
개요
평화롭던 강의 기간은 끝나고 첫 level1 기초 대회(STS)가 마무리 되었다. 2주 간의 짧은 기간동안 진행된 리더보드 형 대회로 많은 걸들을 배운 기간이였다. 배운 것들을 문서화해서 정리하는 것이 무엇보다 중요하단 말을 듣고 빠르게 달려왔다.

남는게 참 많은 대회였던 것 같다. 부끄럽지만 VScode를 제대로 써먹은 것도 처음이고(전까진 ipynb 파일 하나로 모든 처리를 다했었다) 코드를 모듈화해 CLI 환경에서 작동시킨다거나 ssh 서버를 받아와서 구동한다거나 wandb로 실험관리를 한다거나... 모든 발걸음이 처음이라 새로운 것을 배운다는 설렘으로 가득찬 2주 였다!
첫 기초 대회의 주제는 STS, Semantic Textual Similarity로 두 문장 간 의미적 유사도를 0~5점 사이의 실수로 예측하는 task였다. 구조적으론 다르지만 의미가 유사한 것들을 기계가 판단할 수 있게 만들어 인간의 문장 교정 작업을 돕거나 QA 시스템과 같은 자연어 task의 품질을 높이는데 광범위하게 사용된다.
대회의 시작과 끝, 그리고 지금까지도 운영진과 멘토님들이 강조하시는 '순위가 아닌 문제 정의와 실험'의 관점에서 임하려 노력했고, 그에 따라 많은 가설과 실험을 진행했다. 어떤 모델을 사용했는지, 어떤 학습 결과가 점수가 잘 나오는지에 집중하기 보다,
- 주어진 데이터를 보고 정의하는 유사도란 무엇인가?
- 잘 예측하지 못하는 example을 개선하기 위한 가설을 세우고 검증
- 많은 실험, 그리고 많은 실험
에 가능한! 집중하기 위해 노력했다. 따라서 전반적인 프로젝트를 주루룩 설명하기 보단 내가 어떤 도전, 실험들을 했는지를 중점으로 다루고자 한다.
프로젝트 환경
1. 프로젝트 전체 구조도
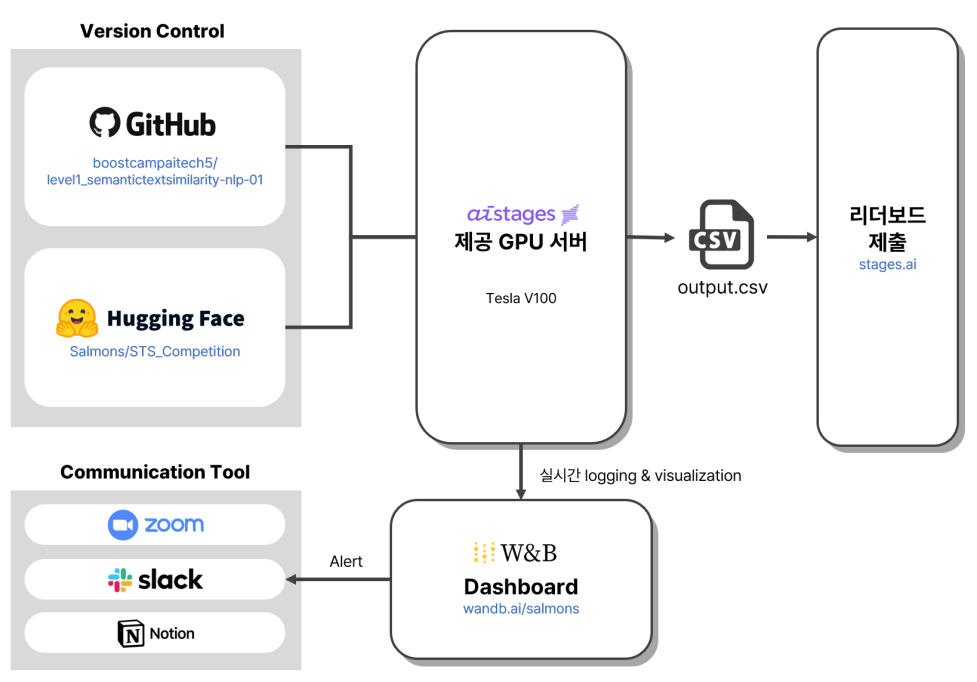
팀원이 이쁘게 만들어준 우리 프로젝트의 전체 구조도이다. AIStages에서 제공하는 Tesla v100 GPU를 사용했고 OS는 Ubuntu가 docker container 형태로 제공되었다. 사실 리눅스 명령어로 관리하는 것도 처음이라 마냥 신기했다!
