Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (SIGGRPAH 2022)
Paper review
Instant NGP라고 불리는 NVIDIA의 유명한 논문이다. 2022년 최고의 발명품으로 선정되었다는데 어떤 기여가 있는지 궁금하다. Dream 기업 NVIDIA의 논문 읽어보자!
논문: https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
프로젝트 홈페이지 : https://nvlabs.github.io/instant-ngp/
Github: https://github.com/NVlabs/instant-ngp
Motivation
- Fully connected neural networks에 의해 파라미터화 된 Neural graphics primitives는 학습하고 평가하는데 비용이 많이 든다.
- 이 encoding 중에서 가장 성공적인 것은 학습가능하고 task-specific data 구조로 learning task에서 큰 portion을 차지한다.
그러나 이러한 데이터 구조는 heuristics와 구조적 수정(pruning, spliting, merging)에 의존하여 학습 과정을 복잡하게 만들고 methods를 특정 task로 제한하며 GPU의 performance를 control flow와 pointer chasing이 비싼 곳으로 제한한다.
Contributions
- 우리는 이러한 문제들을 우리의 multiresolution hash encoding으로 다루며 이는 적응적이고 효율적며, task에 독립적이다.
- 우리는 더 작은 network의 사용을 quality의 손상 없이 가능하게 하는 versatile 새로운 multiresolution hash encoding을 통해 이 cost를 줄였다.
Future direction
- MLP의 size를 줄임으로 인해 발생하는 문제들을 보완해야 한다.

Fig. 1. 우리는 다수의 task들을 위한 single GPU에서 neural graphics primitives의 instant 학습을 증명한다.
Abstract
- Fully connected neural networks에 의해 파라미터화 된 Neural graphics primitives는 학습하고 평가하는데 비용이 많이 든다.
- 우리는 더 작은 network의 사용을 quality의 손상 없이 가능하게 하는 versatile 새로운 입력 encoding을 통해 이 cost를 줄였다.
- 작은 neural network는 값이 stochastic gradient descent에 의해 최적화된 학습 가능한 feature vector들의 multiresolution hash table에 의해 증강된다.
- Multiresolution 구조는 network가 hash collision의 차이를 분명하게 보여주도록 하여 modern GPU에 대해 병렬화하기 사소한 구조를 만든다.
- 우리는 이 병렬성을 이용하여 전체 시스템을 fully-fused CUDA 커널을 이용해 싫행하고 낭비된 bandwidth와 연산량을 줄이고자 한다.
- 우리는 magnitude의 몇 가지 순서의 combined speedup을 달성했고 몇 초 안에 높은 퀄리티의 neural graphics primitives를 학습시키는 것과 1920 1080 해상도로 수십 milliseconds안에 rendering을 가능하게 했다.
1. Introduction
-
컴퓨터 그래픽스의 primitives는 근본적으로 appearance를 파라미터화하는 수학적 함수에 의해 표현된다.
-
이러한 접근법들의 가장 중요한 공통점은 neural network 입력들을 더 높은 차원으로 mapping하는 encoding으로 compact model들로부터 high approximation quality를 추출하는데 있어 key가 된다.
-
이 encoding 중에서 가장 성공적인 것은 학습가능하고 task-specific data 구조로 learning task에서 큰 portion을 차지한다.
-
그러나 이러한 데이터 구조는 heuristics와 구조적 수정(pruning, spliting, merging)에 의존하여 학습 과정을 복잡하게 만들고 methods를 특정 task로 제한하며 GPU의 performance를 control flow와 pointer chasing이 비싼 곳으로 제한한다.
-
우리는 이러한 문제들을 우리의 multiresolution hash encoding으로 다루며 이는 적응적이고 효율적며, task에 독립적이다. 이는 2가지 값들로 구성되는데 parameter의 수 와 바람직한 finest resolution 로 몇 초간의 학습만으로 다양한 task들에 대해 state-of-the-art quality를 생성한다.
- Task에 독립적인 적응성과 효율성의 key는 hash table의 multiresolution hierarchy이다.
-
Adaptivity
- 우리는 grids의 cascade를 feature vectors의 대응하는 fixed size array들로 mapping한다.
- Coarse resolution에서 grid point로부터 array entries까지 1:1 mapping이 있다.
- Fine resolution에서 array는 the array는 hash table로서 다뤄지고 다수의 grid point들이 각 array entry를 alias하는 공간적인 hash function을 사용하여 index된다.
- 이러한 hash collision들은 충돌하는 학습 gradients가 평균되도록 하며 가장 큰 gradient가 지배적이다.
-
Efficiency
- 우리의 hash table lookups는 으로 control flow를 요구하지 않는다.
-
The hash table들은 모든 해상도에서 병렬적으로 요구된다.
-
우리는 multiresolution hash encoding을 4개의 representative task들에 대해 평가했다.
(1) Gigapixel image: the MLP는 고해상도 이미지에서 2D 좌표를 RGB colors에 mapping하는것을 학습한다.
(2) Neural signed distance functions (SDF): the MLP는 3D 좌표들을 surface까지의 거리로 mapping하는 것을 학습한다.
(3) Neural radiance caching (NRC): the MLP는 Monte Carlo path tracer로부터 scene의 5D light field를 학습한다.
(4) Neural radiance and density fields (NeRF): the MLP는 이미지 관측과 대응하는 perspective transforms로부터 주어진 scene의 3D density와 5D light field를 학습한다.
