
🟪 빅오 표기법이 필요한 이유
'알고리즘 수행에 필요한 단계 수'가 알고리즘의 효율성을 결정하는 주된 요인이다.
그러나 단순히 알고리즘을 "22단계의 알고리즘", "400단계의 알고리즘" 이라고 표시할 수는 없다. 이 단계 수라는 것을 하나의 수로 확정지을 수 없기 때문이다.
예를 들어 선형 검색에는 배열의 원소 개수 만큼 단계 수가 필요하다. 그래서 원소가 4개일 땐 4단계가, 100개일 땐 100단계가 필요하므로 그때 그때 마다 달라지는 것이다.
이러한 선형 검색의 효율성을 '배열에 N개의 원소가 있을 때 N단계가 필요하다'라고 표현하는 것이 몇 단계로 정량화 하는 것보다 훨씬 효과적이다.
컴퓨터 과학자는 시간 복잡도를 쉽게 소통할 목적으로 자료 구조와 알고리즘의 효율성을 간결하고 일관된 언어로 설명하기 위해 수학적 개념을 차용했다.
이러한 개념을 형식화한 표현을 빅 오 표기법이라고 부른다.
빅 오 표기법을 사용해 주어진 알고리즘의 효율성을 쉽게 분류할 수 있다.
빅 오 표기법을 알면 일관되고 간결한 방법으로 어떤 알고리즘이든 분석할 수 있는 도구가 생긴 것이다.
🟪 🌟빅 오의 본질🌟

🔶 데이터 원소 N개에 대한 알고리즘의 단계 수를 의미한다.
빅 오 : 데이터 원소가 N개일 때 알고리즘에 몇 단계가 필요할까?
↳ 빅 오 표기법의 핵심질문이자 정의이다 !
핵심 질문에 대한 답은 빅 오 표현의 괄호 안에 들어있다.O(N)은 알고리즘에 N 단계가 필요하다는 핵심 질문에 대한 답을 나타낸다.
❗빅 오는 데이터 원소가 N개일 대 알고리즘에 몇 단계가 필요한가에 대한 답이다. 데이터 원소 N개에 대한 알고리즘의 단계 수를 나타낸다.
🔶 데이터가 늘어날 때 단계 수가 어떻게 증가하는가를 의미한다.
🔵 O(3) == O(100) == O(1)
데이터가 몇 개든 항상 3단계가 걸리는 알고리즘을 가정하자.
즉 원소가 N개일 때 알고리즘에 항상 3단계가 필요하다.
이를 빅 오로 어떻게 표현할까?O(3)일까? 아니다. O(1)이다.
이유는 빅오가 알고리즘에 필요한 단계 수를 알려주는 것 말고도 한 가지 더 역할을 한다는 것에 있다.
빅 오는 단순히 알고리즘에 필요한 단계 수 뿐만 아니라, ❗데이터가 늘어날 때 알고리즘의 단계 수가 어떻게 증가하는지, 성능이 어떻게 바뀌는지도 설명한다.
이러한 관점에서 보면 알고리즘이 O(1)이든 O(3)이든 별로 중요하지 않다.
O(1)과 O(3) 두 알고리즘 모두 데이터 증가에 영향을 받지 않는, 즉 단계 수가 변하지 않는 유형이므로 본질적으로 같은 알고리즘 유형이다. N이 얼마든 항상 상수 단계만 필요하다. 그래서 O(1) 알고리즘을 상수시간constant time을 갖는 알고리즘이라고도 표현한다.
둘 다 데이터에 관계없이 단계 수가 일정한 알고리즘이므로 둘을 구분할 필요가 없다.
🔵 O(1)과 O(N)에서 데이터 변화가 미치는 영향
O(1)이 데이터 증가 또는 감소에 영향을 받지 않는 반면 O(N) 알고리즘은 데이터 증가가 성능에 영향을 미친다. 데이터가 늘어날 때 정확히 그 데이터에 비례해 단계 수가 증가하는 알고리즘 유형이다. 알고리즘의 효율성과 데이터가 비례 관계이다. 데이터가 증가할 때 단계 수가 정확히 어떻게 증가하는지 설명한다.
