1. SVM이란?
서포트 벡터 머신, 즉 SVM(Support Vector Machine)은 N차원 공간에서 각 클래스 간의 거리를 최대화하는 최적의 선 또는 초평면을 찾아 데이터를 분류하는 지도형 머신 러닝 알고리즘이다.
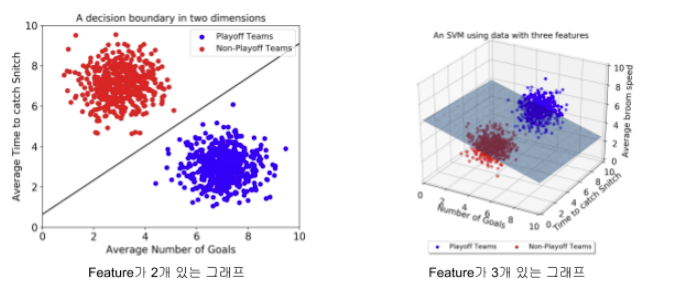
- 초평면(Hyperplane): 데이터를 나누는 기준 선(또는 면)으로, n차원 공간에서의 결정 경계를 의미한다.
- 마진(Margin): 초평면과 데이터 포인트(서포트 벡터) 간의 거리로, SVM은 마진을 최대화하는 초평면을 선택한다.
- 서포트 벡터(Support Vector): 결정 경계에 가장 가까운 데이터 포인트로, 마진을 결정하는 데 직접적으로 영향을 미친다.
- 커널 함수(Kernel Function): 선형 분리가 불가능한 경우 데이터를 고차원으로 변환하여 선형 분리를 가능하게 하는 함수이다.
- 선형 커널(Linear Kernel), 다항 커널(Polynomial Kernel), RBF 커널(Radial Basis Function) 등 다양한 커널이 존재한다.
1-1. 선형 SVM
선형 SVM은 데이터를 직선(또는 초평면)으로 나눌 수 있는 경우에 적용된다. 즉, 데이터가 선형적으로 구분 가능한 경우에 적합하다.
- 결정경계:
- 장점: 빠르고 튼튼하며 고차원(희소 텍스트 등)에 강하다
- 단점: 데이터가 선형적으로 분리되지 않는 경우 성능이 저하된다
- 전처리: 스케일링 필수(표준화), 편차 큰 특성이 마진을 왜곡하지 않도록 한다
- 특징:
- 데이터가 크면
LinearSVC(또는SGDClassifier(loss="hinge"))가 효율적 - 불균형 데이터는
class_weight="balanced"로 가중치를 자동 보정
- 데이터가 크면
예시(분류)
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
model = make_pipeline(StandardScaler(),
LinearSVC(C=1.0, loss="squared_hinge", class_weight="balanced", random_state=42))
model.fit(X_train, y_train)
1-2. 비선형 SVM
직선(평면)으로는 나누기 어려울 때, 커널 트릭으로 고차원에서 선형 분리를 구현해 비선형 경계를 만든다.
- 특징: 커널 함수는 원래 데이터 공간에서 계산하지 않고, 고차원 공간에서의 연산을 효율적으로 처리한다.
- 장점: 선형적으로 구분되지 않는 데이터를 잘 처리하며 다양한 커널 함수로 유연성이 높다
- 단점: 계산 비용이 높고 커널 및 하이퍼파라미터 선택이 중요하다
- 대표적인 커널 함수
- 다항 커널(Polynomial Kernel)
- RBF 커널(Radial Basis Function Kernel)
- 다항 커널(Polynomial Kernel)
예시(RBF 분류)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
rbf_svm = Pipeline([("scaler", StandardScaler()),
("svc", SVC(kernel="rbf", C=10, gamma="scale", class_weight="balanced"))])
rbf_svm.fit(X_train, y_train)
2. SVR (SVM 회귀)
SVM의 회귀 버전인 SVR은 예측 곡선 주변에 ε-무감 허용대(튜브) 를 두고, 그 튜브 밖의 점에만 벌점을 준다. 결과적으로 “마진이 넓은, 과도하게 굽지 않은” 함수가 된다.
-
ϵ-튜브(ϵ-Tube(epsilon tube)): 예측 값과 실제 값의 오차가 이내인 경우 패널티를 부여하지 않는다.
-
커널 트릭(Kernel Trick): SVR은 선형 관계 뿐만 아니라, 비선형 관계도 커널 함수를 사용하여 표현할 수 있다.