2. github
- 깃허브 repo를 파서 pytorch lightning으로 이루어진 baseline code를 모듈화해서 저장했다.
- 각자 실험은 브랜치를 파서 한 후 main에 합칠만한 내용이면 merge하는 방식을 썼다.
3. 협업 툴
- Slack : 현재 나의 상황, 진척 정도 등을 공유하고 실험 실행을 logging 했다.
- Notion : 전체 프로젝트 일정 관리, 실험 관리, 의견 공유, 문서화 작업을 했다.
- Zoom : daily scrum을 통해 개발 과정을 공유했다.
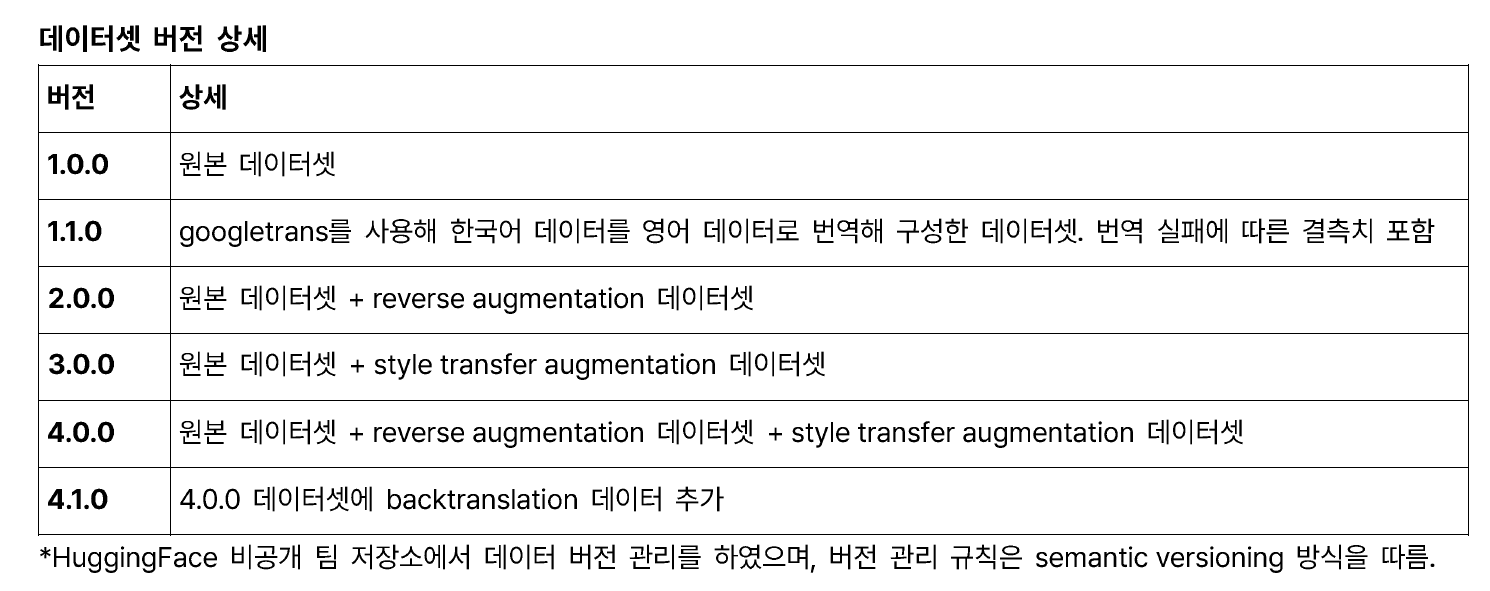
4. 실험 및 버전 관리
- Weight&Biases : 각 실험의 그래프 시각화, 하이퍼파라미터 튜닝을 진행했다. 팀 레포를 파서 project 별로 개인의 실험을 저장했다.