Background and related work
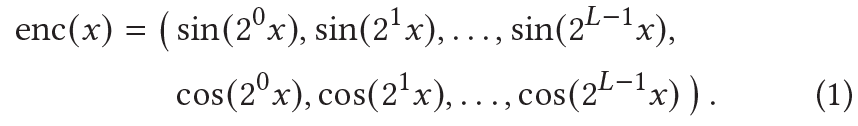
- NeRF에 사용된 positional encoding의 식은 위와 같다.
- Parametric encoding: 최근의 state-of-the-art 결과들은 parametric encoding에 의해 달성된 것으로 이는 전통적인 데이터 구조와 neural 접근법들 사이의 line을 흐리게 한다. 아이디어는 추가적 학습 가능한 parameter들을 grid 또는 tree와 같은 예비 데이터 구조에 배열하는 것이다.
- Parameter의 수는 parametric encoding이 input encoding보다 훨씬 더 크지만 학습 중 업데이트에 필요한 FLOPs와 memory 접근들의 수는 현저하게 증가하지 않는다.
- MLP의 size를 줄이는 것에 의해, parametric model은 approximation quality를 희생하지 않고 훨씬 빠르게 수렴할 수 있다.

Fig. 2: 학습 가능한 feature embedding들에 대해 다른 encoding과 parametric data 구조들의 reconstruction quality의 증명
- 또 다른 parametric 접근법은 domain 의 tree subdivision을 사용하며 큰 예비 좌표 encoder neural network (ACORN)가 학습되어 주변의 leaf node에서 dense feature grids를 출력한다.
- 이 dense feature grids는 10000 entries의 순서를 갖고 선형적으로 보간된다. 이 접근법은 더 큰 계산적 비용에도 불구하고 더 큰 적응도를 생성한다.
Sparse parametric encodings
- Parametric encoding이 non-parametric encoding보다 훨씬 정확하지만 학습 가능한 feature들의 dense grids는 neural network weights보다 훨씬 더 많은 memory를 사용한다.
- Figure 2는 몇몇 다른 encoding들에 대해 neural radiance field의 reconstruction quality를 보여준다.
- (a): The network는 위치의 smooth function만 학습할 수 있으며 light field의 poor approximaiton 결과를 낳는다.
- (b): The frequency encoding은 같은 moderately sized network (8 hidden layers, each 256 wide)가 scene을 훨씬 더 정확하게 표현할 수 있게 해준다.
- (c): The middle image는 trilinearly interpolated dense grid를 가진 더 작은 network와 33.6 million 학습가능한 parameters를 가진 16 차원의 feature vectors를 짝짓는다. 큰 수의 학습가능한 parameter들은 효율적으로 업데이트될 수 있고 각 sample은 8 grid point들에만 영향을 미친다.
- 그러나 dense grid는 2가지 측면에서 낭비적이다.
- 이것은 많은 feature들을 surface 근처만큼이 나 많이 빈 공간에 할당한다.
- 자연적인 scene들은 smoothness를 보여주며 multi-resolution decomposition의 사용을 장려한다.
- Figure 2 (d)는 interpolated feature들이 에서 d의 eight co-located grids에 저장되는 encoding을 보여준다. 각각은 2차원의 feature vector들을 포함하고 있다.
- 이것들은 network에 대해 16 차원의 input을 형성하기 위해 이어붙여진다.
- (c)와 같이 parameter의 수가 절반 이하지만 reconstruction quality는 비슷하다.
- Interest의 표면이 priori라면, octree나 sparse grid와 같은 데이터 구조는 dense grid에서 사용되지 않은 feature들을 선별하는데 사용될 수 있다.
- NSVF와 몇몇 최신 연구들은 multi-stage coarse to fine strategy를 도입했고 여기서 feature grid는 필요에 따라 단계적으로 정제되고 선별된다.
- 우리의 방법은 -Figure 2(e,f)- 2가지 방법을 결합하여 낭비를 줄인다.
- 우리는 학습 가능한 feature vector들을 compact spatial hash table에 저장했고 그 크기는 로 이는 파라미터의 수와 reconstruction quality를 바꾸기 위해 조정될 수 있다.
- 이는 학습 중에 progressive pruning 또는 scene의 geometry의 pior knowledge에 의존하지 않는다.
- (d)의 multi-resolution grid와 유사하게 우리는 다른 resolution들에 대해 index된 다수의 독립된 hash table들을 사용한다.
- The reconstruction quality는 dense grid encoding과 비교할만하며 20배 적은 parameter들을 갖고 있다.
- 우리는 probing, bucketing, chaining과 같은 전형적인 방법에 의해 hash function의 충돌을 다루지 않고 neural network에 의존하여 hash 충돌 자체를 명확히 하고 복잡성의 시행을 줄이며 성능을 향상시킨다.
- 우리의 hash table은 cache size와 같은 low-level 구조적 detail에서 fine-tune될 수 있다.
