1. 지도 학습(Supervised Learning)이란?
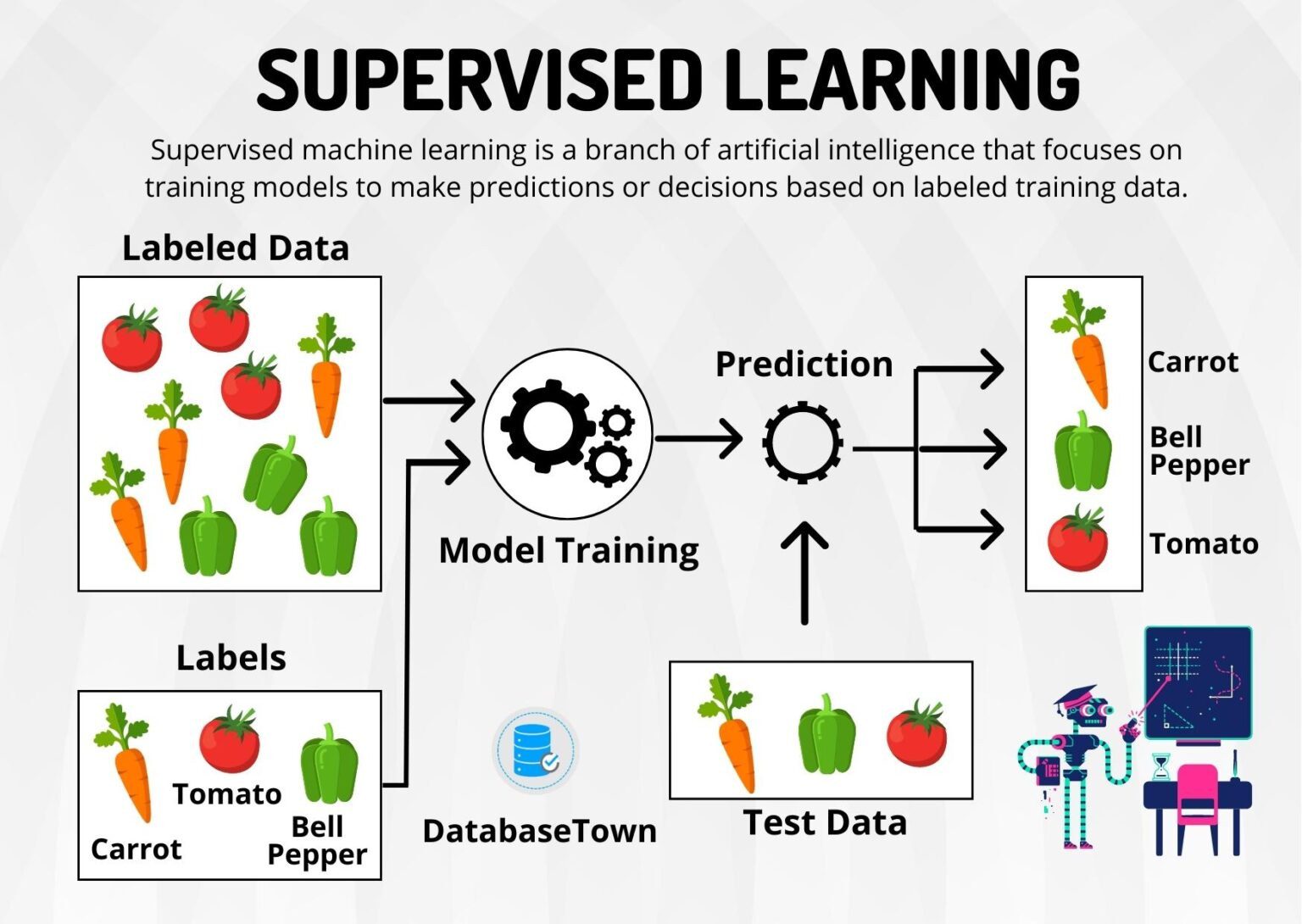
이미지 출처: https://databasetown.com
정답(라벨)이 있는 데이터를 보고 입력→정답 간 규칙을 학습해, 보지 못한 입력의 정답을 예측하는 방법이다.
- 학습 데이터로 사용하는 데이터 안에, 어떤 데이터를 바탕으로 어떤 값이 결론으로 나온다는 정답이 들어가야 한다.
