논문 : https://arxiv.org/abs/2309.03160
프로젝트 홈페이지 : https://markomih.github.io/ResFields/
Github: https://github.com/markomih/ResFields
Motivation
- 신호들을 MLP로 나타내는 것은 power나 simplicity에도 불고하고 크고 복잡한 temporal signal들을 모델링하는데 어려움을 겪는데 이는 MLP의 제한된 용량 때문이다.
- Neuron 수의 측면에서 MLP의 capacity를 증가시키면 추론과 최적화 속도가 느려지고 GPU 메모리가 많이 소모되며 메모리 복잡도는 parameter 수에 비례하여 증가한다.
Contributions
- Temporal residual layer들을 ResFields라고 불리는 neural fields로 통합하는 것에 의해 이 한계점을 다루고 있다.
- 우리는 ResFields의 학습 가능한 parameter의 수를 줄이고 일반화 성능을 향상시키기 위해 matrix factorization 기법을 제시한다.
- MLP의 width는 늘리지 않고 추론과 학습 속도를 유지한다.
- Spatial partitioning에 집중하는 다른 방법들과 달리, MLP의 implicit regularization과 generalization에 집중한다.
- ResFields를 challenging task들에 대해 평가했고 2D video approximation, signed distance function들을 통한 temporal 3D shape modeling, RGB(D)로부터 dynamic scene들의 radiance field reconstruction, 그리고 3D scene flow의 학습에 있어 state-of-the-art임을 증명했다.
Future direction
- Model capacity에 bottleneck이 있을 때를 타겟으로 residual layer를 추가하여 해결하고 있지만 제한 없는 문제를 푸는 모델 연구가 필요함.
Abstract
- Neural fields는 고주파 신호를 표현하기위해 학습된 neural network로, single multi-layer perceptron (MLP)으로 signed distance (SDFs)나 radiance fields (NeRFs)와 같은 복잡한 3D data를 모델링하는데 있어 인상적인 성능 때문에 최근에 많은 관심을 받고 있다.
- 신호들을 MLP로 나타내는 것의 power나 simplicity에도 불구하고 크고 복잡한 temporal signal들을 모델링하는 것은 어려움을 겪는데 이는 MLP의 제한된 용량 때문이다.
- 본 논문에서, 일시적인 residual layer들을 ResFields라고 불리는 neural fields로 통합하는 것에 의해 이 한계점을 다루고 있다.
- 복잡한 temporal signal들을 효율적으로 표현하기 위해 novel class of network들이 디자인되었다.
- 우리는 ResFields의 속성에 대한 종합적인 분석을 수행하고 학습 가능한 parameter의 수를 줄이고 일반화 성능을 향상시키기 위해 matrix factorization 기법을 제시한다.
- 가장 중요한 것은, 우리의 공식은 존재하는 MLP-based neural fields를 빈틈없이 통합하고 지속적으로 2D video approximation, dynamic shape modeling via temporal SDFs, 그리고 dynamic NeRF reconstruction 등 도전적인 task들에 대해 지속적으로 결과를 향상시킨다.
- 마지막으로, 우리는 경량의 capature 시스템의 RGBD 카메라로부터 dynamic 3D scene들을 캡쳐하는 것에서 그 효율성을 보여주는 것에 의해 ResFields의 실용성을 증명한다.
1. Introduction
-
Multi-layer Perceptron (MLP)는 common neural network 구조로 neural fields라고 불리는 연속적인 spatiotemporal 신호들을 표현하는데 사용되는 netowork 구조이다.
-
그러나 MLP의 neural network가 저주파의 함수들만 학습하려고 하는 경향은 복잡한 real-world를 정확하게 표현하고 fine-grained detail들을 포착하는데 있어 challenge가 되었다.
-
이전의 연구들은 positional encoding이나 특별한 activation function을 사용하여 이를 해결했다.
-
이러한 방법들도 긴 video들이나 dynamic 3D scene들과 같은 spatiotemporal signal들을 다룰 때 어려움을 겪는다.
-
MLP의 capacity를 증가시키는 직접적인 방법은 neuron의 수의 측면에서 network complexity를 증가시키는 것이다.
-
그러나 그러한 접근법은 추론과 최적화를 느리게 하고 더 많은 GPU 메모리를 비싸게 하며 메모리의 복잡도는 parameter의 수에 비례하여 증가한다.
-
또 다른 가능성은 MLP weight들을 meta-learn하고 특화된 독립적인 parameter들을 유지하는 것이다.
-
이는 느린 학습을 가하고 photo-realistic reconstruction을 scale하지 않는다. 지금까지 가장 유명한 접근법은 spatiotemporal field를 나누고 separate/local nerual fields를 맞추는 것이다.
-
그러나 이러한 접근법들은 grid structure의 local gradient update로 인해 global reasoning과 generalization을 막는다.
-
우리가 다루고자 하는 문제는 모델 capacity를 어떻게 MLP neural fields의 디자인 선택과에 무관한 방식으로 증가시킬지이다.