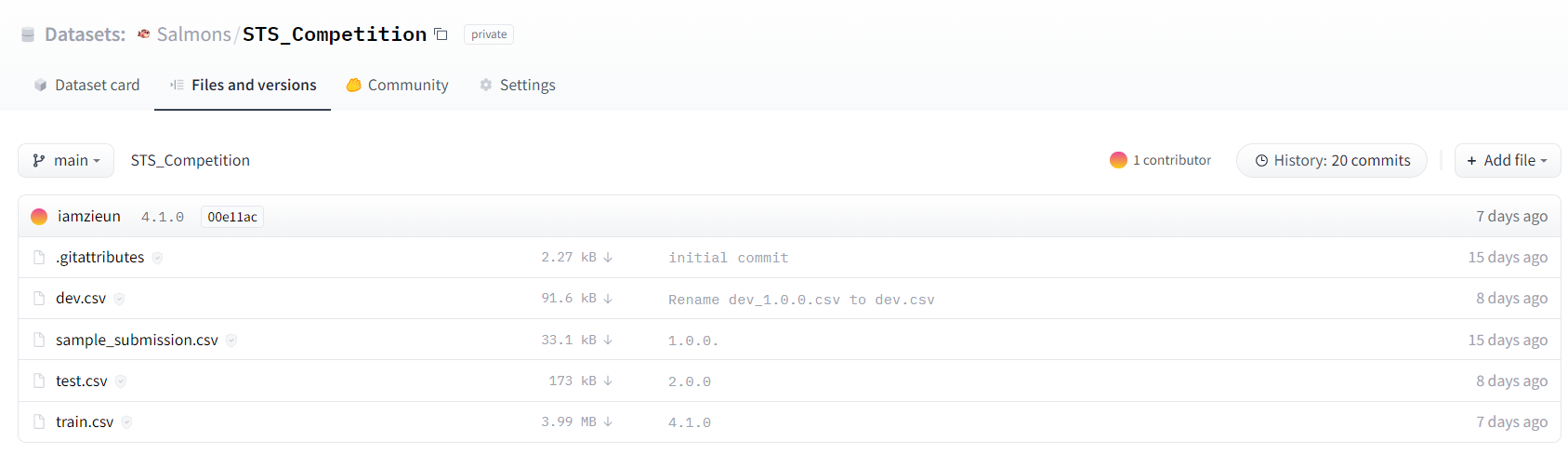
- HuggingFace Datasets : huggingface가 제공하는 dataset 기능을 이용해 데이터 버전을 관리했다. 기본적인 전처리는 모듈 내에서 진행하고 data augmentation 결과를 버전 별로 구분해서 실험의 편리함을 더했다.
분석 과정
이번 대회는 리더보드형 대회였지만 순위보단 데이터를 보고 두 문장의 유사도가 어떤 것인질 정의하고 가설을 세워 논리적인 실험을 하는 것에 중점을 두었다. 물론 계획했던 것만큼 잘된 것은 아니지만 그저 점수 올리기 위한 무지성 실험은 지양하고 논리적인 가설과 검증을 거친 경험은 앞으로의 지속적인 성장에도 상당한 도움이 되지 않을까 생각한다.
1. 유사도 정의
결론부터 얘기하자면 잘 정의되지 않았다.... 어떤 task를 다루던 가장 중요한 문제 정의!
대회의 시작 점에선 '데이터 엄청 뜯어보고 유사도를 확실히 정의해야지' 라는 의지로 불탔으나 꽤 많은 강의들과 베이스라인 코드 모듈화작업이 겹치면서 금요일이 되서야 제대로 데이터를 보게되었고 언제나 그랬듯 계획은 수정되었다..
그래도 데이터를 쭉 둘러보며 이 문장 쌍은 왜 5점인지, 이 친구들은 왜 1점인지, 무슨 차이가 있길래 점수가 다른건지 유사도가 어떻게 생겨먹은 친군지 확인해봤다.

명사에 높은 attention..?
label 값이 높은 두 문장은 그냥 보기에도 거의 비슷한데 형태나 단어만 조금씩 달랐다. 문제는 값이 낮은 문장들이고 이 친구들이 왜 낮은질 알아봐야 했다.
| idx | sentence 1 | sentence 2 | label |
|---|---|---|---|
| 1 | 다음 밥스테이지가 기대됩니다~ ㅎ | 다음 후기도 기대됩니다~~ | 1.4 |
| 2 | 좀 신박하긴한데 마마가 날뛸때 웃으면서 봄 | 좀 지루할지도 모르지만 난 딱 이정도로 봤다 | 0 |
| 3 | 대통령님, 저희 모녀 좀 도와주세요 | 대통령님, 저희 스킨푸드 좀 꼭! 살려주세요. | 0.6 |
-
다음, 기대됩니다~ 까지 거의 동일하나 명사인 밥스테이지, 후기가 다르다.
