
복잡해진 LLM 워크플로우, 그리고 LangGraph
처음엔 간단했다. 프롬프트 한 줄 던지고 답을 받으면 되는 줄 알았다.
하지만 실전은 달랐다. 검색해서 문서를 끌고 오고(RAG), 부정확한 문서는 거르고, 부족하면 다시 찾고, 유저 맥락은 기억하고, 도중에 실패하면 재시도하고, 때론 툴(API)도 호출해야 했다. 이 흐름을 코드로 짜다 보니 금방 이런 생각이 든다.
“이건 더 이상 직선(Chain)이 아니다. 분기, 반복, 상태가 있는 흐름(Graph)이다.”
여기서 등장하는 게 LangGraph다. 이름 그대로 그래프(노드/엣지)로 LLM 애플리케이션의 흐름을 설계한다.
LangChain이 블록(모델·프롬프트·툴)을 잘 조립하게 해주는 공구상자라면, LangGraph는 그 블록들이 언제, 어떤 조건으로, 어떤 상태를 들고 움직일지를 정밀하게 오케스트레이션하는 조감도 + 신호등에 가깝다.
그래서 LangGraph가 뭐냐면..
LangChain 에서 개발한 LangGraph는 복잡한 생성형 AI 에이전트 워크플로를 구축, 배포 및 관리하도록 설계된 오픈소스 AI 에이전트 프레임워크입니다. 사용자가 확장 가능하고 효율적인 방식으로 대규모 언어 모델 (LLM)을 생성, 실행 및 최적화할 수 있도록 지원하는 도구와 라이브러리 세트를 제공합니다. LangGraph는 그래프 기반 아키텍처의 강력한 기능을 활용하여 AI 에이전트 워크플로 의 다양한 구성 요소 간의 복잡한 관계를 모델링하고 관리합니다.
LangGraph의 특징:
- 기존 LangChain은 체인(Chain) 기반으로 직선적인 흐름을 다루기 좋았지만, 복잡한 조건 분기나 상태 기반 워크플로우에는 한계가 있었고,
- LangGraph는 이를 보완해, 노드(Node)와 엣지(Edge) 개념을 이용해 LLM 파이프라인을 시각적으로 구조화할 수 있도록 했다.
- 즉, 단순한 "프롬프트 → 응답"을 넘어서, 상태 관리, 분기, 반복 루프가 필요한 복잡한 시스템을 다루기 쉽게 만든다.
LangChain vs LangGraph, 어떻게 다를까?
- LangChain은 본래 “일반적인 LLM 앱 개발 프레임워크”이고, 에이전트/멀티에이전트는 기능 중 일부임.
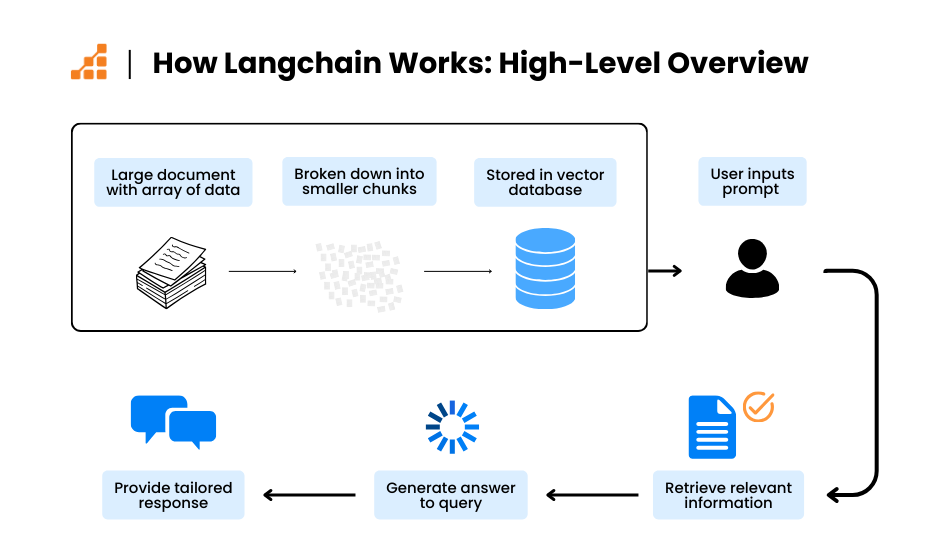
이미지 출처: https://www.scalablepath.com
- LangGraph는 처음부터 멀티에이전트 워크플로우 설계를 염두에 두고 만들어져서, 상태 제어, 반복(루프), 분기 처리, 실패 시 재실행 같은 기능을 더 안정적으로 제공함.