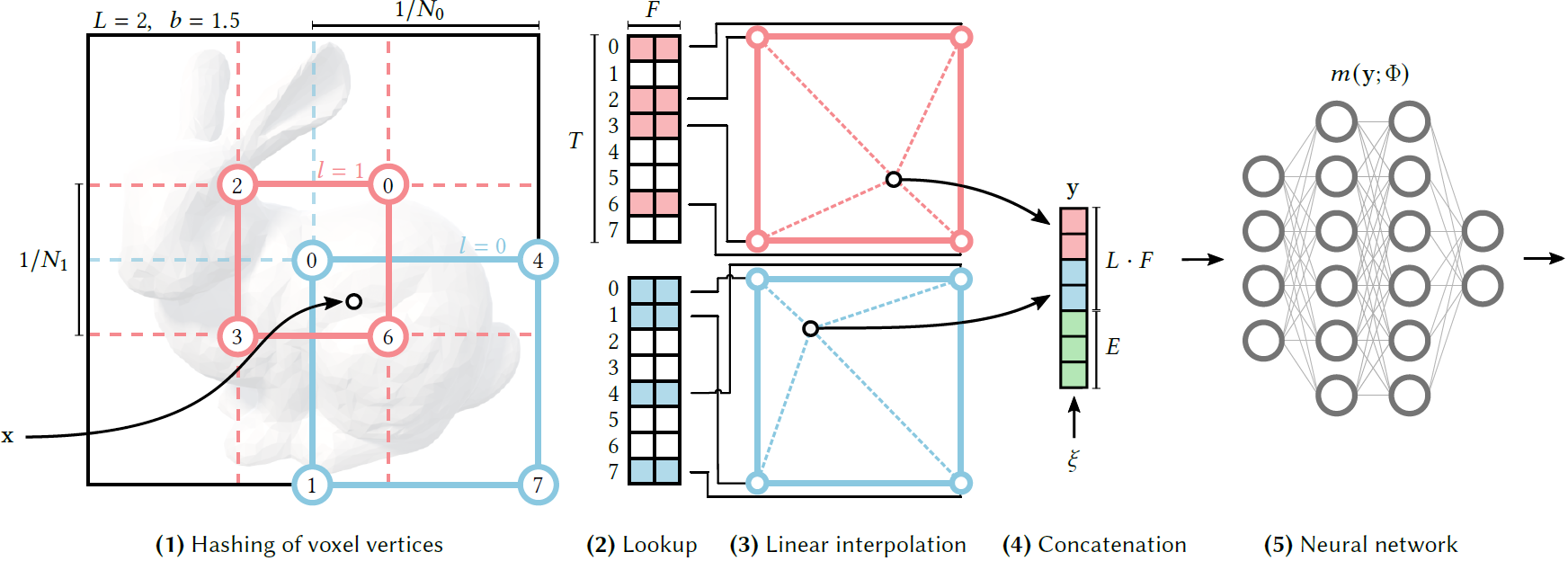
Fig. 3. Illustration of the multiresolution hash encoding in 2D. (1) 주어진 입력 좌표 , 우리는 resolution level에서 둘러싸는 voxel을 찾고 integer 좌표들을 hashing하는 것에 의해 그 coner들에 indices를 부여했다. (2) 모든 corner indices에 대해, 우리는 hash table 로부터 대응하는 F-차원의 feature vector들을 look up했다. (3) -th level에서 상대적 position 에 따라 그들을 interpolate한다. (4) 예비적인 inputs $ \xi \in \R^E$ 뿐만 아니라 각 level의 결과들을 이어붙여 encoded MLP input 를 생성한다. Encoding을 학습하기 위해, loss gradients는 MLP, concatenation, the linear interpolation, accumulated look-up feature vectors를 통해 backpropagate된다.

Table 1. 우리의 결과들에 대한 Hash encoding parameter들과 그 범위. Hash table size 와 max. resolution 만 task에 tune되어야 함.
Multiresolution hash encoding
- Fully connected neural network )가 주어졌을 때, 우리는 뚜렷한 performance overhead 없이 approximation quality와 학습 속도를 향상시키는 inputs 의 encoding에 관심이 있다.
- 우리의 neural network는 학습 가능한 weight parameters 뿐만 아니라 학습 가능한 encoding parameters 를 갖고 있다.
- Figure 3은 multiresolution hash encoding에서 수행되는 단계를 나타낸다.
- 각 level은 독립적이고 개념적으로 feature vector들을 grid의 vertice에 저장한다. 각 resolution은 coarsest와 finest resolutions 사이의 geometric progression에 따라 선택된다. []
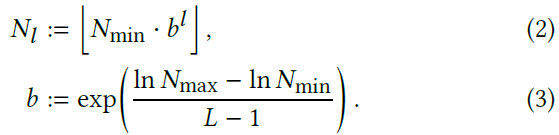
- 는 학습 데이터에서 finest detail을 match하기 위해 선택되었으며 level 의 큰 수 때문에 groth factor는 보통 작다. 우리의 경우 를 사용한다.
- Dense grid가 보다 적은 parameters를 요구하는 coarse level에 대해 이 mapping은 1:1이다. Finer level에서, 우리는 hash function 을 array로 index하여 효율적으로 hash table을 다루는데 사용한다. 하지만 이 과정에도 명백한 collision handling은 없다.
- 우리는 적절한 sparse detail을 array에 저장하기 위해 gradient-based optimization에 의존한다.
- 우리는 각 corner를 level의 feature vector array에서 entry로 mapping한다.
- 우리는 다음 형태를 갖는 공간적 hash function을 사용한다.
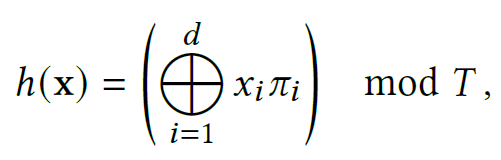
- 여기서 는 bit-wise XOR 연산을 나타내며 는 unique하고 큰 prime numbers를 의미한다.