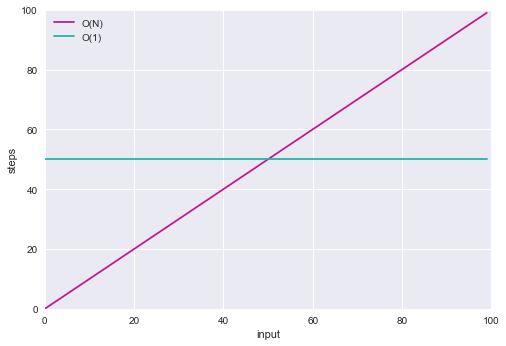
🔵 O(1) & O(N) 그래프
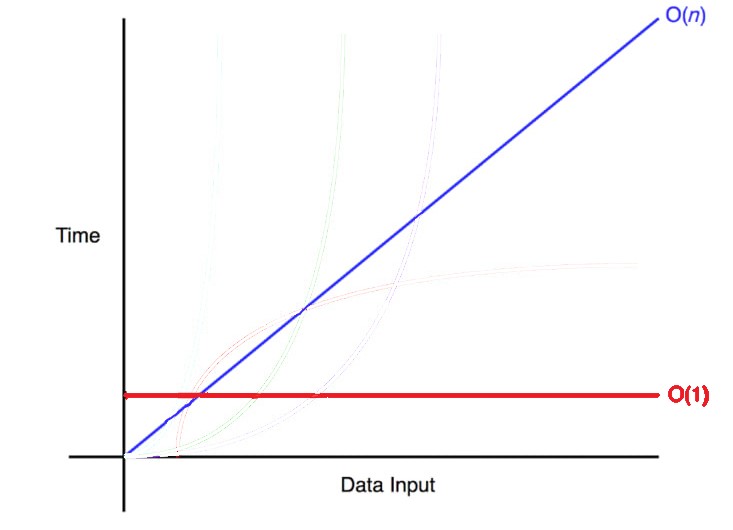
O(N)은 완벽한 대각선을 그린다. 데이터가 하나씩 추가될 때마다 알고리즘이 한 단계씩 더 걸리기 때문이다. 따라서 데이터가 많아질수록 알고리즘에 필요한 단계 수도 늘어난다.
O(1)은 완벽한 수평선을 그린다. 데이터의 증가나 감소에 영향 받지 않고 단계 수가 일정하다.
🔵 O(1)알고리즘이 항상 O(N)보다 빠를까 ?
데이터 크기에 상관없이 항상 100단계가 걸리는 상수 시간 알고리즘이 있다면?
이 알고리즘이 O(N) 알고리즘보다 성능이 우수한가?
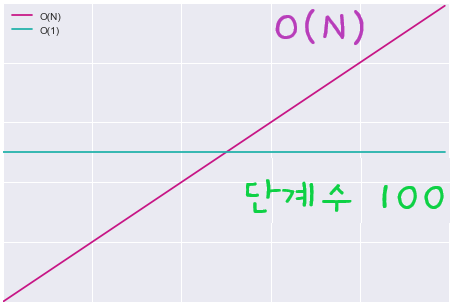
원소가 100개 이하인 데이터 세트에서는 100단계가 걸리는 O(1) 알고리즘보다 O(N) 알고리즘이 단계 수가 더 적다.
두 선이 교차하는 원소가 정확히 100개인 지점에서는 두 알고리즘의 단계 수가 동일하게 100단계이다.
100보다 큰 모든 배열에서는 O(N) 알고리즘이 100단계 O(1) 알고리즘보다 항상 더 많은 단계가 걸린다. 이것이 핵심이다.
