
출처: https://blog.desdelinux.net
1. OpenCV란?
OpenCV(Open Source Computer Vision Library) 는 이미지·영상 처리와 컴퓨터 비전을 위한 오픈소스 라이브러리로 C++로 구현되어 빠르고, Python에선
cv2모듈로 많이 쓴다.
특징
- 풍부한 기본기: 리사이즈, 회전, 색공간 변환, 필터링, 특징점 추출, 윤곽선/에지 검출 등 저수준 처리에 강함.
- 광범위한 I/O: 이미지·동영상·웹캠·네트워크 스트림을 손쉽게 읽고 쓸 수 있음.
- 설치:
pip install opencv-python
2. 이미지처리
2-1. 텍스트 추출(OCR)
아래와 같이 import easyocr를 사용해 poem.png의 텍스트를 추출해봤다.

import easyocr
reader = easyocr.Reader(['ko', 'en'])
result = reader.readtext('poem.png')
for i in result:
print(i[1])
### 출력값: 서시
운동주
죽는 날까지 하늘올 우러러
한 점 부끄럽이 없기름 .
잎새에 이는 바람에도
나는 괴로워있다 .
벌올 노래하는 마음으로
모든 죽어 가능 것올 사랑해야지
그리고 나에게 주어진 길을
걸어가야켓다 .
오늘 밤에도 별이 바람에 스치운다 .위처럼 이미지가 깔끔한 경우엔 조금의 오타를 제외하고는 아주 잘 불러오는 것을 확인 할 수 있었다.
3. MediaPipe
MediaPipe는 구글의 스트리밍 지향 키포인트/세그멘테이션 파이프라인으로 낮은 지연, 모바일 친화, 추적 안정화 필터와 함께 제공된다. OpenCV와 결합해 카메라 입력 → 키포인트 → 시각화/제스처 로직을 빠르게 구현할 수 있다.
3-1. 얼굴 인식(FaceMesh)
- 무엇을 제공하나: 얼굴 바운딩 박스와 핵심 랜드마크(예: 눈·코·입 일부) 및 신뢰도.
- 강점: 실시간 처리, 다양한 조명·포즈에 견고.
- 한계/주의: 마스크/가림/강한 역광, 프레임 드랍에서 검출 누락 가능. 개별 인물 식별(“누구인지”)이 아니라 존재/위치 검출에 초점.

출처: https://ai.google.dev/edge/mediapipe
FacaMesh는 위 사진과 같이 468개 얼굴 랜드마크(일부 3D 정규화 좌표) 제공하여 표정 추정, AR 필터, 뷰티 효과, 시선·고개 방향 추정 등에 활용할 수 있다. Facemesh를 사용한 대표적인 예시로는 TikTok (Effect House), Snapchat (Lenses), SNOW / B612 등이 있다.
3-2. 손 위치 인식 및 추적
- 21개 손 랜드마크와 Handedness(좌/우 손) 제공. 제스처 UI, 사인 인식, 가상 버튼 등에 적합.
- 현장 난제: 모션 블러, 손의 자가 가림, 피부색과 배경 유사, 프레임 속도 저하.
4. 사진 분석
4-1. 사물 인식 및 바운딩 박스 처리
아래와 같이 이미지를 불러와 사물을 인식하고 바운딩 박스를 만들어 줄 수도 있다.