- 각 corner에서의 vector들은 hypercube 내에서 position 에 따라 -linearly interpolated 되었다.
- The interpolation weight:
- 이 과정이 level들에 대해 독립적으로 발생하는 것을 떠올려보면, 예비적인 inputs 뿐만 아니라 각 level의 interpolated feature vector들은 이어붙여져서 를 생성한다. 이는 MLP 로의 encoded input 이다.
Performance vs quality
- Hash table size 를 선택하는 것은 performance, memory 그리고 quality 사이의 trade-off를 제공한다.
- 높은 값의 는 더 높은 quality와 더 낮은 performance를 야기한다.
- The memory footprint는 에 비례하며 quality와 performance는 sub-linearly scale하는 경향이 있다.
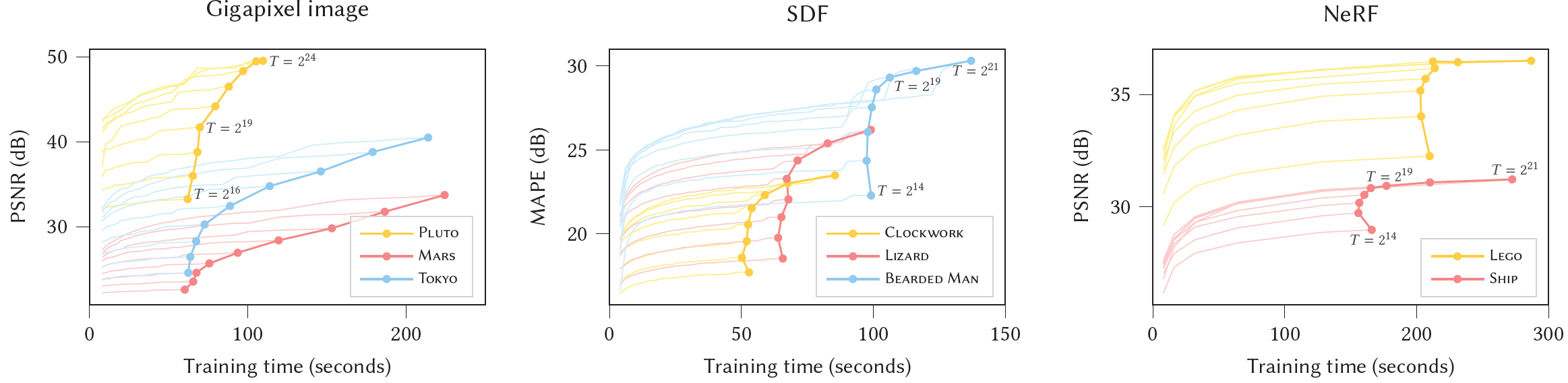
Fig. 4. 학습 가능한 encoding parameters를 결정하는 변화하는 hash table size 를 위한 학습 시간에 따른 test error를 plot한다. 변화하는 hash table size 는 학습 가능한 encoding parameters의 수를 결정하며 증가하는 T는 더 높은 메모리 사용과 더 느린 학습 및 추론을 희생하여 reconstruction을 개선한다. - 일 때 performance cliff를 관찰할 수 있으며 이는 특히 SDF와 NeRF에서 두드러진다.
- 이 plot은 시간에 따라 model convergence를 보여주며 final state로 이어지며 이는 high quality results가 어떻게 몇 초 안에 얻어지는지 보여준다.
- Convergence에서의 jump는 learning rate decay에 의해 야기되며 NeRF와 Gigapixel image는 학습을 31000 steps에 끝냈고 SDF는 11000 steps 후에 끝냈다.
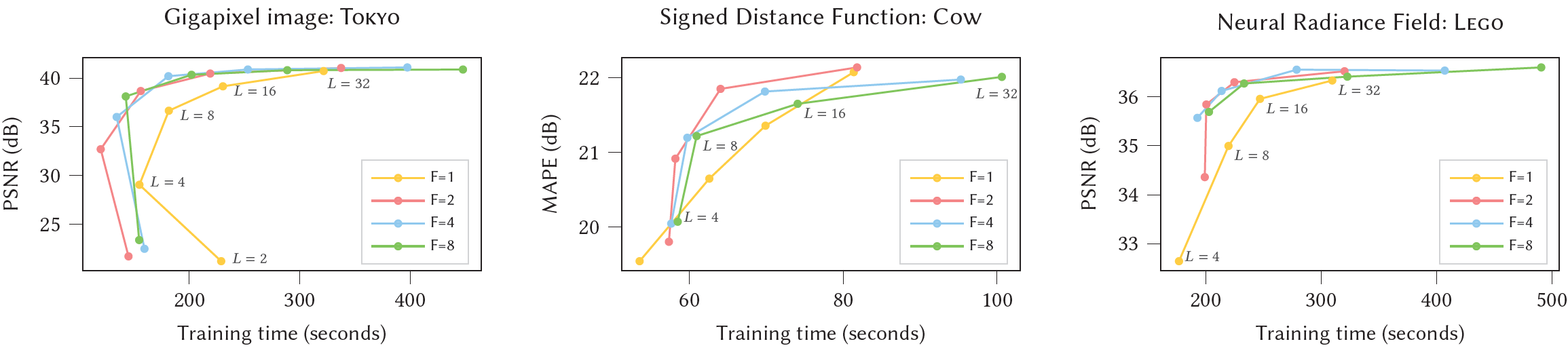
Fig. 5. Hash table levels 이 변할 때, feature 차원 의 고정된 값들을 위한 학습 시간에 대한 Test error.
