1. 결정트리(Decision Tree)란?
Decision Tree는 분류 및 회귀 작업 모두에 사용되는 비모수 지도 학습 알고리즘으로 루트 노드, 가지, 내부 노드 및 리프 노드로 구성된 계층적 트리 구조를 가지고 있다.
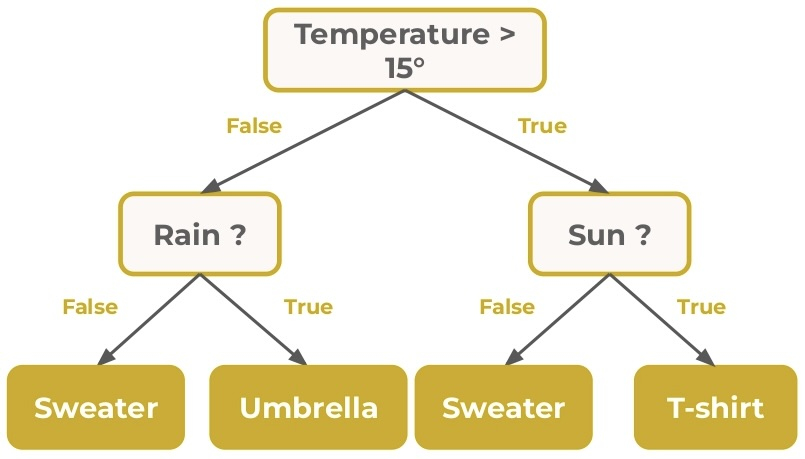
출처: https://inside-machinelearning.com
- 입력 특성(네모상자=노드)들을 기준으로 질문을 순차적으로 분기하여(예: "비가 오는가?") 최종 노드(leaf)에서 클래스(분류)나 수치(회귀) 를 예측하는 모델이다.
- 루트 노드에서 시작해 불순도(impurity) 가 가장 많이 줄어드는 방향으로 데이터를 나누며, 각 분기는 규칙(if-else) 로 해석할 수 있다.
1-1. 결정트리 구조 및 특징
- 노드(node): 데이터를 담는 지점이다
- 분할(split): 한 특성의 임곗값(또는 범주)으로 두 그룹(보통 이진)으로 나눈다
- 잎(leaf): 더는 분할하지 않는 끝 노드로, 예측값(클래스/평균)을 낸다
- 깊이(depth): 루트에서 잎까지의 최대 경로 길이
- 특징
- 규칙 기반이라 해석 가능하고, 결측/스케일에 비교적 강하다(트리 구현에 따라 다름)
- 분류는 지니(Gini)·엔트로피 같은 불순도, 회귀는 MSE(평균제곱오차) 를 최소화하는 방향으로 성장한다
- CART 계열은 이진 분할만 사용한다
1-2. 장/단점
장점
- 결과를 해석하고 이해하기 쉬움
- 비선형/상호작용 자동 학습
- 특성 스케일링 불필요, 더미 변수만으로도 범주 처리 가능
단점
- 깊게 자라면 과적합이 쉬움(고분산)
- 작은 데이터 변화에도 구조가 크게 바뀌는 불안정성
- 단일 트리 성능 한계 → 실제로는 랜덤포레스트/부스팅이 더 자주 쓰임
2. 결정트리의 학습 과정
결정트리는 가능한 모든 특성·임계값 후보를 시험해 불순도(정보) 감소가 최대인 분할을 고르고, 이를 재귀적으로 반복한다.
핵심은 “매 단계에서 가장 좋은 분할을 탐욕적(greedy) 으로 선택한다”는 것이다.
- 모든 후보 특성 jjj 과 임곗값 ttt 에 대해 분할 후 불순도 감소량을 계산
- 감소량이 가장 큰 (j,t)(j, t)(j,t) 를 선택하여 노드를 둘로 나눔
- 정지 조건(깊이, 잎 샘플 수 등)에 도달할 때까지 재귀적으로 반복
아래는 깊이가 각 1→2→9인 결정트리가 만든 결정 경계이다.
