"MUSE"는 이전 포스팅(3차 프로젝트)에서 설명하였듯, LLM(대형 언어 모델)을 기반으로 국립중앙박물관의 유물을 데이터를 학습한 AI 도슨트 챗봇입니다. 3월에 3차 프로젝트로 서비스를 개발하였고, 이번 4차 프로젝트에선 프론트엔드+도커+AWS를 통해 배포의 과정을 진행했습니다.
프론트엔드 개발과 배포 진행 과정에 대한 포스팅에 앞서, 아래 이미지를 클릭하시면 결과물을 확인 하실 수 있으니 한 번씩 살펴봐 주셨으면 좋겠습니다. 모든 피드백 환영입니다!

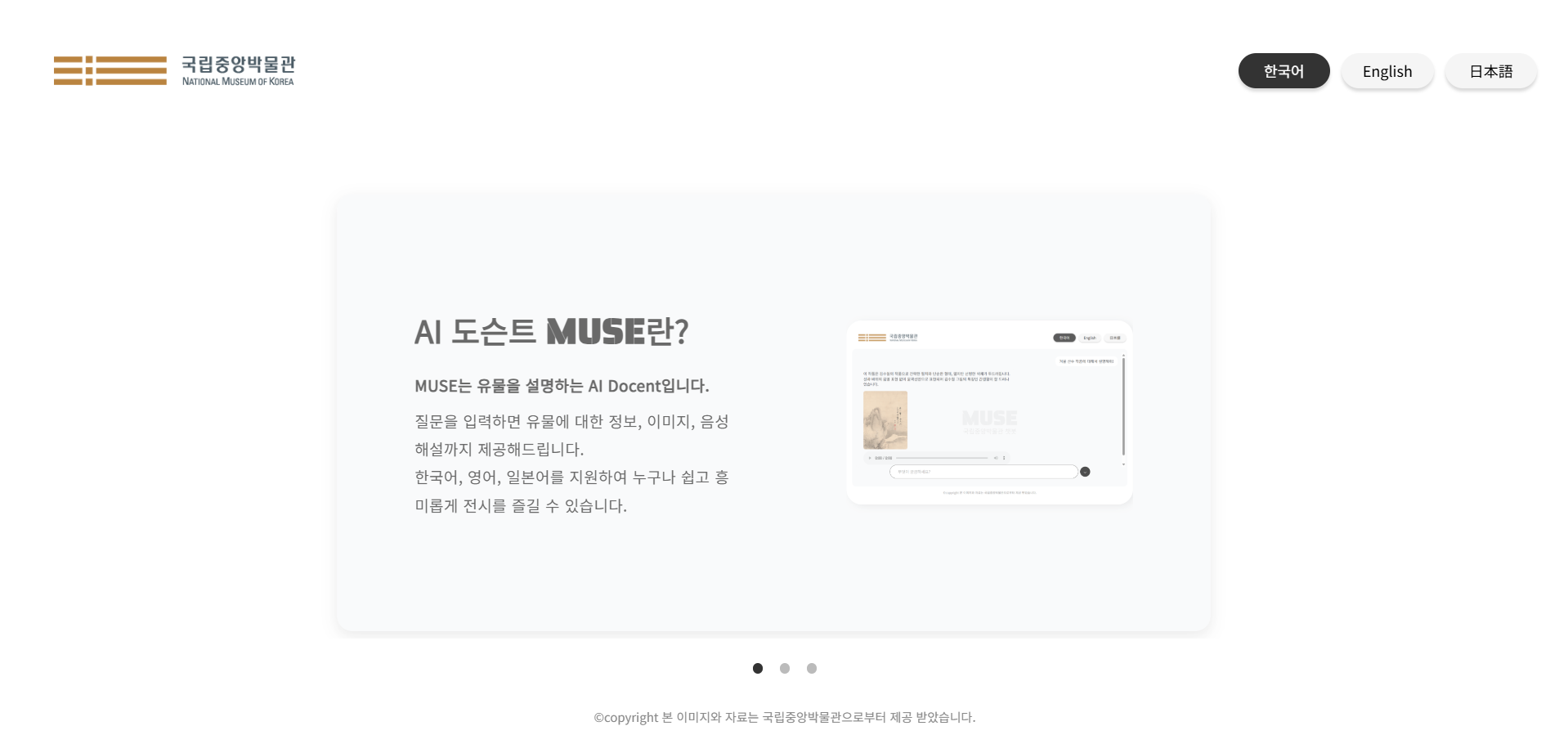
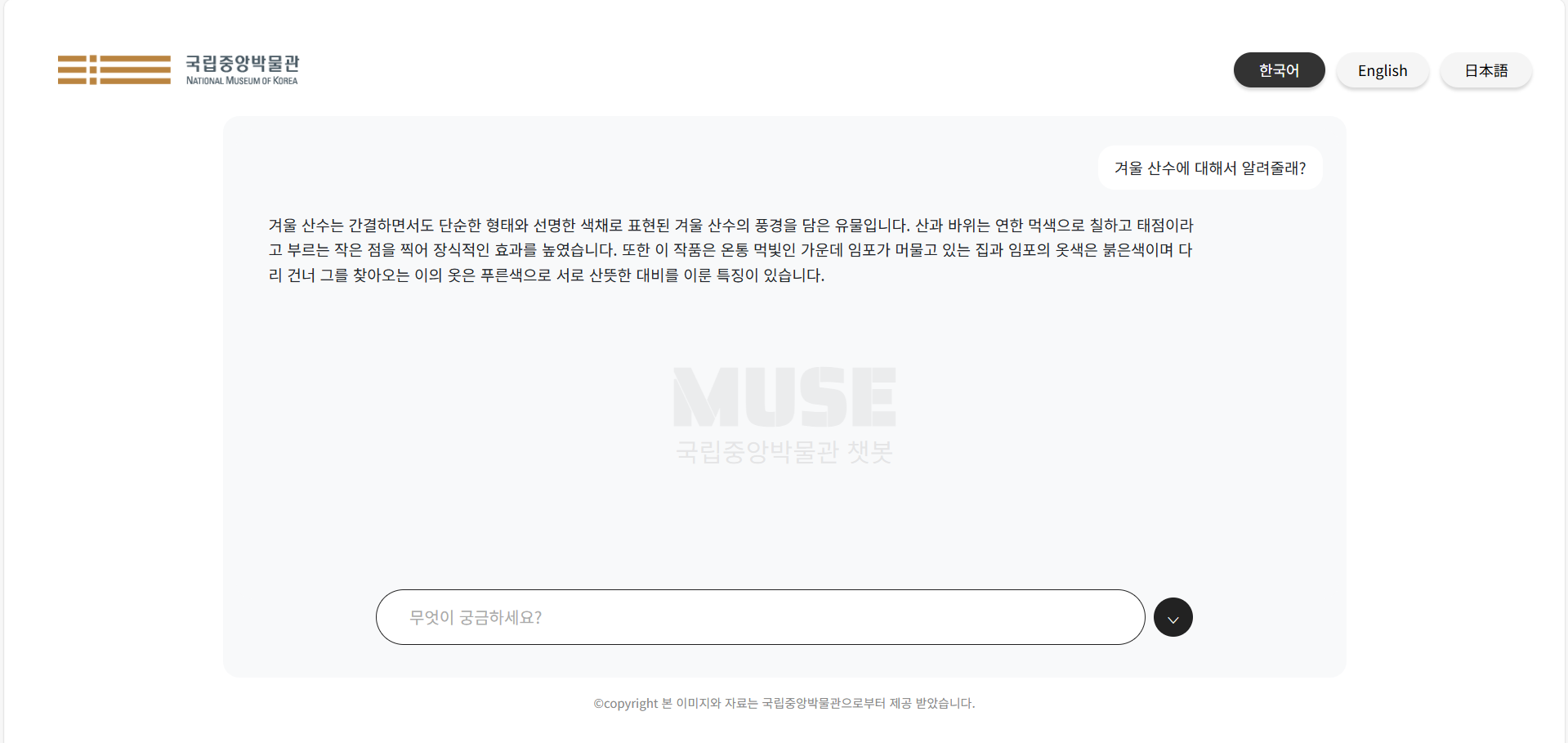
모델 개발 이후 ~ 배포까지
MUSE는 Django 기반 웹 서버를 FastAPI + Uvicorn으로 서버를 구성하고, Nginx를 리버스 프록시/정적 파일 처리용으로 연결한 뒤 Docker로 컨테이너화하여 AWS EC2에서 배포하였습니다. 순서는 아래와 같이 일정을 나누어 진행했습니다:
