1. 손실함수 (Loss Function)
1-1. 손실함수란?
모델의 예측이 얼마나 틀렸는지를 숫자로 평가하는 기준으로 학습의 목표는 손실을 작게 만드는 방향으로 파라미터(가중치)를 조정하는 것이다. 손실함수 선택은 “문제 유형(회귀/분류)·데이터 특성(이상치, 불균형)”에 따라 달라진다.
- 회귀 문제(Regression): 평균 제곱 오차(MSE), 평균 절대 오차(MAE), Huber 손실(Huber Loss)
- 분류 문제(Classification): 교차 엔트로피 손실(CEE), 음성 로그 가능도(NLL, Negative Log Likelihood), Hinge Loss(SVM)
- 강화 학습(Reinforcement Learning): 정책 그래디언트 손실(Policy Gradient Loss), Huber 손실(Huber Loss)
1-2. 평균제곱오차(MSE)
- 언제 쓰나: 회귀(연속값 예측).
- 특징: 오차를 제곱하므로 큰 오차(이상치)에 매우 민감. 잘 맞추면 빠르게 줄어드는 대신, 몇 개의 큰 이상치가 전체를 지배할 수 있다.
- 타깃 값의 스케일 표준화(예: 평균 0, 표준편차 1)로 학습 안정성↑.
1-3. 평균절대오차(MAE)
- 언제 쓰나: 회귀. 이상치에 강함.
- 특징: 중앙값 예측과 친함(중앙값 회귀 직관). 다만 경사(기울기)가 균일해서 미세한 조정 속도는 MSE보다 느릴 수 있다.
- 평균적 오차 크기를 보고 싶을 때 리포팅 지표로도 자주 씀(MAE=“평균적으로 몇 만큼 틀렸나”).
1-4. 휴버손실(Huber)
- 언제 쓰나: 회귀. MSE(작은 오차 구간) + MAE(큰 오차 구간) 의 장점 결합.
- 특징: 작은 오차에선 부드럽고 빠르게 수렴, 큰 오차에선 이상치 영향 완화.
- 전형적으로 이상치가 조금 있지만 완전히 무시할 수 없을 때 기본값 같은 선택.
1-5. 교차엔트로피오차(Cross-Entropy)
- 언제 쓰나: 분류.
- 이진/다중라벨: 시그모이드 + Binary Cross-Entropy
- 다중클래스(배타적): 소프트맥스 + Categorical Cross-Entropy
- 특징: 확률 예측의 “정답 라벨에 쏠린 정도”를 직접 벌점. 틀리면서도 확신(고확률) 한 예측을 강하게 처벌 → 빠르고 안정적으로 학습됨.
- 라벨 스무딩(너무 과신하는 확률 분포를 완화)
- 클래스 불균형엔 가중치·오버샘플링·Focal Loss 검토
- “출력층-손실함수 짝”을 틀리면 성능이 크게 떨어짐.
1-6. 미니배치 학습(Mini-batch)
미니배치 학습(Mini-batch Learning)은 전체 데이터셋이 아닌 일부 데이터를 무작위로 선택하여 학습하는 방법이다.
- 전체 데이터(Full-batch)는 느리고, 1개 샘플(SGD)보다 안정적.
수십~수백 개 묶음으로 손실과 기울기를 계산하면:
- GPU 벡터화 효율↑,
- 적당한 노이즈가 생겨 지역 최적/안장점에서 빠져나오기 쉬움,
- 메모리/속도/안정성의 현실적 균형. - 배치 크기 가이드:
- 작은 배치: 일반화에 유리한 경우 많음(노이즈 학습).
- 큰 배치: 속도 좋고 안정적이나 과신·일반화 저하 가능 → 학습률 스케일링, 워밍업, 정규화로 보완.
- 주의: 셔플 필수, 배치 정규화(BN)와의 상호작용(너무 작은 배치면 통계 불안정).
2. 수치미분 (Numerical Differentiation)
수치 미분(Numerical Differentiation)은 함수의 변화량을 근사적으로 구하는 방법이다. 실제 미분값을 구하는 것이 어렵거나 불가능한 경우 사용된다.