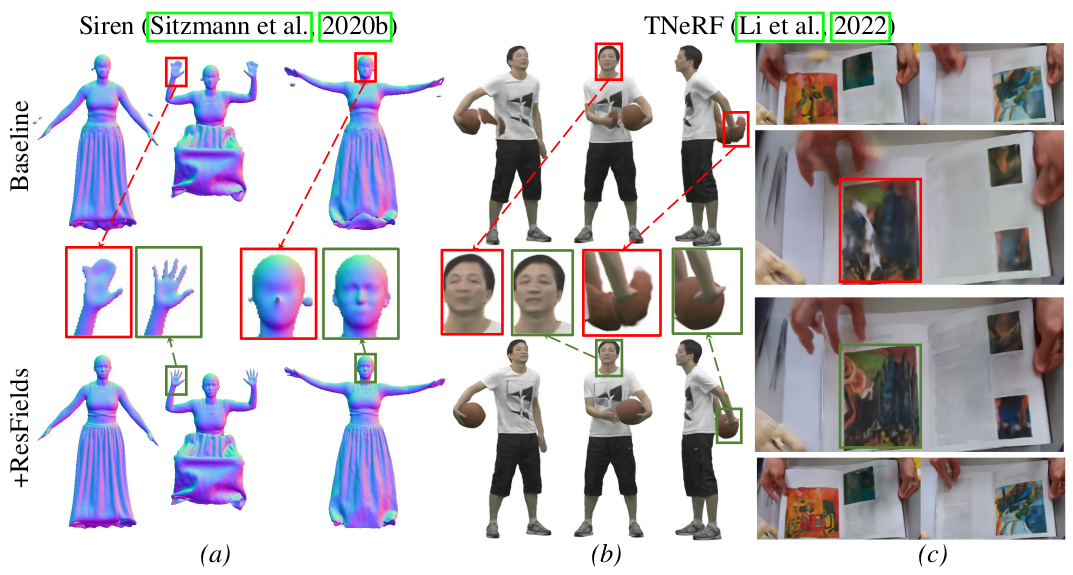
Figure 1: ResField는 conventional layer들을 Residual Field layer들로 대체함으로써 MLP 구조를 확장하여 복잡한 temporal signal들을 효과적으로 표현할 수 있다. -
우리의 key idea는 MLP layer를 time-dependent layer들로 대체하는 것으로 weight들이 존재하는 layer weights 에 더해진 학습가능한 residual parameters 로서 모델링되었다.
-
우리는 이런 방식으로 시행되는 neural fields를 ResFields라고 부른다.
-
Model capacity를 늘리는 것은 3가지 key advantage들이 있다.
- MLP는 width를 늘리지 않고 추론과 학습 속도를 유지한다.
- Spatial partitioning에 집중하는 다른 방법들과는 달리, MLP의 implicit regularization과 generalization을 유지한다.
-
최종적으로, ResFields는 가번적이고, 쉽게 확장 가능하며, 경쟁력있다.
-
그러나 , 많은 수의 제한없는 학습 가능한 parameter들 때문에 ResFields는 감소한 interpolation 속성으로 이어질 수 있다.
-
우리는 the residual parameter들을 global low-rank spanning set과 time-dependent coefficients의 집합으로 제시한다.
-
이 모델링은 일반화 속성을 향상시키고 추가적인 network parameter들을 유지하는 것에 의해 memory footprint를 줄인다.
우리의 key contribution들을 요약하면 다음과 같다.
- 우리는 ResFields라고 불리는 spatiotemporal fields를 모델링하기 위한 architecture-agnostic building block을 제시한다.
- 우리는 시스템적으로 우리의 방법이 많은 존재하는 방법들에 대해 이익이 있음을 증명했다.
- ResFields를 challenging task들에 대해 평가했고 2D video approximation, signed distance function들을 통한 temporal 3D shape modeling, RGB(D)로부터 dynamic scene들의 radiance field reconstruction, 그리고 3D scene flow의 학습에 있어 state-of-the-art임을 증명했다.
2. Related work
Neural field
a pysical quantity로 이는 시간과 공간에서 모든 point들이 neural network에 의해 완전히 또는 부분적으로 파라미터화 되어 있다.
- 하지만 signal의 MLP로의 직접적인 fitting은 낮은 주파수의 spectral bias로 인해 poor reconstruction quality로 이어진다.
- 이러한 문제들은 특별한 input encoding과 activation function들로 완화되었지만, neural fields는 제한된 용량으로 인해 여전히 길고 복잡한 temporal signal들을 scale하지 못한다.
- Modeling capacity를 늘리는 자연스러운 방법은 parameter 수의 측면에서 network의 크기를 늘리는 것이지만 이 solution은 GPU와 학습 시간 요구에 비례하지 않는다.
Hybrid neural fields
- 이 방법은 spatial 그리고 temporal partitioning 기법들을 이용해 모델링 capacity를 향상시키기 위해 학습가능한 feature vector들과 함께 explicit grid-based data 구조를 이용한다.
- 그러나 이 접근법들은 generalization에 필요한 알맞은 global reasoning과 implicit regularization을 희생한다.
- Resfields는 몇몇 중요한 응용들에 대해 state-of-the-art 결과들을 내고 있는 순수하게 neural network 기반의 접근법들을 향상시키는데 집중한다.
Input-dependent MLP weights
- 직접적으로 hypernetwork나 convolutional neural network를 통해 MLP의 weight들을 직접적으로 regress하는 것에 의해 MLP의 capacity를 늘리는 공통 전략이다.
- 그러나 이러한 접근법들은 neural fields를 최적화하는데 있어 현저한 계산적 burden을 가하는 추가적인, 더 큰 network를 도입한다.
- KiloNeRF는 학습된 radiance field를 작은 독립적인 MLP의 grid로 증류하는 것에 의해 정적인 nerual radiance field의 추론 속도를 높인다.
- LoE (Level-of-experts)
- 표현적인 capacity를 희생하여 공유된 MLP weight들의 입력에 독립적인 계층적 구성을 도입한다.
