
airflow - task 실행 흐름
"워커는 자리를 비우고 큐에 쌓여있는 다른 중요한 태스크를 가져와서 병렬로 일하기 시작합니다. 그동안 트리거러는 백그라운드에서 아주 가볍게(비동기로) 대기 상태를 모니터링하다가, 마침내 외부 응답이 딱 도착하면 스케줄러에게 알립니다. 스케줄러는 이 태스크를 다시 큐에
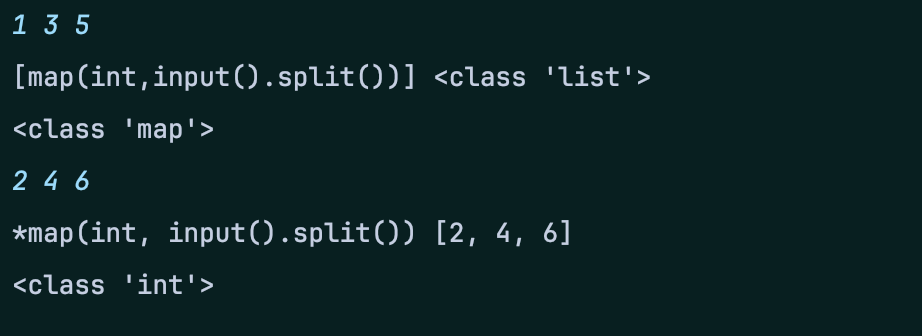
python map unpacking
알고리즘 문제를 풀다가라는 코드가 있었다. 정말 자연스럽게 주어진 코드였는데 문득,로 코드를 작성하는 게 더 간이할 것 같은데? 라는 생각이 들었다.정말 많이 쓰는 코드니까 당연히 되겠지 싶었는데 \[]는 안된다.map()은 주어진 코드에 따라int 형변환을 하려고 대
2026.04.24(Fri)
Rating ClassPySpark(MLlib)에서 추천 시스템 모델(ALS) 만들 때 아주 표준적으로 사용하는 데이터 틀.UserProductRatingRating 객체는 내부적으로 namedtuple과 비슷하게 동작한다. my_rating.user처럼 속성값에 쉽게
2026.04.23(Thu)
RDD(Resilient Distributed Dataset) 회복 탄력성이 있는 분산 데이터셋요즘은 잘 사용하지 않고 DataFrame을 사용하지만, 그 근간이 되는 low-level API이다.주요 특징Resilient(회복력) : 데이터 손실이 일어나도, RDD는
2026.04.22(Wed)
→ KeyError 발생Boolean Indexing을 사용할 때는 대괄호 \[] 안에 들어가는 데이터의 형태가 중요하다.1\. 대괄호 \[] 내부의 데이터 타입PySpark \_\_\_Apache Spark : 대규모 데이터를 빠르게 처리하도록 설계된 오픈 소스 분산
2026.04.21(Tue)
테스트를 실행하기 위해 필요한 준비물@pytest.fixture라는 데코레이터를 사용해서 함수를 정의하면 다른 테스트 함수들이 이름을 파라미터처럼 넘겨받아 사용할 수 있다.Fixture의 범위 (Scope)fixture를 매번 새로 만들지, 아니면 한 번 만들어서 계속
2026.04.19(Sun)
코드 재사용DRY : 반복하지 말 것 Python Class Decorator \_\_\_python에서 decorator는 호출 가능한 객체(Callable)를 받아서 다른 객체를 반환하는 함수기존 기능을 수정하지 않고 새로운 기능을 추가class decorator는
2026.04.17(Fri)
sort puts data in order. By default it does this in ascending alphabetical order, but the flags -n and -r can be used to sort numerically and reverse
2026.04.16(Thu)
데이터 처리 탐색데이터 품질 : 점검 및 변환분석집계변환배치 처리 배치 & 스트리밍고정된 시간 처리스트리밍 처리 (고정 시간 윈도우 & 슬라이딩 시간 윈도우)윈도우 : 연속적인 데이터 스트림을 시간 또는 크기 기준으로 나눈 파티션으로, 계산과 집계를 수행하기 위해 사용
2026.04.15(Wed)
데이터는 사실과 수치의 비조직적이고 맥락 없는 집합이다.아날로그와 디지털 형식이 있고다양한 곳에서 데이터가 수집된다.→ 원천 시스템 문서를 읽고 그 패턴과 특이점을 이해하자→ RDBMS를 사용한다면 그 시스템의 작동 방식을 익히고 영향을 줄 수 있는 요소들을 파악하자.