1. 로컬 개발
- 주요 기능 정리 및 화면 설계
- Django 프로젝트 생성 및 프론트엔드 구현 (HTML/CSS/JS)
- 챗봇 페이지 구축 및 로컬 테스트 (
python manage.py runserver)
2. AI 모델 서버 배포
- RunPod GPU 인스턴스 생성 (RTX 4090 / A100)
- FastAPI + Uvicorn 서버 실행 (
uvicorn main:app --host 0.0.0.0 --port 8002)
3. Django ↔ FastAPI 연동
Django views.py에서 RunPod API 호출 로직 작성- 로컬 서버에서 챗봇 페이지 연동 테스트
4. 컨테이너화
Dockerfile작성docker-compose.yml작성 (Django + Nginx)- Nginx 리버스 프록시 및 정적 파일 서빙 설정
5. 클라우드 배포
- AWS EC2 인스턴스 생성 (Ubuntu 22.04)
- Docker & Docker Compose
docker-compose up -d실행 → 서비스 실행
느낀점 및 후기
3, 4차 단위는 따로 비용이 지원되지 않았기 때문에, AWS와 RunPod 비용 과다를 우려하여 배포한 뒤 정상 작동 유무만 영상으로 확인하고 바로 내렸어야 했는데, 배포의 과정이 예상보다 힘든 시간이었어서 배포를 잠시동안밖에 할 수 없었던게 아쉽긴 했습니다만 그래도 즐거운 경험이었습니다.
또한, GPU 환경에서 배포를 하기 위해 RunPod을 사용하다보니 중간중간 런팟의 연결이 끊길 때마다 팟을 재생성해서 재배포하는 과정이 반복되었는데 이 과정에선 리소스의 중요성을 크게 느꼈습니다.
이렇게 3, 4차 프로젝트를 통해 AI 서비스 개발을 처음부터 끝까지 진행해봤는데요, 이 과정에서 가장 어려웠던 것은 의외로(?) 서류 작성이었습니다.