이미지 출처: https://medium.com/@kbdhunga
| 관점 | LangChain | LangGraph |
|---|---|---|
| 기본 철학 | 체인(직선 흐름)로 컴포넌트 조립 | 그래프(분기/루프/상태)로 워크플로우 설계 |
| 주력 기능 | 모델·프롬프트·툴 블록화/재사용 | 상태 기반 오케스트레이션, 조건 분기, 반복 |
| 상태 관리 | 보통 암묵적/외부 저장 | 명시적 State 스키마 + 체크포인트 |
| 복잡도 대응 | 복잡해질수록 체인 중첩/콜백 지옥 | 노드/엣지로 흐름 시각화, 운영/디버깅 용이 |
| 실패 처리 | 호출 단위 재시도 위주 | 노드/경로 단위 재시도·대체 경로 |
| 언제 쓰나 | 간단한 파이프라인, 빠른 프로토타이핑 | 실서비스급 RAG/에이전트/멀티스텝 플로우 |
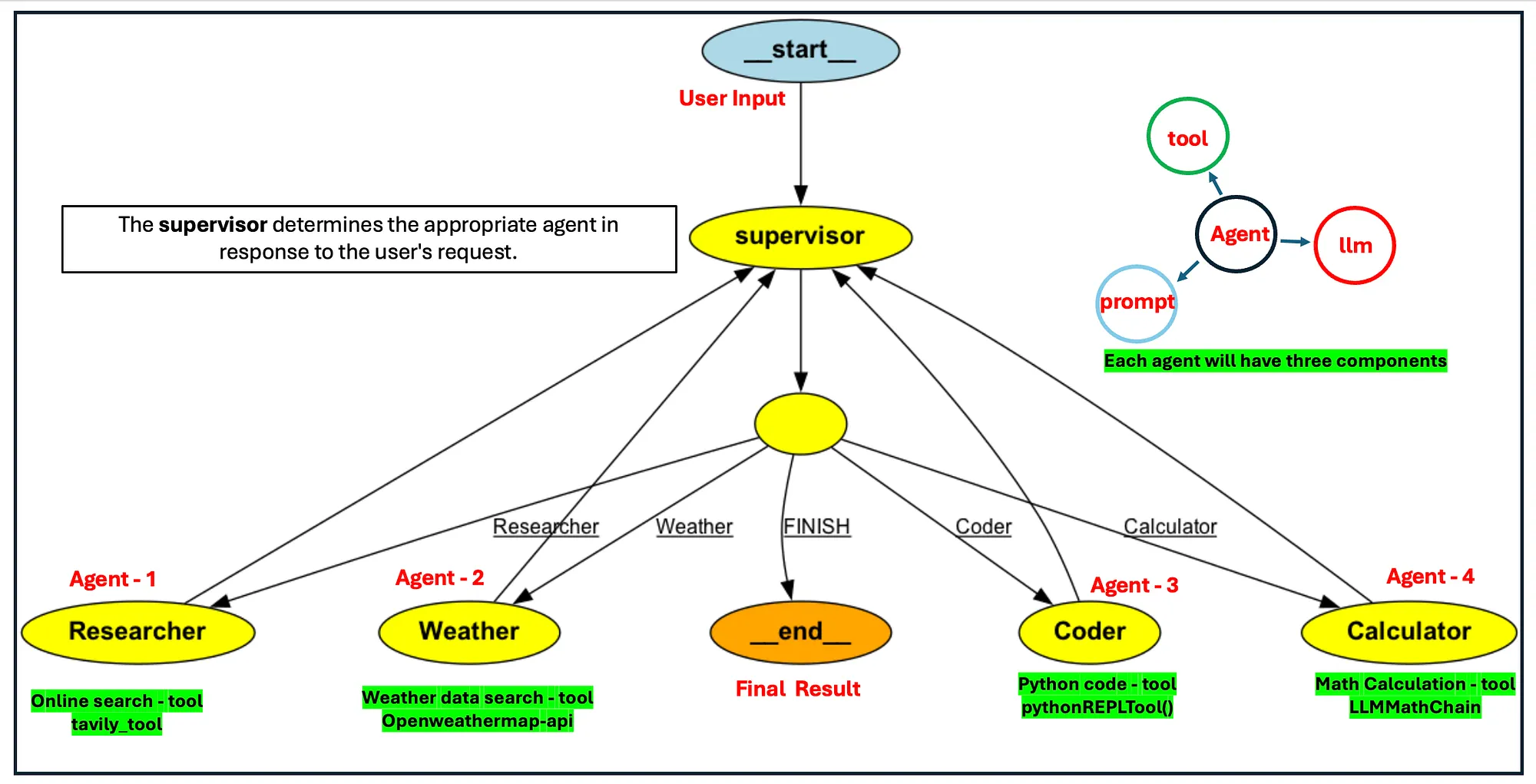
LangGraph는 Multi-Agent 특화 프레임워크
LangGraph는 단일 에이전트의 한계를 뛰어넘는 다중 에이전트 시스템을 구축할 수 있게 해줍니다. 각 에이전트는 특정 목표를 향해 자율적으로 행동하며, 다른 에이전트들과 협업하여 복잡한 문제를 해결합니다. 이러한 에이전트는 복잡한 의사결정을 위한 사전 정보, 작업 단계를 단축하기 위해 도움이 되는 미리 정의된 도구들 등에 접근하여 활용할지 스스로 결정할 수 있습니다.

