출처: https://www.aima.org
1. AI 개요
1-1. AI란 무엇인가
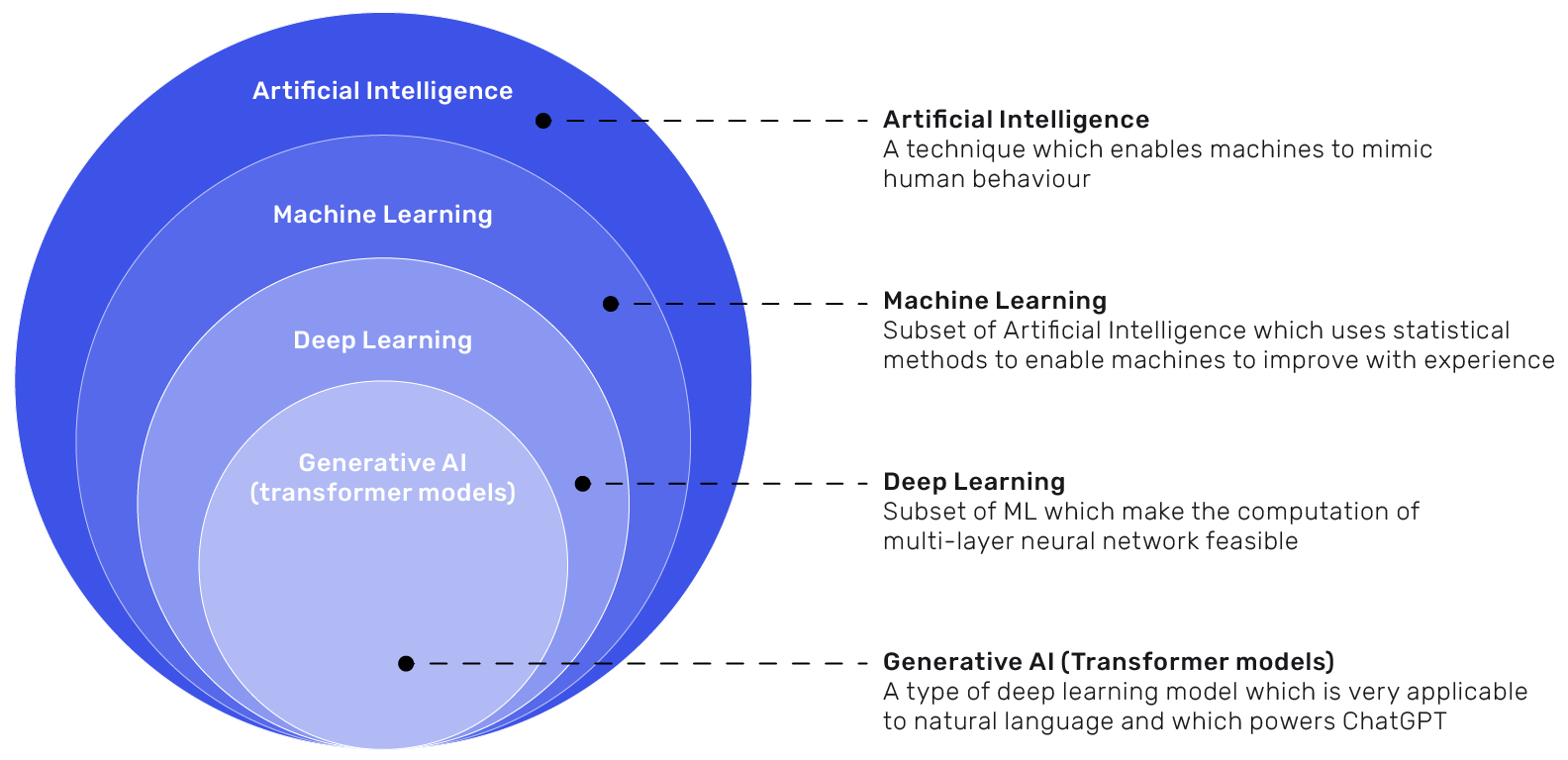
AI(Artificial Intelligence) 는 “기계가 인간의 지능적 과업을 수행하도록 만드는 기술”의 총칭이다. 범위가 넓어서 규칙 기반 추론부터 통계적 학습, 생성형 모델까지 모두 포함한다.