2026.04.13(Mon)
EmptyOperator : 문제 해결을 위한 task나 아직 구현되지 않은 task를 표현하는 데 사용BashOperator : 지정된 Bash 명령어나 스크립트 실행워크플로우 맥락에서 의미가 있다면, Bash가 할 수 있는 거의 모든 동작을 수행할 수 있다.실제 액
2026.04.12(Sun)
DAG(Directed Acyclic Graph) : 방향 비순환 그래피Airflow에서 워크플로를 구성하는 작업 집합작업과 작업 간 의존성으로 구성메타데이터와 함께 생성airflow tasks test <dag_id> <task_id> \[execution
2026.4.10(Fri)
usecols 키워드 인자 : import할 모든 열의 이름 리스트나 열 번호 리스트를 전달함수를 전달해 열 선택 가능nrows 인자 : 임포트되는 행의 수 선택파일을 chunks 단위로 처리하기 위해 skiprows 인자와 결합할 때 유용하다skiprows : 건너뛸
2026.04.09(Thu)
date() →연, 월, 일 date(2000, 10, 16), date(2000, 8, 24)sort_values() : Dataframe이나 series에서 사용하는 메서드list 타입을 정렬하려면 내장 함수 sorted()나 sort()를 사용해야 한다. sort
2026.04.08(Wed)
dbt workflow 1\. dbt init2\. profiles.yml 파일에서 설정 정의, 업데이트3\. 데이터 모델 정의 & 사용 (dbt run) \- 데이터 모델 : 데이터 웨어하우스에 저장된 원천 데이털르 변환한 결과 \- dbt run : 원본 SQL 코
2026.04.07(Tue)
sheet_name=None으로 인수를 전달하면 모든 시트가 dictionary 형태로 반환됨.sheet_name을 인수로 전달하지 않으면 첫 번째 시트만 반환된다.각 스프레드 시트의 이름을 알고 싶다면 xls.keys()로 키값을 구해야 된다.웹 개발에서 tag so
2026.04.06(Mon)
kwargs.iter() → dict has no attribute 'iteration' 파이썬3에는 iter() 메서드 존재하지 않는다. items(), keys(), values()가 iterator와 유사한 view 객체를 반환한다.kwargs.items() →
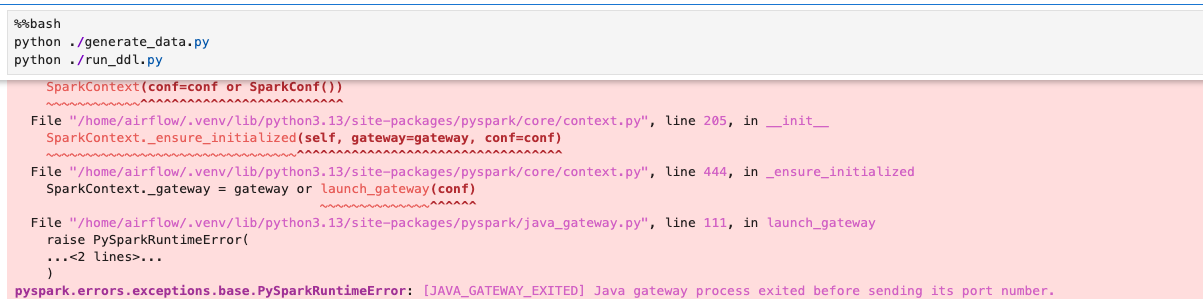
Data Engineering For Beginners : MAC - (1)
공부를 하다 보니 뭘 내 직무로 삼아야 될 지 감이 안 온다. DA? 개발자? 보안? 하나를 진득하니 했어야 했는데, 최소한 누군가한테 기본기로 하루 정도는 설명할 수 있을 지식은 가지고 있어야 했다. 따라서 오늘부터 해보기로 했다. 뭘? 그냥 다! 알고리즘, 판다스,
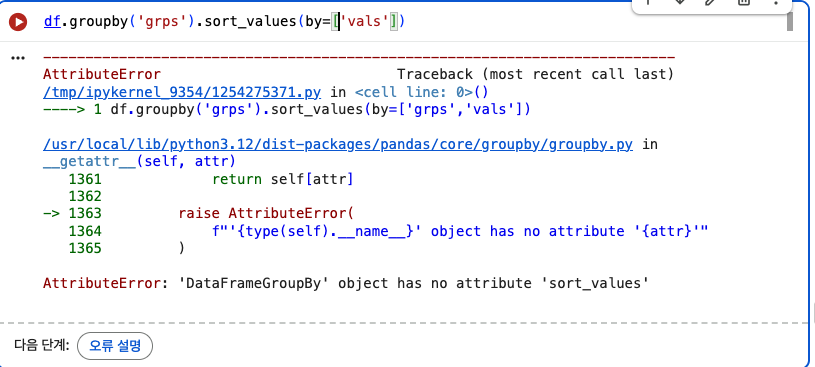
100 padas puzzles - No. 26~27(3)
각 행에서 3번째 NaN 값이 있는 컬럼을 찾아라isnull()은 isna()와 같다. isnull은 null 값에 익숙한 사람들을 위해 만든 alias 함수이다.df.isna().sum() - NaN의 총 개수는 구할 수 있는데 어떻게 3번째일 때를 조건절로 세울까?
100 pandas puzzles No.21 ~ 25 (2)
row : animal, column : 방문횟수, 평균나이pivot_table로 table 확인하는데 원하지 않는 데이터가 많을 때, query 함수로 원하는 데이터만 조회할 수 있다.query('컬럼명 == 원하는 조건')활용 예시df.drop_duplicates(