2-1. 수치미분의 한계
- 느림: 파라미터 수만큼 모델을 반복 호출해야 해서 대규모 신경망엔 사실상 불가.
- 민감함: “얼마나 조금 바꿀지(스텝)”가 너무 작으면 반올림 오차, 너무 크면 근사 오차.
- 비매끄러움/노이즈: ReLU 경계, 드롭아웃, 데이터 샘플링에 따라 값이 튀어 정확한 기울기 추정 실패.
- 자동미분(autograd)이 낸 기울기가 맞는지 스팟 체크할 때, 아주 소수의 파라미터만 대상으로 사용.
2-2. 편미분과 기울기벡터
- 편미분: “특정 변수 하나만 살짝 바꿨을 때 손실이 어떻게 변하나”.
- 기울기벡터(그라디언트): 모든 변수에 대한 편미분을 모아 만든 변화 민감도 지도.
- 길이는 “얼마나 민감한지”, 방향은 “손실이 가장 빨리 커지는 쪽”을 의미.
- 그래서 경사하강은 이 벡터의 반대 방향으로 움직인다.
- 출력이 벡터인 모델(예: 멀티태스크)의 “모든 출력에 대한 민감도”를 모으면 야코비안이라 부른다.
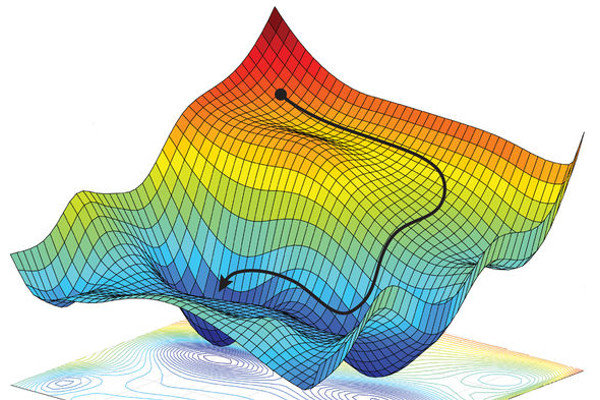
3. 기울기와 최적화 (Optimization)
출처: https://datamapu.com
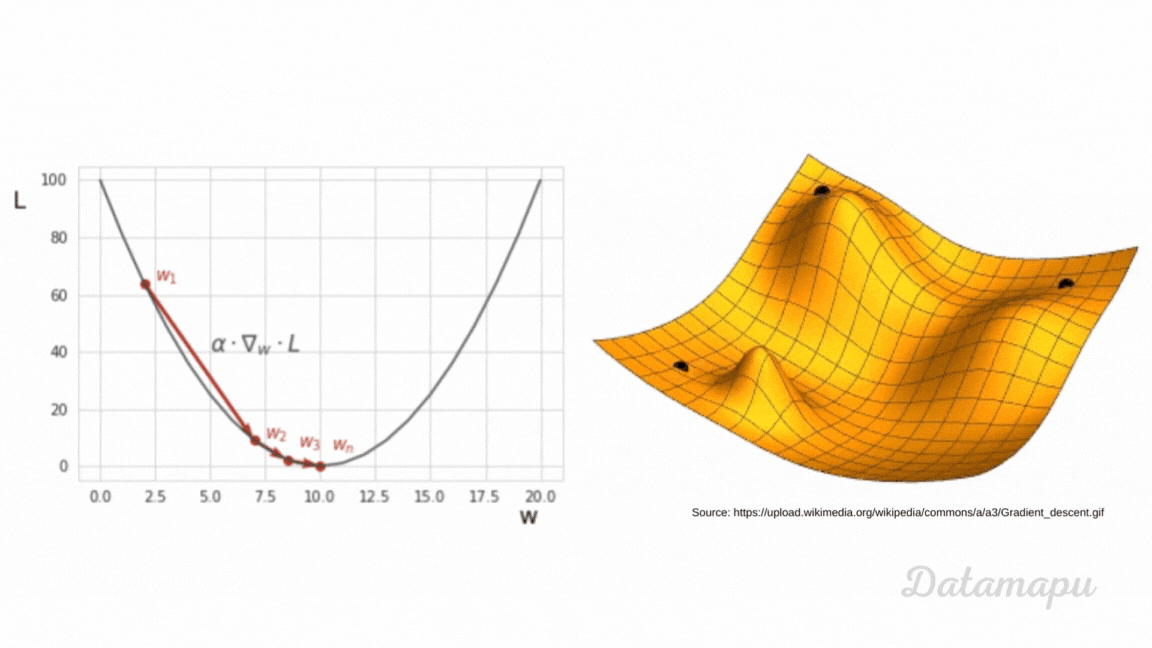
3-1. 경사하강법(Gradient Descent)
경사 하강법(Gradient Descent)은 손실 함수의 기울기를 이용해 최적의 가중치를 찾아가는 방법이다.