-
SVR는 다음 최적화 문제를 푼다
- 제약 조건:
- 제약 조건:
예시(SVR)
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
svr = make_pipeline(StandardScaler(),
SVR(kernel="rbf", C=10, epsilon=0.1, gamma="scale"))
svr.fit(X_train, y_train)
3. 커널(kernel)이란?
커널(Kernel)은 SVM(Support Vector Machine)에서 비선형 데이터를 고차원 공간으로 변환하여 선형적으로 분리 가능하게 만드는 방법이다. 커널 함수는 입력 데이터를 더 높은 차원의 특징 공간으로 매핑(mapping)하여, SVM이 복잡한 데이터의 패턴을 학습할 수 있게 해준다.
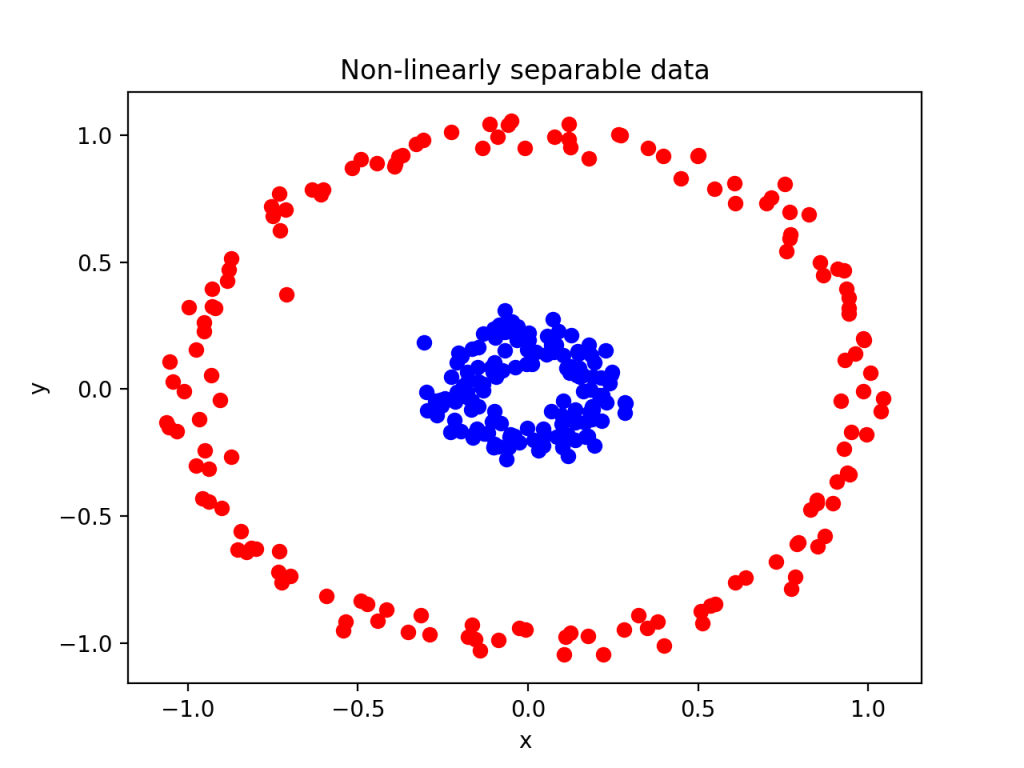
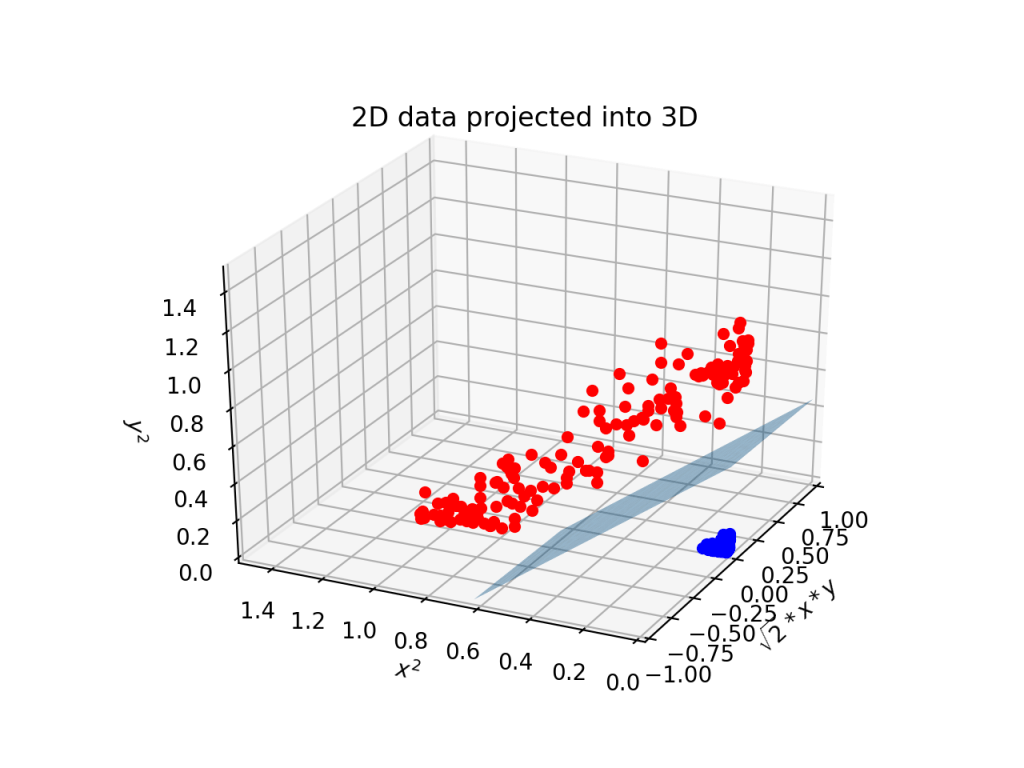
이미지 출처: https://roytravel.tistory.com/90
→ SVM의 핵심은 두 클래스를 최대한 잘 구분할 수 있는 초평면(hyperplane)을 찾는 것이며, 커널 함수를 통해 이 작업을 고차원에서도 수행할 수 있게 된다.
3-1. 커널이 필요한 이유
- 많은 경우 데이터는 선형적으로 분리할 수 없는 형태로 분포되어 있다. 즉, 2차원 공간에서 직선을 이용해 구분할 수 없는 경우가 많다.
- 커널 함수를 사용하면, 고차원으로 데이터를 변환하여 선형적으로 분리 가능하게 만든다. 이를 통해 더 복잡한 데이터 구조를 효과적으로 처리할 수 있다.
- 이 변환을 직접 계산하지 않고, 커널 트릭(Kernel Trick)을 사용해 효율적으로 계산할 수 있다.
3-2. 커널 트릭(Kernel Trick)
