[논문리뷰] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Multi-Modal 논문 리뷰
https://arxiv.org/abs/2102.0598
2021년 Google AI에서 발표한 논문이다.
[ Abstract ]
NLP에서는 사람이 직접 주석을 달지 않은 텍스트 데이터를 사용하여 학습하는 방식으로 전환되고 있지만, Vision 학습이나 Vision-NLP 표현 학습은 여전히 전문가의 지식이 필요한 정제된 Train 데이터셋에 크게 의존하고 있다. 예를 들어, Vision 학습에는 ImageNet이나 OpenImages 같은 명확한 클래스 레이블이 있는 데이터셋을 주로 사용하고, 시각-언어 표현 학습에는 Conceptual Captions, MSCOCO, CLIP 같은 데이터셋을 사용하는데, 이러한 데이터셋을 만드는 과정은 복잡하고 비용이 많이 든다. 이러한 비용이 많이 드는 데이터 정제 과정 때문에 데이터셋의 크기가 제한되고, 그로 인해 훈련된 모델의 확장성이 저하된다.
이 논문에서는 이러한 문제를 해결하기 위해 비정제된 데이터셋을 사용합니다. 저자들은 사람에 의한 필터링이나 후처리 없이 얻은 10억 개 이상의 이미지와 대체 텍스트(alt-text) 쌍을 활용해 학습한다. 간단한 듀얼 인코더(dual-encoder) 구조를 사용하여 이미지와 텍스트 쌍의 시각적 및 언어적 표현을 대조 손실(contrastive loss)을 통해 정렬하는 방식으로 학습한다. 저자들은 이처럼 단순한 학습 방식에도 불구하고 대규모 데이터셋이 포함된 노이즈가 결과에 큰 영향을 미치지 않으며, 오히려 최첨단(state-of-the-art) 표현을 학습할 수 있음을 보여준다.
이 논문의 핵심은 크고 노이즈가 있는 데이터셋이 데이터 정제 과정을 거치지 않고도 Vision 및 Vision-NLP 학습을 가능하게 한다는 점이다.
[ Introduction ]
기존 문제점 (1)
Vision 학습에서는 ImageNet, OpenImages, JFT 300M과 같은 대규모 정제된 데이터에 의존해 학습하는 것이 중요한데, 이런 데이터셋을 준비하려면 데이터 수집, 샘플링, 인간 후처리 작업에 많은 노력이 들어가며 확장하기 어렵다.
기존 문제점 (2)
Vision-NLP 표현 학습에서도 Conceptual Captions, Visual Genome Dense Captions, ImageBERT 같은 데이터셋을 사용하지만, 이는 더 많은 인간 주석 작업과 의미 파싱, 데이터 정제, 균형 작업이 필요해 데이터셋의 규모가 크지 않다. 예를 들어, 이러한 데이터셋들은 약 1천만 개 정도의 예시로 구성되어 있어, Vision 학습에만 사용되는 데이터셋보다 규모가 훨씬 작다.
위와 같은 문제점들로, 본 논문은 10억 개 이상의 노이즈가 있는 이미지와 대체 텍스트(alt-text) 쌍을 활용해 시각적 표현 학습과 Vision-NLP 표현 학습을 확장한다. 기존의 Conceptual Captions 데이터셋을 참고하지만, 복잡한 필터링 및 후처리 과정을 생략하고 단순한 빈도 기반 필터링만 적용한다. 그 결과 데이터셋은 다소 노이즈가 있지만 크기가 기존 데이터셋보다 100배 더 크다.
결론적으로, ALIGN은 노이즈가 있는 대규모 데이터셋을 활용해 시각적 표현 학습과 Vision-NLP 학습에서 탁월한 성과를 냈으며, 복잡한 교차 주의 모델 없이도 최첨단 성능을 달성할 수 있음을 증명했다.
[ Related Work ]
기존 연구들은 주로 작은 데이터셋에 국한되며, 크로스 모달 검색 같은 작업에 필요한 Vision-NLP 표현을 학습하지는 못한다. Vision-NLP 표현 학습에서는 시각-의미 임베딩(VSE)이 자주 사용되며, 이는 객체 검출기, 밀집 특징 맵, 다중 주의 메커니즘 등을 활용해 성능을 개선해왔다. 최근에는 교차 모달 주의 레이어를 사용하는 더 발전된 모델들이 등장하여 이미지-텍스트 매칭 작업에서 뛰어난 성능을 보여주지만, 이러한 모델들은 매우 느리고, 실제 이미지-텍스트 검색 시스템에 적용하기에는 비효율적이라는 한계가 있다.
