eval_by_threshold(y_test, pred_proba[:, 1].reshape(-1, 1), thresholds)
- F1 스코어는 임곗값이 0.6 일 때 가장 좋은
값을 보여줌. - 하지만 임곗값이 0.6 인 경우에는 재현율이 크게 감소하고 있으니 주지하기 바람.
| 0.4 | 0.45 | 0.5 | 0.55 | 0.6 | |
|---|---|---|---|---|---|
| 정확도 | 0.8156 | 0.8492 | 0.8547 | 0.8603 | 0.8715 |
| 정밀도 | 0.6944 | 0.7833 | 0.8182 | 0.8246 | 0.8958 |
| 재현율 | 0.7705 | 0.7377 | 0.7213 | 0.7049 | 0.7213 |
| F1 | 0.7769 | 0.7869 | 0.7759 | 0.7788 | 0.7890 |
5. ROC 곡선과 AUC
- ROC 곡선(Receiver Operation Characteristic Curve) 은 이진 분류의 예측 성능 측정에서 중요한 지표임
- 원래 2차대전 통신 장비 성능 평가를 위해 고안된 수치로, 이름이 다소 특이함
- 주로 의학 분야에서 사용되지만, 머신러닝 이진 분류 평가에도 활용됨
- ROC 곡선은 FPR(False Positive Rate) 변화에 따른 TPR(True Positive Rate) 변화 곡선
X축: FPR
Y축: TPR
TPR 은 재현율, 공식은 , 민감도 라고도 불림
- TPR(민감도)에 대응하는 지표는 TNR(True Negative Rate), 즉 특이성(Specificity)이 있음
| 지표 이름 | ||
|---|---|---|
| 민감도 (TPR) | 실제값 Positive(양성) 가 정확히 예측돼야 하는 수준을 나타냅니다 | 질병이 있는 사람은 질병이 있는 것으로 양성 판정 |
| 특이성 (TNR) | 실제값 Negative(음성) 가 정확히 예측돼야 하는 수준을 나타냅니다 | 질병이 없는 건강한 사람은 질병이 없는 것으로 음성 판정 |
TNR(True Negative Rate)은 특이성, 공식은
= ROC 곡선의 X 축 기준인 FPR(False Positive Rate)
FPR =
이므로 1 - TNR 또는 1- 특이성 으로 표현
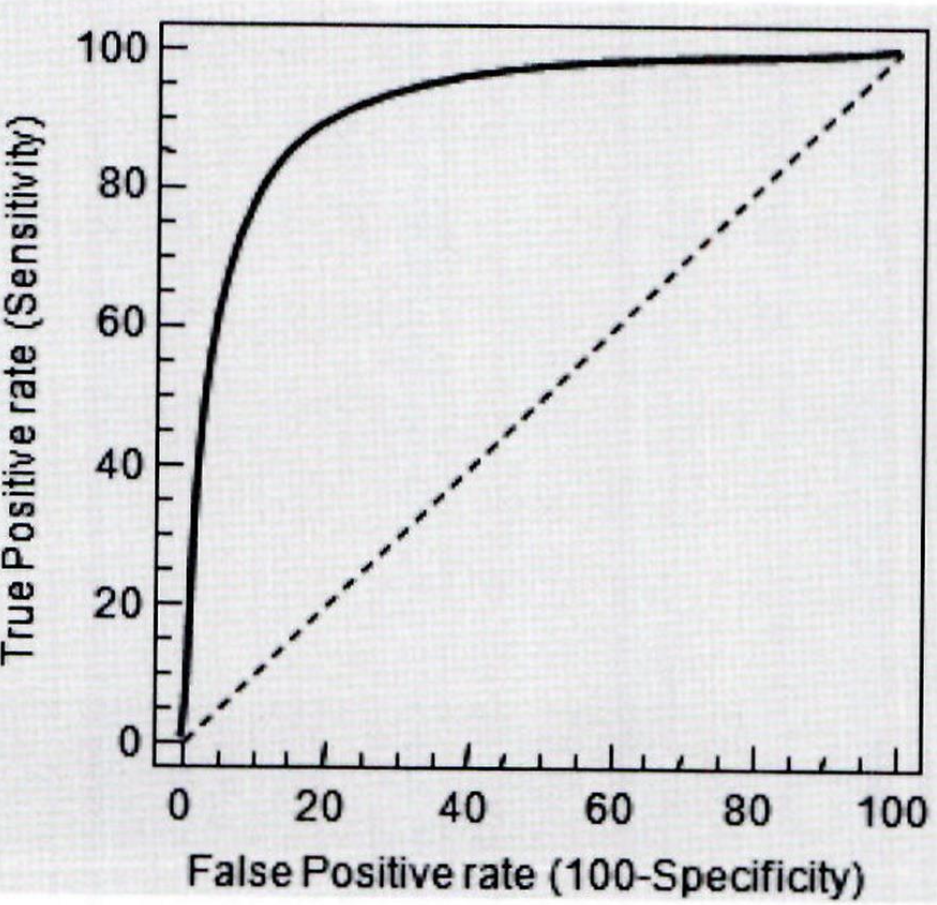
ROC 곡선의 예
-
가운데 직선은 ROC 곡선의 최저 값임.
-
왼쪽 하단과 오른쪽 상단을 대각선으로 이은 직선은 동전을 무작위로 던져 앞/뒤를 맞추는 랜덤 수준의 이진 분류의 ROC 직선임 (AUC 는 0.5임)
ROC 곡선이 가운데 직선에 가까울수록 성능이 떨어지는 것이며 , 멀어질수록 성능이 뛰어남
-
ROC 곡선은 FPR 을 0 부터 1 까지 변경하면서 TPR 의 변화 값을 구함
-
분류 결정 임곗값은 Positive 예측값을 결정하는 확률의 기준이기 때문에 FPR 을 0 으로 만들려면 임곗값을 1 로 지정하면 FPR 을 0 부터 1 까지 변경 가능
-
임곗값을 1로 지정하면 Postive 예측 기준이 매우 높기 때문에 분류기(Classifier)가 임곗값보다 높은 확률을 가진 데이터를 Positive로 예측할 수 없기 때문임
FPR =
-
공식에 의하면, 아예 Positive로 예측하지 않기 때문에 FP 값이 0 이 되므로 자연스럽게 FPR 은 0 이 됨.