- 예측 결과를 기반으로 모델의 성능을 평가하고, 성능을 최적화한다.
- 지도 학습은 주어진 정답이 있으므로 모델 성능이 더 높지만, 정답 데이터가 없으면 학습할 수 없다는 단점을 가진다.
1-1. 지도 학습의 종류
-
분류: 입력 데이터를 주어진 클래스(label)로 분류하는 문제
예: 스팸 이메일 분류, 이미지 분류 등 -
회귀: 연속적인 값을 예측하는 문제("회귀==예측"이라 보면 됨)
예: 주택 가격 예측, 주식 가격 예측 등
2. 분류(Classification) 분석이란?
분류(Classification)는 주어진 데이터를 특정 클래스(또는 레이블)로 나누는 머신러닝의 대표적인 지도 학습(Supervised Learning) 문제 유형이다. 분류 모델은 입력 데이터의 특징을 학습하여 미지의 데이터가 속하는 클래스를 예측한다.
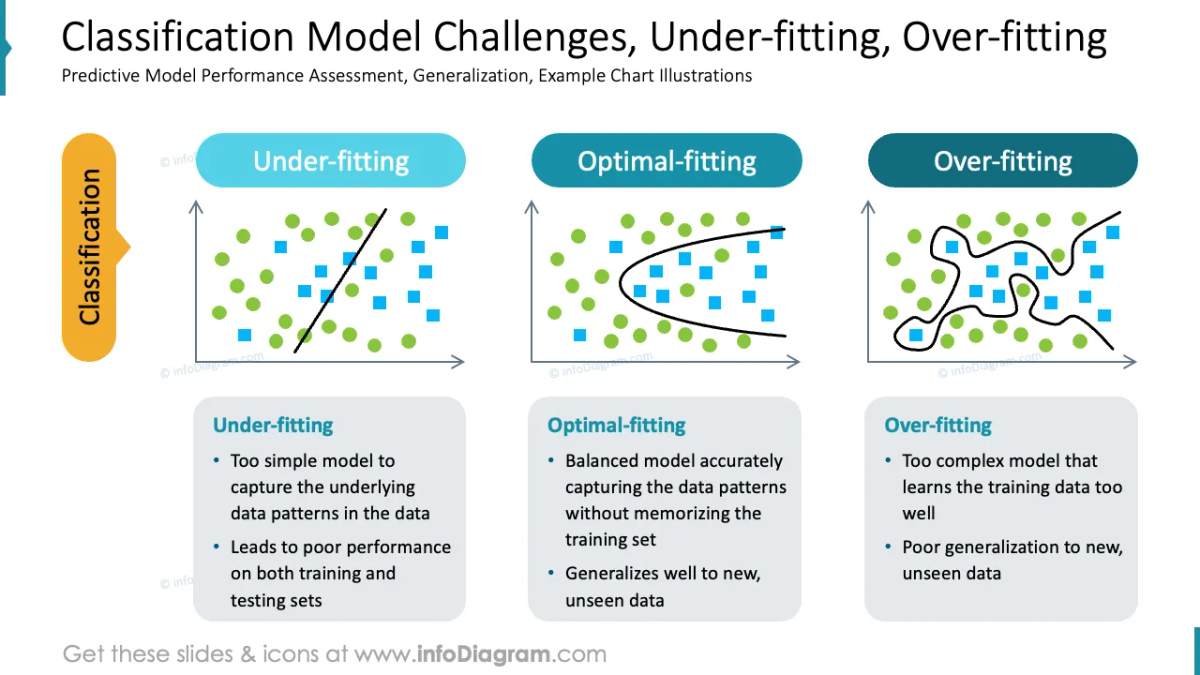
출처: https://www.infodiagram.com
- 출력 값이 연속적인 숫자가 아니라, 유한한 클래스 값으로 제한된다.
- 학습 데이터에 각 데이터 포인트의 정답 레이블이 포함되어 있어야 한다.