저자들의 모델은 이와 대조적으로 단순한 VSE 형태를 따르면서도, 기존의 복잡한 교차 모달 주의 모델들보다 이미지-텍스트 매칭 벤치마크에서 더 나은 성능을 보여준다. 저자들이 제시한 ALIGN 모델은 CLIP과 유사하게 자연어 감독을 통한 대조 학습을 사용해 시각적 표현을 학습하는 방법이지만, 두 모델 간의 주요 차이는 훈련 데이터에 있다. CLIP은 영어 위키피디아에서 고빈도 시각 개념을 기반으로 허용 목록을 만들어 데이터셋을 구성하지만, ALIGN은 전문 지식 없이 노이즈가 포함된 원시 이미지-텍스트 쌍의 자연 분포를 따른다.
결론적으로, ALIGN은 더 단순한 데이터 수집 과정과 더 큰 데이터셋을 사용하지만, CLIP은 더 정교한 데이터 필터링 과정을 통해 데이터 품질을 보장하고 있다.
[ A Large-Scale Noisy Image-Text Dataset ]

이 논문에서는 Vision 및 Vision-NLP 표현 학습을 확장하는 것이 목표로, 이를 위해 기존 데이터셋보다 훨씬 더 큰 데이터셋을 사용한다. 저자들은 Conceptual Captions 데이터셋을 구축할 때 사용된 방법론을 따라 원시 영어 alt-text 데이터(이미지와 alt-text 쌍)를 사용해 데이터셋을 구성했다. Conceptual Captions 데이터셋은 정교한 필터링 및 후처리 과정을 통해 데이터를 정제했지만, 이 논문에서는 데이터 품질을 일부 희생하고 대신 데이터 규모를 확장하는 방법을 택했다. 원래 데이터 정제 과정에서 대부분의 정리 작업을 생략하고, 최소한의 빈도 기반 필터링만 적용했다. 그 결과로, 1.8억 개의 이미지-텍스트 쌍을 포함하는 더 큰 규모의 데이터셋이 만들어졌지만, 다소 노이즈가 포함되었다. 데이터 필터링은 크게 두 가지 방식으로 이루어진다. 이미지 기반 필터링과 텍스트 기반 필터링이다.
-
이미지 기반 필터링:
먼저, 음란물 이미지는 제거되었으며, 짧은 변의 길이가 200픽셀 이하인 이미지와 종횡비(aspect ratio)가 3을 넘는 이미지는 제외되었다.
또한, 평가용 데이터셋과의 중복 이미지를 방지하기 위해, 테스트 이미지와 동일하거나 유사한 이미지는 제거되었다. -
텍스트 기반 필터링:
10개 이상의 이미지에서 공유되는 alt-text는 제거되었다. 이러한 텍스트는 이미지 내용과 관계없을 가능성이 높기 때문이다.
100만 개의 빈도 높은 유니그램과 바이그램에 포함되지 않는 희귀 단어를 포함한 alt-text는 제외되었다. 너무 짧은 텍스트(3개 이하의 단어) 또는 너무 긴 텍스트(20개 이상의 단어)도 제거되었다. 예를 들어, "image tid 25&id mggqpuweqdpd&cache 0&lan code 0"와 같은 노이즈성 텍스트나 너무 일반적인 텍스트는 유용하지 않다고 판단했다.
이러한 필터링 과정을 통해, 더 큰 규모의 데이터셋을 유지하면서도 어느 정도의 품질을 보장하는 노이즈가 있는 데이터셋을 구축했다.
