
일반적인 AI 모델은 텍스트만 처리하거나, 이미지나 오디오 등 한 가지 데이터 형태에만 특화되어 있지만, 멀티모달(Multimodal)은 텍스트, 이미지, 오디오, 영상 등 서로 다른 형태의 데이터 데이터(모달리티)를 동시에 이해하고 처리할 수 있는 AI 기술이다.
1. 작동 방식
모달리티별 특징 추출
- 텍스트 → Transformer 기반 언어 인코더
- 이미지 → CNN, ViT(Vision Transformer) 등
- 오디오 → 스펙트로그램 변환 후 CNN/Transformer 처리
공통 표현 공간으로 통합
- 서로 다른 데이터 타입을 임베딩(Embedding) 공간에 매핑
- 이를 기반으로 텍스트-이미지 매칭, 이미지 캡셔닝, 음성 질의응답 등이 가능
2. 활용 사례
- 이미지 캡셔닝(Image Captioning): 이미지 내용을 자동으로 텍스트로 설명
- 비디오 분석: 영상 속 장면 설명, 하이라이트 추출
- 텍스트-이미지 생성: DALL·E, Midjourney처럼 문장 입력으로 이미지 생성
- 멀티모달 챗봇: 이미지나 음성을 받아 분석 후 대답하는 AI
- 의료 영상 분석: CT/MRI 이미지와 환자 기록을 함께 분석해 진단 지원
3. 이미지 캡셔닝(Image Captioning)
이미지 캡셔닝(Image Captioning)은 이미지 속 내용을 자동으로 설명하는 문장을 생성하는 기술로 쉽게 말해, AI가 이미지를 보고 “이 사진에 뭐가 있는지”를 사람처럼 글로 표현할 수 있는 컴퓨터 비전(Computer Vision)과 자연어 처리(NLP) 기술을 결합한 대표적인 멀티모달(Multimodal) 분야이다.
3-1. 기본 구조: CNN + RNN
- CNN (Convolutional Neural Network): 이미지를 입력받아 중요한 시각적 특징들을 추출한다.
- 예: ResNet, Inception 등
- RNN (Recurrent Neural Network) 또는 LSTM/GRU: CNN에서 추출된 특징을 기반으로 순차적인 단어를 예측하여 문장을 생성한다.
3-2. 작동 방식
[이미지]
│
▼
[특징 추출 (Feature Extraction)]
├─ CNN (Convolutional Neural Network)
└─ ViT (Vision Transformer)
↓ (이미지 특징 벡터로 변환)
▼
[시퀀스 생성 (Sequence Generation)]
├─ RNN / LSTM
└─ Transformer 기반 언어 모델
↓ (단어를 순차적으로 예측)
▼
[출력 (Caption Output)]
└─ 사람이 읽을 수 있는 자연어 문장4. 디퓨젼 (Diffusion)
디퓨전 모델은 이미지를 점점 노이즈로 변환한 뒤, 그 노이즈를 다시 제거하면서 원하는 이미지를 생성하는 확률 기반 생성 모델이다.
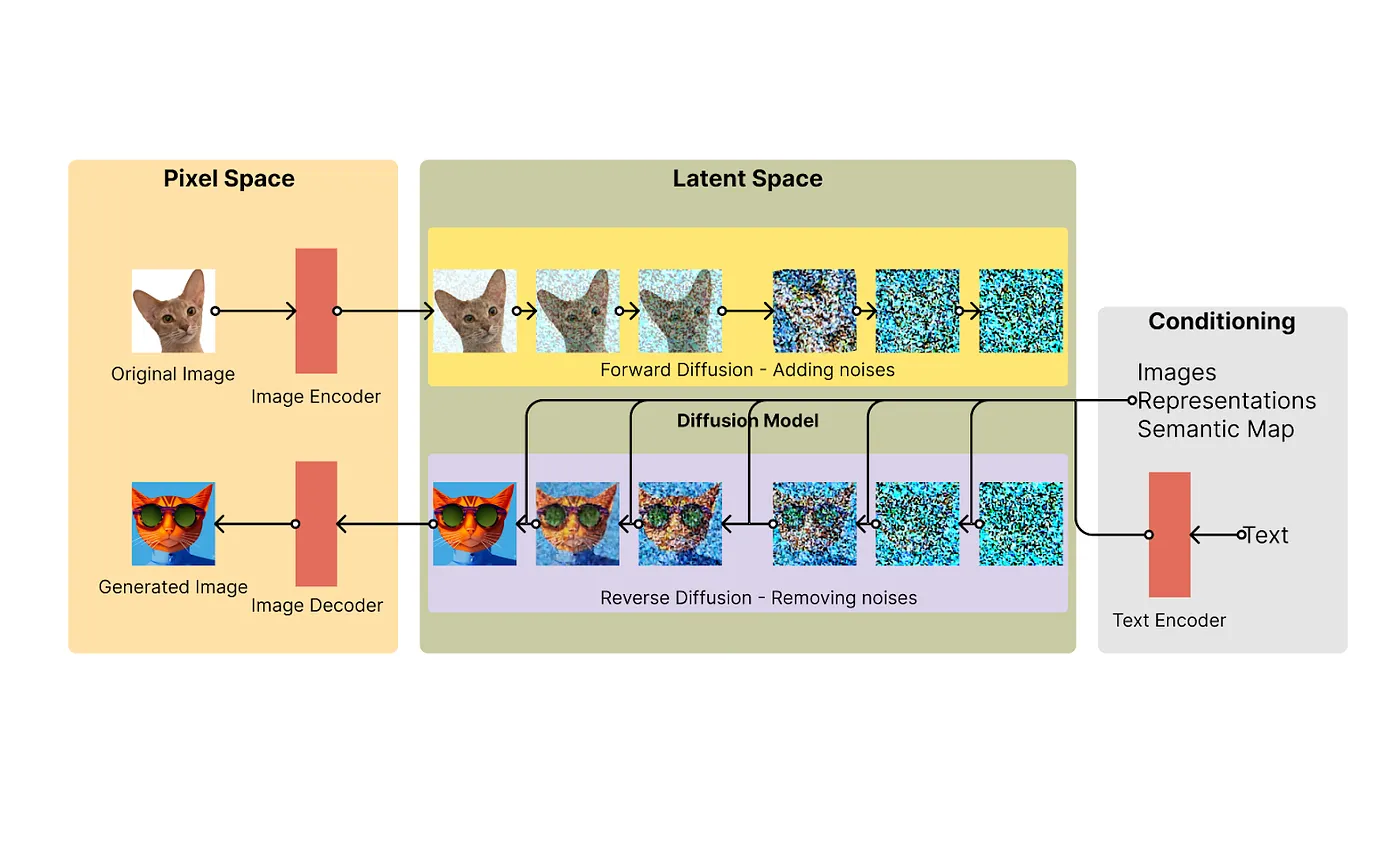 Stable Diffusion의 작동과정, 출처: https://medium.com/@ayushawasthi2409/
Stable Diffusion의 작동과정, 출처: https://medium.com/@ayushawasthi2409/
4-1. 작동 방식
- 순방향 과정(Forward Process)
원본 이미지를 단계별로 조금씩 노이즈를 추가하며 완전히 무작위한 이미지(순백의 노이즈)로 변환. - 역방향 과정(Reverse Process)
노이즈가 가득한 상태에서 점차 노이즈를 제거하며, 조건(prompt)에 맞는 이미지를 생성. - 조건부 생성