- FPR을 1로 만드는 방법: TN을 0으로 만들면 됨
- TN을 0으로 만들기 위해 분류 결정 임곗값을 0으로 지정
- 모든 데이터를 Positive로 예측 → Negative 예측 없음 → TN = 0 → FPR = 1
- 이렇게 임곗값을 1부터 0까지 변화시키며 FPR과 TPR 값을 구하는 것이 ROC 곡선
- 결과적으로 재현율 곡선과 형태가 유사
- 사이킷런의
roc_curve()API는 ROC 곡선을 구하는 함수 (사용법은 precision_recall_curve()와 유사) - 반환값은 FPR, TPR, 임곗값 3가지로 구성
입력 파라미터
y_true: 실제 클래스 값 array ( array shape=[데이터 건수])
y_score: predict_probe() 의 반환 값 array 에서 Positive 칼럼의 예측 확률이 보통 사용됨. array.
shape = [n_samples]
반환 값
fpr: fpr 값을 array로 반환
tpr:fpr 값을 arrray 로 반환
thresholds: threshold 값 array
roc_curve()API 를 이용해 타이타닉 생존자 예측 모델의 FPR, TPR, 임곗값을 구하기- 앞 정밀도와 재현율에서 학습한 LogisticRegression 객체의 predict_proba() 결과를 다시 이용해 roc_curve() 의 결과를 도출할 예정.
from sklearn.metrics import roc_curve
# 레이블 값이 1 일때의 예측 확률을 추출
pred_proba_class1 = lr_clf.predict_proba(X_test)[:, 1]
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_class1)
# 반환된 임곗값 배열에서 샘플로 데이터를 추출하되 , 임곗값을 5 Step 으로 추출.
# thresholds [0] 은 max(예측확률)+1 로 임의 설정됨. 이를 제외하기 위해 np.arange 는 1 부터 시작
thr_index = np.arange(1, thresholds.shape[0], 5)
print('샘플 추출을 위한 임곗값 배열의 index:', thr_index)
print('샘플 index 로 추출한 임곗값 :', np. round (thresholds[thr_index], 2))
# 5 step 단위로 추출된 임계값에 따른 FPR, TPR 값
print('샘플 임곗값별 FPR:', np.round(fprs[thr_index], 3))
print('샘플 임곗값별 TPR:', np.round(tprs[thr_index], 3))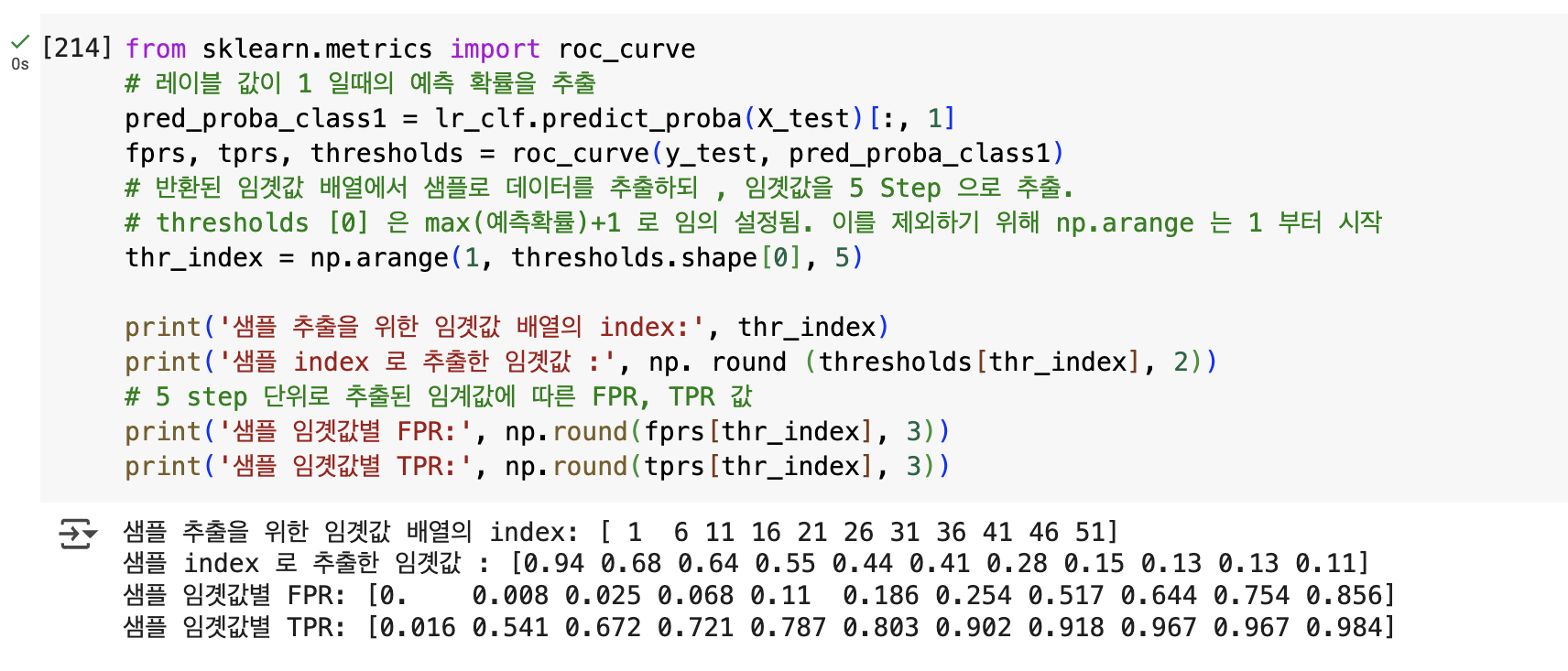
roc_curve()의 결과를 살펴보면
- 임곗값이 1 에 가까운 값에서 점점 작아지면서 FPR 이 점점 커짐.
- 그리고 FPR 이 조금씩 커질 때 TPR 은 가파르게 커짐을 알 수 있음.