- 단순히 두 문장의 단어들이 얼마나 일치하느냐가 유사도로 사용되었다면 1.4보단 높게 나왔을 것이다. -
좀, 봄, 보다와 같은 유사성을 보이나 라벨은 0이다.
- 직접 읽어보면 그래도 0은 아닌것 같은 느낌이 있는데 매몰차다.
- 신박하다 ↔ 지루하다 에서 갈린 것 같다.
- 명사와 형용사들에 attention이 많이 들어간게 아닌가라는 생각이 든다. -
거의 문장 구조가 비슷하나 모녀와 스킨푸드가 좀 다르고, 도와주세요와 살려주세요가 의미적으로 다르나 방향성은 유사하다고 보인다.
- 그러나 라벨은 0.6이다. 여기서도 명사가 달라졌다.
- 이는 사람이 라벨링 할 때 핵심내용이 동등하지 않음을 모녀와 스킨푸드에서 확인했기 때문이다.
높은 label의 특성
| idx | sentence 1 | sentence 2 | label |
|---|---|---|---|
| 1 | 이국종교수님 지원해주세요 | 이국종 교수님을 지원해주세요 | 5 |
| 2 | 다들 환영해주셔서 감사합니다. | 다들 환영해주셔서 감사합니다 | 5 |
| 3 | 다음에 또 뵐게요~~ | 다음에 또 뵐게요~~~ | 5 |
| 4 | 청소년보호법 개정해주세요 | 청소년 보호법 개정해주세요 | 5 |
| 5 | 문재인 대통님게 청원합니다 | 문제인 대통령님깨 청원합니다 | 5 |
| 6 | 조두순 출소반대!! | 조두순 출소반대!!!!! | 5 |
| 7 | 외상센터지원해주세요 | 외상센터 지원해주세요 | 5 |
- 대부분 정말 사소한 차이에서 드러난다.
- 띄어쓰기 한 번, 온 점 한번, 특수기호 한 번
- 앞의 전처리가 가능하겠다는 생각이 든다.
- 대부분 잘 예측하나(roberta-large epoch10 기준) 특히 못한 두 개를 보면,
- 단어 자체가 잘못 적혀있거나 조사가 잘못된 경우
- ;ㅁ; 과 같이 이상한 글자들이 경우가 있다.
- 전처리로 맞춤법 교정이나 ㅋ,ㅁ,ㅎ,과 같이 의미없이 덩그러니 있는 자음, 모음같은 것을 제거해주는 작업을 해주면 더 잘 예측하지 않을까 싶다.
기타..
한글 <-> 영어 유의어를 잘 잡아내지 못한다거나 포함관계에 있는 문장들은 낮게 예측하는 등 베이스라인이 잘 못맞추는 예제들을 뜯어보며 모델이 궁극적으로 예측하고자 하는 유사도가 무엇인지를 알아보는 과정들을 거쳤다.
하지만 이런 결과들을 실험과 모델에 직접 녹여내는 과정이 부족했다고 생각한다. 앞의 명사 attention의 경우 토크나이징을 통해 각 문장의 주된 명사에 special token으로 추가적인 embedding을 준다거나 하는 방법들이 제안되었으나 구현력의 한계로 실행되지 못했다. 열심히 분석해서 얻은 인사이트를 모델링에 녹여내는 훈련을 다음 대회부턴 잘해봐야겠다고 생각했다.
2. 전처리
실험 과정속에서 특수문자, 같은 문자 반복, 영문, 이모티콘 포함 데이터에 대한 예측 성능이 좋지 않음을 확인했다.
- 한글과 숫자, 일부 특수문자(? , ; : ^)를 제외한 나머지 문자를 제거했다.
- 이모티콘 역하를 하는 ㅋ,ㅎ,ㅠ 등을 제거했다.
- 연속된 특수문자는 1개 문자로, 연속된 문자는 2개로 치환했다.