텍스트, 이미지, 스타일 등을 조건으로 입력하여 원하는 특징을 갖는 이미지를 생성 가능.
4-2. 장/단점
장점:
- 고품질 이미지 생성 가능 (특히 세부 묘사가 뛰어남)
- GAN보다 학습 안정성이 높음
- 다양한 조건을 붙여 생성 가능 (텍스트, 스타일, 색상 등)
단점:
- 연산량이 많고 생성 속도가 느림
- 다단계 연산 구조로 인해 GPU 메모리 사용량이 높음
- 빠른 샘플링을 위해 추가 최적화 필요
4-3. 활용 분야
- 이미지 생성: Stable Diffusion, DALL·E 2
- 이미지 복원: 오래된 사진 복원, 해상도 업스케일링
- 스타일 변환: 사진을 특정 화풍으로 재구성
- 영상 생성: 동영상 프레임 보간, 짧은 애니메이션 생성
4-4. 디퓨젼(Diffusion)은 스타일 전이, GAN과 무엇이 다를까?
스타일 전이(Style Transfer), GAN, 디퓨전(Diffusion)은 모두 이미지를 변환하거나 생성하는 기술이지만 접근 방식이 다르다.
스타일 전이는 주로 기존 이미지의 내용과 다른 이미지의 스타일을 결합하는 데 초점을 맞춘 기술이다. CNN을 활용해 특징을 추출하고 합성하는 방식이라, 비교적 간단하고 빠르지만 생성의 자유도가 낮다.
예) 사진을 ‘고흐 화풍’으로 변경
GAN은 생성자와 감별자가 경쟁하며 점점 더 정교한 가짜 이미지를 만드는 구조이다. 사실적인 결과를 낼 수 있지만, 학습이 까다롭고 불안정할 수 있다.
예) 이미지 생성, 딥페이크, 데이터 증강
디퓨전은 이미지를 노이즈로 변환했다가 그 노이즈를 단계적으로 제거하며 이미지를 복원하는 방식이다. 학습이 안정적이고 세밀한 묘사가 가능하지만, 계산량이 많고 속도가 느리다.
예) Stable Diffusion, Midjourney 같은 최신 이미지 생성 모델에 사용
| 구분 | 스타일 전이 (Style Transfer) | GAN (Generative Adversarial Networks) | 디퓨전 (Diffusion Models) |
|---|---|---|---|
| 핵심 아이디어 | 한 이미지의 내용(Content)과 다른 이미지의 스타일(Style)을 분리·합성 | 생성자(Generator)와 감별자(Discriminator)의 경쟁으로 점점 더 진짜 같은 데이터 생성 | 이미지를 노이즈로 변환 후, 역으로 노이즈를 제거하며 고품질 이미지 생성 |
| 주요 알고리즘 | CNN 기반 특징 추출 및 스타일 합성 | GAN, DCGAN, StyleGAN 등 | DDPM, Stable Diffusion |
| 장점 | 비교적 간단하고 빠르게 스타일 적용 가능 | 매우 현실적인 결과 생성 가능 | 학습 안정성 높고, 세부 묘사 우수 |
| 단점 | 새로운 구조나 대규모 데이터에 취약 | 학습이 불안정하고 모드 붕괴 문제 발생 가능 | 생성 속도가 느리고, 높은 연산 자원 필요 |
| 대표 활용 | 예술적 이미지 변환, 사진 필터 | 이미지 생성, 딥페이크, 데이터 보강 | 이미지 생성, 복원, 스타일 적용, 영상 생성 |
| 대표 서비스/예시 | Prisma, DeepArt | ThisPersonDoesNotExist, 딥페이크 영상 | Stable Diffusion, DALL·E 2, Midjourney |
참고자료1: https://wikidocs.net/275452
참고자료2: https://brunch.co.kr/@b2439ea8fc654b8/71