변화가 생기는 일정량의 데이터가 있을 것이고 O(N)은 그 순간부터 무한대까지 더 많은 단계가 걸리므로 O(1) 알고리즘에 실제로 몇 단계가 걸리든 O(N)이 전반적으로 O(1)보다 덜 효율적이라 볼 수 있다.
🔶 최악의 시나리오를 의미한다.
선형 검색이 항상 O(N)은 아니다.
검색값이 배열의 맨 처음에 있는 최선의 시나리오에서는 O(1)이고
검색값이 배열의 맨 끝에 있는 최악의 시나리오에서는 O(N)이다.
빅 오 표기법은 일반적으로 최악의 시나리오를 의미한다.
"비관적인" 접근이 유용한 도구일 수 있기 때문이다.
최악의 시나리오에서 알고리즘이 얼마나 비효율적인지 정확히 알면 최악을 대비함과 동시에 알고리즘의 선택에 중요한 영향을 미칠 수 있기 때문이다.
🟪 O(N)
데이터 원소가 N개일 때 N단계가 걸리는 알고리즘이다.
데이터가 늘어날 때 정확히 그 데이터에 비례해 단계 수가 증가하는 알고리즘이다.
선형검색 알고리즘을 빅 오로 표현해보자.
< 빅 오 표기법으로 시간 복잡도를 표현하는 사고 과정 >
-
핵심 질문 : 배열에 원소가 N개일 때 선형 검색에 몇 단계가 필요할까?
-
정답 : 배열에 N개의 원소가 있을 때 선형 검색에 N단계가 필요하다.
-
표현 : O(N) - "빅 오 N", "차수 N", "오 N"이라고 부른다.
🟪 O(1) : 상수시간
데이터 원소가 N개와 상관없이 항상 일정한 상수 갯수의 단계 수만 걸리는 알고리즘이다.
데이터 증가에 영향을 받지 않는 알고리즘이다.
배열에서 읽기의 효율성을 빅 오로 표현해보자.
< 빅 오 표기법으로 시간 복잡도를 표현하는 사고 과정 >
-
핵심 질문 : 데이터 원소가 N개일 때 배열에서 읽기에 몇 단계가 필요할까?
-
정답 : 배열 읽기에 필요한 단계 수는 배열의 크기와 상관없이 딱 하나다.
-
표현 : O(1) - "오 1"
데이터 원소가 "N"개 일때 알고리즘에 필요한 단계 수를 질문했다.
이 질문은 N에 대한 물음이었으나 답은 N과 무관하다.
배열에 원소가 몇 개든 배열에서 읽기는 항상 한 단계면 된다.
N에 구애받지 않고 항상 1단계만 걸리므로 O(1)을 가장 빠른 알고리즘 유형으로 분류한다.
데이터가 늘어나도 알고리즘의 단계 수는 증가하지 않는다.
N이 얼마든 항상 상수 단계만 필요하다. 그래서 O(1) 알고리즘을 상수시간constant time을 갖는 알고리즘이라고도 표현한다.
🟪 로그 log 뜻
로그는 로가리즘logarithm의 줄임말이다.
❗로그log
- 지수
exponent와 역inverse의 관계다. - 2를 몇 번 곱해야 N이 나올까? =
log₂N - 1이 될 때까지 N을 2로 몇 번 곱해야 할까? =
log₂N
🔵 지수exponent와 역inverse의 관계다.
log₂8은 2³의 역converse 관계다.
log₂64은 2⁶의 역이다.
🔵 2를 몇 번 곱해야 N이 나올까?
2를 세 번 곱해야 8이 나오므로 log₂8 = 3이다.
2를 여섯 번 곱해야 8이 나오므로 log₂64 = 6이다.
🔵 1이 될 때까지 N을 2로 몇 번 곱해야 할까?
8 / 2 / 2 / 2 = 1
8이 1이 될 때까지 2를 세 번 나눠야 하므로 log₂8 = 3이다.
64 / 2 / 2 / 2 / 2 / 2 / 2 = 1
64가 1이 될 때까지 2를 여섯 번 나눠야 하므로 log₂64 = 6이다.