- LoE와 다르게 ResFields는 복잡하고 spatiotemporal signal들을 모델링하는 것에 있어 더 강한 generalization과 더 높은 표현적 power를 증명한다.
Temporal fields
- Temporal fields는 neural fields에 time-space 좌표 쌍을 제공하는 것에 의해 모델링된다.
- 그러나 이 접근법들을 4D로 scaling하는 것은 실행 불가능하고 NeRF 모델들의 dynamic extension들에 증명된것처럼 바람직한 결과를 생성하지 않는다.
- 그러므로, 존재하는 대부분의 NeRF solution들은 학습 문제를 정적인 canonical nerual field와 deformation neural network로 분리한다. Deformation network는 query point들을 observation space에서 canonical space로 변환한다.
- 그러나 이러한 방법들은 neural network를 통해 복잡한 deformation들을 학습하는 것의 어려움 때문에 더 복잡한 신호에 대해 실패한다.
- 이 문제를 해결하기 위해서 HyperNeRF는 topological 변화들을 더 잘 포착하고 모델링 capacity를 늘리며, 복잡한 deformation의 학습을 단순화하기 위해 추가적인 작은 MLP와 per-frame 학습가능한 ambient code들을 도입했다.
- NDR: HyperNeRF의 후속 연구로 invertible nerual networks와 더 제한된 SDF-based density formulation을 이용하는 것에 의해 deformation field를 더 향상시켰다.
Scene flow
- Neural fields의 dynamics를 모델링하는데 공통적으로 사용된다.
- 대부분의 연구들은 MLP를 offset vector들을 예측, SE(3) transformation, pre-defined bases의 coefficents, 직접적으로 invertible architecture들을 사용하는 것에 의해 scene flow 모델링하는 데에 사용한다.
Residual connections
- Input signal에 대응하여 효율성을 증가시킨다.
- Vanishing gradient 문제를 극복하는데 유용하다.
- Large language models에서 fine-tuning에 쓰이거나 모델 weights를 예측하는데 사용되었지만 spatiotemporal neural fields를 학습하는 데에 직접적으로 사용되지 않았다.
3. ResFields: Residual Neural Fields for spatiotemporal signals
Formulation
- Temporal neural fields는 neural network 를 통해 연속적인 signals 를 encode하고 이 때, 입력은 time-space 좌표 쌍 ()이며 출력은 field quantity 이다. 공식적으로 temporal neural field는 다음과 같이 정의된다.
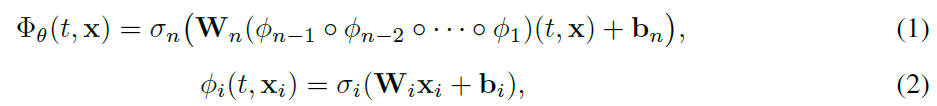
- :은 MLP의 i번째 MLP로 non-linear activation function 에 의해 따라지며 input 에 적용된 linear transformation , 에 의하 linear transformation으로 구성된 MLP의 번째 MLP이다.
- The network parameter 는 loss term 을 a ground truth signal로 최소화하는 것에 의해 최적화되거나 field quantity를 sensory input에 독립적으로 연관시키는 것에 의해 간접적으로 최적화된다.
Limitations of MLPs
- 복잡하고 긴 신호들을 모델링하기 위해, MLP가 충분한 모델링 용량을 갖는 것이 중요하다.
- MLP 크기가 증가할수록, neural fields의 학습 시간은 느려지고 GPU의 메모리 요구량은 증가하여 최종적으로 MLP 크기의 bottleneck으로 이어진다.
- 이는 dynamic radiance field reconstruction에서 강조되는데 이는 inverse rendering 문제를 수십억개의 MLP query들에 대해 푸는 것을 요구한다.
- 우리는 ResFields를 도입했는데 이 접근법은 spatiotemporal signal들을 모델링하고 재구성하는 것에 있어 capacity bottleneck을 완화한다.
ResFields model
- 우리는 크고 복잡한 spatiotemporal signal들을 효율적으로 포착하기 위해 residual field layer들을 도입한다.
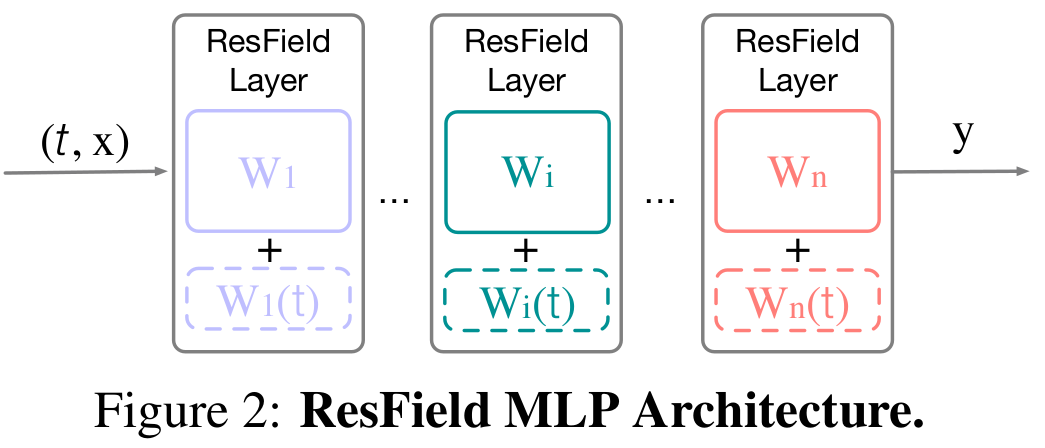
- ResFields는 적어도 하나의 residual field layer와 함께 layer나 neuron들의 수의 측면에서 MLP의 크기를 증가시키지 않고 aforementioned capacity bottleneck을 완화한다. 특히 우리는 MLP의 linear layer 를 우리의 temporal time-conditioned residual layer로 데체한다.