- FPR 의 변화에 따른 TPR 의 변화를 ROC 곡선으로 시각화 해보기
def roc_curve_plot(y_test, pred_proba_c1):
# 임곗값에 따른 FPR, TPR 값을 반환받음.
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_c1)
# ROC 곡선을 그래프 곡선으로 그림.
plt.plot(fprs, tprs, label='ROC')
# 가운데 대각선 직선을 그림.
plt.plot([0, 1], [0, 1], 'k--', label='Random')
# FPR X 축의 Scale 을 0.1 단위로 변경 , X, Y 축 명 설정 등
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0, 1); plt.ylim(0, 1)
plt.xlabel('FPR( 1 - Specificity )'); plt.ylabel('TPR( Recall )')
plt.legend
roc_curve_plot(y_test, pred_proba[:, 1] )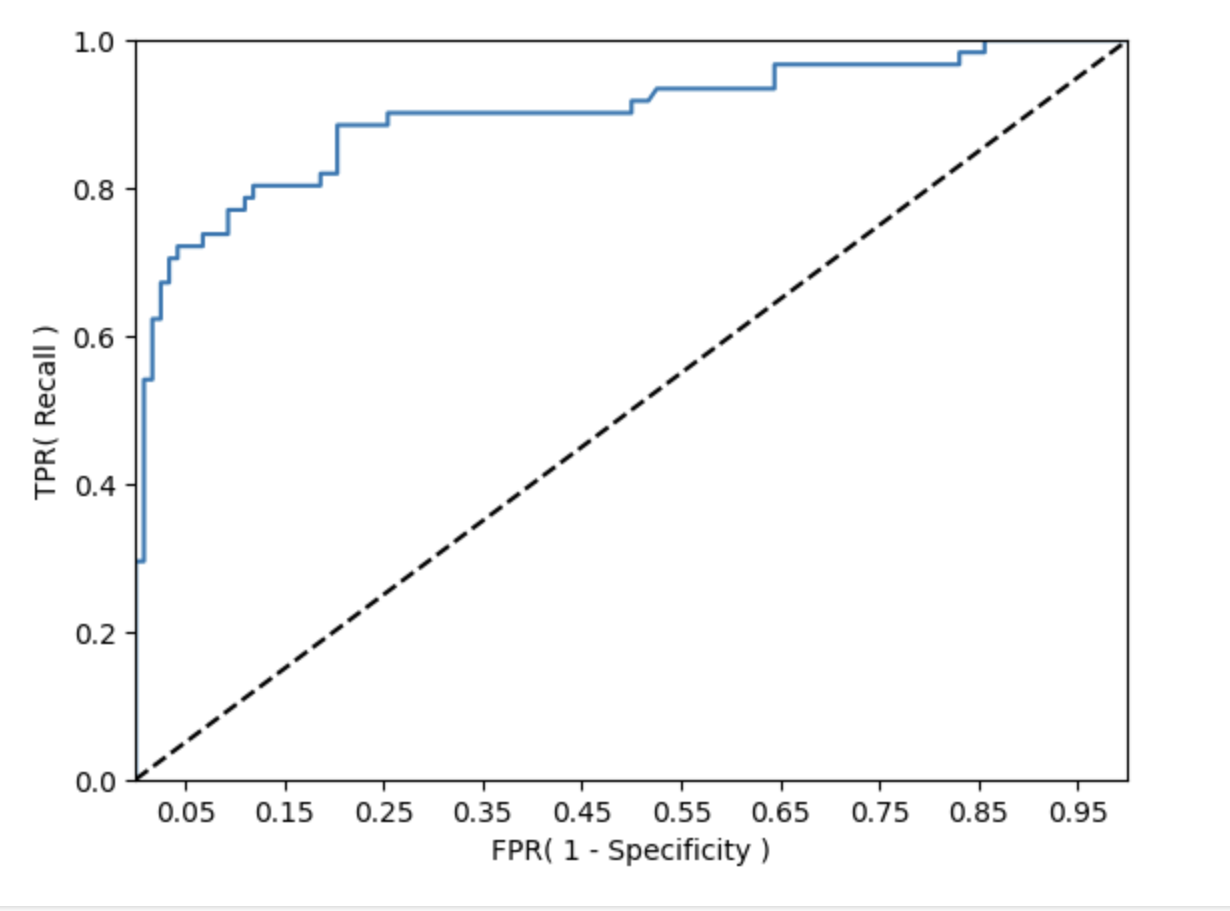
- ROC 곡선은 FPR과 TPR의 변화를 시각적으로 보여주는 도구
- 실제 분류 성능 지표로 사용되는 것은 ROC 곡선의 면적, 즉 AUC(Area Under Curve)
- AUC 값은 일반적으로 1에 가까울수록 좋은 성능
- FPR이 낮은 상태에서 TPR이 높을수록 AUC 수치가 커짐
- ROC 곡선이 왼쪽 상단으로 가파르게 올라갈수록, 면적이 1에 가까워짐
- 가운데 대각선 직선은 랜덤 수준의 (동전 던지기 수준) 이
진 분류 AUC 값으로 0.5 임 - 따라서 보통의 분류는 0.5 이상의 AUC 값을 가짐
from sklearn.metrics import roc_auc_score
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
roc_score = roc_auc_score(y_test, pred_proba)
print('ROC AUC 값: {0: .4f}'. format(roc_score))
- 타이타닉 생존자 예측 로지스틱 회귀 모델의 ROC AUC 값은 약 0.8987 로 측정됨.
-get_clf_eval() 함수에 roc_auc_score() 를 이용해 ROC AUC 값을 측정하는 로직을 추가하는데, ROC AUC 는 예측 확률값을 기반으로 계산되므로
- 이를
get_clf_eval()함수의 인자로 받을 수 있도록get_clf_eval(y_test, pred=None, pred_proba=None)로 함수형을 변경해 줌. get_cf_eval함수는 정확도 , 정밀도 , 재현율 , F1 스코어 , ROC AUC 값까지 출력 가능.