[ Pre-training and Task Transfer ]
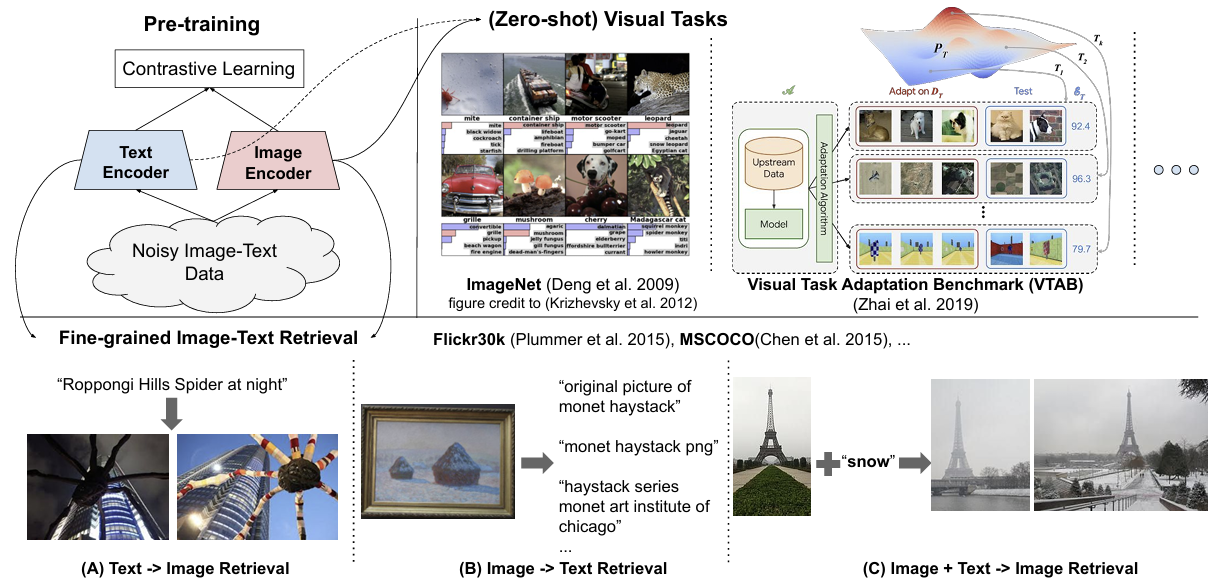 위 그림은 ALIGN 모델의 학습 및 평가 과정을 전반적으로 설명한 것이다. 크게 세 가지 중요한 부분으로 나눌 수 있다. Pre-training, Fine-grained Image-Text Retrieval, 그리고 Zero-shot Visual Tasks이다.
위 그림은 ALIGN 모델의 학습 및 평가 과정을 전반적으로 설명한 것이다. 크게 세 가지 중요한 부분으로 나눌 수 있다. Pre-training, Fine-grained Image-Text Retrieval, 그리고 Zero-shot Visual Tasks이다.
-
Pre-training (사전 학습)
그림의 왼쪽 상단에서는 대조 학습(Contrastive Learning)을 통해 텍스트 인코더와 이미지 인코더를 동시에 학습하는 과정을 보여준다. ALIGN 모델은 노이즈가 있는 이미지-텍스트 데이터를 사용하여 학습되며, 텍스트와 이미지를 각각 텍스트 인코더와 이미지 인코더를 통해 임베딩한다. 대조 학습을 통해 텍스트와 이미지의 표현을 동일한 임베딩 공간에 정렬하여, 이미지-텍스트 매칭 작업에서 성능을 향상시키는 방식이다. -
Fine-grained Image-Text Retrieval (세분화된 이미지-텍스트 검색)
중간 하단에서는 세 가지 이미지-텍스트 검색 작업을 보여준다.
(A) 텍스트 -> 이미지 검색: 텍스트 쿼리를 주면 그에 맞는 이미지를 찾습니다. 예를 들어, "Roppongi Hills Spider at night"이라는 텍스트를 입력했을 때 해당 이미지를 검색한다.
(B) 이미지 -> 텍스트 검색: 이미지를 주면 그에 맞는 설명이나 텍스트를 찾아냅니다. 예를 들어, 그림을 주면 관련 텍스트가 검색된다.
(C) 이미지 + 텍스트 -> 이미지 검색: 이미지와 텍스트를 동시에 입력하여 더 구체적인 이미지를 검색할 수 있다. 예를 들어, "Eiffel Tower" 이미지에 "snow"라는 텍스트를 추가하면, 눈 내리는 에펠탑 이미지를 검색한다. -
Zero-shot Visual Tasks (제로샷 시각적 작업):
오른쪽 상단에서는 ALIGN 모델을 ImageNet 같은 시각적 작업에 제로샷으로 전이하는 과정을 보여준다. 이는 사전 학습된 모델을 사용하여 새로운 데이터에 맞게 모델을 미세 조정하거나, 추가적인 학습 없이 곧바로 이미지 분류 작업을 수행할 수 있음을 의미한다.
