출처: https://towardsdatascience.com
1. 퍼셉트론(Perceptron)
1-1. 퍼셉트론이란?
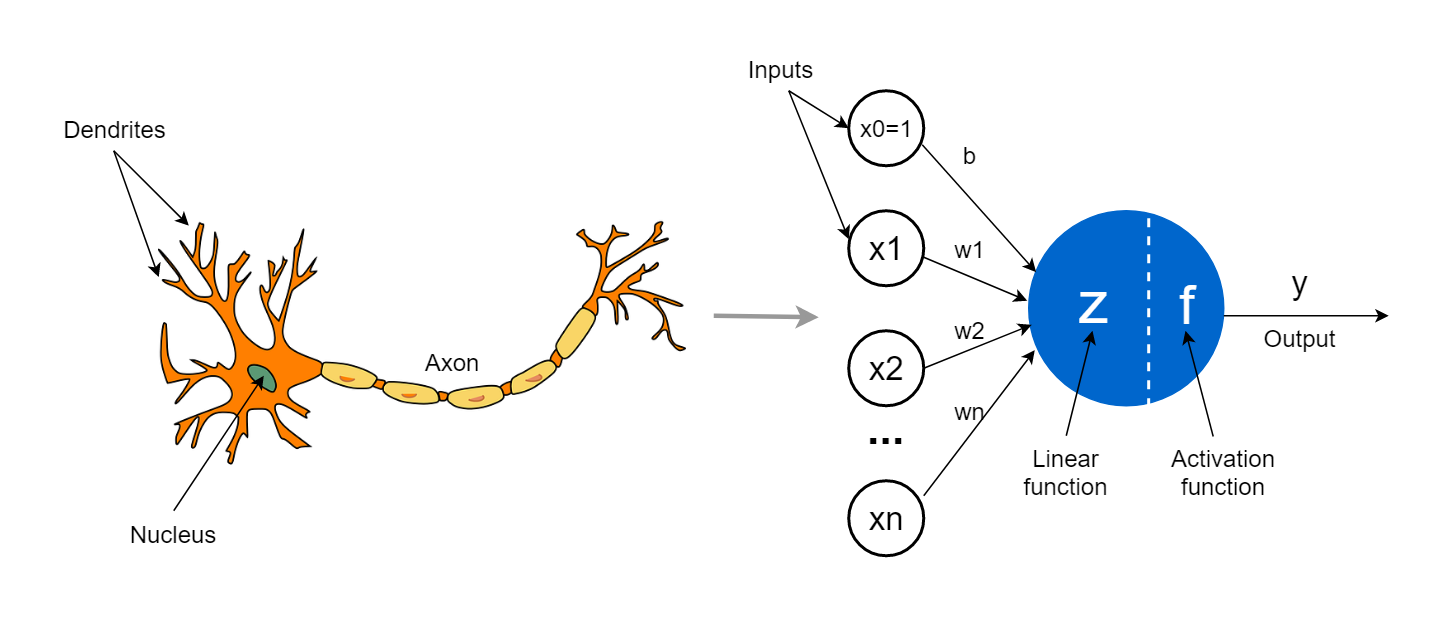
퍼셉트론은 생물학적 뉴런을 모방한 간단한 인공지능 모델로 입력 벡터 와 가중치 의 내적에 바이어스 를 더해 얻은 스칼라 를 임계함수(계단 함수) 로 이진 결정하는 선형 분류기다.
- 결정 경계: 인 직선/평면(고차원에서는 초평면).
- 한계: 선형 분리(linearly separable) 한 문제만 풀 수 있다(XOR 불가).
1-2. 어떻게 발전했나?
- 1세대(1950s): Rosenblatt의 퍼셉트론—빠른 학습, 단층 구조.
- 한계 지적(1969): Minsky & Papert가 XOR 같은 비선형 문제 한계를 정리.
- 재도약(1986): 역전파(backpropagation) 로 다층 신경망 학습이 실용화.