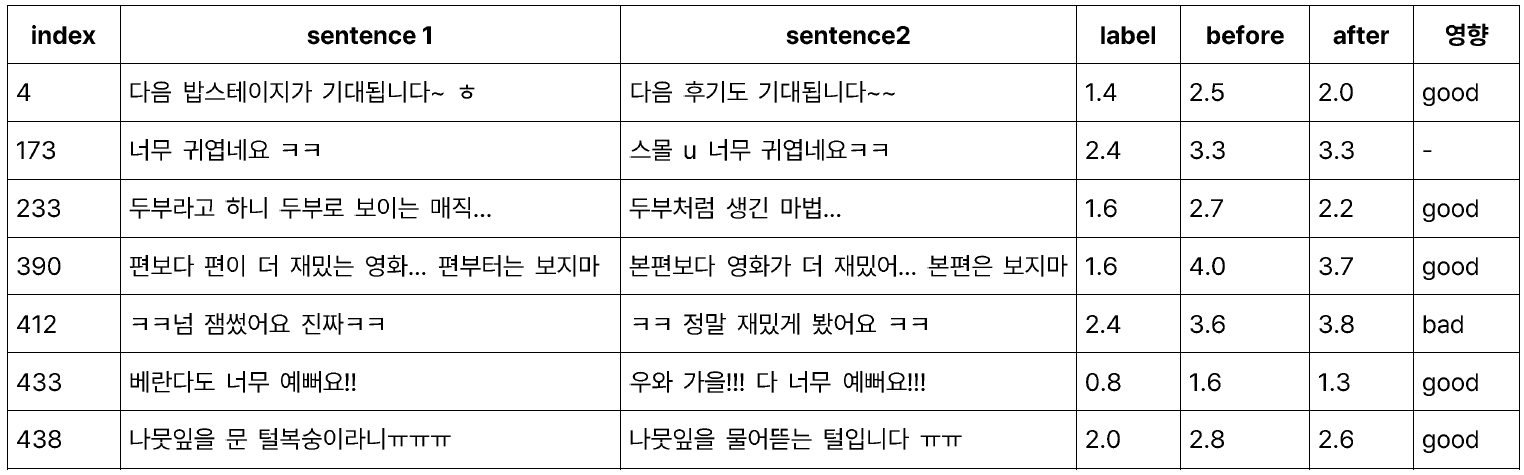
위 도표는 base model의 valid dataset에 대한 inference 결과물로 분석한 내용이다. 전처리하기 전보다 후의 성능, 즉 개선시키고자 한 example들의 score가 좋아졌음을 확인했고, 나머지 example들에 대한 성능도 유지되는 모습을 보여 최종적으로 선정하게 되었다.
3. 데이터 증강
이번 대회의 아픈 손가락 중 하나다. class imbalance(0 데이터가 너무 많음)를 극복하기 위해서 시도했다. 팀원들이 다양한 형태의 증강을 해주시고 huggingface datasets로 버전 관리까지 했지만 실제 모델의 성능에 큰 영향을 주진 못했다. 증강에 있어서 간과한 사실은 다음과 같다.
- 증강된 데이터의 수가 적지 않아 라벨이 잘 유지가 되게 증강되었는지 확인하기 힘들었다.
- upsampling이나 reverse augmentation(문장 순서만 바꾸기)와 같은 안전한 증강 기법만 활용해서 증강하는 방법도 고려해보아야 했다.
- 증강 처리엔 생각보다 많은 시간이 필요하다..!
무엇보다 데이터를 건드는 쪽이 성능에 가장 큰 영향을 끼칠 수 있음에도 적절한 검증절차 없이 그냥 사용한 점이 문제였던 것 같다.
4. 모델링
총 세 가지 버전의 모델(klue/roberta-large, snunlp/KR-ELECTRA-discriminator, Bi-directional GRU layer adding)을 실험했으며 총 4개 output을 hard voting해서 최종 제출하였다. 최종 제출까지의 과정은 다음과 같다.
- 각 모델의 성능을 어느정도 보장해주는 수준(>
LB 0.915)의 하이퍼파라미터 조합을 찾는다. (validation data 예측결과를 사후분석한 결과, valid pearson, valid loss 확인) - 데이터 증강, 전처리, 다양한 모델링 기법에 대한 가설을 세우고 적용해보며 평가지표, 사후분석을 통해 적용시킬지를 결정한다.
- WandB sweep을 통한 하이퍼파라미터 튜닝을 진행 후 적절한 파라미터 조합을 찾는다.
- 찾은 조합으로 모델 학습 후 결과를 hard voting해서 제출한다.
1) klue/roberta-large
- 한국어 벤치마크 데이터셋인 klue로 pre training시킨 모델로 대회 베이스라인보다 모델의 크기가 크다. 대회 task에 사전학습 모델이 base로 어느 수준으로 나오는지 확인하기 위해 사용하였다.
- base모델에 비해 LB 기준 0.02의 성능향상(
LB 0.896)을 보였지만 사후분석 결과 일관성있는 예측을 보여주지 않고 불안정한 모습을 보여 최종적으론 기각했다. - CuDA OOM 문제가 있어서 mixed precision training을 활용해 학습시켰다.