(1) Pre-training on Noisy Image-Text Pairs
ALIGN 모델은 듀얼 인코더 아키텍처를 사용하여 사전 학습된다. 이 모델은 이미지 인코더와 텍스트 인코더 쌍으로 구성되며, 이들의 출력을 상단에서 코사인 유사도를 통해 결합한다. 이미지 인코더로는 EfficientNet을 사용하고, 텍스트 인코더로는 BERT를 사용한다. EfficientNet에서는 글로벌 풀링을 사용하고, 분류 헤드의 1x1 합성곱 레이어는 학습하지 않는다. BERT는 [CLS] 토큰 임베딩을 사용해 텍스트 임베딩을 생성하며, 훈련 데이터셋에서 생성한 100k개의 워드피스(wordpiece) 어휘를 활용한다. BERT 인코더 상단에는 이미지 인코더와 차원을 맞추기 위한 Fully Connected Layer가 추가된다. 이미지와 텍스트 인코더는 모두 처음부터 학습된다.

이미지와 텍스트 인코더는 normalized softmax loss을 통해 최적화된다.

Positive: 일치하는 이미지-텍스트 쌍
Negative: 일치하는 쌍을 제외한 다른 모든 random한 이미지-텍스트 쌍
Negative는 noisy한 데이터가 될 수 있지만 dataset의 거대한 scale이 noisy를 덜어준다.
(2) Transferring to Image-Text Matching & Retrieval
ALIGN 모델은 이미지-텍스트 매칭 및 검색 작업에서 전이 성능을 평가한다. 이를 위해 세 가지 주요 데이터셋에서 실험을 진행한다.
첫째, Flickr30K과 MSCOCO 데이터셋을 사용해 이미지-텍스트 및 텍스트-이미지 검색 작업을 수행하며, finetuning을 적용한 경우와 그렇지 않은 경우 모두 평가한다.
둘째, MSCOCO의 확장판인 Crisscrossed Captions (CxC) 데이터셋에서도 ALIGN 모델을 평가한다. CxC는 이미지-텍스트 쌍 외에도, 캡션-캡션, 이미지-이미지 등의 쌍에 대한 추가적인 사람이 부여한 의미적 유사성 판단(semantic similarity judgments)을 제공하는 데이터셋이다. CxC는 네 가지 모달리티 내외의 검색 작업을 지원하는데, 여기에는 이미지-텍스트 검색, 텍스트-이미지 검색, 텍스트-텍스트 검색, 이미지-이미지 검색이 포함된다.
마지막으로, 세 가지 의미적 유사성 평가 작업도 수행할 수 있다. 이에는 텍스트 의미 유사성(STS), 이미지 의미 유사성(SIS), 이미지-텍스트 의미 유사성(SITS) 평가가 포함된다.
ALIGN 모델은 MSCOCO와 동일한 학습 데이터를 사용하기 때문에, MSCOCO로 파인튜닝된 모델을 CxC 주석 데이터를 기반으로 바로 평가할 수 있다. 이를 통해 ALIGN의 크로스 모달 검색 및 의미적 유사성 평가 성능을 종합적으로 검증한다.
(3) Transferring to Visual Classification
ALIGN 모델은 이미지 분류 작업에서도 제로샷 전이 성능을 평가하며, 이를 위해 ImageNet ILSVRC-2012 벤치마크와 그 변형 데이터셋에서 실험을 진행한다. 이러한 변형 데이터셋에는 ImageNet-R(비자연 이미지: 예술, 만화, 스케치 등), ImageNet-A(머신러닝 모델에 더 도전적인 이미지), ImageNet-V2가 포함되며, 모두 ImageNet과 동일한 클래스 또는 하위 클래스를 따르지만, ImageNet-R과 ImageNet-A는 ImageNet과 매우 다른 분포에서 샘플링된 이미지들로 구성된다.
ALIGN의 이미지 인코더는 다운스트림 시각적 분류 작업에서도 전이되어 평가된다. 이를 위해 ImageNet뿐만 아니라 세분화된 소규모 분류 데이터셋에서도 실험을 수행하는데, 여기에는 Oxford Flowers-102, Oxford-IIIT Pets, Stanford Cars, Food101 같은 데이터셋이 포함된다. ImageNet에서는 두 가지 설정으로 결과를 보고하는데, 하나는 ALIGN 이미지 인코더를 고정한 상태에서 분류 레이어만 학습하는 경우이고, 다른 하나는 전체 모델을 파인튜닝한 경우이다. 세분화된 분류 데이터셋에서는 파인튜닝 설정으로만 결과를 보고한다.