- 특정 매개변수(예: 가중치
w)에 대해 손실 함수의 기울기를 구하고, 기울기의 반대 방향으로 이동하며 최적점을 찾는다. - 학습률(learning rate,
lr)이 너무 크면 최적점을 지나칠 수 있고, 너무 작으면 수렴 속도가 느려진다.
3-2. 기울기 소실 & 폭발
- 소실(작아져서 0에 수렴): 시그모이드/탠하 같은 포화 활성화, 매우 깊은 네트워크, 순환 구조(RNN)에서 흔함 → 앞쪽까지 신호가 전달되지 않아 학습이 멈춤.
- 폭발(값이 비정상적으로 커짐): 깊은 곱 연산, RNN의 긴 시퀀스, 큰 학습률 → 손실이 널뛰고 수렴 실패.
대응책
- 활성화: ReLU/Leaky ReLU, 현대형(GELU/SiLU).
- 초기화: He/Xavier 등 층 깊이에 맞춘 분산.
- 정규화: BatchNorm/LayerNorm으로 분포 안정화.
- 구조: Residual(스킵) 연결, RNN은 LSTM/GRU나 짧은 BPTT.
- 학습률: 워밍업·스케줄·적절한 크기.
- 클리핑: Gradient Clipping(특히 RNN/시퀀스)으로 폭발 방지.
- 혼합정밀 학습: 손실 스케일링으로 언더플로/오버플로 완화.
3-3. 대표 최적화 알고리즘
- SGD + Momentum: 단순하지만 강력. 컴퓨터 비전 대형 모델에서 일반화가 좋다고 보고되는 경우 많음. 모멘텀은 관성처럼 일관된 방향 가속.
- Nesterov 모멘텀: 한 발 앞선 지점의 기울기를 참고해 과도한 관성을 줄이려는 변형.
- RMSProp: 파라미터별로 최근 기울기 제곱을 추적해 적응적 학습률 제공.
- Adam: 모멘텀 + RMSProp 결합. 초기 수렴 빠르고 안정적, 대부분의 NLP/멀티모달에서 기본값처럼 사용.
- AdamW: Adam에 가중치 감쇠(Weight Decay) 를 올바르게 분리 적용.
- 실무 가이드
- 기본값: AdamW + 코사인/원사이클 스케줄 + 워밍업 → 빠른 수렴과 안정성.
- 비전 대규모/최종 미세튜닝: AdamW로 예열 후 SGD+Momentum 전환이 장점일 때도.
- 배치가 매우 작음: Adam/AdamW 쪽이 안정적.
- 배치가 매우 큼: 학습률 선형 스케일링 규칙(배치 2배 → LR 2배) + 워밍업.
3-4. 수렴이 안 될 때 체크리스트
- 학습률이 너무 큼/너무 작음
- 데이터/라벨 전처리 스케일 문제(정규화/표준화 누락)
- 출력층-손실함수 짝 불일치(다중클래스에 시그모이드 사용 등)
- 클래스 불균형 방치(가중치, 샘플링, Focal Loss 필요)
- 초기화/정규화/활성화의 조합 부적합
- 배치 크기 변화에 따른 BN/스케줄러/학습률 조정 누락

기록은 기억을 지배한다.