ActorsNeRF: Animatable Few-shot Human Rendering with Generalizable NeRFs (ICCV 2023)
Paper review

Figure 1: Animatable NeRF from a few images. We present ActorsNeRF, a category-level human actor NeRF model that generalizes to unseen actors in a few-shot setting.
Motivation
- NeRF 기반의 human reconstruction 방법들은 여전히 많은 수의 images/ views에 의존한다.
- 대부분의 접근법들은 정적인 scene들만 모델링한다.
- Category-level NeRF: 학습과 추론에 multiple-view image들을 요구함.
- Instance-level NeRF: Novel human actor들에 대해 일반화되지 못함.
Contributions
- ActorsNeRF는 feature encoder와 skinning weight network의 조합이 category-level shape과 appearance prior를 형성하도록 했고 deformation network는 category-level canonical space에서 instance-level canonical space로의 mapping을 학습한다.
우리가 아는 한, MonoNeRF는 NeRF-based human representation 측면에서 few-shot monocular video들로부터 few-shot generalization을 수행하는 최초의 연구이다.
Future direction
- Category-level canonical space에서 Human apperance나 shape prior를 넣는 것이 인간의 동작을 rendering하는 것에 성능 향상이 있겠지만 좀 더 범용적인 dynamic human/object들에도 sharp rendering이 가능하도록 network 구성이 필요하다.
Abstract
- NeRF-기반의 human representations 방법들이 인상적인 novel view synthesis 결과를 보였지만, 대부분의 방법들은 여전히 학습을 위한 많은 수의 images/ views에 의존한다.
- 본 연구에서 우리는 ActorsNeRF라고 불리는 참신한 animatable NeRF를 제시한다.
- 이것은 다양한 human subject들을 사용하여 사전학습되고 처음 보는 pose를 취하는 새로운 actor를 위한 few-shot monocular video에 적응한다.
- ConvNet encoder를 사용하는 parameter sharing을 갖춘 이전의 generalizable NeRF를 기반으로 만들어진 ActorsNeRF는 큰 human appearance, shape, 그리고 pose variations를 포착하기 위해 2가지 human prior들을 도입했다.
- 특히, encoded feature space에서, 우리는 category-level canonical space에서 다른 human subject들을 align할 것이고 rendering을 위해 instance-level canonical space에서 다른 프레임들로부터 같은 human을 align할 것이다.
- 우리는 ActorsNeRF가 다수의 데이터셋에 대해 새로운 사람들과 pose들에 대해 few-shot generalization의 존재하는 state-of-the-art를 현저하게 압도할 것이라는 것을 양적으로 그리고 질적으로 증명했다.
1. Introduction
- Neural Radiance Fields (NeRF)는 복잡한 움직임을 수행하는 인간의 free-viewpoint rendering에 현저한 진보를 가능하게 했다.
- 그러나 높은 quality의 rendering을 달성하려면, 존재하는 접근법들은 동기화된 multi-view video들과 특정 human video sequence에 의해 학습된 instance-level NeRF network의 조합을 요구한다.
- Multi-view에 대한 요구는 videos in the wild를 포함하는 application들에 대한 현저한 challenge가 된다.
- 최근에 이러한 제약을 없애기 위해 진보가 이루어졌지만 이러한 접근법들은 여전히 모든 viewpoint들로부터 dense하게 person을 다루는 많은 수의 프레임들을 요구했다.
- 이 논문에서, 우리는 더 실용적인 setting을 고려하고 질문을 던진다.
- 우리가 animatable human model은 적은 이미지들로부터 학습될 수 있는가?
- 우리는 이것이 다수의 사람들에 대해 학습된 class-level encoder를 도입하는 것에 의해 가능하다고 가정헀다.
- 이 가정은 generalizable NeRF에 대한 최근 연구에 의해 증명되었는데 이 NeRF에서 encoder network는 같은 category 안의 다수의 scene과 object들에 대해 학습되어 NeRF를 구성했다.
- Encoder를 통한 parameter sharing에 의해 다른 scene들에 걸쳐 학습된 prior는 적은 view만으로도 합성을 수행하도록 재사용될 수 있다.
- 그러나 대부분의 접근법들은 정적인 scene들만 modeling한다.
- 우리는 generalizable NeRF가 높은 자유도의, 큰 움직임과 복접한 texture pattern들을 포함하여 행동을 수행하는 인간의 복잡한 video 환경을 위한 좋은 prior의 학습으로 확장될 수 있는지 조사한다.
- 이를 위해 우리는 few-shot setup으로 참신한 행동 포즈를 취하고 있는 처음 보는 사람에 대해 전이 가능한 category-level human actor NeRF 모델을 도입한다.
- 이 setup은 monocular video의 few frame들로부터 처음 보는 view와 pose들을 취하고 있는 처음 보는 human actor의 animaton을 요구한다.
- 우리의 insight는 human action과 appearance는 복잡하며 모든 인간들은 SMPL과 같은 parametric model을 사용하여 category-level canonical space에서 coarse하게 정렬될 수 있다.
- Fine-grained alignment는 이 prior와 target actor를 위한 few-shot data 모두로부터 얻어진 instance-level canonical space에서 이익을 볼 수 있다.