2-1. 분류 문제 종류
- 이진 분류: 스팸/비스팸
- 다중 분류: 붓꽃 3종 분류
- 다중 라벨: 한 샘플에 라벨 여러 개(영화 장르)
- 순서형(Ordinal): 위험도 낮음/중간/높음
- 불균형 클래스: 양성 비율이 매우 낮은 사기 탐지(평가 지표 주의)
2-2. 주요 분류 모델
1) 로지스틱 회귀
- 아이디어: 선형 결합 → 시그모이드/소프트맥스로 확률 추정
- 장점: 빠름, 해석 용이(계수), 기준선(baseline)에 좋음
- 단점: 비선형 경계엔 약함(다항/커널로 보완)
- 언제: 특성 수가 많아도 희소/선형적으로 분리 가능할 때
2) k-NN
- 아이디어: 가까운 이웃 다수결
- 장점: 학습 단순, 데이터 분포 반영
- 단점: 예측 느림, 차원의 저주
- 언제: 소규모, 명확한 지역성
3) 나이브 베이즈
- 아이디어: 특성 독립 가정 + 베이즈 정리
- 장점: 텍스트 분류에 강함(멀티노미얼 NB), 매우 빠름
- 단점: 독립 가정이 강함
- 언제: 빠른 1차 모델, 문서/메일 스팸 등
4) 결정트리 / 랜덤포레스트 / 그라디언트부스팅(XGBoost/LightGBM 등)
- 아이디어: 규칙 분할(트리) / 다수 트리 앙상블
- 장점: 비선형·상호작용에 강함, 피처 스케일링 불필요
- 단점: 트리는 과적합 위험, 부스팅은 튜닝 필요
- 언제: 대부분의 탭울러(tabular) 문제에서 강력한 기본 선택지
5) SVM
- 아이디어: 마진 최대화(커널로 비선형 분리)
- 장점: 고차원에서도 성능 우수
- 단점: 대규모 데이터/튜닝 비용
- 언제: 특성 수 많고 샘플 중간 규모
6) 신경망(MLP)
- 아이디어: 은닉층으로 비선형 함수 근사
- 장점: 유연성 높음
- 단점: 데이터/튜닝/정규화 필요
- 언제: 특성 간 복잡한 상호작용이 있을 때
분류 예제 코드(파이프라인 + 평가 기초)
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report, roc_auc_score, roc_curve
import numpy as np
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42, test_size=0.2)
pipe = Pipeline([
("scaler", StandardScaler()),
("clf", LogisticRegression(max_iter=1000, class_weight="balanced"))
])
# 교차검증(정확도)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print("CV acc:", cross_val_score(pipe, X, y, cv=cv, scoring="accuracy").mean())
# 학습/평가
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
y_prob = pipe.predict_proba(X_test)[:, 1]
print(classification_report(y_test, y_pred, digits=3))
print("ROC-AUC:", roc_auc_score(y_test, y_prob))
3. 회귀(Regression) 분석이란?
회귀 분석이란 독립 변수와 종속 변수의 관계를 분석하는 것이다. 머신 러닝에서 독립 변수는 feature이고, 종속 변수는 label이다. 즉, 피처와 레이블 사이의 관계를 분석하는 것이다.

출처: https://www.infodiagram.com
- 회귀(Regression)는 연속적인 값을 예측하는 지도학습 문제이다. 분류 문제와 달리, 회귀 문제는 정해진 클래스가 아닌 숫자를 예측한다.
- 회귀 모델은 입력 변수(특성)를 기반으로 목표 변수(종속 변수)의 연속적인 값을 예측한다.