2) snunlp/KR-ELECTRA-discriminator
- https://github.com/snunlp/KR-ELECTRA
ELECTRA를 34GB의 한국어 데이터(위키피디아, 뉴스, 댓글, 리뷰 등)으로 pre training하여 discriminator를 뽑아온 모델이다.RoBERTa에 비해 가볍고 빠르며, 교체된 토큰을 구별해내는 MLMtask를 학습한ELECTRA의 특징 상 문맥 정보를 더 잘 파악할 것이라고 생각했다. RoBERTa는 mask된 토큰의 하위 집합에서만 학습하는데 비해ELECTRA는 모든 입력 토큰을 사용하기 때문이다.- 전반적인 성능이
klue/roberta-large에 비해 좋았고 사후분석 결과의 경향성도 안정적이였으며, 여러 실험 중 바뀌지 않길 원하는 부분에 대한 예측결과도 일관성있게 유지되는 장점이 있었다.- ex. 특수문자 및 의성어 자음(ㅋㅋ,ㅎㅎ)을 제거한 실험 결과 제거한 example들의 예측능력이 향상함과 동시에 제거하지 않은 sample들의 성능도 유지되었다.
- 단일 모델 학습 기준으로 가장 높은 성능(
LB 0.9215)을 보였다. - 다음은 valid data의 예측결과로 전체적으로 후하게 예측하고 있음을 알 수 있다.
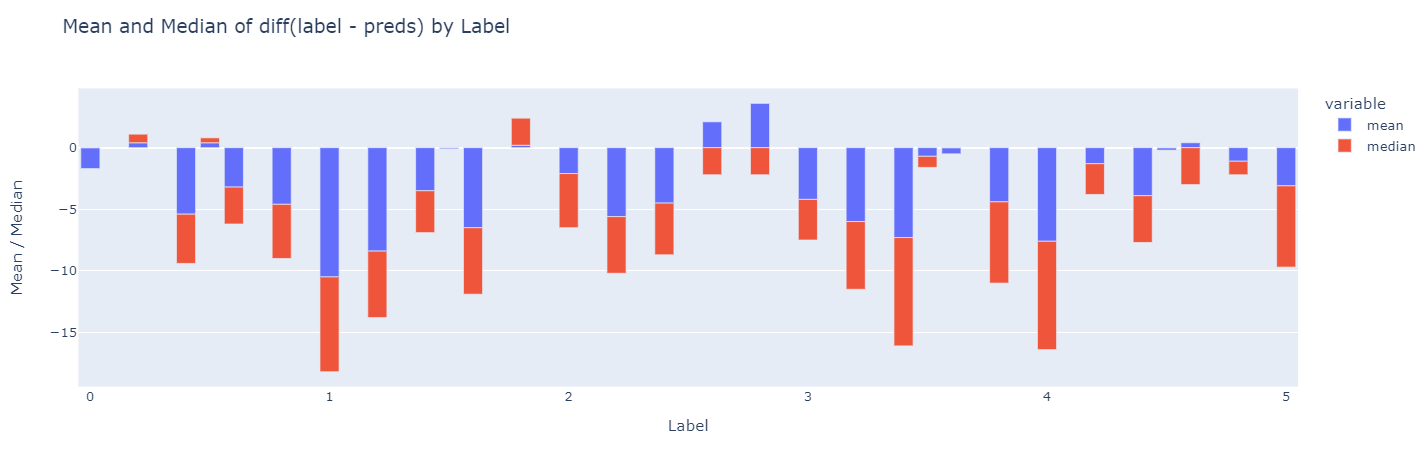
3) Bi-directional GRU adding
ELECTRA가 사전 학습에 사용한 데이터의 분포, 형태가 대회 데이터셋과 다르기 때문에 문맥적 유사도를 세세히 예측해내는데 어려움이 있을거라 판단하였다. 양방향 layer를 추가하여 의미론적 유사도와 문맥정보의 복잡한 연관성을 파악하고자 했다.- 앞의 electra 모델의 output hidden layer 2개를 가져와
Bi-directional GRU모델의 input으로 넣고tanh activation,dropout,linear layer를 추가해 학습시켰다. - 기본 ELECTRA 모델보다 학습이 더 안정적이고 valid loss 역시 안정적임을 확인했다.