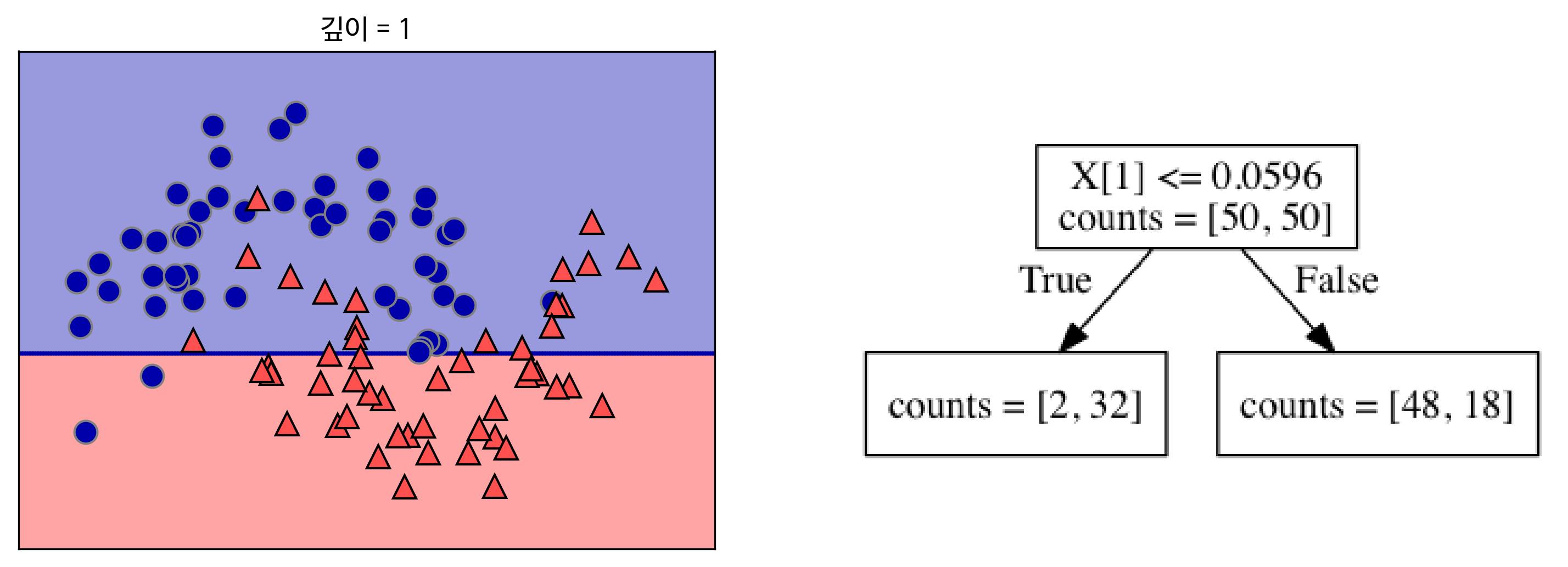
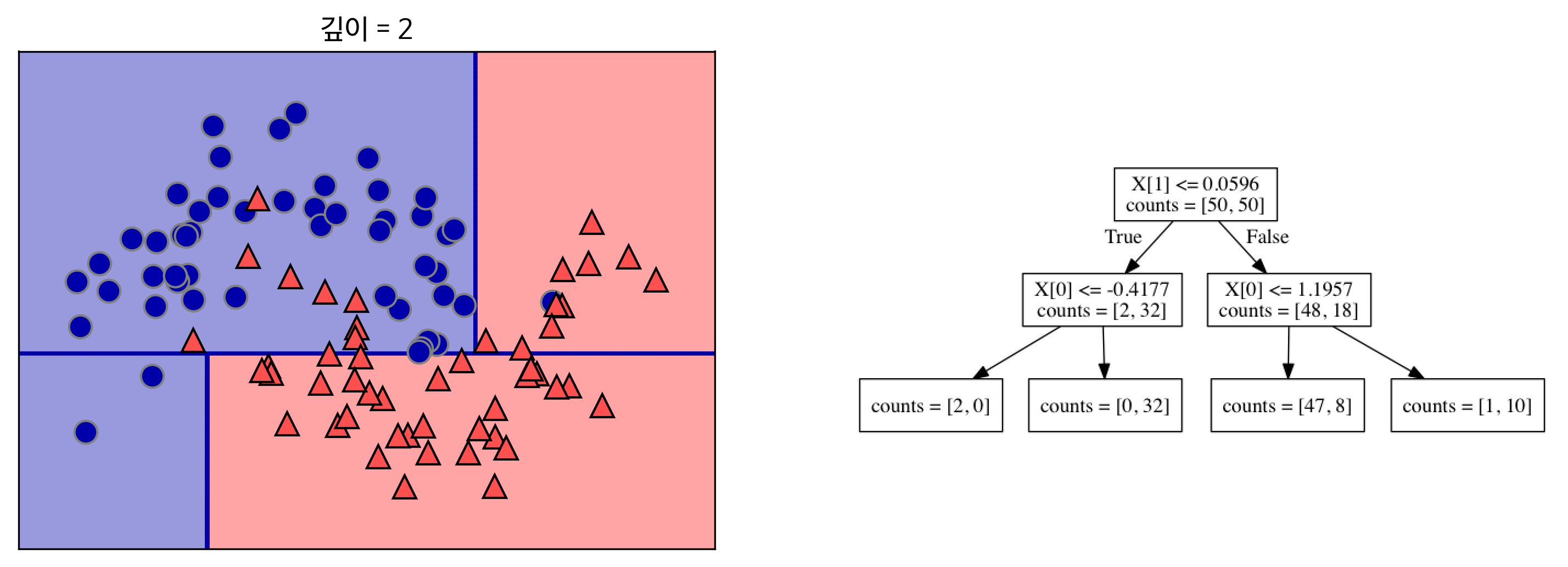
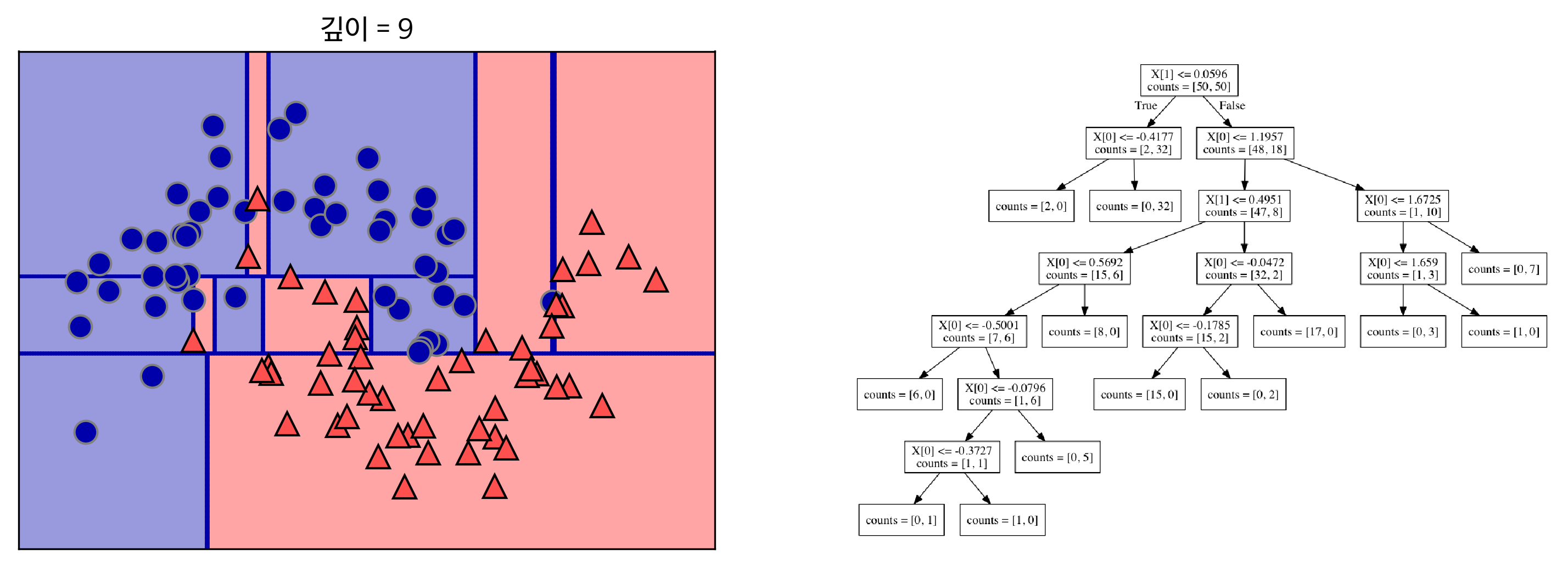
출처: https://tensorflow.blog
수식(분류, 지니 예시):
여기서 는 불순도, 은 왼쪽/오른쪽 샘플 수이다.
2-1. 결정트리 학습 방법, CART
CART(Classification And Regression Tree) 알고리즘은 결정 트리를 학습시키는 대표적인 방법으로,
- 이진 분할만 사용한다
- 분류에서 지니(Gini), 엔트로피(Entropy)(또는 log loss)를, 회귀에서 MSE(또는 MAE 변형)을 불순도로 사용한다
- 학습은 전적으로 불순도 감소의 합을 최대화하는 방향이다
2-2. 엔트로피와 정보이득
엔트로피
엔트로피는 데이터의 불확실성을 측정하는 지표로, 분류 문제에서 얼마나 혼합된 데이터를 가지고 있는지를 나타낸다. 엔트로피가 높을수록 데이터가 더 혼란스럽고, 엔트로피가 낮을수록 데이터가 더 잘 정돈된 상태다.