또한, 모델의 견고성을 평가하기 위해 VTAB(Visual Task Adaptation Benchmark)에서도 실험을 수행한다. VTAB는 자연 이미지, 전문화된 이미지, 구조화된 이미지 분류 작업으로 세분화된 19가지 다양한 시각 분류 작업으로 구성되어 있으며, 각 작업마다 1000개의 학습 샘플을 사용한다. 이러한 다양한 실험을 통해 ALIGN 모델의 시각적 분류 작업에서의 전이 학습 성능을 종합적으로 평가한다.
[ Experiments and Results ]
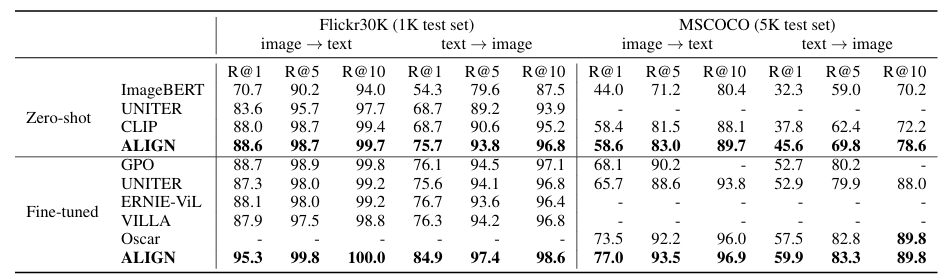 ALIGN은 Flickr30K와 MSCOCO 벤치마크에서 모든 지표에서 최첨단(SOTA) 성과를 달성한다. 특히 제로샷 설정에서 이미지 검색 작업에서 이전 SOTA 모델인 CLIP보다 7% 이상 개선되었다. 파인튜닝 후에도 cross-modal attention 레이어를 사용하는 ImageBERT, UNITER, ERNIE-ViL, VILLA, Oscar 등의 모델보다도 큰 폭으로 성능이 우수하다.
ALIGN은 Flickr30K와 MSCOCO 벤치마크에서 모든 지표에서 최첨단(SOTA) 성과를 달성한다. 특히 제로샷 설정에서 이미지 검색 작업에서 이전 SOTA 모델인 CLIP보다 7% 이상 개선되었다. 파인튜닝 후에도 cross-modal attention 레이어를 사용하는 ImageBERT, UNITER, ERNIE-ViL, VILLA, Oscar 등의 모델보다도 큰 폭으로 성능이 우수하다.
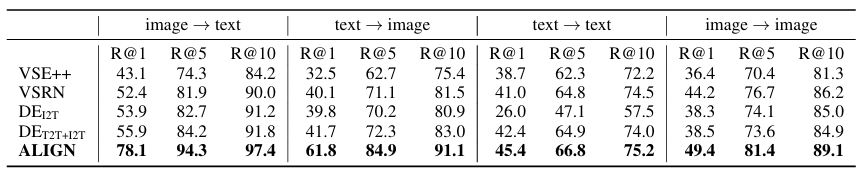 Crisscrossed Captions (CxC)에서도 ALIGN은 이미지-텍스트 및 텍스트-이미지 검색에서 22.2% R@1 및 20.1% R@1 개선을 기록한다. 다만, 동일 모달 작업(예: 텍스트-텍스트, 이미지-이미지)에서는 성능이 비교적 덜 개선되었는데, 이는 ALIGN의 학습 목표가 주로 크로스 모달 매칭에 초점을 맞추었기 때문이라고 분석한다.
Crisscrossed Captions (CxC)에서도 ALIGN은 이미지-텍스트 및 텍스트-이미지 검색에서 22.2% R@1 및 20.1% R@1 개선을 기록한다. 다만, 동일 모달 작업(예: 텍스트-텍스트, 이미지-이미지)에서는 성능이 비교적 덜 개선되었는데, 이는 ALIGN의 학습 목표가 주로 크로스 모달 매칭에 초점을 맞추었기 때문이라고 분석한다.