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print (confusion)
# ROC-AUC print 추가
print('정확도 : {0:.4f}, 정밀도 : {1:.4f}, 재현율 : {2: .4f}, \
F1: {3:.4f}, AUC: {4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))6. 피마 인디언 당뇨병 예측
- 피마 인디언 당뇨병 데이터 세트는 북아메리카 피마 지역 원주민의 Type-2 당뇨병 결과 데이터
- 당뇨병의 주된 원인은 식습관과 유전
- 피마 지역은 고립된 유전적 특성을 가진 지역으로, 서구화된 식습관 도입 후 당뇨 환자 급증
- 이 데이터는 당뇨병 연구에 많이 활용되며, 머신러닝 예측 모델 구축 및 평가 지표 적용 사례로 사용됨
https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database download
피마 인디언 당뇨병 데이터 세트는 다음 피처로 구성.
• Pregnancies: 임신 횟수
• Glucose: 포도당 부하 검사 수치
• BloodPressure: 혈압 (mm Hg)
• SkinThickness: 팔 삼두근 뒤쪽의 피하지방 측정값 (mm)
• Insulin: 혈청 인슐린 (mu U/ml)
• BM: 체질량지수 (체중 (Kg)/( 키(m)^2)
• DiabetesPedigreeFunction: 당뇨 내력 가중치 값
• Age: 나이
• Outcome: 클래스 결정 값 ( 0 또는 1)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
from sklearn.metrics import f1_score, confusion_matrix, precision_recall_curve, roc_curve
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
diabetes_data = pd.read_csv('sample_data/diabetes.csv')
print(diabetes_data['Outcome'].value_counts())