- 이러한 insight를 실행하기 위해, 우리는 ActorsNeRF에 2-level canonical space를 부여했다.
- Body pose와 rendering viewpoint가 주어졌을 때, 3D 공간에서의 sampled point는 linear blend skinning (LBS)에 의해 canonical (T-pose) space로 변환된다. 이 때 skinning weight들은 다양한 subject들에 대해 공유되는 skinning weight network에 의해 생성된다.
- 우리는 T-pose space를 category-level canonical space라고 부른다.
- Category-level space에서 바로 rendering을 하는 것은 다른 사람들을 구분하는 shape와 texture detail을 포착하지 못하는 문제점이 있다.
- 이러한 한계를 극복하기 위해서, category-level canonical space의 point들은 deformation field에 의해 instance-level canonical space로 mapping된다.
- A rendering network는 최종적으로 pixel-aligned encoder feature들과 point들을 대응하는 color와 density로 mapping한다.
- ActorsNeRF는 feature encoder와 skinning weight network의 조합이 category-level shape과 appearance prior를 형성하도록 했고 deformation network는 instance-level canonical space로의 mapping을 학습한다.
- Test time에서 novel human actor에 적응하기 위해, the deformation network (instance-level)과 rendering network는 few-shot monocular image들에 fine-tuning된다.
- 우리는 ActorsNeRF가 ZJU-MoCap Dataset과 AIST++ Dataset 모두에 대해 다양한 few-shot setting에서 큰 차이로 존재하는 접근법들을 압도함을 양적으로 그리고 질적으로 보여주었다.
- 우리가 아는 한, MonoNeRF는 NeRF-based human representation 측면에서 few-shot monocular video들로부터 few-shot generalization을 수행하는 최초의 연구이다.
2. Related Work
Dynamic NeRF
- NeRF는 정적인 scene들을 modeling하기 위해 제안되었지만, 최근의 연구들은 성공적으로 이를 dynamic scene들이나 변형 가능한 물체들로 확장했다.
- Dynamic object들과 scene들을 모델링하는 한 전략은 댜양한 time step들에서의 관측들을 canonical space에서 정렬하는 것으로 4D를 3D와 time으로 분리하여 복잡성을 낮추는 것이다.
- 우리의 연구는 효율적인 모델링을 위해 다른 관측들을 정렬하는 원칙을 보여준다.
- Instance와 canonical space를 넘어, ActorsNeRF는 few image들을 이용하여 처음 보는 actor들을 모델링하는 것에서 category-level human prior를 통합한다.
NeRF-based Human Rendering
- Peng et al. : SMPL에 대한 latent code들의 집합을 결합하고 multi-view video들에 대해 performer의 novel view를 rendering함.
- Canonical space를 도입하여 다른 body pose들을 align함
- 이러한 방법들은 video를 요구하여 그 응용을 제한한다.
- Instance-level NeRF: Novel human actor들에 대해 일반화되지 못함.
- Category-level NeRF: 학습과 추론에 multiple-view image들을 요구함.
- 이전의 모든 접근법들과 달리, ActorsNeRF는 category-level generalizable NeRF로 처음 보는 human들에 대해 novel pose animation을 허용하고 추론 과정에서 monocular video로부터 few-shot 이미지들만 요구했다.
Few-shot NeRF
-
NeRF는 few view들로부터 학습되었을 때, 최적이 아닌 solution들로부터 어려움을 겪는다.
-
이 문제를 해결하기 위해 few-shot setting을 위한 다양한 regularization들이 제안되었다.
-
Data prior를 이용한 방법
- CLIP을 이용해 semantic consistency를 feature space에 넣었다.
- 더 강한 geometry prior, supervised or unsupervised depth information을 사용하여 solution의 악화를 막았다.
-
Few-shot transfer를 달성하기 위한 Data-driven way: large-scale 데이터셋에 대한 generalizable NeRF를 학습함.
- Encoder는 data prior를 배우도록 학습되고 model은 fine-tuning을 통해 처음 보는 예시에 적응함.
-
ActorsNeRF는 large-scale 데이터에 대한 data-driven 접근법과 human-specific prior를 이용한 regularization 방법의 결합이다.