- H(D): 데이터 D의 엔트로피
- k: 클래스의 개수
- pi: 클래스 i에 속하는 데이터의 비율
- 엔트로피 값의 범위
- H=0: 데이터가 하나의 클래스에 완벽히 속함 (완전히 정돈된 상태)
- H>0: 데이터가 여러 클래스에 혼합되어 있음 (불확실성 존재)
- H=1: 데이터가 모든 클래스에 균등하게 분포됨 (최대 불확실성)
정보이득(Information Gain)
정보 이득은 데이터를 특정 속성(특징)에 따라 분할했을 때, 불확실성이 얼마나 줄어드는지를 측정하는 지표다. 높은 정보 이득을 가진 속성을 선택하면 데이터의 엔트로피를 크게 줄일 수 있다.
- IG(D,A): 데이터 D와 속성 A에 대한 정보 이득
- H(D): 전체 데이터 D의 엔트로피
- : 속성 A의 값 v에 해당하는 데이터 부분 집합
- : 데이터 D에서 Dv가 차지하는 비율
3. 규제 매개변수, 사전 가지치기(Pre-pruning)
트리가 너무 깊어지는 것을 사전에 막아 과적합을 줄인다.
max_depth: 트리 최대 깊이 제한(가장 영향력 큼)min_samples_split: 분할을 시도할 최소 샘플 수min_samples_leaf: 잎이 가질 최소 샘플 수(작을수록 과적합↑)max_leaf_nodes: 잎 노드 수 상한max_features: 분할 후보로 볼 특성 개수 제한(랜덤화 → 분산↓, 과적합↓)- 분류
class_weight: 불균형 시 노드 점수 계산에 가중치 반영 - 회귀
min_impurity_decrease: 분할 시 필요한 최소 불순도 감소량

max_depth을 설정하지 않아 깊어진 트리, 출처: IT Story
튜닝 원칙
- 먼저
max_depth로 큰 과적합을 막고, 필요하면min_samples_leaf를 키워 노이즈 분할을 억제 - 특성이 많으면
max_features로 랜덤성을 주어 일반화를 개선 - 검증셋/교차검증으로 조합을 탐색
4. 노드 삭제/병합, 가지치기(Pruning)
성장 후 불필요한 가지를 잘라 단순화(사후 가지치기)한다.