()이 모든 application에서 best-case performance and quality에 가까우므로 우리는 모든 결과들에 대해 이 configuration을 사용한다. 은 RTX 3090 GPU에 대해 느린데 이는 atomic half-precision accumulation이 2D vectors에 대해서만 효율적이지만 scalars에 대해서는 아니기 때문이다. NeRF와 Gigapixel image에 대해 학습은 31000 steps에 끝났고 SDF는 11000 steps에 끝났다.
- 우리는 의 영향을 Figure 4에서 분석했으며 우리는 3개의 neural graphics primitives에 대해 넓은 범위의 값들에 대해 test error vs training time을 보고했다.
- The hyperparameters (number of levels)와 (number of feature dimensions)는 quality와 performance의 trade off 관계이다. 우리는 ()이 모든 applications에서 선호할만한 Pareto optimum임을 알게 되었다.
- 그래서 우리는 이 값들을 모든 결과들에 대해 사용하고 default로서 추천한다.
Implicit hash collision resolution
- 다른 resolution level들은 서로서로를 보완할 수 있는 힘을 갖고 있다.
- The coarser level들은 injective해서 충돌로부터 어려움을 전혀 겪지 않는다. 그러나 그것들은 넓게 위치한 grid of points들로부터 선형적으로 보간되는 feature들을 제공하기 때문에 scene의 low-resolution version만 표현할 수 있다.
- Fine level들은 fine grid resolution 때문에 작은 feature들을 capture할 수 있지만 많은 충돌들로부터 어려움을 겪는다. 즉 벗어난 point들은 같은 table entry에 hash된다.
- 더 중요한 sample들의 gradients는 collision average를 지배하고 aliased table entry는 자연적으로 더 높은 weighted point를 반영하는 방식으로 최적화된다.
- Hash encoding의 multiresolution aspect는 coarse resolution 에서 finest resolution 의 전체 범위를 다룬다.
- 이는 모든 scale들이 포함되는 것을 보장하며 Geometric scaling은 이 scale들을 의 많은 level들에서 다루며 이는 보수적으로 의 큰 값을 선택하는 것을 허용한다.
Online adaptivity
- Inputs 가 좁은 영역에 집중되어 있으면 finer grid level들은 더 적은 충돌과 더 정확한 학습될 수 있는 함수를 경험할 것이다.
- Multiresolution hash encoding은 학습 중에 discrete jumps를 야기할 수 있는 task-specific data maintenance 없는 tree-based encoding의 장점을 물려받아 학습 데이터 분포에 자동적으로 적응한다.
- Neural radiance caching이 feature로부터 크게 이익을 얻어 animated viewpoints와 3D content에 계속해서 적응한다.
d-linear interpolation
- Queried hash table entry들을 interpolate하는 것은 와 chain rule에 의한 이것의 neural network composition 가 연속적이게 만든다.
- Interpolation 없이, grid-aligned discontinuity들은 network 출력에 존재하고 이는 바람직하지 않은 blocky appearance를 야기한다.
4. Implementation
Performance considerations
- 추론과 backpropagation performance를 최적화하기 위해, 우리는 hash table entry들을 half precision에 저장했다. 우리는 추가로 안정적인 mixed-precision parameter updates를 위해 full precision에서 parameter들의 master copy를 추가적으로 유지한다.
GPU의 caches를 효율적으로 사용하기 위해 우리는 입력 positions의 batch를 처리할 때, hash table들을 level by level로 평가한다.
Architecture
- NeRF를 제외히고, 우리는 width가 64 neurons인 two hidden layers를 가진 MLP를 사용했고 이는 rectified linear unit (ReLU) activation functions, 그리고 linear output layer를 갖고 있다.
- 는 NeRF와 signed distance functions에 대해 2048 의 scene size를 갖고 gigapixel image width의 절반, radiance caching에서 의 값을 갖는다.
Training
- 우리는 , , 일 때, Adam을 적용하여 neural network weights와 hash table entries를 공동으로 학습한다.
- Gigapixel image들이나 NeRFs를 fitting할 때, 우리는 loss를 사용한다. 우리는 아래 식과 같은 mean absolute percentage error (MAPE)를 사용한다.
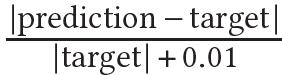
그리고 neural radiance caching에 대해 우리는 luminance-relative loss를 사용한다. - Light field의 학습에서 view direction과 material parameters 등에서 예비 입력 차원 는 neural network에 도움이 된다.
- 우리는 neural radiance caching에서 one-blob encoding을 사용하고 NeRF에서 spherical harmonics basis를 사용한다.

Fig. 6. 우리의 multiresolution hash encoding과 함께 해상도의 RGB image 근사를 나타낸다. Hash table size 값이 , , 로 증가함에 따라 모델의 학습 가능한 parameter의 수도 117k, 2.7M, 47.5M으로 증가함.
5. Experiements
- Versatility와 encoding의 높은 quality를 강조하기 위해, 우리는 이를 공간적 좌표들을 encoding하는 것으로부터 이익을 얻는 4개의 구분된 computer graphics primitives에서 이전의 encoding과 비교한다.