- 커널 트릭은 특징 공간으로의 변환을 직접 계산하지 않고, 커널 함수의 결과만 사용하여 마치 변환한 것처럼 처리하는 방법이다.
- SVM에서 입력 벡터의 내적만 계산하면 되기 때문에, 커널 함수를 사용하여 복잡한 계산을 효율적으로 수행할 수 있다. 이를 통해 고차원 변환을 일일이 수행하지 않아도 된다.
3-3. 주요 커널 함수 종류
1) 선형 커널(Linear Kernel): kernel="linear"
- 단순히 선형 모델을 의미하며, 커널 함수가 두 벡터의 내적을 계산한다.
- 데이터가 선형적으로 분리 가능한 경우에 적합하다.
2) 다항 커널(Polynomial Kernel): kernel="poly"
- 데이터의 비선형 관계를 다항식을 통해 표현할 때 사용된다.
3) RBF 커널(Radial Basis Function Kernel, 가우시안 커널): kernel="rbf"
- 가장 널리 사용되는 커널로, 데이터가 선형적으로 분리되지 않을 때 거리 기반의 유사성을 측정하는 방법이다.
- 데이터가 복잡한 비선형 관계를 가질 때 적합하다.
4)시그모이드 커널(Sigmoid Kernel): kernel="sigmoid"
- 신경망의 활성화 함수와 유사한 형태를 가지며, 뉴럴 네트워크와의 유사성을 기반으로 한다.
마무리 요약
- SVM이란? 마진을 최대화하는 경계 기반 모델이다.
- 선형 SVM: 빠르고 해석 가능, 큰 데이터에 적합하다.
- 비선형 SVM: 커널로 복잡한 결정경계를 학습(RBF가 표준 선택)한다.
- SVM 회귀(SVR): ε-무감 손실로 매끄러운 예측 곡선을 만든다.
- 커널: 고차원 내적을 유사도 함수로 대체하는 트릭—비선형 학습의 핵심이다.
참고 자료
IBM: https://www.ibm.com
블로그, For a better world: https://roytravel.tistory.com/90