- LB기준으로 성능은
0.9188정도로 향상이 이루어지진 않았지만 다른 경향성을 보여주고 있어 앙상블에 포함시켰다. - private score 공개 이후엔 적용시키기 전보다 후가 일반화 성능에 있어 훨씬 뛰어난 점을 확인하며 꽤 괜찮은 모델링 이였음을 확인했다..!
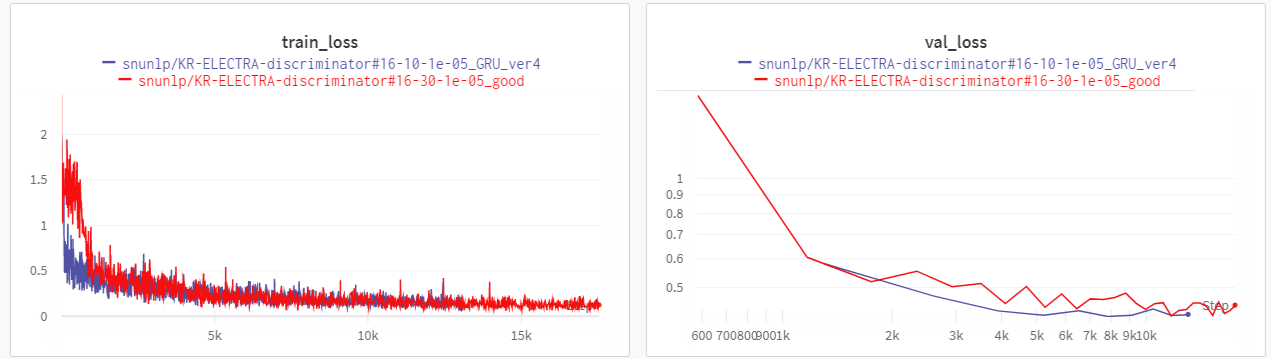
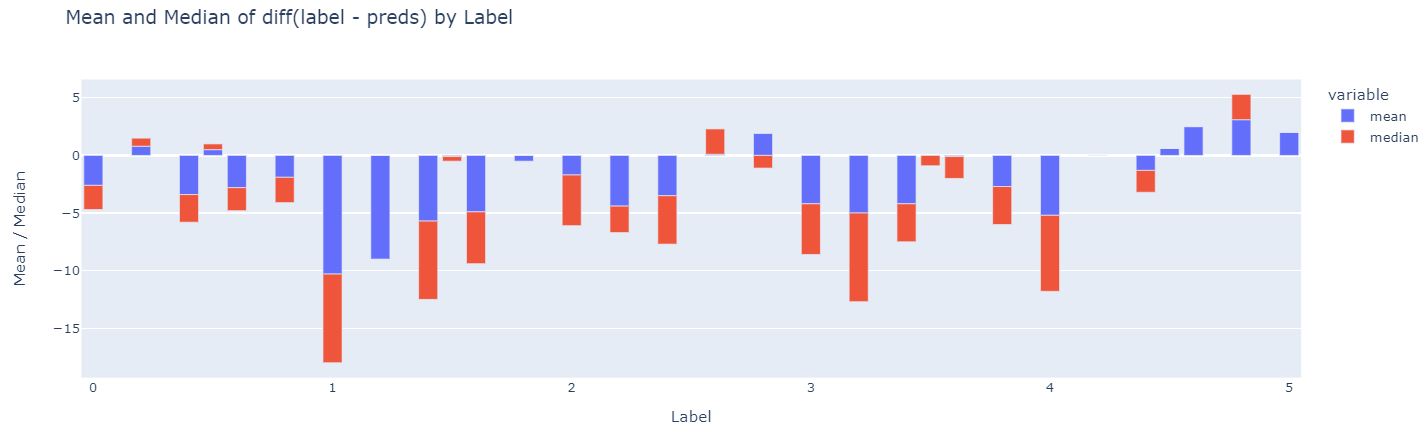
4) k-fold 교차 검증
- 원본 데이터에 0인 라벨이 특히 많았던 class imbalance를 확인하였고, 크게 두 가지 방법으로 나누어 k-fold 교차 검증 실험을 해보았다.
- 나눠져있던 train.csv와 dev.csv를 합치고 0.8 비율로 학습 및 검증 데이터셋을 위한 종합 데이터셋(total set)을 구성한 뒤 k-fold 교차 검증을 적용하였다.
→ train, dev, test의 분포가 같아지게 하는 가정이 포함되어 있어 기각했다. - train.csv에 대해서만 교차 검증을 적용하였다.