- 예시: 주택 가격 예측, 주식 가격 예측, 온도 변화 예측 등
3-1. 회귀 분석 종류
- 선형 회귀: 입력 선형 결합으로 예측
- 정규화 회귀: Ridge(L2), Lasso(L1), ElasticNet(L1+L2)
- 다항/커널 회귀: 비선형 패턴 근사
- 트리 기반 회귀: 결정트리·랜덤포레스트·GBM
- 서포트 벡터 회귀(SVR): 마진 내 오차 무시(ε-insensitive)
- k-NN 회귀, 포아송/퀀타일 회귀(GLM) 등
3-2. 주요 회귀 모델 소개 및 설명
1) 선형/정규화 회귀
- 아이디어: y^=w⊤x+b\hat{y} = w^\top x + by^=w⊤x+b / 가중치 크기에 패널티(L1/L2)
- 장점: 빠름, 해석 가능, 과적합 제어
- 단점: 강한 선형 가정
- 언제: 베이스라인, 피처 수 많고 상관관계가 비교적 선형일 때
2) 다항 특성 + 선형
- 아이디어: 다항 변환으로 비선형 패턴을 선형모형으로 설명
- 주의: 차수↑ → 과적합↑ (정규화 병행)
3) 트리/랜덤포레스트/그라디언트부스팅
- 아이디어: 구간 분할로 비선형 근사, 앙상블로 성능 향상
- 장점: 범주형/결측치 처리 우수(일부 라이브러리), 상호작용 자동 학습
- 단점: 튜닝 필요, 해석성 낮을 수 있음
- 언제: 탭울러 회귀의 강력한 디폴트
4) SVR
- 아이디어: ε-튜브 내 오차 무시 + 커널로 비선형
- 장점: 복잡한 경계도 잘 핏
- 단점: 대규모 데이터 비용
- 언제: 중간 규모, 복잡한 패턴
5) 신경망(MLPRegressor 등)
- 장점: 높은 유연성
- 단점: 데이터/튜닝/정규화 필요
- 언제: 비선형·대규모·복잡 상호작용
회귀 예제 코드(파이프라인 + 지표)
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import numpy as np
X, y = fetch_california_housing(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
pipe = Pipeline([
("scaler", StandardScaler()),
("reg", Ridge(alpha=1.0))
])
cv = KFold(n_splits=5, shuffle=True, random_state=42)
print("CV RMSE:", (-cross_val_score(pipe, X, y, cv=cv, scoring="neg_root_mean_squared_error")).mean())
pipe.fit(X_train, y_train)
pred = pipe.predict(X_test)
print("RMSE:", mean_squared_error(y_test, pred, squared=False))
print("MAE :", mean_absolute_error(y_test, pred))
print("R2 :", r2_score(y_test, pred))
4. 평가 지표
4-1. 분류 지표
- 정확도: 불균형에 취약
- 정밀도/재현율/F1: 불균형·임계값 조정 시 필수
- ROC-AUC / PR-AUC: 확률 분리력, 특히 PR-AUC는 극단적 불균형에 유용
4-2. 회귀 지표
- MAE: 절대 오차, 이상치에 비교적 강건
- RMSE: 큰 오차에 민감, 튜닝 지표로 자주 사용
- R²: 설명력(1에 가까울수록 좋음)
4-3. 데이터·모델링 팁
- 데이터 분할: 누수 방지(train/valid/test), 분류는
Stratified분할 권장 - 스케일링: 선형/거리·마진 기반 모델은
StandardScaler - 카테고리: 원-핫/타겟 인코딩(주의)
- 불균형:
class_weight, 언더/오버샘플링(SMOTE), 임계값 최적화 - 교차검증: 작은 데이터엔 필수, 파이프라인으로 전처리 포함
- 해석/신뢰: 특성 중요도, SHAP, 캘리브레이션(분류 확률 보정)
- 하이퍼파라미터 탐색:
RandomizedSearchCV→ 필요 시GridSearchCV
5. 언제 어떤 모델을 사용할까?
모델 선택의 핵심은 “데이터 모양·문제 유형·규모·제약” 4가지를 보고 무난한 출발 모델 → 한 단계 업그레이드 순서로 고르는 것이다.
5-1. 가장 먼저: 무난한 기준선(baseline)부터 시작
- 분류:
로지스틱 회귀(LogisticRegression) - 회귀:
릿지(Ridge)
이 둘은 빠르고 튼튼하며 과적합을 억제하는 정규화가 내장되어 있다. “기준 점수”를 만드는 데 최고다.
간단 예시(수치형 특성만 있을 때):
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, Ridge
from sklearn.pipeline import Pipeline
# 분류 기준선
clf_baseline = Pipeline([("scaler", StandardScaler()),
("clf", LogisticRegression(max_iter=1000))])
# 회귀 기준선
reg_baseline = Pipeline([("scaler", StandardScaler()),
("reg", Ridge(alpha=1.0))])
5-2. 탭울러(표 형태) 데이터, 성능을 더 올리고 싶을 때
- 추천:
랜덤포레스트(RandomForest),그라디언트 부스팅(Gradient Boosting, XGBoost/LightGBM) - 이유: 트리 기반 앙상블은 비선형·특성 상호작용을 잘 잡고, 스케일링도 거의 필요 없다.