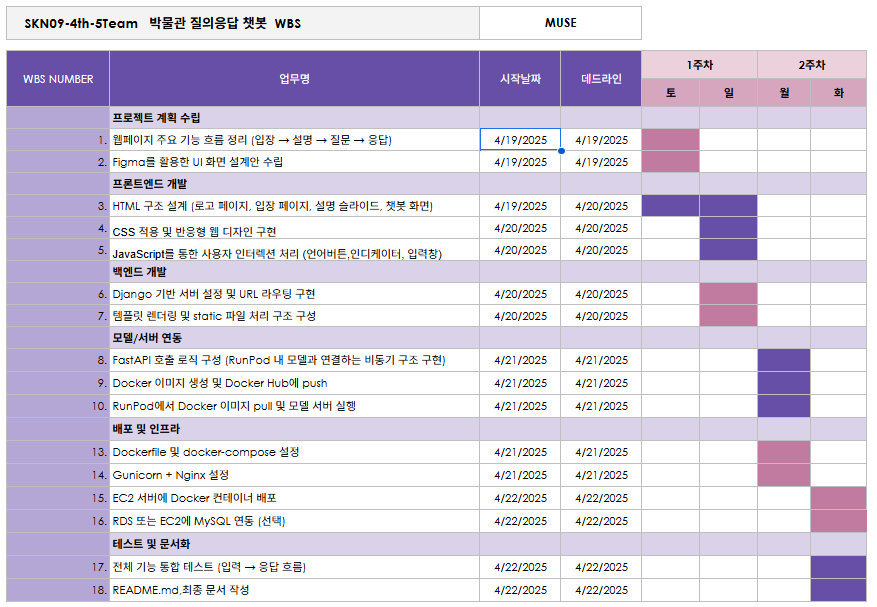
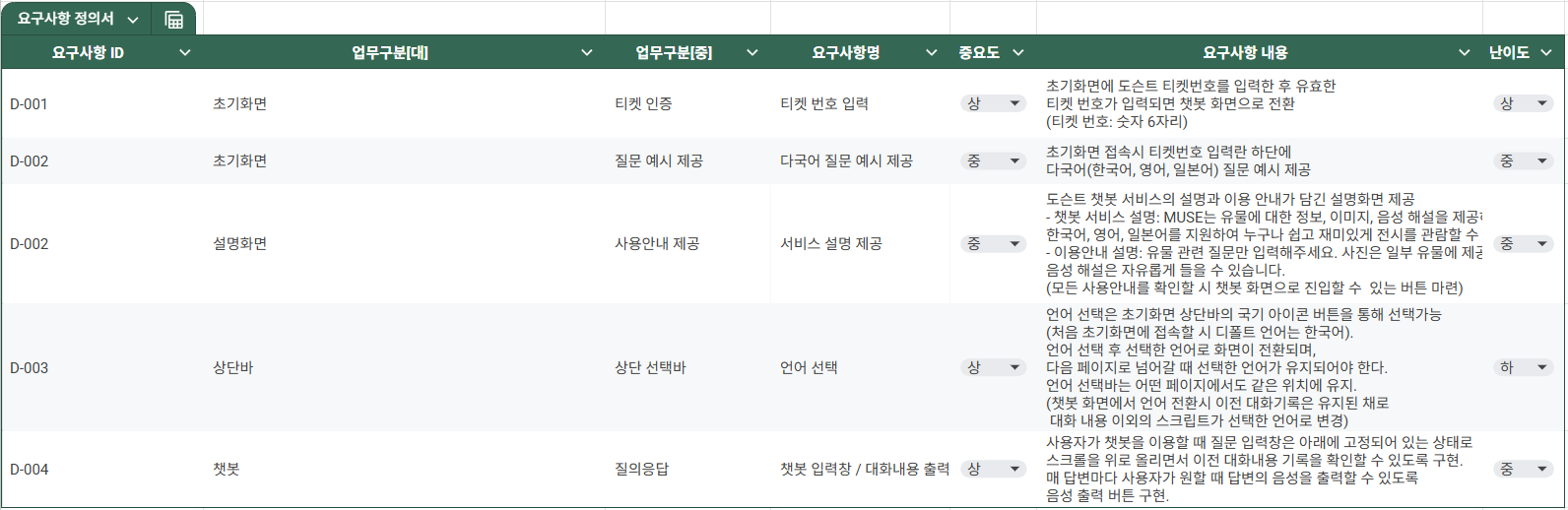 각 단계별로 작성해야하는 산출물을 강사님께 검사 받으며 몇번이고 리젝을 당하면서, 결국 일을 할 때에는 사람 간의 소통이 중요하고 회사에서의 소통은 서류를 통해 이뤄진다는 것 역시 배울 수 있었던 프로젝트였습니다.
각 단계별로 작성해야하는 산출물을 강사님께 검사 받으며 몇번이고 리젝을 당하면서, 결국 일을 할 때에는 사람 간의 소통이 중요하고 회사에서의 소통은 서류를 통해 이뤄진다는 것 역시 배울 수 있었던 프로젝트였습니다.
