이미지 출처: https://ceralytics.com
1. 'Machine Learning' 이란?
주어진 데이터를 스스로 학습하여 수치적인 특징을 찾고, 다른 데이터가 주어졌을 때 결과가 되는 데이터를 예측할 수 있는 인공지능 모델을 만드는 것. 통계적 접근법, 경사하강법을 통해 정답과 예측한 값의 차이를 점차 줄여나가는 방식으로 학습하는 것이 특징.
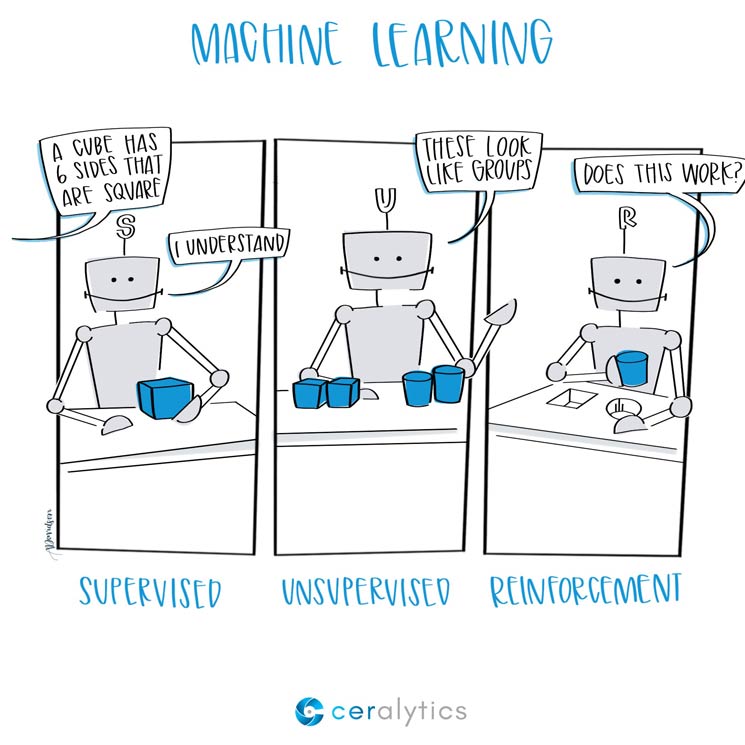
2. Machine Learning 의 종류
- 지도학습 : 입력과 타겟(정답) 데이터 전달하여 모델을 훈련 -> 새로운 데이터 예측
- 비지도학습 : 타겟(정답) 데이터 없음 -> 입력 데이터의 특징 찾는 데에 사용
- 강화학습 : 인공지능이 결과로 도출하는 값에 대해 가점 또는 감점을 주어 학습시키는 방식
2-1. Supervised Learning Workflow
지도 학습은 정답을 학습하고 예측하는 것
- 데이터 로드 (Data Load)
- 데이터 탐색 및 전처리 (EDA & Preprocessing)
- 훈련/테스트 데이터 분리 (Train-Test Split)
- 데이터 스케일링 (Scaling, Optional)
- 모델 학습 (Training - fit(X_train, y_train))
- 모델 평가 (Scoring - score() or Metrics)
-> F1-score, RMSE 등 수치적 평가 가능 - 모델 튜닝 및 개선 (Hyperparameter Tuning, Feature Engineering)
-> DecisionTreeL: max_depth, SVM: c - 예측 수행 (Predict - predict(X_test))
2-2. Unsupervised Learning Workflow
비지도 학습의 핵심은 패턴 발견으로 데이터의 숨겨진 구조를 찾는 것
- 데이터 로드 (Data Load)
- 데이터 탐색 및 전처리 (EDA & Preprocessing)
- 데이터 스케일링(Scaling, 정규화/표준화 필수)
- 모델 학습 (Training = fit(X))
- 모델 평가 및 활용(Evaluation - Silhouette Score 등)
- 모델 튜닝 및 개선 (Hyperparameter Tuning)
-> K-Means: 클러스터 개수(K) 조정, PCA: 주성분 개수 - 예측 수행
-> K-Means: 새로운 데이터가 어느 클러스터에 속하는지 예측, PCA: 차원 축소된 공간에서 변환된 데이터 제공
3. 오늘의 궁금증
3-1. 전처리(preprocessing)란?