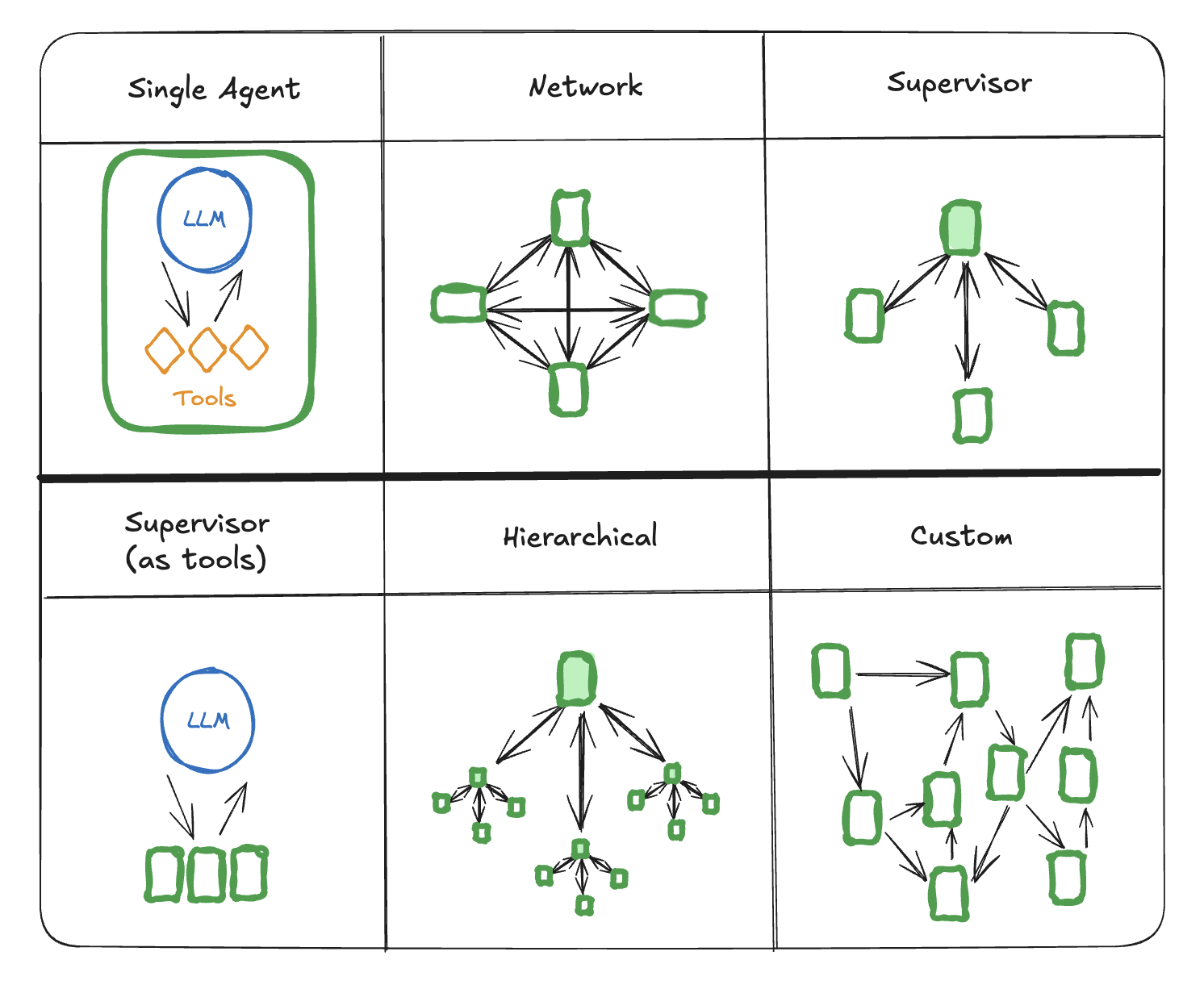
출처: https://modulabs.co.kr
구성 요소 및 예시 살펴보기
LangGraph는 기본적으로 에이전트 워크플로를 그래프로 모델링 하는데, 세 가지 핵심 구성 요소를 사용하여 에이전트의 동작을 정의한다.