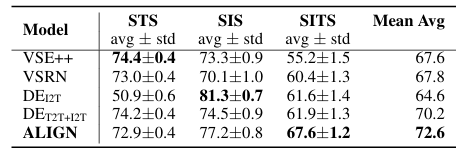 텍스트 의미 유사성(STS), 이미지 의미 유사성(SIS), 이미지-텍스트 의미 유사성(SITS) 평가의 종합 평균 역시 ALIGN이 가장 높은 것을 알 수 있다.
텍스트 의미 유사성(STS), 이미지 의미 유사성(SIS), 이미지-텍스트 의미 유사성(SITS) 평가의 종합 평균 역시 ALIGN이 가장 높은 것을 알 수 있다.
 이 표는 ALIGN과 CLIP 모델을 ImageNet과 그 변형 데이터셋들에서 비교한 Top-1 정확도 결과를 보여준다. ALIGN은 ImageNet-R(예술, 만화, 스케치)에서 CLIP보다 더 뛰어난 성능을 보여주며, 특히 비자연 이미지에서 성능이 좋다.
이 표는 ALIGN과 CLIP 모델을 ImageNet과 그 변형 데이터셋들에서 비교한 Top-1 정확도 결과를 보여준다. ALIGN은 ImageNet-R(예술, 만화, 스케치)에서 CLIP보다 더 뛰어난 성능을 보여주며, 특히 비자연 이미지에서 성능이 좋다.
 위 그림은 ALIGN 모델을 사용한 텍스트-이미지 검색 시스템의 작동 방식을 보여준다. ALIGN을 활용해 텍스트 쿼리로부터 가장 적합한 이미지를 검색하는 시스템을 구현하며, 그림은 세 가지 쿼리 그룹에 대한 검색 결과를 시각적으로 나타낸다.
위 그림은 ALIGN 모델을 사용한 텍스트-이미지 검색 시스템의 작동 방식을 보여준다. ALIGN을 활용해 텍스트 쿼리로부터 가장 적합한 이미지를 검색하는 시스템을 구현하며, 그림은 세 가지 쿼리 그룹에 대한 검색 결과를 시각적으로 나타낸다.
-
"Van Gogh Starry Night ...":
이 부분에서는 "반 고흐의 별이 빛나는 밤"에 대한 세부적이고 구체적인 텍스트 설명을 통해 이미지를 검색한다. 예를 들어, "세부", "흑백으로", "캔버스에", "어두운 나무 프레임에"라는 설명을 입력하면, 이러한 텍스트에 맞는 다양한 각도나 표현 방식의 별이 빛나는 밤 이미지들이 검색된다. -
"Lombard street ...":
"롬바드 스트리트"라는 유명한 장소를 여러 각도에서 묘사하는 설명을 입력해 이미지를 검색한다. 예를 들어, "아래에서 본 모습", "위에서 본 모습", "조감도", "폭우 속에서"와 같은 텍스트 설명을 통해 각기 다른 시점과 상황에서 찍힌 롬바드 스트리트의 이미지를 검색한다. -
"seagull in front of ...":
마지막으로, 특정 랜드마크 앞에 있는 갈매기를 묘사하는 설명을 통해 이미지를 검색한다. 예를 들어, "골든 게이트 브리지", "런던 타워 브리지", "시드니 하버 브리지", "리알토 브리지"와 같은 텍스트 쿼리에 맞는 갈매기가 있는 랜드마크 이미지를 검색한다.
이 예시는 ALIGN 모델이 텍스트와 이미지 간의 유사한 의미를 어떻게 정렬하는지, 그리고 세밀한 설명이나 세분화된 개념을 기반으로 새롭고 복잡한 개념을 검색하는 데 얼마나 효과적인지를 보여준다.
[ Conclusion ]
대규모 노이즈가 포함된 이미지-텍스트 데이터를 활용해 Vision 및 Vision-NLP 표현 학습을 확장하는 간단한 방법을 제시한다. 이 방법은 복잡한 데이터 큐레이션이나 주석 작업을 최소화하고, 빈도 기반의 간단한 정제 작업만을 필요로 한다. 이 데이터셋을 통해 contrastive loss을 사용하는 듀얼 인코더 모델을 학습했으며, 이 모델인 ALIGN은 크로스 모달 검색에서 뛰어난 성능을 보여주며, 기존 모델들을 크게 능가한다. 또한, 시각적 다운스트림 작업에서도 ALIGN은 대규모 레이블이 있는 데이터로 학습된 모델들과 비슷하거나 더 우수한 성능을 보여준다.