바운딩 박스 좌표값 출력:
objs = root.findall('object')
for obj in objs:
bndbox = obj.find('bndbox')
name = obj.find('name').text
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
print(f'{name}: ({xmin}, {ymin}), ({xmax}, {ymax})')
## aeroplane: (104, 78), (375, 183)
## aeroplane: (133, 88), (197, 123)
## person: (195, 180), (213, 229)
## person: (26, 189), (44, 238)이미지 내 바운딩 박스 시각화:
base_image = image.copy()
objs = root.findall('object')
for obj in objs:
bndbox = obj.find('bndbox')
name = obj.find('name').text
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
cv2.rectangle(base_image, (xmin, ymin), (xmax, ymax), color=(255, 0, 0), thickness=1)
cv2.putText(base_image, name, (xmin, ymin-5), cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.5, color=(255,0,0), thickness=1)
plt.imshow(base_image)
plt.show()
5. 영역 추정 (Region Proposal)
Region Proposal(영역 제안) 은 “객체가 있을 법한 후보 박스”를 대량으로 만드는 단계다.
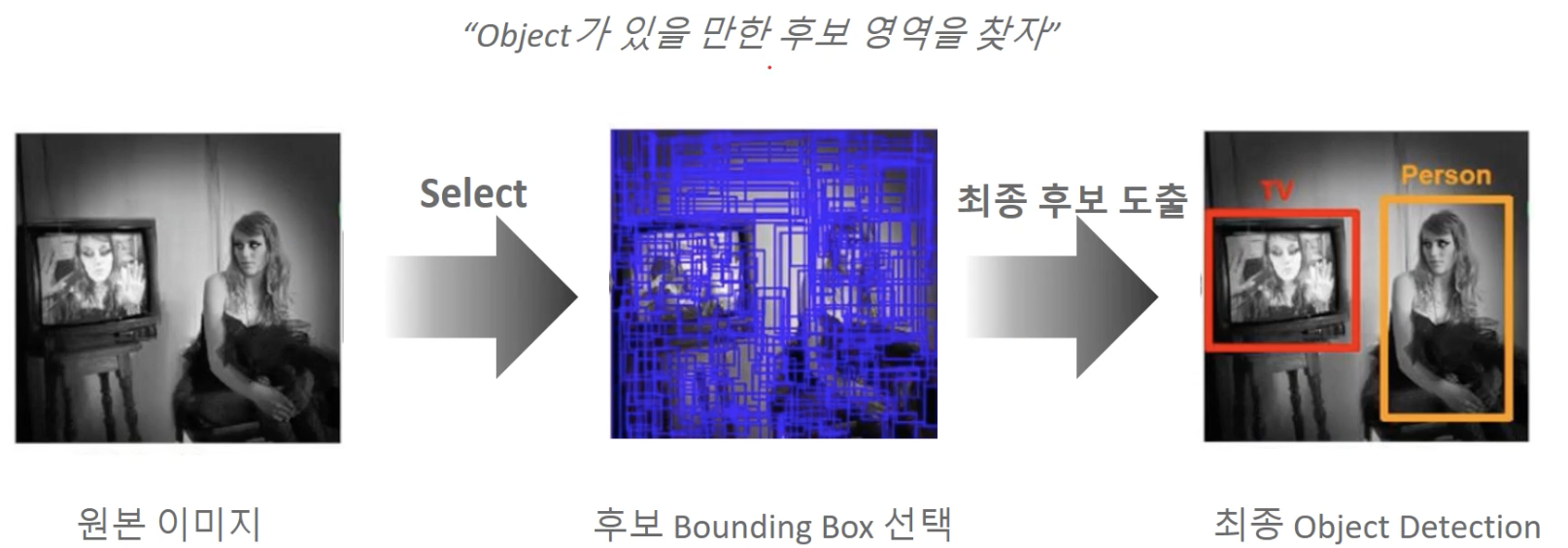
출처: https://donggoolosori.github.io
- Selective Search: 슈퍼픽셀을 색상·텍스처·크기·형태 유사도로 병합하며 수백~수천 개 후보 생성(R-CNN의 고전적 구성).
- 장점: 학습 없이 다양한 객체를 포괄, 작은 데이터로도 실험 가능.
- 단점: 느리고, 후보가 많아 후속 분류기의 비용 증가.
- 언제 유용한가: 딥러닝 없이 프로토타이핑할 때, 또는 커스텀 파이프라인에서 후보 추림 후 클래식 분류기/SVM과 조합할 때.
6. YOLO 이미지 객체 탐색
YOLO(You Only Look Once) 는 이미지를 한 번만 통과시켜 바운딩 박스 + 클래스를 동시에 예측하는 1-단계(One-stage) 객체 검출기다. R-CNN류처럼 후보영역을 따로 뽑지 않아 지연(latency) 이 낮고 실시간성이 강하다. 초기 아이디어는 “검출을 회귀 문제로 통째로 풀자”는 관점에서 출발했다.

출처: https://www.researchgate.net
YOLO(You Only Look Once) 계열은 실시간 객체 검출의 사실상 표준으로 다음과 같은 특징이 있다:
- 장점: 단일 네트워크로 빠른 추론, 경량 모델(nano/small)부터 고정밀(large/xlarge)까지 선택 폭이 넓다.
- 버전 선택: v5/v7는 성숙한 생태계, v8/v9는 검출·분할·포즈 등 다기능과 온보딩 편의성 개선되었다.