State: 애플리케이션의 현재 스냅샷을 나타내는 공유 데이터 구조. 어떤 데이터 유형이든 가능하지만 일반적으로 공유 상태 스키마를 사용하여 정의된다.Nodes: 에이전트의 로직을 인코딩하는 함수. 현재 상태를 입력으로 받고, 계산이나 부수 효과를 수행한 후 업데이트된 상태를 반환한다.Edges: Node현재 상태에 따라 다음에 실행할 함수를 결정하는 함수. 조건 분기 또는 고정 전환일 수 있다.
예를 들어 “질문 → 검색 → 문서평가 → 생성 → (부족하면) 다시 검색”이란 루프를 만든다고 해보자.
예시 코드:
from typing import TypedDict, List, Optional
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
class State(TypedDict):
question: str
docs: List[str]
answer: Optional[str]
retries: int
def retrieve(state: State) -> State:
# 검색 로직 (예: 벡터DB)
return {**state, "docs": search(state["question"])}
def grade_docs(state: State) -> State:
# 품질 낮은 문서 제거
good = filter_docs(state["docs"])
return {**state, "docs": good}
def generate(state: State) -> State:
# LLM으로 초안 생성
return {**state, "answer": llm_write(state["question"], state["docs"])}
def decide_more(state: State) -> str:
# 충분하면 END, 아니면 START로 되감기
if is_good_enough(state["answer"]) or state["retries"] >= 2:
return END
return "retrieve" # 다시 검색
g = StateGraph(State)
g.add_node("retrieve", retrieve)
g.add_node("grade_docs", grade_docs)
g.add_node("generate", generate)
g.add_node("decide_more", decide_more)
g.add_edge(START, "retrieve")
g.add_edge("retrieve", "grade_docs")
g.add_edge("grade_docs", "generate")
g.add_edge("generate", "decide_more")
# 조건 분기(END or retrieve로 루프)는 decide_more가 반환
app = g.compile(checkpointer=MemorySaver()) # 대화/상태 저장
result = app.invoke({"question": "파이썬 GIL을 설명해줘", "docs": [], "answer": None, "retries": 0})위 코드에서 상태, 노드, 엣지는 다음과 같다.
- 상태(State): 질문, 후보 문서 목록, 현재까지의 답변, 재시도 횟수 등
- 노드(Nodes):
retrieve,grade_docs,generate,decide_more - 엣지(Edges):
START → retrieve → grade_docs → generate → decide_more → (END 또는 retrieve로 루프)
간단히 말해서, 노드는 작업을 수행하고, 에지는 다음에 무엇을 할지 알려준다.
핵심 활용 분야
LangGraph의 강점은 상태 기반(Stateful) LLM 오케스트레이션이다.
이러한 강점을 활용한 예시는 다음과 같다:
- RAG(Retrieval-Augmented Generation) 시스템
- 검색 → 후보 문서 평가 → 최종 응답 생성 과정을 노드 단위로 구성
- 에러 핸들링, 재시도 로직을 그래프에서 쉽게 정의 가능
- 에이전트 시스템(Agentic Workflow)
- 예: 사용자가 “이번 주 날씨 기반으로 여행 추천” 요청
- 노드1: API 호출(날씨 데이터)
- 노드2: LLM 분석
- 노드3: 여행 추천 응답 생성
- 각 노드가 독립적이면서 연결되어 있어, 유지보수와 확장이 용이
- 대화형 챗봇
- 사용자 입력에 따라 분기 처리(예: 고객지원, 기술상담, 피드백 루트 구분)
- 대화 맥락(Context)을 상태(State)로 관리 → 기억력 있는 챗봇 구현
다시 한 번 정리해보는 LangGraph의 장점!
- 복잡한 워크플로우에 강함
- 단순 체인 모델로는 힘들었던 “조건 분기/루프/상태 관리”가 가능
- 실무에서 쓰이는 복잡한 LLM 애플리케이션에 적합
- 안정성과 가시성
- 그래프 구조라서 흐름을 시각적으로 이해하기 쉬움
- 디버깅, 성능 최적화, 장애 처리 로직을 추가하기 간편
- 생태계 확장성
- LangChain 기반이라, 기존의 모든 LangChain 리소스를 그대로 활용 가능
- LLM 서비스 개발에서 표준 워크플로우 도구로 자리잡아가는 중
참고자료
LangGraph GitHub: https://langchain-ai.github.io
모두의 연구소: https://modulabs.co.kr
IBM: https://www.ibm.com
AWS: (https://aws.amazon.com
