What is Ensemble Learning?, 출처: https://encord.com
1. 앙상블
여러 약한/강한 학습기의 예측을 결합하여 단일 모델보다 일반화 성능을 높이는 기법이다. 서로 다른 관점을 가진 모델들을 다양화(variance↓)하거나, 체계적으로 보정(bias↓)해 성능을 끌어올린다.
1-1. 투표 기반 분류기
여러 분류기의 출력을 투표로 합쳐 최종 클래스를 결정한다. 종류는 아래와 같다.
- 하드 보팅(Hard voting): 각 모델의 최빈값 클래스를 선택한다. 간단·견고하다.
- 소프트 보팅(Soft voting): 각 모델의 클래스 확률을 평균(가중 평균)하여 확률이 가장 큰 클래스를 선택한다. 보통 하드보다 성능이 좋다(확률을 이용하므로 정보 손실이 적다).
- 가중 투표: 더 신뢰하는 모델에 가중치를 높게 준다(예: 검증 성능 비례).
1-2. 베깅과 페이스팅
- 베깅(Bagging): 학습 데이터를 부트스트랩(복원추출) 하여 여러 묶음을 만들고, 각 묶음으로 개별 모델을 학습한다 → 분산 감소·OOB 평가 가능.
- 페이스팅(Pasting): 복원 없이 샘플링한다. 중복이 없어 데이터가 넓게 쓰인다.
- 공통: 예측은 평균(회귀) 또는 투표(분류) 로 집계한다.
1-3. 랜덤 패치 & 랜덤 서브스페이스
샘플뿐 아니라 특성(feature) 도 샘플링하여 추가로 다양화한다.
- 랜덤 패치(Random Patches): 샘플 + 특성을 동시에 서브샘플링(둘 다 일부만 사용).
- 랜덤 서브스페이스(Random Subspaces): 특성만 서브샘플링(샘플은 전체 사용).
- 결정트리와 잘 맞는다. 트리 분할이 서로 상관되지 않게 만들어 앙상블 이득을 키운다.
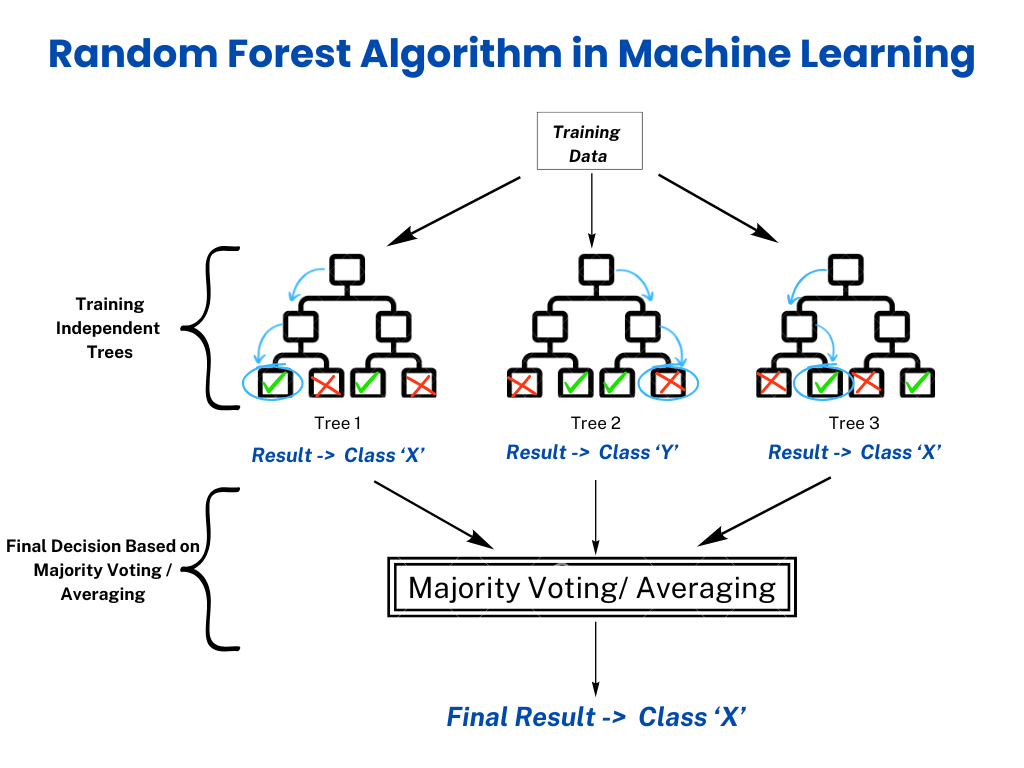
2. 랜덤 포레스트
많은 결정트리를 베깅으로 학습하되, 각 분할에서 사용할 특성도 무작위로 제한하는 앙상블이다. 트리 간 상관을 낮춰 분산을 크게 줄이는 것이 핵심이다.