diabetes_data.head(3)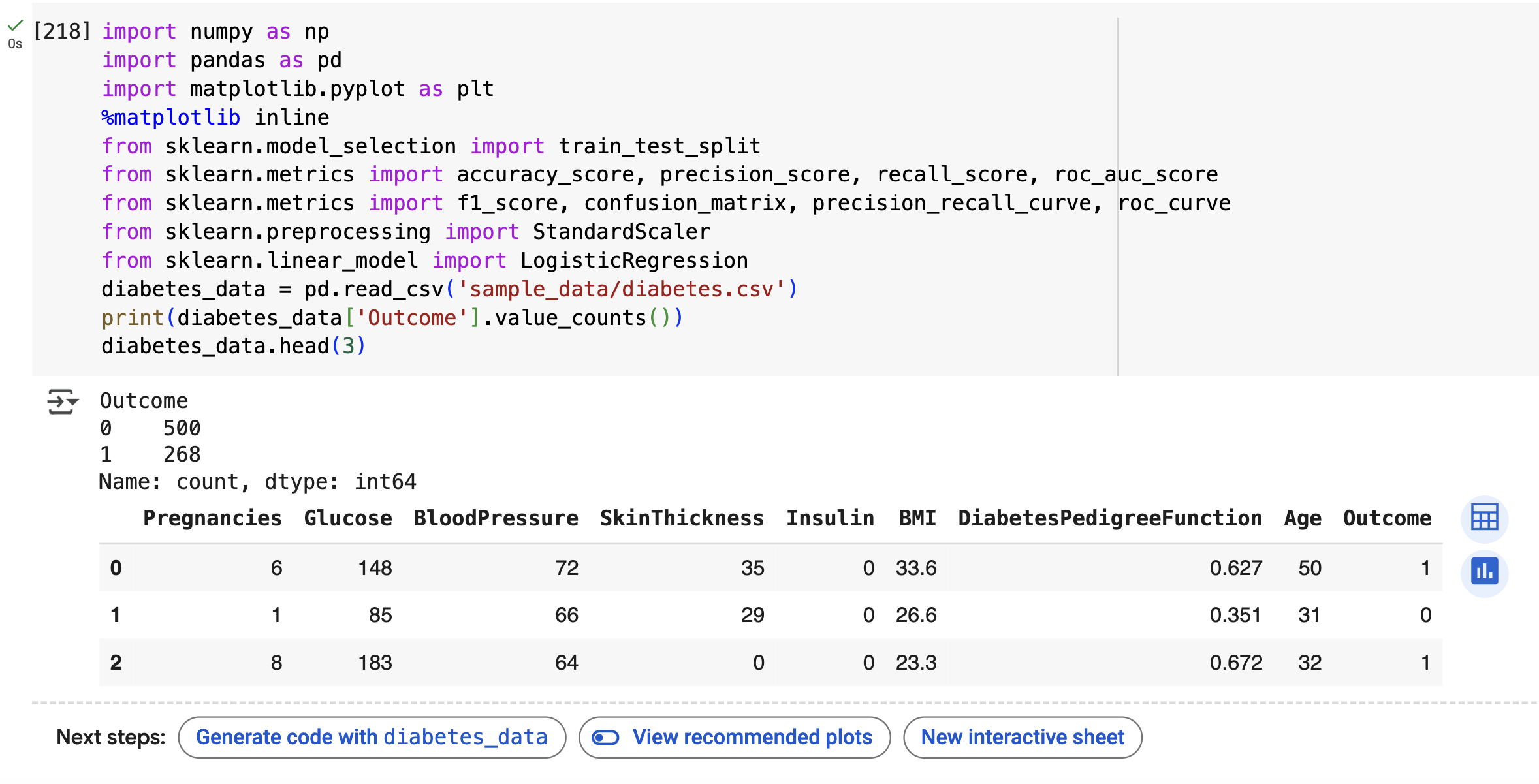
- 전체 768 개의 데이터 중에서 Negative 값 0 이 500 개 , Positive 값 1 이 268 개로 Negative가 상대적으
로 많음 - feature 의 타입과 Null 개수를 살펴볼 예정임
diabetes_data.info()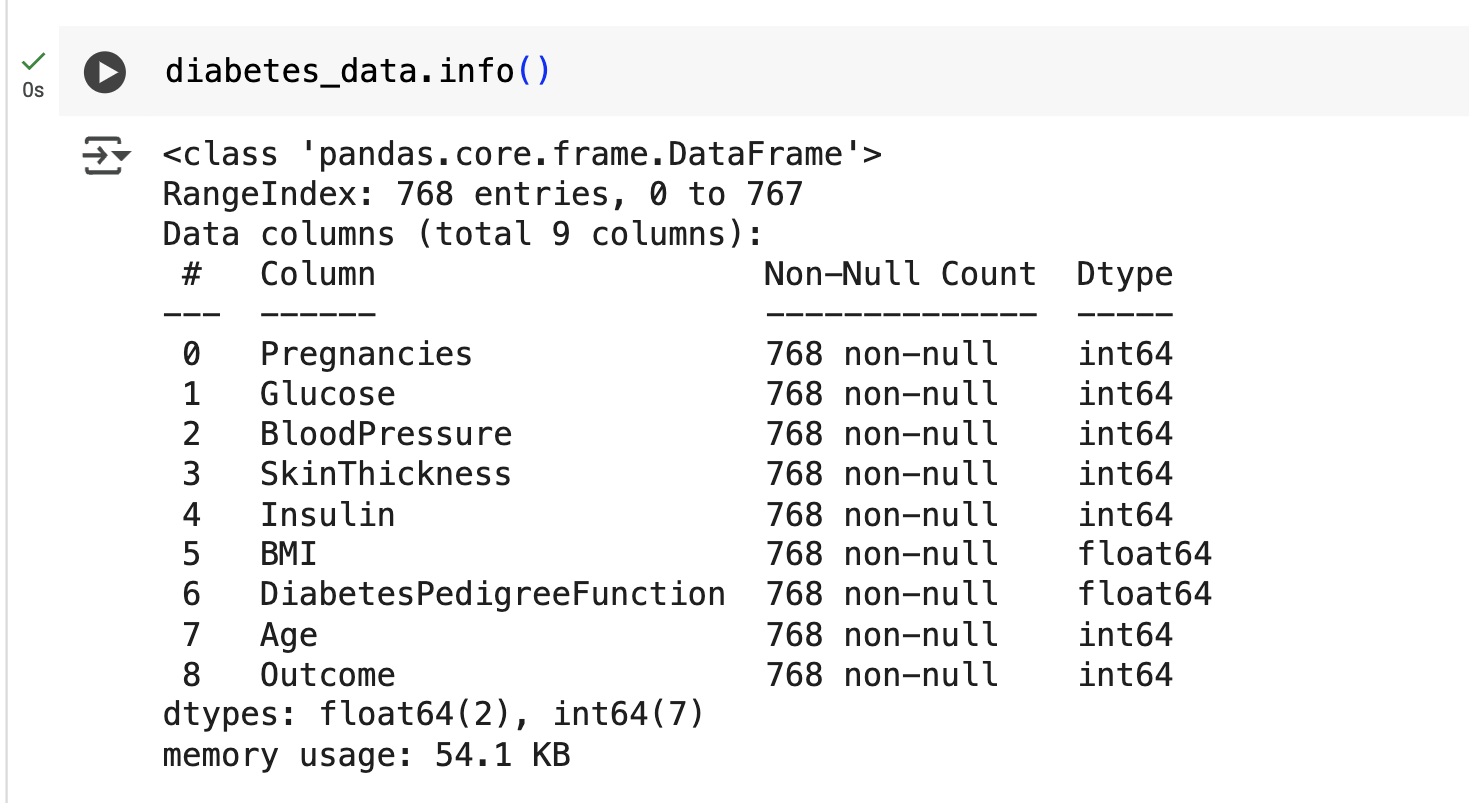
- Null 값 없음, 모든 피처는 숫자형 → 피처 인코딩 불필요
- 피처는 임신 횟수, 나이, 당뇨 검사 수치 등 숫자형 피처로 구성
- 로지스틱 회귀(Logistic Regression)를 사용해 예측 모델 생성 예정
- 데이터 세트를 피처 데이터 세트와 클래스 데이터 세트로 분리
- 이후, 학습 데이터 세트와 테스트 데이터 세트로 분할
예측 수행 후, 이전에 사용한 유틸리티 함수들 적용:
get_df_eval()get_eval_by_threshold()precision_recall_curve_plot()
성능 평가 지표 출력 및 재현율 곡선 시각화 진행
# 피처 데이터 세트 X, 레이블 데이터 세트 y 를 추출.
# 맨 끝이 outcome 칼럼으로 레이블 값임. 칼럼 위치 1 을 이용해 추출
X = diabetes_data.iloc[:, :-1]
y = diabetes_data. iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 156, stratify=y)
# 로지스틱 회귀로 학습 , 예측 및 평가 수행.
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
get_clf_eval(y_test, pred, pred_proba)
- 예측 정확도가 77.27%, 재현율은 59.26% 로 측정됐습니다. 전체 데이터의 65% 가 Negative 이므로 정
확도보다는 재현율 성능에 조금 더 초점을 맞춤. - 먼저 정밀도 재현율 곡선을 보고 임곗값별
정밀도와 재현율 값의 변화를 확인함. - 이를 위해
precision_recall_curve_plot()함수를 이용함.