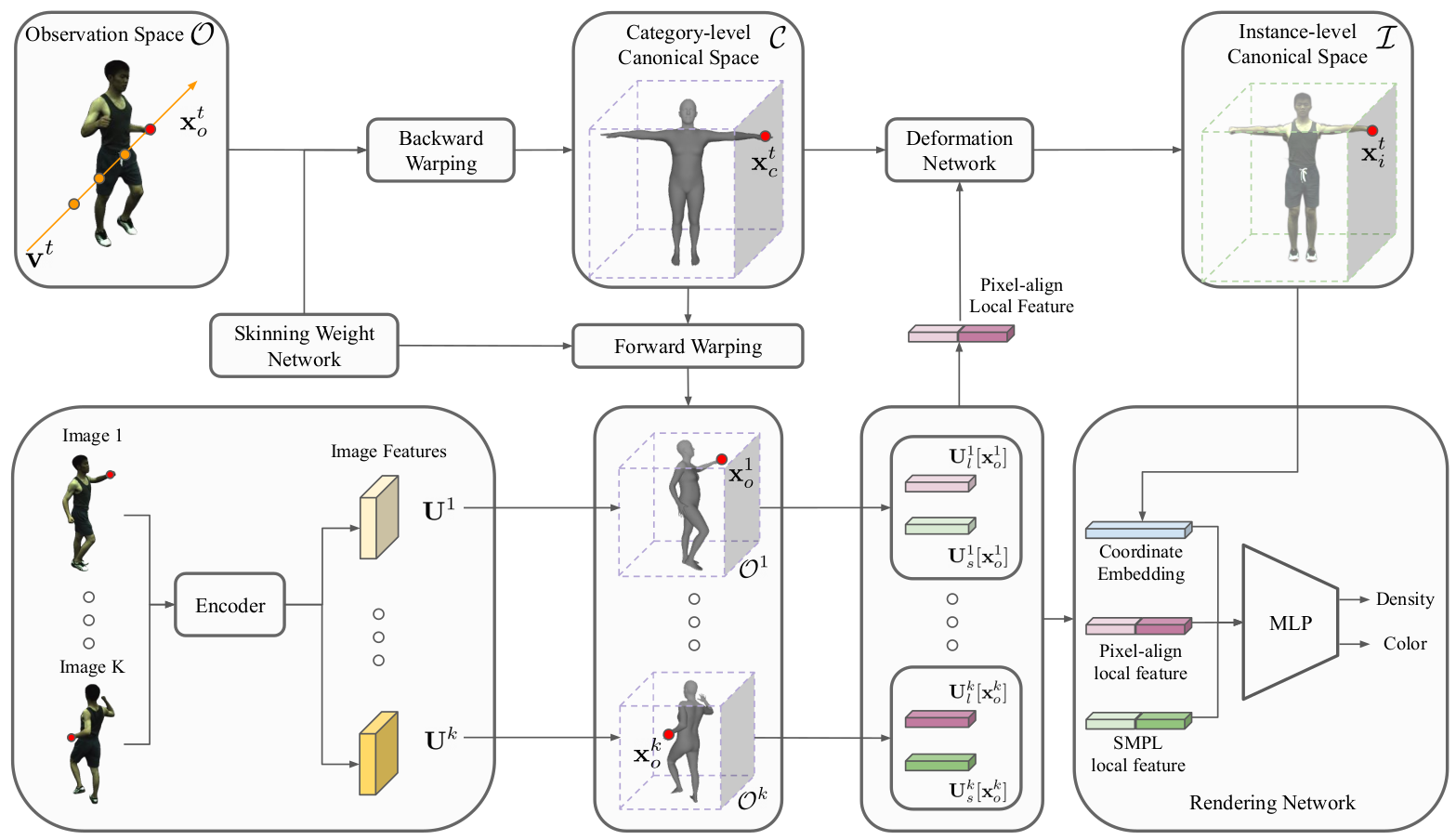
Figure 2: Overview of Actors NeRF.
3. Method
- Few-shot setup에서 novel body pose들과 함께 처음 보는 human을 합성 가능한 category-level generalizable NeRF인 ActorsNeRF를 도입했다.
- 다른 개인들에 대해 generalization을 달성하기 위해, a category-level NeRF 모델은 다양한 subject들의 집합에 대해 처음으로 학습된다.
- 추론 단계에서 target actor들에 대한 적은 image들만 사용하여 사전학습된 category-level NeRF 모델을 fine-tune하며 이는 모델이 actor의 구체적인 특징에 적응하도록 한다.
- 수학적으로, 목적은 random pose를 취하고 있는 human actor를 포착하는 작은 개의 frame 들이 주어질 때, network는 랜덤으로 샘플링된 view point 와 target pose 에 대해 3 point x를 color vector 와 density 로 mapping한다.
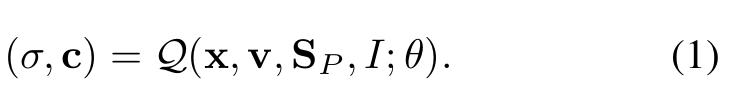
-
이는 와 같이 적은 이미지들만 주어졌을 때 매우 challenging하다.
-
이 문제를 해결하기 위해, 우리는 2가지 key idea들을 제시한다.
1) Monocualar video들의 large-scale dataset을 이용하여 Mapping을 위한 category-level prior를 학습하도록 해서 모델이 few-shot setting에서 새로운 사람에 빠르게 적응할 수 있게 한다.
2) Two-level canonical space를 사용하여 다양한 모양과 body pose를 가진 사람들을 정렬하는 human-specific knowledge를 통합하는 것
3.1. ActorsNeRF
- High-level에서 mapping을 학습하기 위해, 우리는 category-level new person을 학습하기 위해 다른 사람들을 캡쳐하는 다수의 monocular video들의 학습에 접근할 수 있음을 가정한다.
- 그러고 나서 모델은 개의 frame들에서 새로운 사람에 적응하도록 finetuning된다.
- Category-level pre-training과 finetuning에서, 우리의 아이디어는 sampled point를 category-level canonical space로 mapping하고 instance-level canonical space로 순서대로 mapping하는것이이다. Instance-level canonical space에서 human body는 canonical pose로 표현되고 encoder feature에 대해 조절되어 color와 density를 rendering한다.