Random Forest Algorithm in Machine Learning, 출처: https://www.sitepoint.com
- 학습: 각 트리는 부트스트랩된 데이터로 학습하며, 노드 분할 시 후보 특성을
max_features개로 무작위 제한한다(분류 기본=√p, 회귀 기본=p). - 예측: 분류는 다수결, 회귀는 평균.
2-1. 장/단점
장점
- 강력한 기본기: 탭울러 데이터에서 기본선 대비 높은 성능과 안정성.
- 전처리 부담 적음: 스케일에 둔감, 비선형/상호작용 자동 학습.
- 특성 중요도 제공: 불순도 기반/퍼뮤테이션 기반 중요도 모두 활용 가능.
- OOB 점수로 별도 검증 세트 없이도 대략적 성능 추정 가능.
단점
- 설명력 제한: 단일 트리보다 해석이 어렵다(개별 규칙 불투명).
- 메모리·예측 시간 증가: 트리 수가 많으면 리소스 비용↑.
- 많은 희소 고차원 텍스트/선형 문제에선 선형 모델이 더 효율적일 수 있음.
- 매우 긴 꼬리분포/희귀 이벤트는 부스팅이 더 잘 맞는 경우가 많다.
다른 앙상블과 비교
- 부스팅(Adaboost, XGBoost 등)은 직렬로 이전 오차를 보정해 바이어스↓에 강한 반면, 랜덤포레스트는 병렬 베깅으로 분산↓에 강한 편이다.
즉, 랜덤포레스트는 “여러 무작위화된 트리의 집단지성”으로 성능을 끌어올리는 대표적 앙상블 모델이다.
2-2. 예시 코드
# scikit-learn 예시 (분류)
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.inspection import permutation_importance
import pandas as pd
# 1) 데이터
X, y = make_classification(n_samples=8000, n_features=20, n_informative=8,
n_redundant=4, class_sep=1.2, random_state=42)
X_tr, X_te, y_tr, y_te = train_test_split(X, y, stratify=y, test_size=0.2, random_state=42)
# 2) 모델: OOB 점수로 대략 평가, 트리 깊이/수 최소 규제
rf = RandomForestClassifier(
n_estimators=400,
max_depth=None, # 필요 시 10~30 등으로 제한
min_samples_leaf=2, # 노이즈 분할 억제
max_features="sqrt", # 분류 권장값
oob_score=True,
n_jobs=-1,
random_state=42
)
rf.fit(X_tr, y_tr)
print("OOB score:", rf.oob_score_)
print("Test score:", rf.score(X_te, y_te))
print(classification_report(y_te, rf.predict(X_te), digits=3))
# 3) 중요도
imp_impurity = pd.Series(rf.feature_importances_).sort_values(ascending=False)
print("Impurity-based top5:\n", imp_impurity.head())
perm = permutation_importance(rf, X_te, y_te, n_repeats=10, random_state=42, n_jobs=-1)
imp_perm = pd.Series(perm.importances_mean).sort_values(ascending=False)
print("Permutation-based top5:\n", imp_perm.head())
- 데이터 크면
n_estimators를 충분히 크게(수백)하고,min_samples_leaf(또는min_samples_split)로 과적합을 1차 제어. - 불균형 분류는
class_weight="balanced"또는 표본 전략 조합. - 속도 이슈 땐 ExtraTrees(완전 무작위 분할)로 대체하면 빠르고 분산이 더 줄어드는 경향.