모델이 원하는 형태로 데이터를 제공하기 위한 과정
3-2. 정규화(Normalization)와 표준화(Standardization)
정규화와 표준화: 특성(Feature) 간의 크기 차이 조정
-
정규화와 표준화가 필요한 이유:
1) 거리 기반 알고리즘의 성능 향상(KNN, SVM, K-Means, PCA 등)
머신러닝 모델은 숫자의 크기에 민감하여 한 특성이 0~1 사이의 값을 가지는데, 다른 특성이 1~1000 사이의 값을 가진다면 값이 큰 특성이 모델의 예측에 더 큰 영향을 주어 스케일이 더 큰 특성이 더 중요하게 여겨짐
2) 경사하강법(Gradient Descent) 기반의 모델 속도 개선(선형 회귀, 로지스틱 회귀, 신경망), 특성마다 값의 범위가 다르면 최적의 가중치로 수렴하기까지 더 많은 시간이 걸릴 수 있습니다. 쉽게 말해 학습 속도 느려짐.
-
정규화 또는 표준화가 필요한 모델:
1) 꼭 필요한 모델
거리 기반 알고리즘: KNN, K-Means, SVM
경사하강법 기반 알고리즘: 선형 회귀, 로지스틱 회귀
2) 덜 필요하거나 불필요한 모델
트리 기반 알고리즘: 결정 트리, 랜덤 포레스트, XGBoost
트리 모델은 데이터 스케일에 영향을 받지 않기 때문.
-
정규화 vs 표준화 비교
| 방법 | 계산 방식 | 값의 범위 | 사용 예시 |
|---|---|---|---|
| 정규화 (Min-Max Scaling) | (값 - 최소값) / (최대값 - 최소값) | 0 ~ 1 | KNN, K-Means, Neural Network |
| 표준화 (Standardization) | (값 - 평균) / 표준편차 | 평균 0, 표준편차 1 | SVM, 선형 회귀, PCA |
1) 거리 기반 알고리즘에서는 둘 중 하나를 적용해야 하지만, 어떤 걸 선택할지는 데이터 특성에 따라 다름
2) 정규분포를 띄는 경우 → 표준화, 그렇지 않다면 → 정규화를 적용
3-3. ML의 2차원 배열, Pandas가 아닌 Numpy를 사용하는 이유?
-
Pandas:
Pandas는 고수준 데이터 분석을 위해 만들어진 라이브러리로, 주로 DataFrame과 Series 구조를 사용해서 데이터를 다루며, 다양한 라벨링, 데이터 전처리 및 필터링 기능을 제공한다. 자동으로 데이터의 인덱스나 컬럼명을 관리하고, 데이터 형식이 다양할 수 있어 유연한 처리가 가능하지만, 머신러닝 모델에서 효율적인 수치 연산을 요구하는데는 부적합한 경우가 많다.
-> 추가적인 관리가 가능하지만 이로 인해 메모리 사용이 많고 성능 떨어짐 -
Numpy:
Numpy는 고성능 수치 연산을 위해 설계된 라이브러리로, 배열 단위의 연산을 매우 빠르게 수행할 수 있도록 최적화되어 있어 배열 구조(Array)와 벡터화 연산을 사용하여 대규모 데이터의 수학적 계산을 효율적으로 처리할 수 있다. 머신러닝 알고리즘은 대부분 행렬 연산이나 벡터 연산을 사용하기 때문에, Numpy 배열은 이러한 연산에 적합하고, 더 나은 성능을 제공한다.
-> C언어로 구현되어 있어 속도 빠르고 메모리 사용 효율적, 단순한 데이터 타입을 다루기 때문에 배열 크기가 커질수록 성능 차이가 두드러짐 -
결론:
Pandas는 데이터 탐색(EDA)과 분석에 강점을 가진 반면,
Numpy는 수치 연산과 머신러닝 알고리즘의 요구사항에 맞춰 최적화되어 있음.