- 비용복잡도 가지치기(Cost-Complexity Pruning, CCP)
- 잎을 제거해 얻는 오차 증가와 모델 복잡도 사이의 균형을 맞춤
- 사이킷런(Scikit-learn)의
ccp_alpha가 이 계열의 규제 강도이다
실무 절차
1) cost_complexity_pruning_path 로 알파 경로 후보를 얻음
2) 각 ccp_alpha 로 교차검증하여 최적 알파 선택
3) 최종 트리를 재학습
5. 시각화 및 분석
시각화에는 몇가지 방법이 있는데 우리 수업 시간엔 graphviz를 설치하여 진행했다. 아래 예시는 레드/화이트 와인 이진분류 데이터셋을 사용하여 분석/시각화한 결정트리이다.
5-1. 데이터셋
- 컬럼: alcohol, sugar, pH, class(0=레드, 1=화이트)
- 표본 수: 6,497개, 특성 3개
- 타깃 분포(요약): class 평균이 0.754 → 화이트가 약 75%로 많은 불균형 데이터
→ 아무 생각 없이 “항상 화이트(1)”만 맞춘다면 정확도 ≈ 75.4%가 나오는 상황
5-2. 학습 및 평가
dt_clf = DecisionTreeClassifier(random_state=0, max_depth=3)
dt_clf.fit(X_train, y_train)
dt_clf.score(X_train, y_train), dt_clf.score(X_test, y_test)
# (0.8433908045977011, 0.8584615384615385)max_depth=3으로 사전 가지치기(pre-pruning) 를 적용해 과적합을 완화함- 정확도: Train 84.3% / Test 85.8%
- 베이스라인(항상 화이트) ≈ 75.4% 대비 약 10%p 개선
- Train/Test 간 격차가 작아 과적합이 심하지 않음을 시사함
