
1. Pandas란?
Pandas는 데이터 분석과 조작에 특화된 라이브러리로, 구조화된 데이터(테이블 형식, 시계열 등)를 처리하는 데 사용된다.
- Series: 1차원 레이블이 있는 배열
- DataFrame: 2차원 테이블 형태로, 여러 데이터 타입의 열을 가질 수 있음. NumPy와 비교해 더 복잡한 데이터 구조를 다루기 용이(Excel, SQL 테이블과 유사)
1-1. num_ser[0] / num_ser.iloc[0] / num_ser.loc[0]
우선 num_ser.loc[0]는 문자열로 찾는 것이라 나머지 두가지와 성격이 조금 다르다. 나는 num_ser[0] , num_ser.iloc[0] 이 두가지를 비교해보고 싶었다. 수업 시간에 예제를 풀며 둘 다 사용해봤는데 어차피 같은 기능이라면 왜 두가지 함수가 존재할까 생각해보다 이리 저리 시도해보니 다른 점을 발견했다. 보기엔 생김새만 약간 다르고 같은 동작을 하는 것 같은데 차이점을 한 번 발견하니 쓰임새가 확실히 다르다.
import pandas as pd
s = pd.Series([10, 20, 30], index=[1, 2, 3])
print(s[0]) # 에러 발생 (인덱스 레이블이 0이 없음)
print(s.iloc[0]) # 10 (첫 번째 위치)
print(s.loc[1]) # 10 (인덱스 레이블이 1인 값)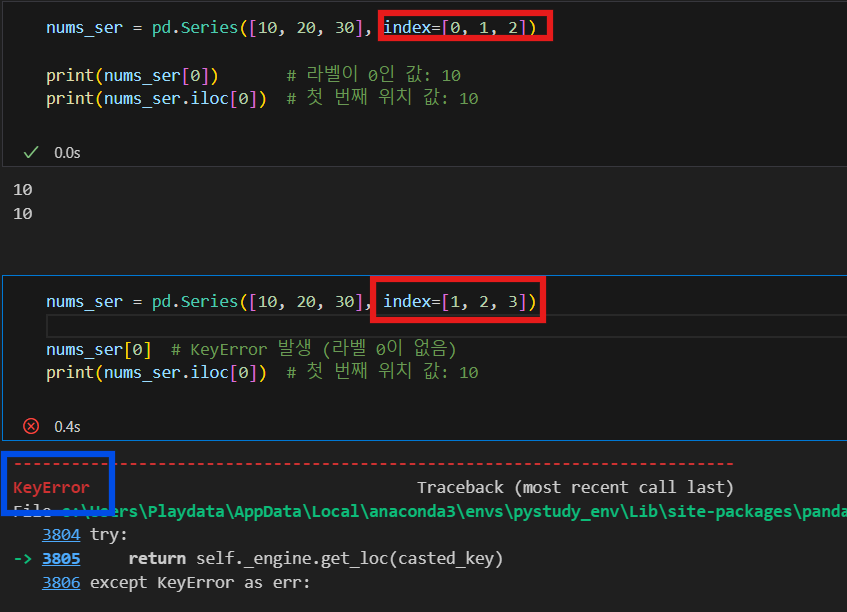
1-2. index(drop=True)
DataFrame의 인덱스를 초기화할 때 사용한다.
df = df.drop_duplicates().reset_index(drop=True)- drop=True: 기존 인덱스를 버리고 새로 0부터 시작하는 인덱스를 부여
- drop=False(기본값): 기존 인덱스를 새 컬럼으로 남겨둠
1-3. 전치행렬 df.T
- 행과 열을 뒤바꾼다. index ↔ columns 교환
- values도 그대로 전치(transpose)된 형태로 바뀜
[예시1]
import pandas as pd
df = pd.DataFrame({"A": [1,2], "B":[3,4]})
print(df)
# A B
# 0 1 3
# 1 2 4
print(df.T)
# 0 1
# A 1 2
# B 3 42. Pandas vs NumPy
2-1. 공통점
- 둘 다 데이터 분석과 연산에 사용되는 핵심 라이브러리
- 내부적으로 Pandas도 NumPy를 기반으로 동작
2-2. 차이점
| 구분 | NumPy | Pandas |
|---|---|---|
| 데이터 구조 | 다차원 배열 (ndarray) | Series, DataFrame |
| 인덱스/라벨 | 없음 (0부터 정수 인덱스) | 있음 (인덱스, 컬럼) |
| 데이터 성격 | 수치 연산 중심 | 테이블, 시계열, 혼합 데이터 |
| 가독성 | 낮음 (인덱스 번호로 접근) | 높음 (컬럼명/인덱스로 접근 가능) |
| 활용 예시 | 행렬 연산, 머신러닝 입력 데이터 | 데이터 분석, 통계 요약, 결측치 처리 |
2-3. 논리 연산 차이
- Python 기본 연산자 and, or는 스칼라(Boolean 하나)에만 사용 가능
- Pandas에서는 &, | 연산자를 사용해야 Series 간 element-wise 연산 가능
[예시1]
import pandas as pd
s = pd.Series([True, False, True])
t = pd.Series([False, False, True])
print(s & t)
# 0 False
# 1 False
# 2 True
기록은 기억을 지배한다.