- 현대(2012~): 대규모 데이터·GPU·새 아키텍처(CNN/Transformer)로 딥러닝 시대 개막.
1-3. AND / OR / NAND 게이트와 퍼셉트론
두 입력 에 대해 퍼셉트론은 간단한 논리 게이트를 표현할 수 있다(계단 함수 사용).
- AND: 둘 다 1일 때만 1 → 직관적으로 “합이 2 이상이면 1”.
- OR: 둘 중 하나라도 1이면 1 → “합이 1 이상이면 1”.
- NAND: AND의 부정 → “합이 2이면 0, 그 외 1”. 이 셋은 모두 선형 분리 가능하다. 반면 XOR은 선형 경계로는 나뉘지 않아 다층 구조가 필요하다.
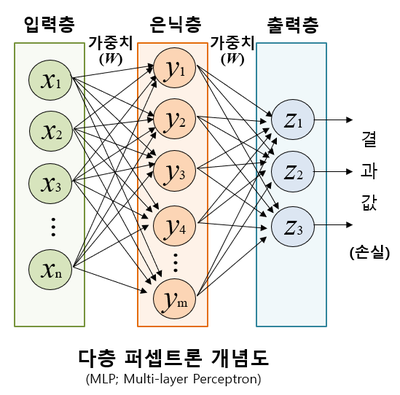
1-4. 다층 퍼셉트론(MLP)
MLP(Multi-Layer Perceptron) 은 퍼셉트론(=선형 변환) 사이에 비선형 활성화 함수를 끼운 층(layer) 들의 합성이다.
출처: https://wiki1.kr
- 구성: (입력) → → 활성화 → → … → (출력)
- 왜 비선형이 필요한가? 선형만 겹치면 전체가 다시 선형이 된다. 활성화 함수가 들어가야 XOR처럼 비선형 결정 경계를 표현할 수 있다.
- 표현력: 충분한 너비/깊이를 가진 MLP는 연속함수를 임의의 정밀도로 근사할 수 있다.
2. 활성화 함수
- 계단(Step)함수:
- 장점: 결정이 명확.
- 단점: 미분 불가 → 경사하강 기반 학습에 부적합(이론적 설명용).
- 시그모이드(Sigmoid)함수:
- 장점: 범위, 확률 해석.
- 단점: 큰 구간에서 기울기 소실(gradient vanishing), 출력이 비영(0~1)이라 깊은 망에서 수렴이 느릴 수 있음.
- 렐루(ReLU):
- 장점: 계산 간단, 기울기 소실 완화, 깊은 네트워크 학습 안정.
- 단점: 음수 영역 기울기 0 → 죽은 ReLU(뉴런이 영영 0만 출력) 가능.
- 리키 렐루(Leaky ReLU):
- 장점: 음수 영역에 작은 기울기를 남겨 죽은 ReLU 완화.
- 단점: 선택 민감, 항상 ReLU보다 낫다고 보긴 어려움.
3. 출력층 설계
출력층 활성화와 손실은 짝을 맞춰 설계하는 게 정석이다.
3-1. 항등(Identity) — 회귀(연속값 예측)
- 출력:
- 손실: MSE(평균제곱오차)나 MAE
- 메모: 목표 분포가 대략 가우시안이면 MSE가 자연스럽다. 스케일이 크면 표준화가 필수.
3-2. 시그모이드 — 이진 분류 / 다중라벨 분류
- 출력: → “양성일 확률”로 해석
- 손실: Binary Cross-Entropy
- 메모: 다중라벨(서로 배타적이지 않은 여러 클래스)에선 클래스별 시그모이드를 독립 적용.
3-3. 소프트맥스(Softmax) — 다중클래스(배타적) 분류
- 출력: (각 클래스 확률)
- 손실: Cross-Entropy
- 메모: 클래스 간 합이 1이 되어 상호배타적 선택에 적합. 로그-소프트맥스 + NLLLoss 형태로 구현되기도 함.

기록은 기억을 지배한다.