- : Observation space
- : Category-level canonical space
- : Instance-level canonical space
- : a forward warping
- : backward warping
-
Support set에서 개의 이미지들 중 개의 이미지들은 랜덤으로 샘플링되었고 encoder 는 대응하는 feature vector 를 얻는데 (local feature들을 추출하는데) 사용되었다.
-
Figure 2에서 target image를 rendring하기 위해 pixel과 target rendering viewpoint 는 point들의 ray 를 정의한다. 각 point들은 category-level canonical space에서 point 로 mapping된다. 이 변환은 backward warping 을 통해 일어나며 skinning weight network 에 의해 가이드된다.
-
Canonical, category-level, shape을 다른 human actor들의 shape detail들에 적응하기 위해, deformation network 는 를 instance-level canonical space 의 위치인 로 변환하기 위해 deformation network 가 실행된다.
- 이 때, instance-level canonical space 에서 warping은 의 집합으로부터 추출된 image local feature들에 의해 가이드된다.
-
Pixel-aligned feature들을 추출하기 위해, category-level canonical space point 를 대응하는 forward warpings 에 의해 observation spaces 로 mapping한다.
- 이 때, set image 는 대응하는 feature map으로 project된다.
-
최종적으로, 와 image local feature들을 사용하여 a NeRF-based rendering network 은 color와 density를 출력한다.
-
ActorsNeRF의 구성 요소는 image encoder , skinning weight network , deformation network , 그리고 rendering network 로 이루어져 있다.
Feature Encoder
- 사전 연구들은 category-level에서 학습된 encoder feature들이 NeRF generalization을 향상시키는 것을 보여주었다.
- 우리는 encoder 를 사용하여 이미지 로부터 feature를 추출한다.
- Feature tensor 로부터 local features의 집합 []가 생산됨
- : pixel-aligned local feature로 3D point x, camera mapping 로부터 다음 식에 따라 생성된다.
- =
- : bilinear interpolation
- : SMPL local features로 pixel-aligned local features localized by SMPL model
- 이고 는 에 맞는 SMPL 모델의 vertices로, 각 vertex는 a local feature
Skinning Weight Network
- The skinning weight network는 category-level canonical space에서 다른 개인들에 대해 linear blend of skinning weights를 생성한다.
- Human body에 대한 B개의 point(B = 24)들이 주어졌을 때, network의 design은 [48]을 따르며, category-level canonical space 에서 the linear blend skinning weights는 3D volume으로 표현된다.
- 차이점은, ActorsNeRF의 경우, network parameter들이 training set에서 category-level shape prior를 포착하기 위해 actor들 간에 공유된다는 것이다.
Forward and Backward Transformation
- 다양한 body pose를 취하고 있는 같은 actor로부터 얻은 image feature들을 합하는 것은 다른 observation space인 의 matching body points 사이의 correspondence를 식별하는 것을 요구한다.
- Canonical space 에서 point 를 통한 공통 표현은 forward 와 backward warping의 도입을 통해 이를 가능하게 했다.
- Body pose , a transformation set 가 개의 point들에 대해 계산되었을 때, location 는 linear blend skinning (LBS)에 의해 point 로 mapping된다.
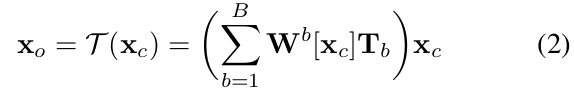
- 는 location 에서 sampled blending weights의 th channel을 나타낸다.
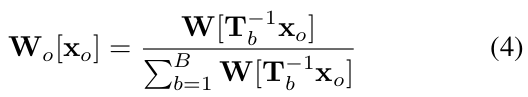
는 point 에 대한 sampled observation space blending weights의 th channel을 나타낸다.
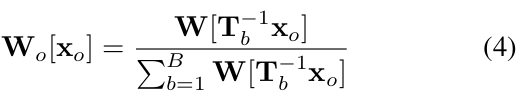
- Observation space 의 point 가 주어졌을 때, support set observation space 의 대응하는 points 는 backward mapping 는 (를 category-level canonical space point 로의 backward mapping과 로의 forward mapping에 의해 세워졌다.
Deformation network
- Category-level canonical space에서 missing detail들을 보상하기 위해, 에 의해 parametrize된 a deformation network 는 point 를 fine-grained instance-level canonical space 의 로 변환하기 위해 수행되었다.
- 이 deformation은 target body 에 의해 조절되며 개의 support set pixel은 local features 에 대해 정렬되었다.
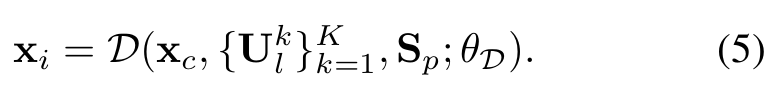
- Category-level에서 instance-level canonical space로의 mapping
Rendering Network
- A rendering network는 로 파라미터화 되었고 instance-level 3D location 에 대해 color와 density를 예측한다.