pred_proba_c1 = lr_clf.predict_proba(X_test)[:, 1]
precision_recall_curve_plot(y_test, pred_proba_c1)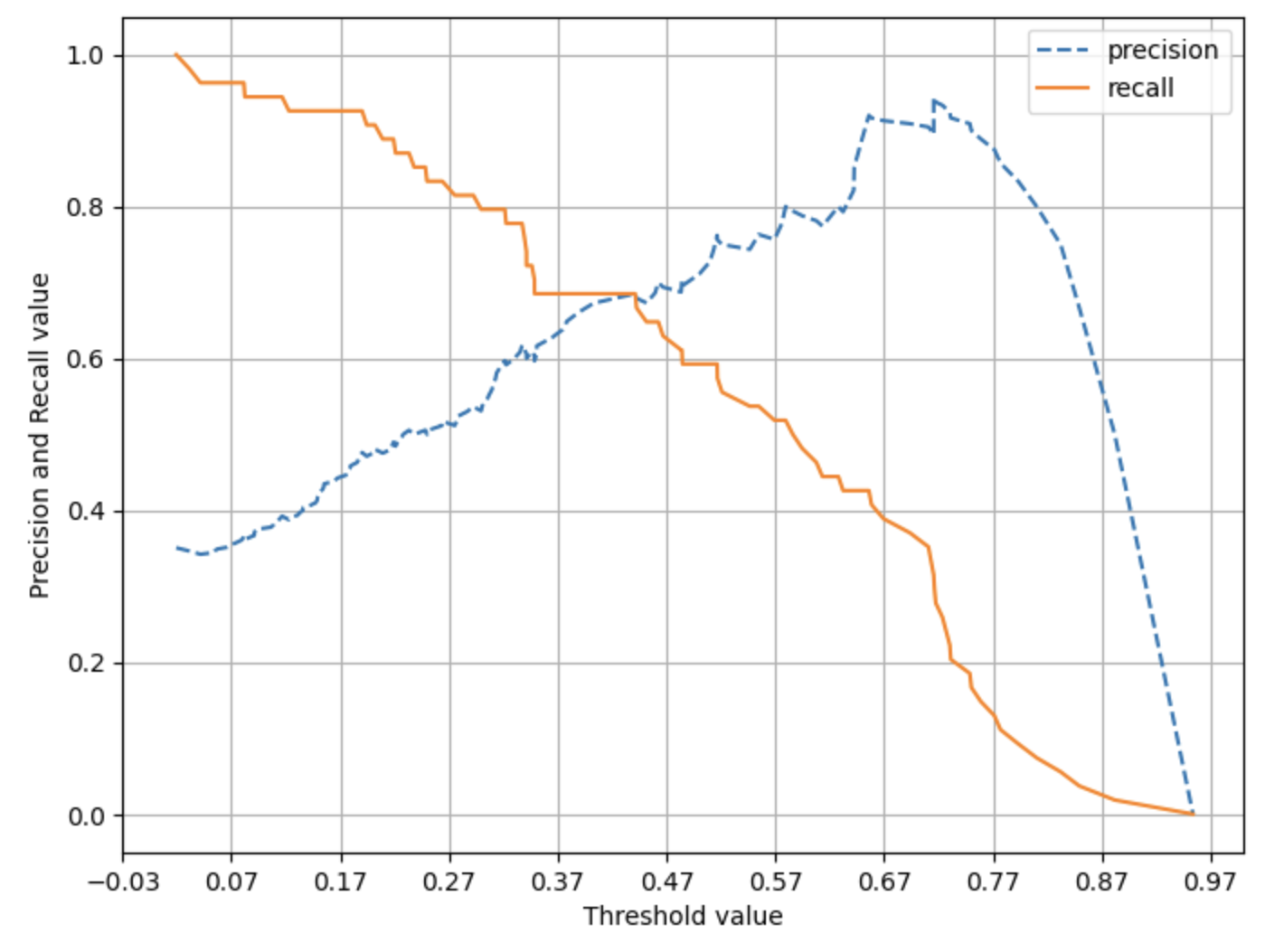
- 재현율 곡선을 보면 임곗값을 0.42 정도로 낮추면 정밀도와 재현율이 어느 정도 균형을 맞출 것 같음
- 하지만 두 개의 지표 모두 0.7 이 안 되는 수치로 보임.
- 여전히 두 지표의 값이 낮음.
임계값을 인위적으로 조작하기 전에 다시 데이터 값을 점검하겠습니다.
- 먼저 원본 데이터 DataFrame의
describe()메서드를 호출해 피처 값의 분포도를 살펴볼 예정임.
diabetes_data.describe()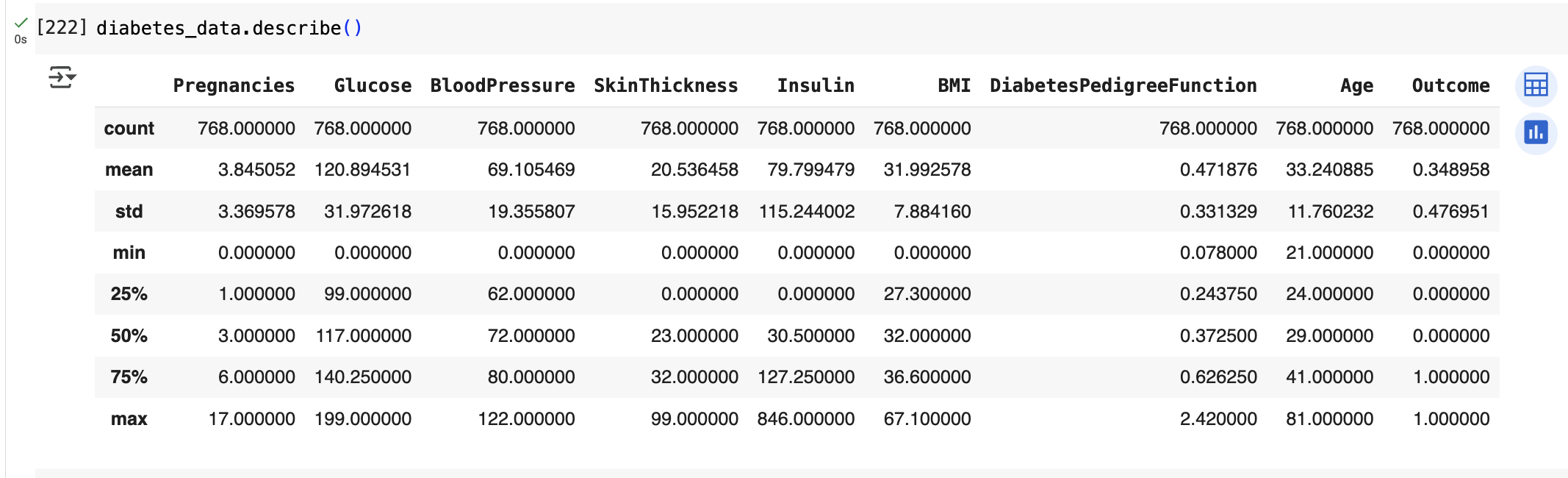
diabetes_data.describe() 데이터 값을 보면
- min() 값이 0 으로 돼 있는 피처가 상당히 많음.