3. 부스팅(Boosting)
여러 약한 학습기를 직렬로 학습하여 앞선 모델의 오류를 다음 모델이 보완하도록 하는 방법(가중 재학습). 바이어스↓ 효과가 크다.
- 효과: 바이어스를 줄이고 복잡한 패턴을 잡는다.
- 위험: 단계가 너무 많거나 학습률이 크면 과적합된다 → 학습률(shrinkage), 얕은 트리 깊이, 조기 종료(early stopping) 로 제어한다.
3-1. 대표적 알고리즘
- AdaBoost: 오분류 샘플에 가중치를 높여 다음 약학습기가 집중하도록 한다(보통 얕은 트리 사용).
- Gradient Boosting: 현재 예측의 잔차(기울기) 를 다음 트리가 근사하며 누적 개선한다.
GradientBoosting*,HistGradientBoosting*(대용량 효율), 외부 라이브러리 XGBoost/LightGBM/CatBoost 가 실무 표준.
- 특징: 학습률(learning_rate) 과 트리 깊이(보통 3~8)로 복잡도를 통제, 강력하지만 튜닝 필요.
4. 스태킹(Stacking)
서로 다른 종류의 모델들을 수평으로 학습하고, 그들의 예측값을 입력으로 하는 메타 모델이 최종 결합을 학습하는 방법.
- 1단계(base): 로지스틱, 랜덤포레스트, SVM, 부스팅 등 다양하게 학습.
- 2단계(meta): 1단계의 교차검증 OOF 예측을 특징으로 사용하여 누수 없이 메타 모델(예: 로지스틱/GBM)을 학습.
- 장점: 서로 다른 편향을 가진 학습기를 조합해 안정적인 개선을 기대.
- 주의: 데이터 누수 방지(OOF 생성), 지나친 복잡화 지양.
# 간단 예시: scikit-learn StackingClassifier
from sklearn.ensemble import StackingClassifier, RandomForestClassifier, HistGradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
base_estimators = [
("rf", RandomForestClassifier(n_estimators=300, random_state=42)),
("hgb", HistGradientBoostingClassifier(random_state=42)),
("svm", SVC(probability=True, random_state=42))
]
stack = StackingClassifier(
estimators=base_estimators,
final_estimator=LogisticRegression(max_iter=200),