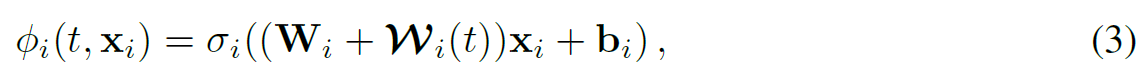
- : network weight의 time-dependent 그리고 models residuals
- 이 간단한 공식은 전반적인 network 구조를 수정하지 않고 추가적인 학습 가능한 parameter들을 통해 model capacity를 증가시킨다.
ResFields factorization
- 그러나 단순히 학습 가능한 weights의 dictionary로서 를 수행하는 것은 많은 양의 독립적이고 제한되지 않은 parameter들을 낳는다. 이는 space partitioning method들과 유사하게 spatiotemporal signal의 partitioning을 야기하며 MLP의 global reasoning과 implicit bias을 막는데 이는 sparse setup에서 novel view synthsis와 같은 제한된 문제들을 푸는 것에 있어 필수적인 속성이다.
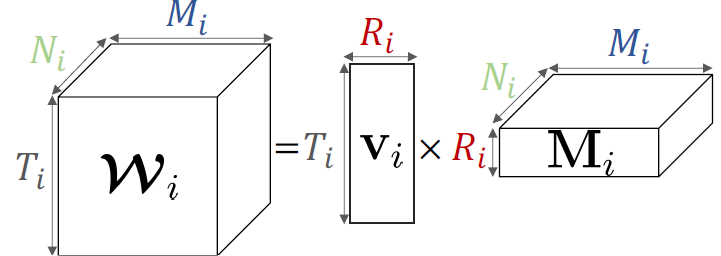
Figure 3: Factorization of
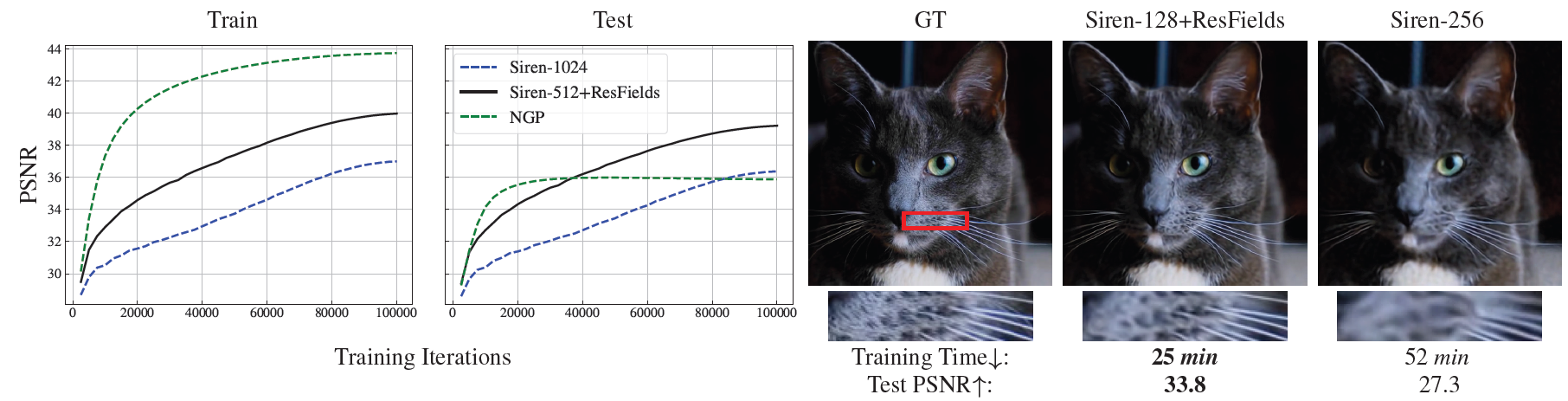
Figure 4: 2D video approximation. RGB video들에 fitting할 때 다른 neural fields의 비교. PSNR curves의 학습과 테스트는 모델의 능력과 generalization 속성들 사이의 trade-off를 가리킨다.
-
Instant NGP는 좋은 overfitting 능력을 갖고 있지만 처음 보는 픽셀들에 대해 일반화하는 데에 어려움을 겪는다.
-
A siren MLP with 1024 neurons: 좋은 generalization 속성을 보여줬지만 이것은 낮은 학습 및 테스트 PSNR로 표현적인 power가 부족했다.
-
ResFields와 함께 실행된 더 작은 512개의 뉴런을 가진 더 작은 Siren은 좋은 generalization을 증명했고 더 높은 모델 capacity를 제공했다.
-
우리의 접근법은 더 높은 정확도 외에도 2.5배 더 빠른 수렴과 더 작은 MLP로 30% 낮은 GPU 메모리 요구량을 제공했다.
-
오른쪽의 결과는 256개의 뉴런을 갖는 Siren과 ResField layer들과 함께 실행된 128개의 뉴런을 갖는 Siren의 시각적 비교를 제공한다.