- 약한(좁은) AI: 특정 과업에 특화된 시스템(스팸 필터, 추천, 음성 인식).
- 강한(일반) AI: 인간 수준의 범용 지능(연구적 개념, 아직 실현 X).
1-2. 전통적 AI vs 머신러닝 vs 딥러닝
- 전통적 AI: 사람이 만든 규칙(rule) 로 문제를 해결(전문가 시스템, 규칙 기반 추론). 데이터가 적거나 규칙이 명확할 때 유리.
- 머신러닝(ML): 데이터로 규칙을 학습. 선형회귀, 결정트리, SVM, 랜덤포레스트 등. 특징(Feature)을 사람이 설계하는 경우가 많다.
- 딥러닝(DL): 다층 신경망이 표현(Feature)까지 스스로 학습. 이미지·음성·자연어 등 비정형 데이터에서 강력한 성능을 보인다.
1-3. AI의 주요 활용 분야
- 비전: 불량 검출, 자율주행 인지, 의료 영상 분석.
- 자연어: 번역, 질의응답, 요약, 생성형 챗봇.
- 음성/오디오: 음성 인식, 화자 분리, TTS.
- 추천/예측: 이탈 예측, 수요 예측, 개인화 추천.
- 로보틱스/제어: 강화학습을 통한 경로 계획, 조립/픽킹 자동화.
1-4. 현실적 제약과 윤리
- 자원: 데이터 라벨 비용, 학습/추론 비용(GPU, 메모리).
- 거버넌스: 개인정보·보안, 저작권, 설명가능성(XAI), 공정성(Fairness).
- 책임있는 사용: 휴먼 인 더 루프(HITL), 감사 로그, 실패 모드 대비.
2. 딥러닝의 이해
출처: https://builtin.com
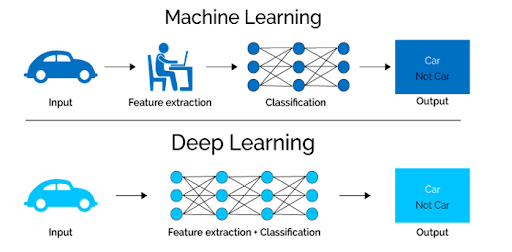
2-1. 왜 딥러닝인가
딥러닝은 “입력→출력” 사이의 복잡한 매핑을 다층 비선형 함수로 근사한다. 사람이 특징을 설계하지 않아도 표현(Representation) 을 자동으로 학습해, 이미지·음성·텍스트처럼 구조가 복잡한 데이터에서 탁월하다.
2-2. 기본 작동 원리
- 신경망(Neural Network): 뉴런(노드)이 층(layer)으로 연결된 구조. 각 층은 가중치·편향을 가지고 활성화 함수(ReLU, GELU 등) 로 비선형성을 만든다.
- 순전파(Forward): 입력을 통과시켜 예측을 만든다.
- 역전파(Backward): 손실(Loss)의 기울기를 계산해 가중치를 경사하강법(Adam, SGD) 으로 업데이트.
- 학습 목표: 손실 최소화 → 일반화 성능(테스트 성능) 최대화.
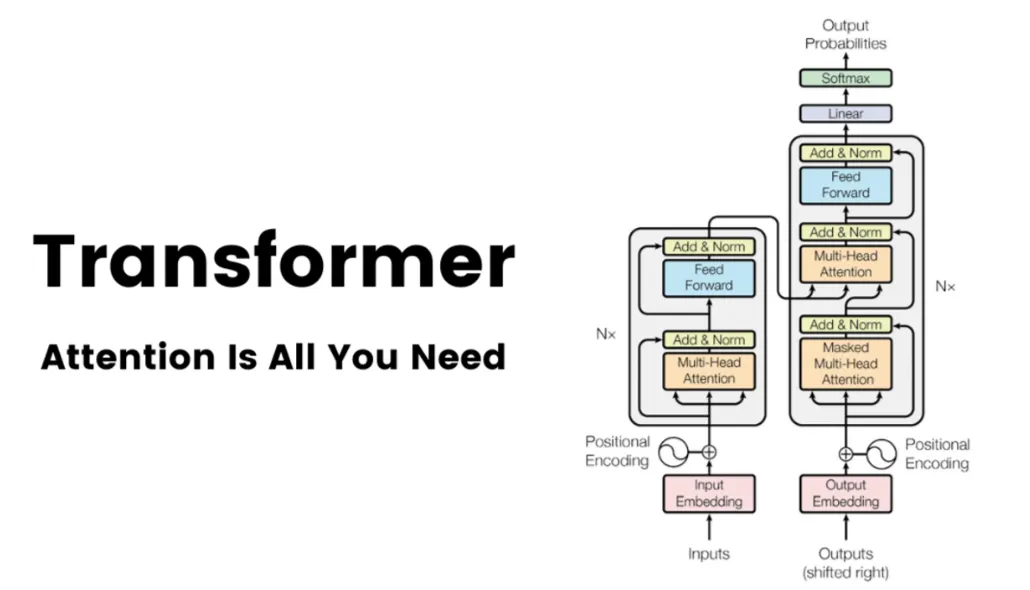
2-3. 대표 아키텍처
출처: https://saqibcs.medium.com
- CNN(합성곱 신경망): 지역적 패턴과 계층적 특징을 학습. 이미지 분류·검출·분할의 표준 출발점.