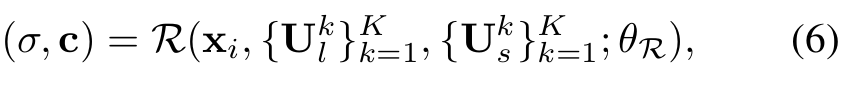
- 위 식은 local features 과 SMPL local features 에 의해 조절됨.
- SMPL feature들을 continuous space로 확장하여 feature들이 직접적으로 a continuous space에서 sampled point로서 query될 수 없는 문제를 해결함.
- K SMPL local features 는 이어붙여지고 sparse 3D convolution network로 들어가서 3D volume을 만든다. 그래서 sampled locaiton 의 feature들은 tri-linear interpolation을 통해 얻어질 수 있다.
- SMPL feature diffusion process는 canonical space에서 실행되고 category-level prior로서 역할을 한다.
Volume Rendering
- NeRF와 같이, 기대되는 rendering color 와 camera ray 은 표준 volume rendering을 사용하는 것에 의해 예측된 color 와 density 를 합하는 것에 의해 얻어진다.
3.2. Category-level Training
- The image encoder 은 key image들을 위한 대응하는 feature들인 를 추출하는데 사용되었다. 추출된 image feature들과 함께, target rendering viewpoint 를 위한 sampled point들의 ray가 합해져서 corresponding color 을 생성한다.
- 높은 quality의 rendering을 보장하기 위해, mean square error 와 the perceptual loss 가 목적 함수로서 사용되었다.
- 추가로, 또 다른 loss인 skinning weight regularizer 는 skinning weight network로부터 얻은 output skinning weight이 skeleton으로부터 얻은 prior에 가까워지도록 장려한다.
- 3개의 objective function들 모두 모든 network parameter들을 업데이트하기 위해 공동으로 최적화된다.
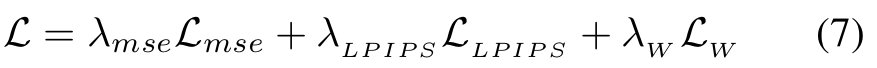
- : 다른 loss function들을 balance하기 위한 대응하는 coefficients
3.3. Few-shot Optimization
- category-level에서 학습한 ActorsNeRF를 위한 지식을 제공된 frame들과 함께 novel human actor에 전달하기 위해, 우리는 모델을 관찰과 match하도록 fine-tune하는 것을 제시했다.
- Fine-tuning 중에 우리는 개의 프레임들 중 개를 뽑아 feature 추출을 위한 encoder의 support frame으로 사용한다.
- 개의 frame들이 iteration마다 쓰이는 학습 단계와 달리, 개의 프레임들은 few-shot setting에서의 few-shot optimization stage에 고정되었다.
- Feature encoder와 skinning weight network의 조합이 category-level shape과 appearance prior를 형성함에 따라 deformation network와 rendering network는 fine-tune된다. 그리고 encoder와 skinning weight network는 고정된다.
- 추가로, mean square error와 perceptual loss가 few-shot optimization stage에서 사용된다.
- Fine-tuning 이후에, ActorsNeRF는 개의 support frame들을 사용하여 novel viewpoint, pose와 함께, novel actor를 rendering할 수 있다.
4. Experiments
- 우리는 ActorsNeRF를 다수의 benchmark dataset인 ZJU-MoCap 데이터셋과 AIST++ 데이터셋에 대해 test했으며 다수의 ActorsNeRF는 state-of-the-art baseline들을 현저하게 압도했다.
4.1. Datasets and Baselines
Dataset.
- 우리는 ActorsNeRF를 ZJU-MoCap 데이터셋과 AIST++ 데이터셋의 2가지 데이터셋에 대해 평가했다.
- ZJU-MoCap 데이터셋
- 21/23 multi-view camera들로부터 기록된 10가지 human subject들을 포함한다.
- 우리는 데이터셋에 의해 제공된 camera projections, body poses, 그리고 segmentation을 사용한다.
- AIST++ 데이터셋
- 9개의 multi-view camera를 사용하여 다양한 댄스들을 수행하는 30 human subject들을 캡쳐했다.
- 각 subject들에 대해 하나의 action sequence를 선택하여 25명의 actor들은 training에, 5명의 actor들은 test에 사용했다.
Baseline and Metric.
- 우리는 우리의 방법을 가장 representative한 state-of-the-art view synthesis 방법들과 비교했다.
- HumanNeRF (HN)은 canonical space에서 다양한 pose들과 align되고 monocular video로부터 state-of-the-art rendering performance를 달성했다.
- NeuralBody는 observation space로부터 rendering을 위한 representative method이다.
- Neural Human Performer와 MPS-NeRF: 학습과 추론 모두에서 multi-view를 요구하므로 우리의 monocular setting과 직접적으로 비교할만하지 않다.
- 사용한 metrics
- PSNR (Peak Signal-to-noise ratio)
- SSIM (Structural Similarity Index Measure)
- LPIPS (Learned Perceptual Iamge Patch Similarity)
4.2. Generalization
- 우리는 ActorsNeRF가 어떻게 few-shot setup에서 일반화하는지 분석했다.