-
최종적으로 우리는 직접적으로 time-dependent coefficients와 spatiotemporal signal에 걸쳐 공유되는 residual network weight들의 차원의 spanning set을 직접적으로 최적화했다.
-
특히 network weight들은 다음과 같이 정의된다.
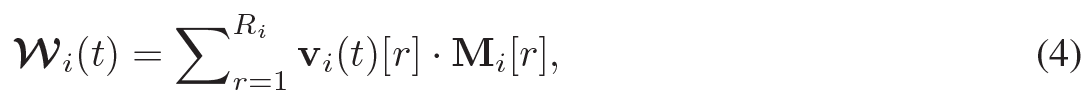
- 여기서 coefficients 와 spanning set 는 학습 가능한 parameter들이다.
- 우리는 를 matrix로 사용하여 그것의 행들을 선형적으로 interpolate했다. 이러한 형식은 학습 가능한 parameter들의 수를 줄이고 field partition 방법들에서 빈번한 바람직하지 않은 overfitting을 방지한다.
Key idea
- 파라미터화의 목표는 좋은 일반화 성능을 유지하면서 높은 학습 용량을 달성하는 것이다.
- 파라미터 수의 측면에서 제한된 예산에서 이를 달성하기 위해, 우리는 time step마다 몇몇 독립적인 parameter들과 많은 globally shared parameter 을 할당했다.
- 공유된 parameter들에 더 많은 capacity를 할당하는 것은 shared weights로 효율적으로 압축될 수 있는 작은 패턴들을 발견할 수 있는 능력 때문에 모델의 증가된 capacity를 가능하게 한다.
- 모델이 shared weights에 걸쳐 전체 시퀀스들을 알고 있기 때문에 더 강한 일반화를 가능하게 한다.
- 2가지 목적들이 주어졌을 때, 우리는 가 매우 적은 parameters ()와 을 갖도록 디자인했다.
4. Experiments
- ResFields의 versatility를 강조하기 위해 우리는 우리의 방법을 4개의 도전적인 challenge들에 대해 분석했다: neural fields를 통한 2D video approximation, temporal signed distance function의 학습, calibrated camera로부터 dynamic scene의 radiance reconstruction, 3D scene flow의 학습
4.1. 2D video approximation
- 픽셀 좌표들을 RGB color로 mapping하는 것은 복잡한 신호에 맞추는 모델 capacity를 평가하는 유명한 benchmark이다.
- 비교를 위해 우리는 250과 300프레임으로 이루어진 bikes and cat이라는 2가지 video들을 사용했다. 그리고 RGB 값들에 대해 mean squared error를 최소화하는 것에 의해 neural representation을 fit했다.
- 우리는 image 값들에 대한 overfitting 뿐만 아니라 모델의 interpolation 측면에서 평가하고자 했다.
- 우리는 nerual field modeling에 대한 유명한 grid-based 접근법인 Instant NGP와 우리의 접근법을 비교헀다.
- 우리는 또한 pure MLP-based 접근법인 1024개의 neuron을 갖는 five-layer Siren network와 비교했다.
- 우리는 512개의 neuron을 갖는 five-layer Siren network를 선택했다.
Insights
- 우리는 2개의 video들에 대해 평균낸 PSNR 값들을 학습하고 평가했다.
- Instant-NGP는 data를 hash grid 구조에 저장하는 것이 제한된 MLP capacity의 문제를 풀면서 residual weights의 필요성을 완화하므로 극도로 빠르고 좋은 overfitting 능력을 보여준다.
- 그러나 이는 감소된 일반화 능력이라는 expense를 야기한다.
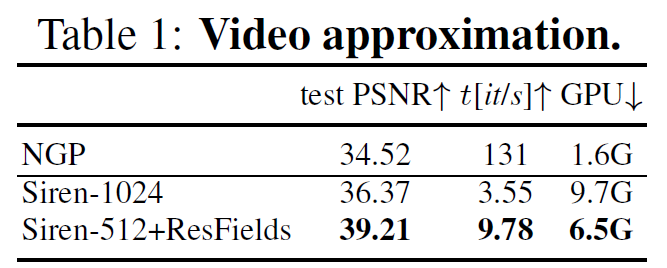
Table 1: Video approximation
4.2. Temporal signed distance functions (SDF)
- Signed-distance functions는 주어진 공간적 좌표 와 shape의 surface 사이의 orthogonal distance를 모델링한다.
- 우리는 time-space coordinate 쌍을 signed distance value로 mapping하는 nerual field network를 통해 signed distance 함수의 temporal sequence를 모델링한다.
- 우리는 어려움의 다른 레벨의 5개의 sequence들을 샘플링하고 ReSynth로부터 하나, ground truth mesh를 SDF 값들로 변환했다.
- 방법들을 benchmark하기 위해 우리는 mesh들의 시퀀스를 marching cube를 통해 학습된 neural fields로부터 추출하고 L1 Chamber distance (CD)와 normal consistency (NC)를 보고했다.
- Main baseline으로 state-of-the-art Siren network (five layers)와 residual field layer들이 3번째 middle layers에서 사용된 ResField layers와 함께 시행된 Siren에 대해 비교했다.
Insights
- 양적이고 질적인 평가는 ResFields가 더 높은 rank와 함께 계속해서 결과를 향상시키며 reconstruction의 quality를 지속적으로 향상시키는 것을 증명헀다.
- Siren with 128 neurons는 vanilla Siren with 256 neurons보다 더 좋은 성능을 냈고 이는 우리의 방법이 훨씬 더 적은 MLP 구조를 사용하기 때문에 GPU memory를 더 적게 요구하면서 2배 더 빠르게 만든다.