🟪 O(logN) : 로그시간
🔶 O(logN) == O(log₂N)
컴퓨터 과학에서 O(logN)은 O(log₂N)을 줄여 부르는 말이다.
- 핵심 질문 : 데이터 원소가 N개 일 때 알고리즘에 몇 단계가 필요할까?
- 정답 : O(logN)은 데이터 원소가 N개 있을 때 알고리즘에 log₂단계가 걸린다.
원소가 8개면 log₂8 = 3이므로 이 알고리즘은 3단계가 걸린다.
이진 검색이 정확히 O(logN) 알고리즘 방식으로 동작한다.
이진 검색을 빅 오 표기법의 관점에서 어떻게 설명할까?
- 배열의 크기가 3일 때 이진 검색은 2단계
- 배열의 크기가 7일 때 이진 검색은 3단계
- 배열의 크기가 15일 때 이진 검색은 4단계
- 배열의 크기가 100일때 이진 검색은 7단계
- 배열의 크기가 10,000일때 이진 검색은 13단계
- 배열의 크기가 1,000,000일때 이진 검색은 20단계
데이터가 커질수록 단계 수가 늘어나므로 이진 검색은 O(1)이라 표현할 수 없다.
검색하고 있는 배열의 원소 수보다 단계 수가 훨씬 적으므로 O(N)이라 표현할 수도 없다.
이진 검색은 O(1)과 O(N)사이 어디쯤엔가 있다.
이것을 빅 오로 O(logN)으로 나타낸다.
그리고 오 로그 엔 이라고 부른다.
🔶 데이터가 두 배로 증가할 때마다 한 단계씩 늘어나는 알고리즘
❗O(logN) : 오 로그 N
- 로그시간
log time의 시간 복잡도 - 데이터 원소가 N개 있을 때 알고리즘에 log₂단계가 걸린다.
- 데이터가 두 배로 증가할 때마다 한 단계씩 늘어나는 알고리즘
이러한 유형의 알고리즘을 로그시간log time의 시간 복잡도라고 말한다. 이 말의 뜻은 빅오의 방법으로 O(logN)을 데이터가 두 배로 증가할 때마다 한 단계씩 늘어나는 알고리즘이라고 설명하는 것이다.
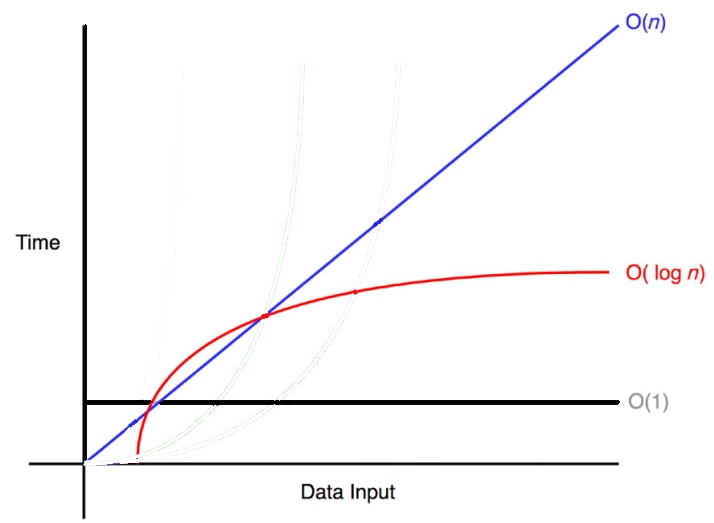
🟪 O(1) & O(N) & O(logN) 그래프
O(1) > O(logN) > O(N) 순으로 가장 효율적이다.
O(logN)은 아주 조금씩 증가하는 곡선을 그리고 있는데 O(1)보다는 덜 효율적이지만 O(N)보다는 훨씬 효율적이다.
🟪 연습문제
다음 알고리즘의 효율성을 빅 오 표기법으로 나타내라.