- 우리는 학습된 category-level prior의 일반화를 2가지 setting에 대해 증명했다.
- Few-shot generalization
- Human actor가 대부분 관측된다.
- Short-video generalization
- 입력 프레임들은 subject들이 dense하게 cover되지 않도록 선택된다.
- 이 실험은 모델이 missing portion들을 상상해야 하도록 디자인되었다.
- Few-shot generalization
4.2.1. Few-shot Generalization

Figure 3: ZJU-MoCap 데이터셋에 대한 처음 보는 pose들을 취하는 novel actor들의 few-shot novel view synthesis를 위한 질적인 비교
-
우리의 방법은 sharp boundary와 detail과 함께 high-quality image들을 rendering했다.
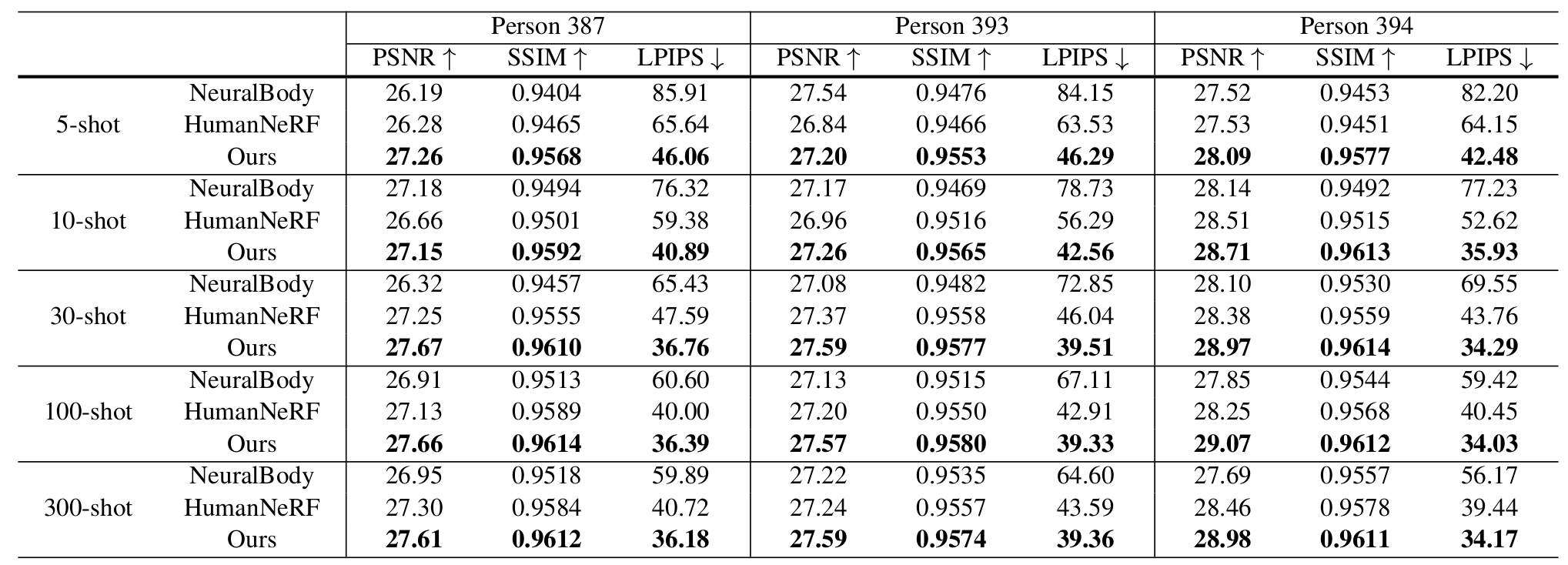
Table 1: Few-shot generalization comparison for novel view synthesis of novel actors with unseen poses on the ZJU-MoCap dataset. -
이 setction에서, 우리는 처음 보는 pose들에 대한 novel actors의 novel view synthesis를 입력 이미지들의 수를 다르게 하면서 테스트했다.
-
The support set은 개의 frame들로 구성되어 있으며 이다.
- 이는 처음 보는 subject의 monocular video의 300개의 연속적인 프레임들로부터 sampling되었다.
-
목적은 actor들을 novel pose들과 함께 novel viewpoint들로부터 합성하는 것이다
-
Table 1에서 볼 수 있듯이, ZJU-MoCap 데이터셋에 대해, ActorsNeRF는 모든 baseline 방법들을 모든 shot들에 대해 큰 차이로 압도하며 특히 LPIPS metric에서 더욱 그렇다.
-
Figure 3은 ZJU-MoCap 데이터셋에서 2개의 다른 viewpoint들로부터 test actor들의 처음 보는 pose들에 대해 30-shot rendering을 나타낸다.
-
ActorsNeRF에 의해 생성된 rendering은 less body distortion과 함께 valid shape을 유지하면서 더 smooth하고 high-quality detail들을 보존한다.
-
HumanNeRF는 rendered image들에서 왜곡된 boundary들과 함께 unsmooth, blurry textures를 생성한다.
-
우리는 우리의 알고리즘을 복잡한 dancing pose들과 loose clothes를 포함하는 더 challenging한 AIST++ 데이터셋에 대해 평가했다.