4.3. Temporal neural radiance fields (NeRF)
- Temporal or Dynamic NeRF는 color와 density의 함수를 모델링하는 neural fields로서 geometry와 texture를 표현한다.
- 이 모델은 알려진 카메라 포즈로부터 캡쳐된 이미지들과 미분 가능한 ray marcher 사이의 pixel-wise error를 최소화하는 것에 의해 학습된다.
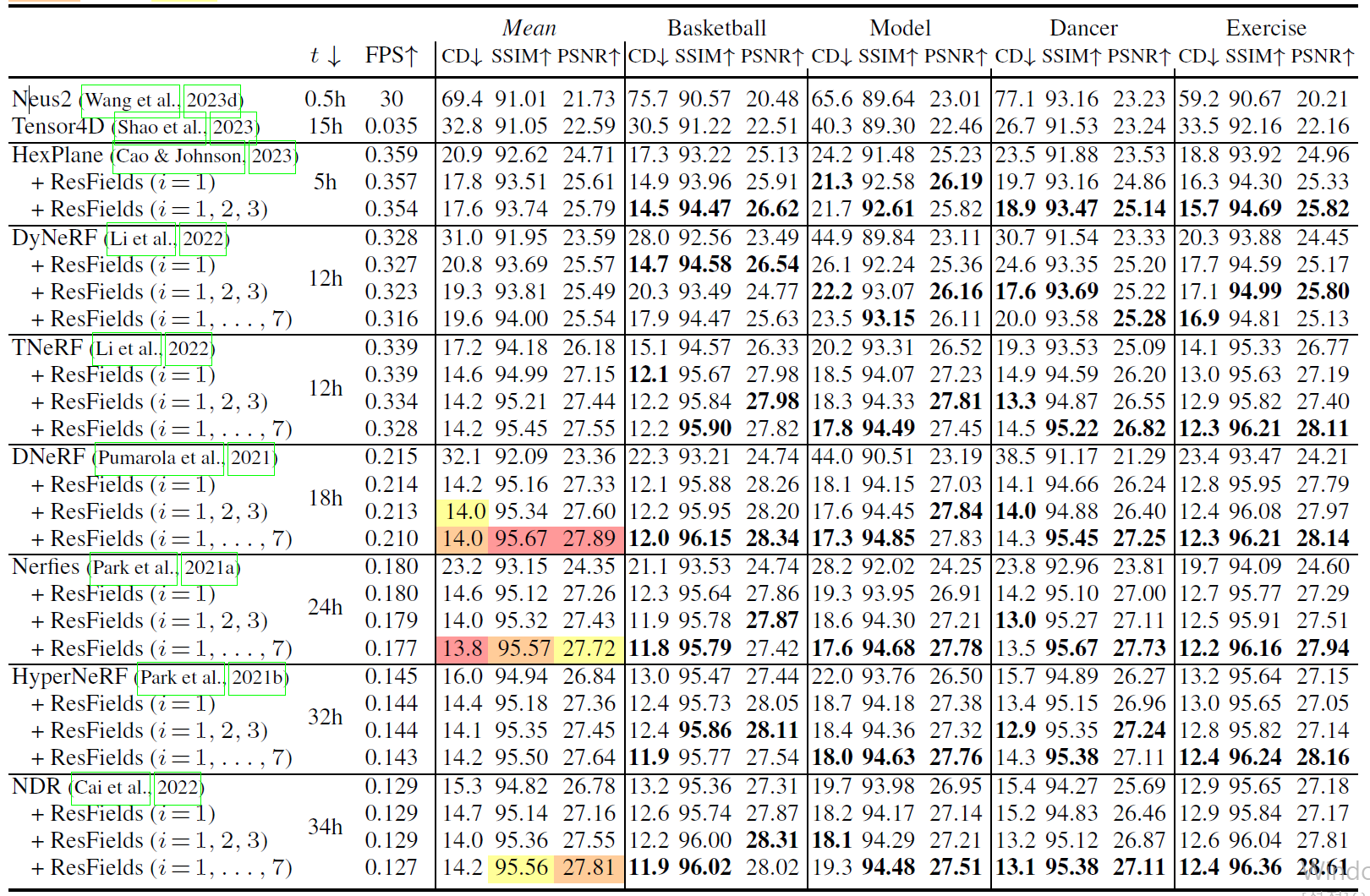
Table 3: Temporal radiance field reconstruction on Owlii. 이전의 state-of-the-art 방법들은 높은 계산적인 overhead를 가하지 않고 지속적으로 ResField layer들로부터 지속적으로 이익을 얻었다.는 어떤 layer들이 ResFields layer로 대체되었는지를 나타낸다.