- RNN/LSTM/GRU: 순차 데이터(시계열, 음성)에 초창기 표준.
- Transformer: 어텐션으로 장기 의존성을 효율적으로 학습. 언어모델(LLM), 비전 트랜스포머(ViT), 멀티모달까지 확장. 오늘날 대부분의 대규모 모델의 뼈대.
2-4. 학습 데이터와 일반화
- 데이터 품질: 라벨 정확도·표현 다양성(조명, 각도, 배경), 클래스 불균형 해소가 핵심.
- 증강(Augmentation): 회전·크롭·색상변환, MixUp/CutMix, 텍스트 마스킹 등으로 일반화 향상.
- 편향/드리프트: 훈련 분포와 운영 환경이 다르면 성능 급락 → 모니터링 + 재학습 루프 필수.
2-5. 과적합과 정규화
- 문제: 훈련 데이터에 너무 최적화되어 새로운 데이터에서 성능 하락.
- 대응: 드롭아웃, 가중치 감쇠(L2), 배치정규화, 데이터 증강, 초기 중단(Early stopping), 더 많은/더 다양한 데이터.
2-6. 평가 지표
- 분류: 정확도, 정밀도/재현율, F1, AUC.
- 검출: mAP@0.5, mAP@0.5:0.95(다중 IoU).
- 세그멘테이션: IoU, mIoU, Dice.
- 회귀/예측: RMSE, MAE, MAPE.
- 언어/생성: BLEU/ROUGE/METEOR, perplexity, 인간 평가(Human Preference).
2-7. 대규모 사전학습과 전이학습
- 프리트레인(Pretrain): 대규모 일반 데이터로 표현을 학습.
- 파인튜닝(Finetune): 도메인 데이터로 미세 조정 → 적은 데이터로도 높은 성능.
- LoRA/Adapter/Prompt Tuning: 파라미터 효율형 미세튜닝으로 비용·시간 절감.
2-8. 추론(서빙)과 최적화
- 성능 목표: 지연(latency), 처리량(throughput), 비용의 균형.
- 최적화 기법: 양자화(INT8/FP16), 프루닝(가지치기), 지연 로딩, 배치/동시성 조정, 캐싱.
- 배포 경로: 클라우드(API), 엣지(모바일/임베디드), 하이브리드. 하드웨어에 맞춰 ONNX/TensorRT/OpenVINO/CoreML 등으로 내보내기.
2-9. 해석 가능성과 안전성
- XAI: CAM/Grad-CAM, SHAP/LIME 등으로 모델의 의사결정을 시각화/설명.
- 안전: 입력 교란(적대적 예제), 프롬프트 주입, 데이터 유출 등 위협 모델을 정의하고 방어(필터링, 감지, 거버넌스) 설계.
2-10. 언제 딥러닝을 쓰고, 언제 아닌가
- 딥러닝 권장: 이미지/음성/텍스트 등 비정형 대용량 데이터, 피처 공학이 어려운 문제, 높은 상한(성능 잠재력)이 필요한 경우.
- 전통 ML/규칙 권장: 데이터가 적고 구조가 단순, 해석가능성과 일관성이 더 중요, 지연/비용 제약이 극심할 때.

기록은 기억을 지배한다.