-
Table 2에서 우리의 결과는 훨씬 좋은 성능을 달성헀다.
-
Figure 4는 이 데이터셋에 대해 HumanNeRF가 valid shape을 생성하는데 얼마나 자주 실패하는지 (왜곡된 몸과 분리된 body parts) 보여주며, ActorsNeRF는 전반적인 shape들과 texture들에 대해 훨씬 나은 합성을 보여주었다.
-
이는 학습된 category-level prior의 효율성을 다시 입증한다.

Figure 4: AIST++ 데이터셋에 대해 처음 보는 포즈에 대한 novel actor들의 few-shot novel view synthesis의 질적 비교
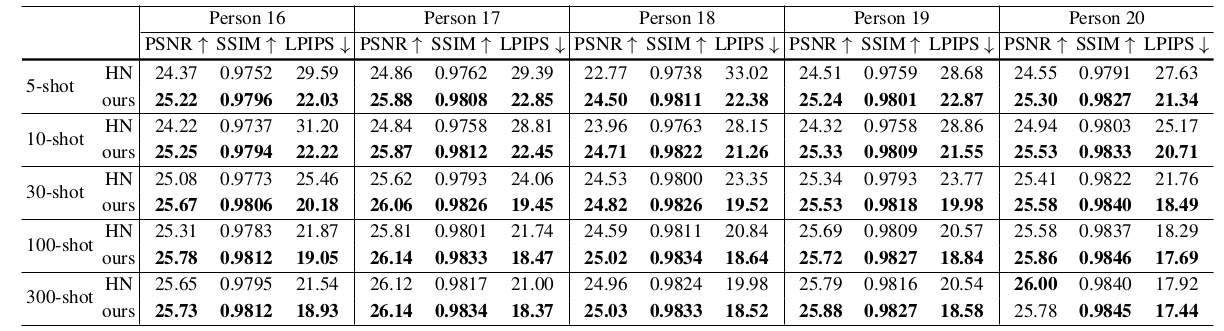
Table 2: AIST++ 데이터셋에 대해 처음 보는 포즈들에 대한 novel actor들의 novel view synthesis를 위한 few-shot generalization 비교
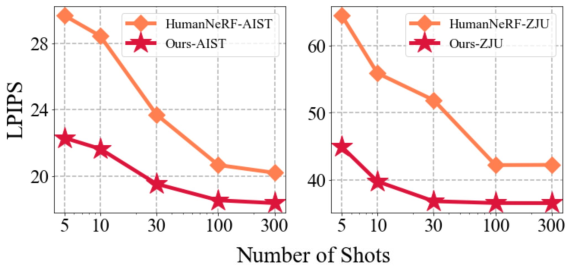
Figure 5:ZJU-MoCap 데이터셋 (오른쪽)과 AIST++ 데이터셋 (왼쪽)에 대해 처음 보는 포즈의 novel actors의 few-shot novel view synthesis 비교
- 우리는 Figure 5에서 다른 shot들에 대해 모든 test subject들에 대해 평균한 LPIPS metric을 추가적으로 plot했다.
- 우리의 insight는 ActorsNeRF는 더 적은 이미지들을 넣었을 때 학습된 prior로부터 더 많이 이익을 얻는다.
- 그러나 300개의 프레임들이 제공되었을 때, ActorsNeRF는 baseline에 대해 여전히 현저한 margin을 만들어낸다.
- 결과는 large few-shot spectrum에 대해 category-level ActorsNeRF가 rendering quality를 향상시킨다는 것을 제시한다.
4.2.2. Short-video Generalization
- Novel pose들과 viewpoint들을 rendering하는 목적이 있을 때 새로운 사람의 이미지의 몇 안되는 이미지들이 주어졌을 때, body의 missing portion들을 상상할 수 있다는 것을 연구했다.
- 우리는 모든 프레임들에서 사람의 일부만 관측된 시나리오를 고려하고 이는 body의 missing part들을 상상할 수 있는 사람들에 대한 natural task이다.
- 우리는 100개읭 연속된 프레임들에서 프레임들을 샘플링하는 조건에서 우리의 알고리즘이 비슷하게 작업을 수행할 수 있는지 조사했다.
- Table 3는 ZJU-MoCap 데이터셋에서 ActorsNeRF가 HumanNeRF (HN)을 다시 현저하게 압도함을 보여준다.