5.1. Gigapixel Image Approximation
- 우리는 multiresolution hash encoding을 사용하여 large image들을 높은 정확도로 fitting하는데 사용했고 몇 초에서 몇 분 안에 high-fidelity images로 수렴한다.
- Figure 1, ACORN의 TOKYO panorama는 36.9 시간의 학습 이후 38.59dB의 PSNR을 달성했고 비슷한 수의 parameter를 가진 우리의 방법은 같은 PSNR을 2.5분의 학습 후에 달성했고 4분 후에 41.9dB의 peak 값에 도달했다.
- Multiresolution hash encoding의 가장 큰 value-add는 simplicity로 ACORN의 경우 학습 curriculum으로 adaptive subdivision에 의존하는데 이는 우리의 encoding에 필요하지 않다.
5.2. Signed Distance Functions
- Signed distance functions (SDFs)은 position 의 함수의 zero level-set으로서 표현된 3D shape으로 simulation, path planning, 3D modeling, 그리고 video games 등 많은 application에 사용된다.
- DeepSDF는 large MLP를 사용하여 하나 또는 그 이상의 SDF들을 한번에 표현한다.
- 우리는 NGLOD를 우리의 multiresolution hash encoding과 equal parameter count에 대해 rough하게 비교했다. 그러나 전용의 데이터 구조 없이 비슷한 성능과 memory cost와 함께 intersection-over-union 측면에서 NGLOD와 비슷한 정확도에 접근했다.
- 우리는 비교되는 방법들과 차이를 강조하기 위해, 우리는 shading model을 사용하여 SDF를 시각화했고 결과로 나오는 color들은 surface normal의 작은 변화에도 민감했다.

Fig.7. 11000 step동안 학습한 Neural signed distance functions.
- The frequency encoding: 복잡한 모델들에서 sharp detail을 catch하는데 문제를 겪는다.
- NGLOD: Close-fitting octree의 cell 안의 SDF만 학습하여 가장 높은 visual quality를 달성헀다.
- 우리의 hash encoding은 intersection over union (IoU) 측면에서 유사한 numeric quality를 보여주며 scene의 어디서나 평가될 수 있다.
- 그러나 hash collisions 때문에 시각적으로 바람직하지 않은 surface roughness를 보여준다.

Fig. 8. Neural radiance caching application의 요약.
- The MLP 는 각 픽셀에 대해 독립적으로 feature buffer들로부터 photorealistic pixel color들을 예측한다.
- The feature buffer는 world-space position 를 포함하며 우리는 우리의 method에서 position을 encode한다.

Fig. 9. Neural radiance caching은 약한 성능 penalty만 갖고 multiresolution hash encoding으로부터 훨씬 향상된 quality를 얻는다.
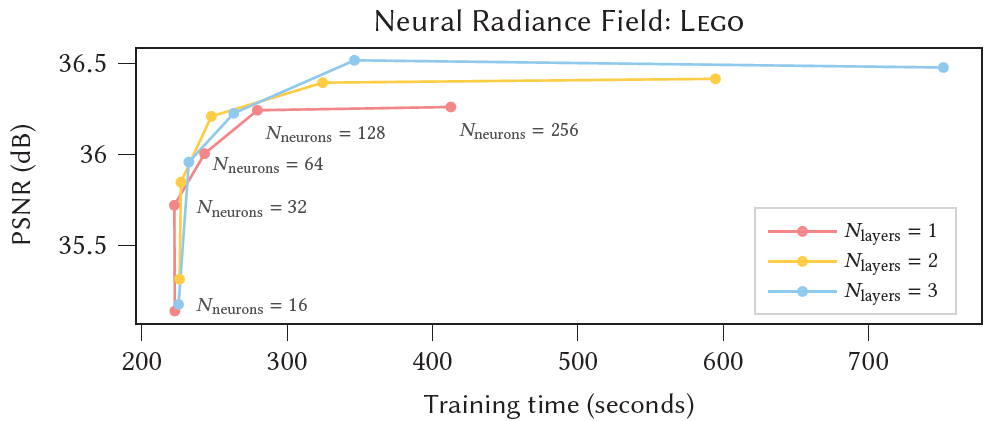
- LEGO scene에 대해 test error와 training time (31000 학습 steps)에 대한 MLP 크기의 효과. The curves는 density와 color MLP에서 뉴런의 수를 16부터 256까지 sweep했으며 우리는 , 를 선택했다.
5.3. Neural Radiance Caching
- Neural radiance caching에서 MLP의 task는 feature buffer로부터 photorealistic pixel color들을 예측하는 것이다.
- 우리는 에 multiresolution hash encoding을 직접적으로 적용하고 모든 추가적인 feature들을 encoded position에서 이어붙여진 예비 encoded 차원 로서 다뤘다.
- 우리는 우리의 연구를 Muller et al의 neural radiance caching 시행에 통합했고 시행 detail을 위해 그들의 논문을 참고했다.
- 우리는 reconstruction error보다 neural radiance cache error를 강조하고자 했으며 우리의 multiresolution hash encoding을 사용하여 그 향상이 얻어지고자 했다.
5.4. Neural radiance and Density Fields (NeRF)
- NeRF setting에서, volumetric shape은 공간적 (3D) density function과 spatiodirectional (5D) emission function으로 표현된다.