- 사용 팁
- 랜덤포레스트: 튜닝 부담이 적고 안정적 → “강한 기준선”
- 부스팅 계열(XGBoost/LightGBM): 튜닝하면 최고 성능을 자주 내지만 과적합/하이퍼파라미터 관리가 필요
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
clf = RandomForestClassifier(n_estimators=300, random_state=42)
reg = RandomForestRegressor(n_estimators=300, random_state=42)
5-3. 텍스트(문서/댓글/메일)처럼 고차원·희소한 데이터
- 추천(분류):
나이브 베이즈(멀티노미얼),로지스틱 회귀,선형 SVM(LinearSVC) - 이유: 단어 수천~수만 차원에서도 빠르고 강하다.
- 사용 팁:
TfidfVectorizer로 벡터화 → 선형 모델을 얹는다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
text_clf = make_pipeline(TfidfVectorizer(),
LogisticRegression(max_iter=2000))
5-4. 데이터가 작거나 중간 규모인데 경계가 복잡해 보일 때
- 추천:
SVM/SVR - 이유: 마진 최대화 + 커널로 복잡한 경계를 잘 그린다.
- 주의: 스케일링 필수, 데이터가 매우 크면 속도가 느릴 수 있다.
5-5. 아주 작은 데이터로 시작할 때
- 추천:
로지스틱/릿지같은 선형 + 정규화 또는k-NN - 이유: 단순 모델이 과적합을 덜 일으키고 해석이 쉽다.
- 팁: 교차검증으로 불안정성을 줄인다.
5-6. 아주 큰 데이터 또는 특성이 복잡(이미지/음성/시계열 등)할 때
- 추천:
신경망(딥러닝)- 이미지: CNN, 텍스트: 트랜스포머/사전학습 언어모델, 시계열: 1D-CNN·RNN·트랜스포머
- 이유: 표현력이 크고 복잡한 패턴을 학습한다.
- 주의: 데이터/연산량/튜닝 비용이 크다. 탭울러에서는 트리 앙상블이 종종 더 낫다.
5-7. 불균형 분류(양성이 아주 적음)
- 모델은 그대로 쓰되 학습·평가를 바꾼다.
class_weight='balanced'또는 리샘플링(SMOTE/언더샘플링)- PR-AUC / F1 / 재현율 중심 평가
- 임계값 조정으로 경보 민감도 튜닝
임계값 조정 예시:
from sklearn.metrics import precision_recall_curve
# y_prob = model.predict_proba(X_valid)[:,1]
prec, rec, thr = precision_recall_curve(y_valid, y_prob)
# 재현율 0.85 이상인 최소 임계값 찾기
import numpy as np
t = thr[np.argmax(rec[:-1] >= 0.85)]
y_pred = (y_prob >= t).astype(int)
5-8. 한 눈에 보는 결론
1) 정답 형태를 본다
- 라벨이면 → 분류, 숫자면 → 회귀
2) 데이터 형태를 본다
- 표 형태(숫자/범주 혼합) → 0단계 기준선 후, 성능이 더 필요하면 랜덤포레스트/부스팅
- 텍스트 → Tfidf + 로지스틱/선형 SVM/나이브 베이즈
- 이미지/음성/시계열 → 딥러닝 우선 고려
3) 데이터 크기·제약을 본다
- 작음 → 단순 모델(선형·kNN), 교차검증으로 점수 안정화
- 중간 → SVM/트리 앙상블
- 큼 → 부스팅/딥러닝
- 예측 속도 제약 큼 → 선형/작은 트리/지연 적은 모델
4) 레이블 불균형/비용 민감이면
- 지표(PR-AUC·F1)와 임계값 조정을 꼭 포함
5-9. 모델 선정 지표 7단계
1) 문제 정의(분류/회귀, 사업 목표 지표)
2) 데이터 분할(train/valid/test, 누수 금지)
3) 기준선 모델로 점수 확보(로지스틱/릿지)
4) 특징 엔지니어링(스케일링·인코딩·결측 처리)
5) 후보 모델 시도(랜덤포레스트/부스팅/SVM 등)
6) 하이퍼파라미터 탐색(RandomizedSearch → Grid)
7) 임계값·비용 민감도 조정, 최종 리포트/에러 분석