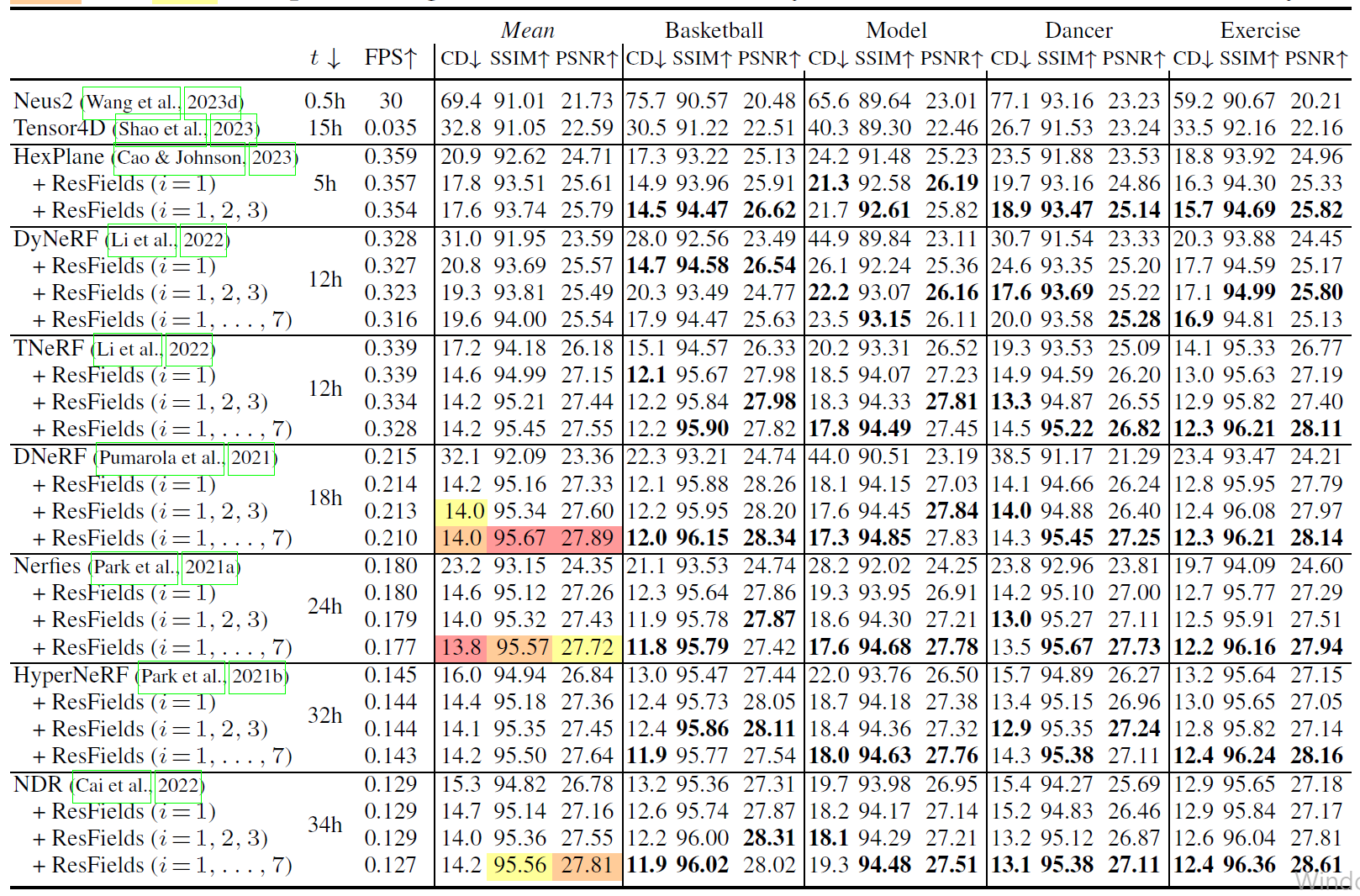

Figure 5: Temporal radiance fields on Owlii.
-
Geometry를 더 잘 모델링하기 위해, 우리는 MLP 구조와 volSDF로부터 signed distance field formulation을 도입했으며 이는 SDF에 적용되는 Laplace의 cumulative distribution function으로서 density function을 정의한다.
-
모든 모델들은 rendered colors와 ground truth colors 사이의 pixel-wise 차이( error), 렌더링된 opacity와 gt mask (binary cross entropy)를 최소화하는 것, 그리고 sparse 캡쳐 setup에서 well-behaved surface를 위한 Eikonal mean squared error loss를 도입하는 것에 의해 감독된다.
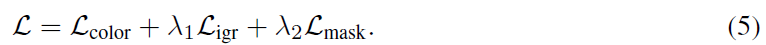
-
우리는 Owlii 데이터셋으로부터 method를 평가하기 위해 4개의 시퀀스들을 사용한다. 이전에 task를 위해 이용되었던 fully synthetic sequence들과 비교했을 때, dynamic Owlii 시퀀스들은 더 빠르고 복잡한 고주파의 움직임을 보여주었고 MLP-기반의 방법들에 대해 더 어려운 task로 만들었다.
-
동시에, ground truth 3D scans의 존재는 RGB 데이터만 가능할 때와 달리, 우리가 geometry와 appearance reconstruction quality를 모두 평가할 수 있게 했다.
-
우리는 100 frames/ time intervals과 100개의 프레임들로부터 회전하는 카메라로 얻은 100개의 테스트 이미지들로부터 4개의 static camera view들로부터 400개의 RGB 이미지들을 rendering했다. 우리는 Chamber distance (CD ) (scaled by ) 그리고 standard image-based metrics (PSNR , SSIM )를 기록했다.
우리는 최근의 state-of-the-art 방법들과 그 변형들인 ResField layers of rank ten ( = 10) - TNeRF, DyNeRF, DNeRF, Nerfies, HyperNeRF, NDR 그리고 HexPlane, 최근의 timespace-partitioning methods Tensor4D 그리고 NeuS2를 benchmark했다.
Lightweight capture from three RGBD views

Table 4: Lightweight capture from three RGBD views
- 우리는 150 프레임들로 구성된 4개의 시퀀스들을 캡쳐하여 computational complexity와 정확도 사이의 좋은 균형을 가진 baseline인 TNeRF와 모든 middle layers에 적용된 ResFields를 가진 그것의 enhancement를 비교했다.