- 예) Glucose 피처는 포도당 수치인데 min 값이 0 인 것은 불가. -> Glucose 피처의 히스토그램을 확인해 보면 0 값이 일정 수준 존재함
plt.hist(diabetes_data['Glucose'], bins=100)
plt.show()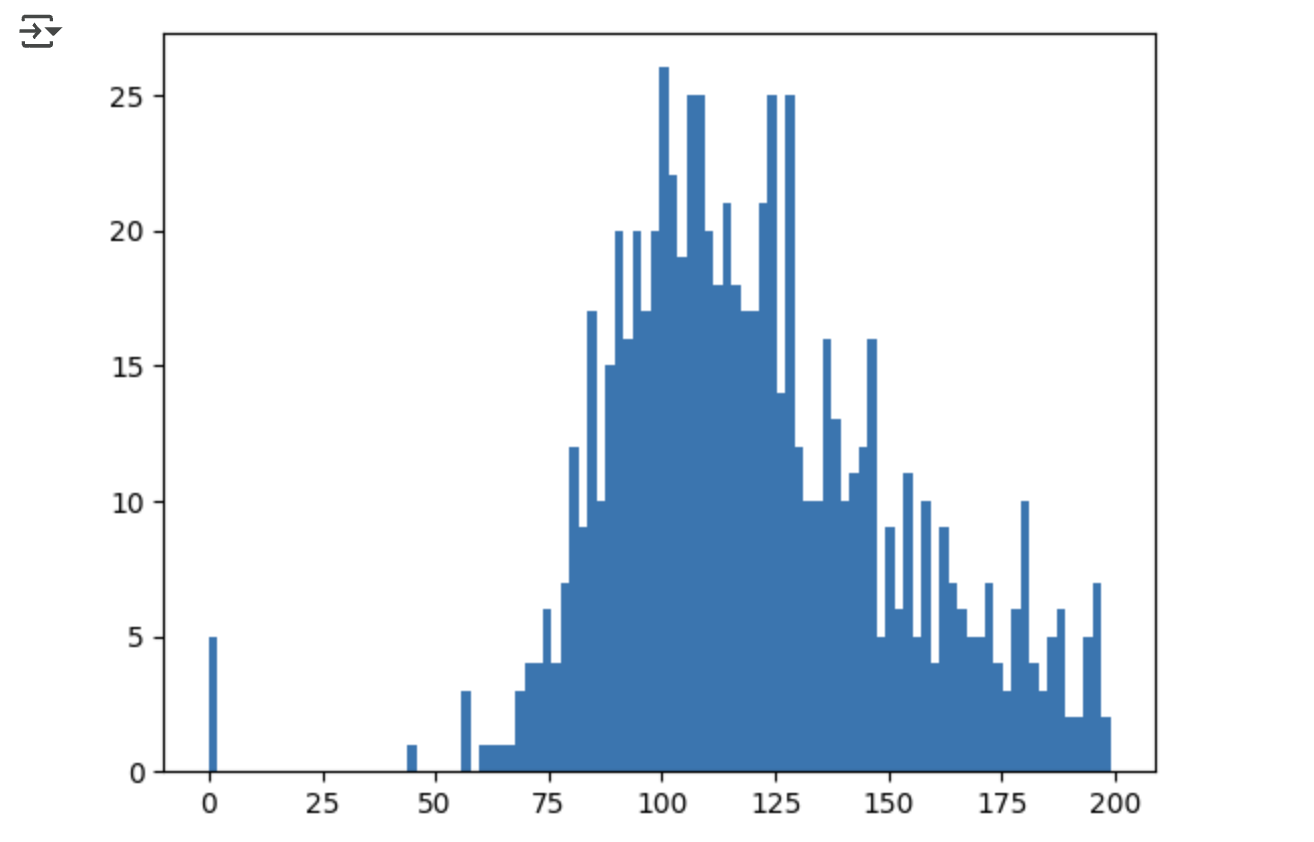
min() 값이 0 으로 돼 있는 피처에 대해 0 값의 건수 및 전체 데이터 건수 대비 몇 퍼센트의 비율로 존재하는지 확인해 보는 예제
- 확인할 피처는 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin' ,'BMI' (Pregnancies 는 출산 횟수를 의미하므로 제외)
# 0 값을 검사할 피처명 리스트
zero_features = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
# 전체 데이터 건수
total_count = diabetes_data['Glucose'].count()
# 피처별로 반복하면서 데이터 값이 0 인 데이터 건수를 추출하고 , 퍼센트 계산
for feature in zero_features:
zero_count = diabetes_data[diabetes_data[feature] == 0][feature].count()
print('{0} 0 건수는 {1}, 퍼센트는 {2:.2f}%'.format(feature, zero_count,100*zero_count/total_count))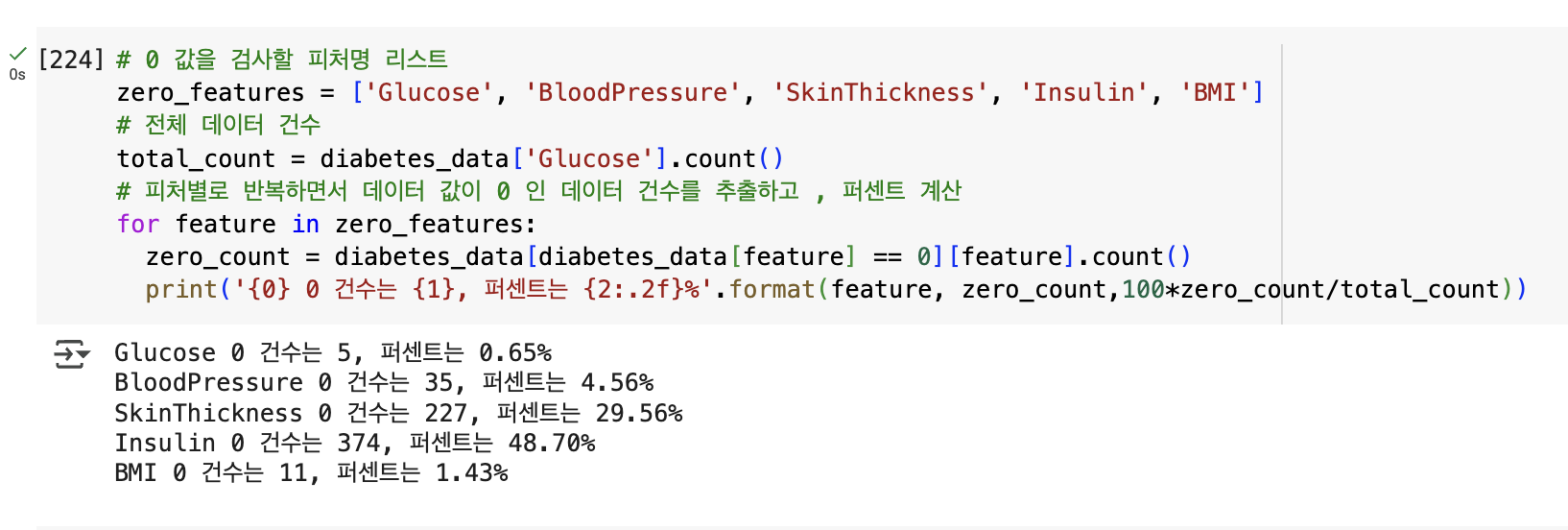
- SkinThickness와 Insulin의 0 값은 각각 전체의 29.56%, 48.7%로 대단히 많음
- 전체 데이터 건수가 적기 때문에 이들 데이터를 일괄적으로 삭제할 경우에는 학습을 효과적으로 수행하기 어려움.