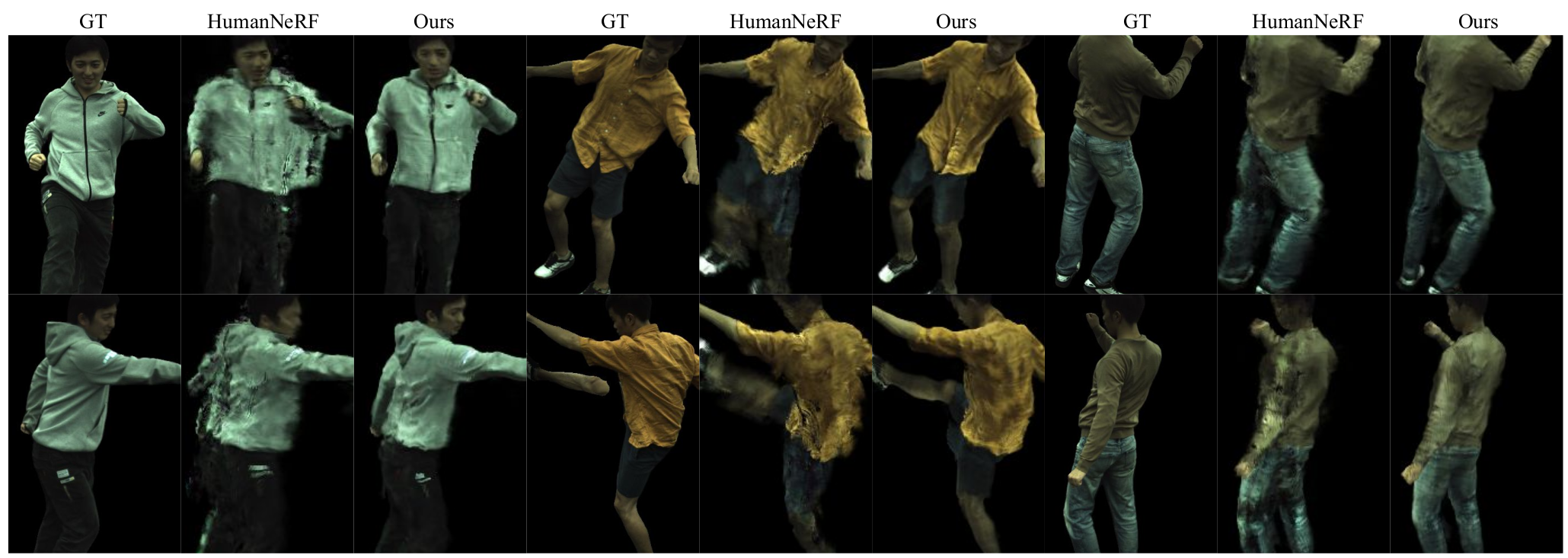
Figure 6: ZJU-MoCap 데이터셋에 대해 처음 보는 포즈들에 대한 novel actor들의 novel view synthesis를 위한 질적 비교. Ground-truth (GT), HumanNeRF, 그리고 우리의 결과는 왼쪽으로부터 오른쪽으로 보여진다. ActorsNeRF는 sharp boundary를 생성하며 더 나은 overall shape을 유지한다. 이는 category-level prior가 관측되지 않은 부분들을 smooth하게 합성하기 위해 이용될 수 있음을 가리킨다.

Table 3: ZJU-MoCap 데이터셋에 대해 처음 보는 포즈에 대한 novel actor들의 novel view synthesis를 위한 short-video generalization 비교

Table4: ActorsNeRF의 요소들에 대한 Ablation
- Figure 6은 다른 방법들에 대한 clear visual comparison을 제시한다.
- HumanNeRF는 관측된 body part들에 대해 valid shape을 생성하지만 덜 관측된 body part들에 대해서는 유효한 모양을 유지하는데 실패한다.
- 이와 비교해서, ActorsNeRF는 여전히 sharp boundary들을 생성하고 전반적인 모양을 유지한다.
- 이는 ActorsNeRF가 body의 관측되지 않은 일부를 smooth하게 합성하는데 category-level prior를 이용할 수 있음을 보여준다.
4.3. Ablation
- 이 섹션에서 우리는 ZJU-MoCap 데이터셋에 대해 10-shot generalization의 context에서 ActorsNeRF의 2-level canonical space와 local encoder feature들의 효율성을 조사한다.
- 우리는 category-level 학습과 instance-level fine-tuning 모두에서 구성 요소들을 배제하는 것에 의해 ablation 실험을 수행했다.
- Deformation network는 category-level shape을 fine-grained instance-level shape으로 정제하는 역할을 한다.
- 우리는 category-level canonical space에서 직접적으로 rendering함으로써 deformation network를 제거했다.
- Table 4에서, 결과는 제시된 2-level canonical design은 photorealistic detail들을 rendering하는데 중요함을 나타낸다.
- 게다가, 우리는 pixel-aligned local feature들이나 smpl local feature들이 낮은 LPIPS 점수를 야기하며 이는 모든 요소들이 최고의 전반적 성능을 달성하는데 있어 필수적임을 보여준다.
5. Conclusion
- 우리는 monocular video들로부터 학습되고 a few monocualr image들의 novel human subject들에 적응된 generalizable NeRF-based human representation인 ActorsNeRF를 도입했다.
- ActorsNeRF는 다수의 human subject들에 대해 parameter sharing을 통한 category-level prior를 encode하고 large human appearance, shape, pose 변화들을 포착하기 위해 2-level canonical space와 함께 실행되었다.
- ActorsNeRF는 ZJU-MoCap 데이터셋이나 AIST++ 데이터셋 등 다수의 benchmark 데이터셋들에 대해 평가되었다.
- 존재하는 state-of-the-art 방법들과 비교하여, ActorsNeRF는 다수의 few-shot setting들에 대해 처음 보는 pose들을 가진 novel human actors들에 대한 뛰어난 novel view synthesis 성능을 증명헀다.