- SSIM과 LPIPS에 대한 양적인 평가는 ResFields가 지속적으로 reconstruction에서 이익을 얻는 것을 보여준다. 하지만, 우리는 두 방법들 모두 선글라스 끈과 같은 얇고 작은 표면들에 대해 어려움을 겪는 것을 관측했다.
4.4 Scene flow
- Scene flow는 space 와 time 에서 모든 point들에 대해 3D motion field를 모델링한다.
- 우리는 같은 4개의 deforming things sequence들을 받아들이고 양방향의 flow를 학습한다.
- 우리는 80%의 tracked mesh vertice들을 flow의 학습에 사용하며 남은 20%를 평가에 사용한다.
- Supervision으로서, 우리는 예측된 vector들과 ground truth flow vector들 사이의 error를 사용한다.
- 우리는 offset vectors, SE(3) transformations, DCT bases의 상관 계수를 예측하는 3가지 motion model들을 고려한다.
- 그 모든 것들을 위해, 우리는 8-layer ReLU-MLP with positional encoding과 같은 구조를 고려한다.
Insight
- Table 5는 evaluation points를 위해 error를 보고했다. ResFields는 모든 setting에서 scene flow의 학습에 있어 크게 이익을 얻었다. 그러나 256 neuron의 구조는 훨씬 더 작고 빠른 counterpart인 128 neurons with ResFields (rank of 10)보다 덜 강력했다. 특히 128 neurons with ResFields(rank of 10)의 경우가 3배 정도 빨랐다.
4.5. Ablation study
ResField modeling
- Layer weights ()의 residual connection은 더 흔하게 사용되던 conditional generation, 직접적으로 modulating layer weights (), LoE에서 time-dependent weights ()보다 더 강력하다.
Factorization techniques
- 우리는 우리의 factorizaiton을 no factorizaiton, low-rank matrix-matrix decomposition, regressing network parameters, 계층적인 Level-of-Experts (LoE) 그리고 전통적인 CP 등 대안적인 기법들과 비교했다.
- No factorization: 뛰어난 학습 PSNR을 달성했지만 일반화 성능은 최적이 아니었고 이는 계층적 formulation인 LoE에 의해 완화되었다.
- 제안된 factorization은 최고의 일반화 속성을 보여주었다.
Limitaitons
- 전반적인 ResFields는 제한없는 문제를 풀기 보다는 bottleneck이 모델 capacity에 있을 때 spatiotemporal neural fields에 이익을 준다.
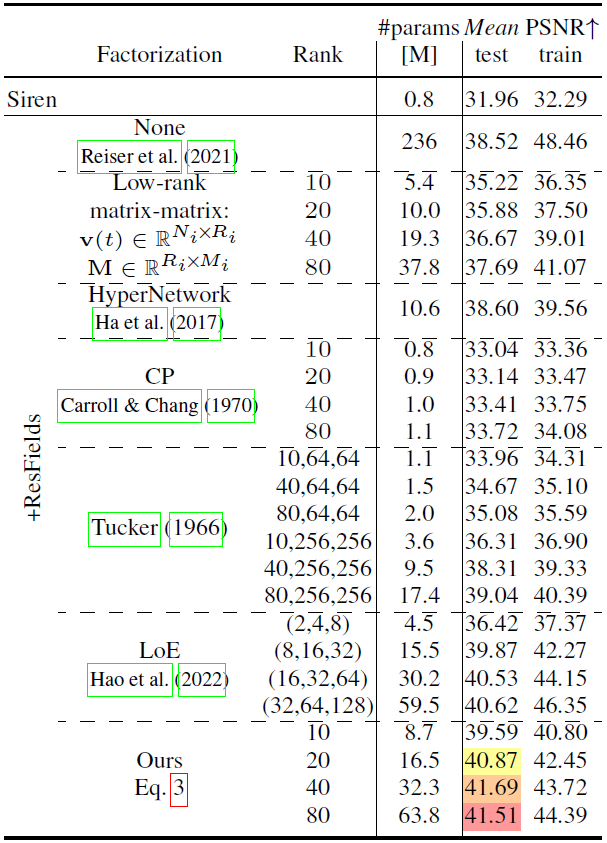
Table 7: Factorization techniques
5. Discussion and conclusion
- 우리는 길고 복잡한 temporal signal들을 효율적으로 모델링하는 것에 있어 spatiotemporal neural fields의 한계를 극복하는 참신한 접근법을 제시한다.
- 우리의 key idea는 temporal residual layer들을 Resfields라고 불리는 neural fields로 통합하는 것이다.
- 우리의 밥법을 이용할 때의 이점은 versatility와 2D와 3D temporal fields를 모델링할 때 존재하는 연구들로 직접적인 통합이다.
- ResFields는 layer나 neuron 수의 측면에서 network 구조의 확장 없이 MLP의 capacity를 증가시키는데 이는 더 작은 MLP가 reconstruction quality를 희생하지 않고 더 낮은 GPU 메모리 요구량과 함께 더 빠른 추론을 달성할 수 있게 해준다.
- 우리는 우리의 연구가 neural fields의 발전에 기여하고 신호를 모델링하는데 있어 가치있는 insight들을 제공하기를 희망한다. 이는 차례로, computer graphics, computer vision, 그리고 robotics 등 다양한 분야에서 진보로 이어질 것이다.