- 나눠져있던 train.csv와 dev.csv를 합치고 0.8 비율로 학습 및 검증 데이터셋을 위한 종합 데이터셋(total set)을 구성한 뒤 k-fold 교차 검증을 적용하였다.
5) data ensemble model
- 증강한 데이터에 대해 독립적으로 실험을 진행한 모델들을 ensemble하였다.
- 원본 train 데이터로만 학습한
snunlp/KR-ELECTRA-discriminator - 원본 train 데이터와 원본 train 데이터에서 label이 0인 데이터를 제외한 나머지 데이터를 reverse augmentation한 데이터로 학습한
snunlp/KR-ELECTRA-discriminator - 원본 train 데이터와 원본 train 데이터의 sentence_1을 style transfer augmentation한 데이터로 학습한
snunlp/KR-ELECTRA-discriminator
- 원본 train 데이터로만 학습한
- 위 세 모델로부터의 inference 결과의 평균을 구하는 방식으로 최종적인 inference를 진행하였다.
6) hyperparameter tuning
WandB sweep을 통해 앙상블 예정인 각 모델들의 하이퍼파라미터 튜닝을 진행했다.lr,epochs,batch size,loss function,optimizer의 조합을 찾았고,Smoothl1loss의 경우 beta값에 대한 조정도 추가되었다.- 기존 실험들에서 활용한 기본 데이터에 증강된 데이터를 합쳐서 tuning을 진행했으나 학습 결과가 좋지 않은 모델의 경우 최종적으로는 제외하고 기본 데이터에서 전처리를 마친 버전을 사용하였다.
7) ensemble
snunlp ELECTRA단일 모델,Bi-directional GRU,data ansemble,kfold4개의 모델 output의 평균을 구해 최종적인 결과를 제출하였다. weighted sum역시 시도해봤으나 큰 차이가 없었다.- 성능과 함께 valid data를 통한 예측분포가 가능한 다양하게 반영될 수 있도록 loss function, optimizer, 데이터버전의 조합을 선택하여 최종결과를 도출했다. 최대한 일반화 성능이 좋아질 수 있는 전략을 세웠다.
- 앙상블 결과 최고성능을 달성했다.
public: 0.9245 /private: 0.9313
결론

팀원들과의 첫 팀 프로젝트 치곤 나쁘지 않았다고 생각한다. 꽤 많은 강의와 초반 여러 초기 환경설정(코드 모듈화 작업, 협업 방식 정리 및 적응, 서버 셋팅 등..)에서 애를 먹어서 그렇지 기존에 대회에 임하던 자세와 다르게 이유 있는 모델링을 하기 위한 노력들이 많았다.
실험을 설계에 있어 가설을 수립한 후 이유 있는 실험을 진행하며 논리적으로 발전시켜 나갔고 가설 검증을 위해 validation output을 직접 뜯어보고 비교분석했다. 깃허브와 깃, huggingface datasets를 통한 코드 및 데이터의 버전 컨트롤을 했으며 WandB와 inference 이후 사후분석을 통해 실험 결과에 대한 객관적인 분석을 진행한 점들은 잘한 것 같다.
몇가지 아쉬웠던 점은, 처음에 얘기했던 유사도를 명확히 정의하고 이를 기준으로 모델링이 이루어지지 않았단 것이다. 가장 중요한 문제 정의, 즉 유사도 정의가 되지 않는 모델링은 반 쪽짜리 라고 생각한다. 이는 다음 프로젝트에서 반드시 개선되어야할 사안이다.
또한 다른 팀들과 우리와의 큰 차이점이 있다면 test predict의 분포를 분석에 사용했느냐 그러지 않았느냐의 차이였다. 사후 분석을 위해 valid predict를 사용했으나 정작 test prediction들의 분포가 어떻게 나오는지를 지표로 삼지 않았던 점이 아쉬웠다. 다른 팀들의 발표를 들으면서 정말 다양한 접근법이 있고 배울 점이 많았던 것 같다.
이제 남은 기간은 대회와 프로젝트의 연속이다. 좋은 날은 다갔다...
문서화해서 기록해놓는 것이 무엇보다 중요하단 말을 들어서 이젠 대부분 다 기록할 생각이다. 다음 포스팅은 STS 대회서 학습시킨 모델을 streamlit으로 웹에 배포하는 내용이 될 것 같다. 완주하는 그날까지.. 화이팅..!!