5-3. 시각화
from sklearn.tree import plot_tree
plt.figure(figsize=(20, 10))
plot_tree(
dt_clf,
filled=True, # 색 채우기 옵션 (특정 클래스의 비율 표현)
feature_names=X.columns, # 특성 이름
class_names=['red wine', 'white wine'], # 클래스 이름
# max_depth=3
)
plt.savefig('wine_simple.png') # 이미지 저장
plt.show()filled=True: 색으로 클래스 비율을 표현(노드가 더 “순수”할수록 한 색으로 진해짐)feature_names,class_names: 노드 라벨을 사람이 읽기 좋게 표시
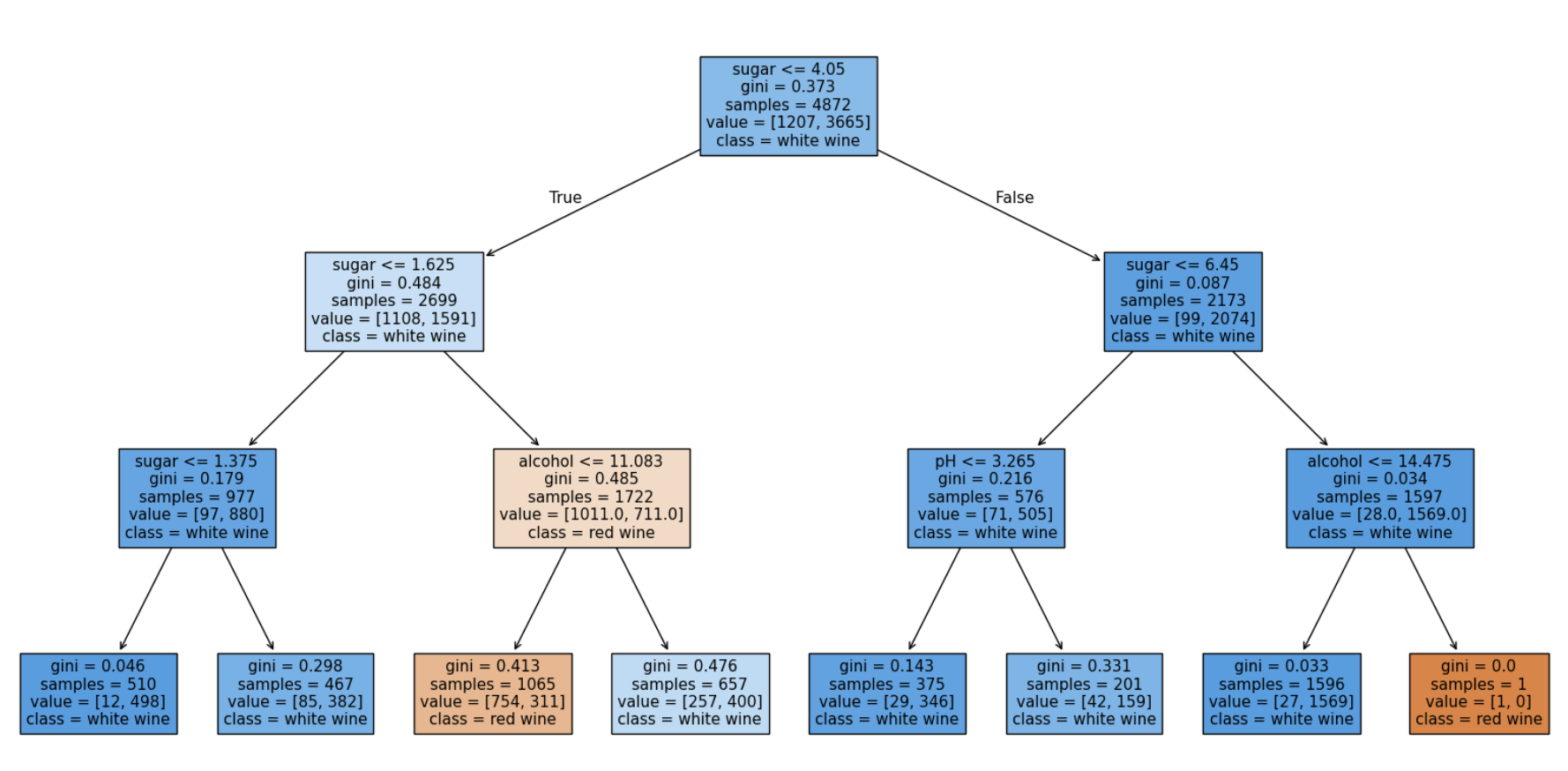
트리 노드 라벨의 각 항목 의미:
sugar <= t: 분할 기준(왼쪽 가지는 sugar ≤ t, 오른쪽은 > t)gini: 지니 불순도 1−∑kpk21-\sum_k p_k^21−∑kpk2 (0에 가까울수록 한 클래스가 지배적)samples: 해당 노드에 포함된 샘플 수value=[n_red, n_white]: 노드 내 클래스별 개수class: 그 노드에서 다수 클래스(예측 클래스)
5-4. 한 줄 분석
이 트리는 당도(sugar) 를 중심으로 레드/화이트를 나누며, max_depth=3으로 과적합을 억제해 테스트 정확도 ≈ 86%를 얻었다.
참고 자료
IT Story: https://itstory1592.tistory.com/13
텐서 플로우 블로그 (Tensor ≈ Blog): https://tensorflow.blog/
IBM: https://www.ibm.com