Fig. 11. NeRF를 학습할 때 MLP에 대해 linear transformation을 통한 우리의 encoding 결과. - 모델은 1분동안 학습되었고 The MLP는 특정 detail들을 해결하고 hash collision에 의해 야기된 background noise의 양을 줄인다. MLP의 작은 size와 효율적인 시행 떄문에, 이것은 15% 비용이 더 들지만 현저하게 향상된 quality를 보여주었다.
Model Architecture
- 우리의 NeRF 모델은 2개의 이어붙여진 MLP로 이루어져 있다: a density MLP 이후에 a color MLP가 따른다.
- The density MLP는 the hash encoded position 를 16 output value들에 mapping하며 이 중 첫번째 값은 log-space density이다.
- The color MLP는 view-dependent color variation을 더하며 그 입력은
- The density MLP의 16 output values와 spherical harmonics basis의 첫 16 coefficients에 투영된 view direction의 concatenation이다.
- Figure 10에서 보듯이 우리의 결과는 둘 다 64개의 neuron들을 가진 1-hidden density MLP와 2-hidden color MLP로 생성되었다.
Accelerated ray marching
- 학습과 rendering에서 ray들을 쏠 때, 우리는 sample들을 놓고 그들이 불필요한 계산을 줄이면서 image에 균등하게 기여하기를 원한다.
- 그러므로 우리는 empty와 non-empty space를 coarse하게 표시하는 occupancy grid를 유지하는 것에 의해 surface들 근처의 sample들에 집중한다.
- 우리는 추가적으로 occupancy grid를 쌓고 ray를 따라 sample들을 지수적으로 분배한다.
- HD resolution에서, 합성과 real-world scene들은 MLP output의 caching 없이 몇 초안에 학습되고 60 FPS 안에 rendering될 수 있다.
- 높은 성능은 anti-aliasing, motion blur 그리고 픽셀 당 다수의 ray들의 brute-force tracing에 의한 depth of field의 추가를 용이하게 한다.
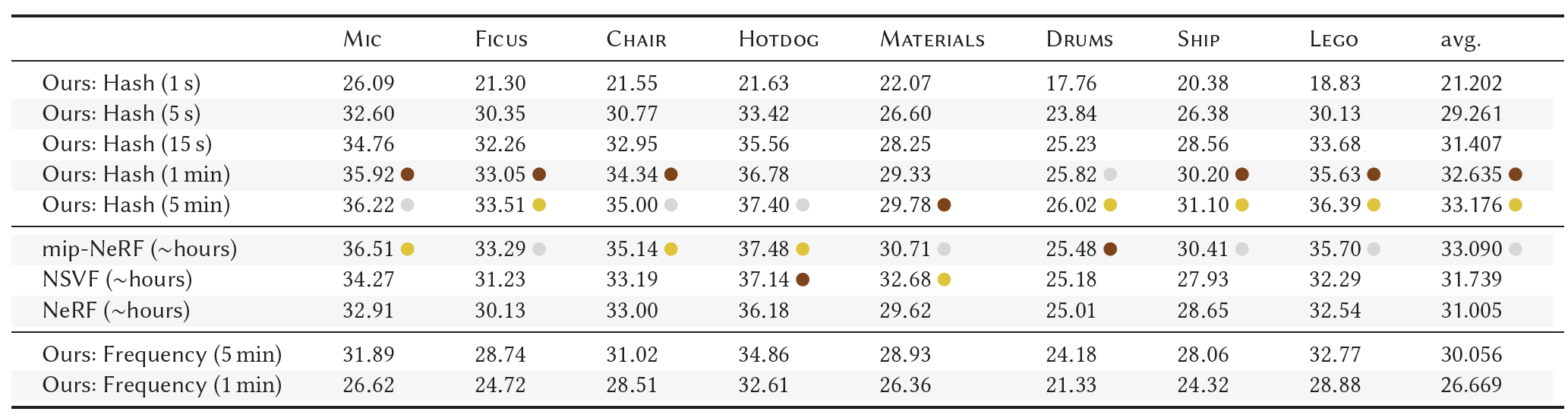
- Table 2. 우리의 multiresolution hash encoding을 가진 NeRF의 시행과 NeRF, mip-NeRF, NSVF의 PSNR 비교.
- 우리의 method의 상대적으로 빠른 학습을 보여주기 위해, 우리는 그 결과를 1~5분 학습 후에 list했다.
- 속도 증가의 원인이 최적화된 시행인지, hash encoding 때문인지 알아보기 위해 hash encoding을 frqeency encoding으로 대체하고 MLP를 Mildenhall et al [2020]와 대응하도록 확장했다
- 이것은 5분 안에 NeRF의 quality에 접근했고 5~15초 학습한 우리의 full method에 의해 압도되었다. 따라서 20-60의 향상은 hash encoding에 기인한다.

Fig. 12. Modular synthesizer의 NeRF reconstruction과 large natural 360 scene. 왼쪽의 이미지는 128개의 sample들을 쌓는데 5초가 걸렸고 brute force defocus effects를 허용한다. 오른쪽 이미지는 같은 GPU에서 1초당 10 frames로 동작하는 상호작용하는 session으로부터 취해졌다.
Direct voxel lookups와의 비교
- Figure 11은 우리가 전체 neural network를 single linear matrix 곱으로 대체할 때 ablation에 대해 보여준다.