n_jobs=-1,
passthrough=False # True로 하면 원본 특징도 메타에 함께 사용
)
stack.fit(X_tr, y_tr)
print("Stacking test score:", stack.score(X_te, y_te))
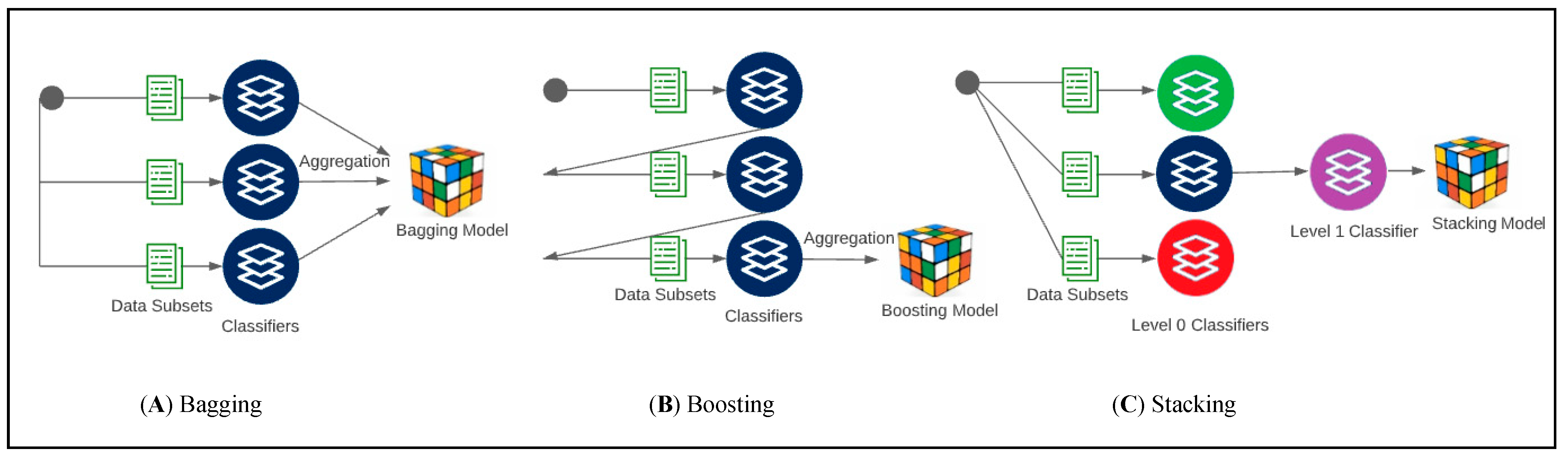
5. 배깅 vs 부스팅 vs 스태킹
출처: https://www.mdpi.com
| 관점 | 배깅(Bagging) | 부스팅(Boosting) | 스태킹(Stacking) |
|---|---|---|---|
| 학습 흐름 | 병렬로 여러 모델을 독립 학습 | 직렬(순차)로 이전 오류를 보정 | 수평 결합 + 메타 학습(2단계) |
| 다양성 원천 | 데이터 부트스트랩 샘플링(복원추출), 경우에 따라 특성 서브샘플 | 단계마다 가중치/잔차에 초점 | 서로 다른 유형의 모델을 혼합 |
| 결합 방식 | 평균(회귀) / 다수결(분류) | 가중 합(누적 개선) | 1단계 예측을 메타 모델이 학습해 결합 |
| 편향/분산 영향 | 분산↓(안정화) | 바이어스↓(정확도 향상) | 모델 간 보완으로 추가 이득 |
| 대표 알고리즘 | Random Forest, BaggingRegressor | AdaBoost, Gradient Boosting, XGBoost/LightGBM/CatBoost | StackingClassifier/Regressor(메타: 로지스틱/GBM 등) |
| 장점 | 튜닝 쉬움, 전처리 부담 적음, 안정적 | 탭형 데이터에서 강력한 성능 | 이질 모델 조합으로 추가 개선 가능 |
| 주의 | 트리 수↑→비용↑ | 학습률/트리깊이/트리 수 튜닝, 과적합·조기종료 | OOF 예측로 데이터 누수 방지, 파이프라인 복잡 |
- 분산을 낮춰 안정화 된, 빠르고 안정적인 → 배깅(랜덤포레스트)
- 바이어스를 낮춰 정밀화 된, 최대한의 성능(특히 표 형식 데이터) → 부스팅(GBM/XGB/LGBM/CatBoost)
- 이질 모델을 메타 학습으로 최적 결합, 서로 성격 다른 모델을 섞어 한 단계 더 UP! → 스태킹(OOF 필수)
마무리 요약
- 앙상블은 다양화·보정으로 단일 모델 한계를 넘어선다.
- 랜덤포레스트는 트리 다수를 무작위화해 분산을 줄이는 안정성 높은 앙상블 기본 선택지이다.
- 부스팅은 직렬 보정으로 강력한 성능을 내지만 튜닝·과적합 관리가 필요하다.
- 스태킹은 이기종 모델을 메타 모델로 결합해 추가 이득을 노린다.

기록은 기억을 지배한다.