- 위 피처의 0 값을 평균값으로 대체함
# zero_features 리스트 내부에 저장된 개별 피처들에 대해서 0 값을 평균 값으로 대체
mean_zero_features = diabetes_data[zero_features].mean()
diabetes_data[zero_features]=diabetes_data[zero_features].replace(0, mean_zero_features)- 0 값을 평균값으로 대체한 데이터 세트에 피처 스케일링을 적용해 변환함.
- 로지스틱 회귀의 경우 일반적으로 숫자 데이터에 스케일링을 적용하는 것이 좋음.
X = diabetes_data.iloc[:, :-1]
y = diabetes_data.iloc[:, -1]
# Standardscaler 클래스를 이용해 피처 데이터 세트에 일괄적으로 스케일링 적용
scaler = StandardScaler( )
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size = 0.2, random_state = 156, stratify=y)
# 로지스틱 회귀로 학습 , 예측 및 평가 수행.
lr_clf = LogisticRegression()
lr_clf. fit(X_train, y_train)
pred = lr_clf.predict(X_test)
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
get_clf_eval (y_test, pred, pred_proba)
- 데이터 변환과 스케일링을 통해 성능 수치가 일정 수준 개선됨
- 로지스틱 회귀에 대해 본격적으로 학습하지 않았으니 하이퍼 파라미터에 대한 튜닝은 생략.
- 하지만 여전히 재현율 수치는 개선이 필요함
분류 결정 임곗값을 변화시키면서 재현율 값의 성능 수치가 어느 정도나 개선되는지 확인해 보겠습니다.
- 임곗값을 0.3 에서 0.5 까지 0.03 씩 변화시키면서 재현율과 다른 평가 지표의 값 변화를 출력
- 임곗값에 따른 평가 수치 출력은 앞에서 사용한
get_eval_by_threshold()함수를 이용
thresholds = [0.3, 0.33, 0.36, 0.39, 0.42, 0.45, 0.48, 0.50]
pred_proba = lr_clf.predict_proba(X_test)
get_eval_by_threshold(y_test, pred_proba[:, 1].reshape(-1, 1), thresholds)
- 임곗값 0.33: 재현율 0.7963으로 가장 높지만, 정밀도 0.5972로 매우 낮아 극단적인 선택
- 임곗값 0.48: 전체 성능 지표를 균형 있게 유지하면서 재현율도 소폭 향상
정확도: 0.7987
정밀도: 0.7447
재현율: 0.6481
F1 스코어: 0.6931
ROC AUC: 0.8433 predict()메서드는 임곗값 조정 불가 →predict_proba()+ Binarizer로 임곗값 0.48을 적용해 예측 수행- 학습된 로지스틱 회귀 모델에 대해 임곗값을 0.48로 조정한 예측 로직을 별도로 구현할 예정
# 임곗값을 0.48 로 설정한 Binarizer 생성
binarizer = Binarizer (threshold=0.48)
# 위에서 구한 Ir_clf의 predict_proba() 예측 확률 array 에서 1 에 해당하는 칼럼값을 Binarizer 변환.
pred_th_048 = binarizer.fit_transform(pred_proba[:, 1].reshape(-1, 1))
get_clf_eval(y_test, pred_th_048, pred_proba[:, 1])
7. 정리
-
분류에 사용되는 정확도 , 오차 행렬 , 정밀도 , 재현율 , F1 스코어 , ROC-AUC 와 같은 성능 평
가 지표 -
이진 분류의 레이블 값이 불균형하게 분포될 경우
0 이 매우 많고 ,
1이 매우 적을 경우 또는 반대의 경우
-
단순히 예측 결과와 실제 결과가 일치하는 지표인 정확도만으로는 머신러닝 모델의 예측 성능을 평가 불가
-
오차 행렬은 Negative와 Positive 값을 가지는 실제 클래스 값과 예측 클래스 값이 True와 False 에 따라 TN, FP, FN, TP 로 매핑되는 4 분면 행렬을 기반으로 예측 성능을 평가.
-
정확도 , 정밀도 , 재 현율 수치는 TN, FP, FN, TP 값을 다양하게 결합해 만들어지며 , 이를 통해 분류 모델 예측 성능의 오류가 어떠한 모습으로 발생하는지 알 수 있음
-
정밀도(Precision)와 재현율 (Recall) 은 Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표임
-
특히 재현율이 상대적으로 더 중요한 지표인 경우는 암 양성 예측 모델과 같이 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우임
-
분류하려는 업무의 특성상 정밀도 또는 재현율이 특별히 강조돼야 할 경우 분류의 결정 임곗값 (Threshold)을 조정해 정밀도 또는 재현율의 수치를 높이는 방법
-
F1 스코어는 정밀도와 재현율을 결합한 평가 지표이며 , 정밀도와 재현율이 어느 한 쪽으로 치우치지 않을 때 높은 지표값을 가지게 됨.
-
ROC-AUC 는 일반적으로 이진 분류의 성능 평가를 위해 가장 많이 사용되는 지표임.
-
AUC(Area Under Curve) 값은 ROC 곡선 밑의 면적을 구한 것으로서 일반적으로 1 에 가까울수록 좋은 수치임