- Linear layer가 MLP와 비교했을 때 현저하게 손상되며 MLP는 세부 효과들을 포착하고 the interpolated multiresolution hash table들의 hash collision들을 해결한다.
- MLP는 작은 size와 효율적인 implementation으로 인해 linear layer에 비해 15% 비용이 더 든다.
Comparison with high-quality offline NeRF.
- Table 2에서 우리는 multiresolution hash encoding을 가진 우리의 NeRF 시행의 the peak signal to noise ratio (PSNR)을 NeRF, mip-NeRF, 그리고 NSVF와 비교한다.
- 나머지 모델들은 학습하는 데에 몇 시간이 걸리지만 우리의 method는 1분~5분 정도 걸린다.
- 우리의 방법은 15초만에 NeRF와 NSVF와 경쟁할만하며 1~5분 후에 mip-NeRF와 경쟁할만하다.
- 우리의 방법은 높은 geometric detail이 있는 FICUS, DRUMS, SHIP 그리고 LEGO 등에서 최고의 PSNR을 달성하며 가장 높은 성능을 보였다. 하지만 mip-NeRF, 그리고 NSVF는 복잡하고 view-dependent reflection들이 있는 MATERIALS 같은 scene들에 대해 우리의 방법을 압도했다. 우리는 이것이 speedup을 얻기 위해 작은 MLP를 사용했기 때문이라고 생각한다.
- 우리는 hash encoding을 frequency encoding으로 변경하고 MLP를 the architecture of Mildenhall et al [2020]와 일치하도록 확장했다.
- 이 버전의 알고리즘은 NeRF quality가 되는데 5분 이내의 시간이 걸렸고 훨씬 더 짧은 학습 시간인 5s-15s 내에 우리의 full method에 의해 압도당했다.
- The hash encoding과 더 작은 MLP에 의해 야기된 20-60의 향상이 있다.
- 우리는 우리의 hash encoding과 작은 MLP의 영향이 성능과 수렴으로 한정했지만 우리는 encoding과 network architecture와 별개로 발전된 ray marching schemes(coarse-fine 또는 DONeRF)의 영향을 정량화하는 ablation study가 필요하다고 믿는다.
- 우리는 그러한 분석을 돕기 위한 추가 정보를 Section E.3에서 기록했다.

Fig. 13. NeRF cloud model 학습의 예비적인 결과. (b) 32ms안에, 우리의 모델의 1024 1024 이미지는 offline rendered ground truth에 확실히 근접한다. 우리의 모델은 같은 시간동안 학습한 GPU path tracer보다 더 적은 noise를 보여준다.
6. Discussion and future work
Concatenation vs reduction
- 각 encoding의 끝에 우리는 각 해상도에서 얻어진 차원의 feature vector들을 줄이기보다는 concatenate한다.
- 첫째, 이는 각 해상도에서 독립적이고 완전히 병렬적인 processing을 허용한다.
- LF to F로부터 얻은 encoded result y의 차원의 감소는 유용한 정보들을 encode하기에 너무 작다.
Microstructure due to hash collisions
- 우리의 encoding의 가장 눈에 띄는 요소는 작은 양의 "grainy" microstructure로 learned signed distance functions에서 가장 visible하다.
- The graininess는 hash collision의 결과로 MLP가 완전히 보상할 수 없다.
- SDFs의 quality에서 state-of-the-art를 달성하는 데에 있어 key는 microstructure를 극복할 방법을 찾는 것인데 그 예로 hash table lookup들을 filtering하는 것이나 loss에 대한 prior에 추가적인 smoothness를 가하는 것이 있다.
Generative setting
- Generative setting에 사용된 Parametric input encoding들은 그 feature들을 dense grid에 배열하며 이는 StyleGN과 같은 CNN의 분리된 generator network에 의해 위치될 수 있다.
- 우리의 hash encoding은 복잡성의 추가적인 layer를 더해주고 input domain을 통해 regular pattern에서 정렬되지 않은 feature들은 복잡한 layer를 더한다. 즉, feature들은 point의 regular grid들과 1:1 매칭되지 않는다.
Other applications
- 우리는 the multiresolution hash encoding을 정확하고, high-frequency fit들을 요구하는 다른 low-dimenational task들에 적용하는 것에 흥미가 있다.
- Frequency encoding은 transformer networks의 attention mechanism에서 시작되었으며 우리는 우리의 것과 같은 parametric encoding이 일반적인 attention-based task들에 대한 의미 있는 향상으로 이어지길 바란다.
7. Conclusion
- 많은 graphics 문제들은 task specific data 구조를 사용하여 주어진 문제의 smotthness 또는 sparsity를 이용한다.
- 우리의 multi-resolution hash encoding은 task와 독립적으로 연관된 detail에 자동으로 집중하는 실용적인 learning based alternative를 제시한다.
- 이것의 낮은 overhead는 online 학습과 추론 같은 시간 제한이 있는 환경에서도 이것이 사용될 수 있게 한다.
- Neural network input encoding의 측면에서, magnitude의 몇몇 순서와 concurrent non-neural 3D reconstruction 기법들의 성능에 맞추는 것에 의해 NeRF의 speeding up을 위한 drop-in replacement이다.
- 우리는 몇 초 안에 측정된 single-GPU 학습 시간은 많은 graphics 응용에 적용될 수 있고 neural approach들이 이전에 무시당했던 영역들까지 적용될 수 있음을 입증했다.