🔶 리스트 내 모든 항목을 출력함
public static void printThings() {
String[] things = {"apples", "chairs", "files", "notes"};
for (String thing : things)
System.out.printf("Here's a thing : %s \n", thing);
}이 알고리즘의 for루프에서 배열의 원소가 4개이기 때문에 4단계가 걸린다.
만약 배열의 원소가 10개이면 10단계가 걸릴 것이다.
for루프에 대입되는 배열의 원소 갯수만큼 단계가 걸리므로 이 알고리즘의 효율성은 O(N)이다.
🔶 주어진 수가 소수인지 알아봄
소수는 1보다 큰 자연수 중 1과 자기 자신만을 약수로 가지는 수다.
public static boolean isPrime(int number) {
if (number == 1) return false;
for (int i = 2; i < number; i++) {
if (number % i == 0)
return false;
}
return true;
}이 코드는 number를 인수로 받아 2부터 number-1까지의 모든 수로 number를 나눠서 나머지가 있는지 확인한다.
나머지가 없으면 이 수는 소수가 아니므로 바로 false를 반환한다.
모든 수로 나눴는데도 항상 나머지가 있으면 이 수는 소수이므로 true를 반환한다.
number가 1이면 당연히 소수가 아니므로 false를 반환한다.
핵심 질문 : number에 N을 전달할 때 알고리즘에 몇 단계가 필요한가?
↳ ( number가 함수 루프 실행 횟수를 좌우하기 때문에 N은 number이다. )
7을 number에 전달하면 for루프는 일곱단계를 실행한다.
(실제로는 2~6까지므로 다섯단계이다.)
101이면 루프는 101단계를 실행한다.
(실제로는 2~100까지므로 99단계이다.)
함수로 전달된 수에 비례해 단계 수가 증가하므로 O(N)알고리즘이다.
🔶 주어진 해가 윤년인지 알아봄
public static boolean isLeapYear(int year) {
return (year % 100 == 0) ? (year % 400 == 0) : (year % 4 == 0);
}N은 number이다.
함수로 전달된 수에 상관없이 단계 수가 일정하므로 O(1)알고리즘이다.
🔶 주어진 배열의 모든 수를 합함
public static int arraySum(int[] array) {
int sum = 0;
for (int num : array)
sum += num;
return sum;
}N은 배열의 원소 갯수다.
배열의 원소 갯수만큼 for루프가 실행되므로 O(N)알고리즘이다.
🔶 몇 번째 칸에 쌀을 놓아야 하는지 계산해줌
체스판 한 칸에 쌀 한톨을 놓는다.
두 번째 칸에는 이전 칸에 놓았던 쌀 양보다 두 배 더 많은 쌀 두 톨을 놓는다.
세 번째 칸에는 쌀 네 톨을 놓는다. (두 번째 칸 2)
네 번째 칸에 쌀 여덟 톨을 놓는다. (세 번째 칸 2)
다섯 번째 칸에 쌀 열여섯 톨을 놓는다. (네 번째 칸 * 2)
16을 함수에 전달하면 5를 반환한다.
public static int getChessboardSpace(int grains) {
int chessboardSpace = 1;
int placedGrains = 1;
while (placedGrains < grains) {
chessboardSpace++;
placedGrains *= 2;
}
return chessboardSpace;
}N은 함수에 전달된 grains이다.
grains = 256 이면 for루프는 9번 실행된다.
grains = 512 이면 for루프는 10번 실행된다.
grains = 1024 이면 for루프는 11번 실행된다.
grains가 두배로 늘어날 때 루프는 한 단계만 더 늘어나므로 O(logN)알고리즘이다.
🔶 문자열 배열을 받아 "a"로 시작하는 문자열만 포함시킨 새 배열을 반환함
public static String[] getAStringsArr(String[] array) {
ArrayList<String> aStringsArr = new ArrayList<String>();
for (int i = 0; i <array.length; i++) {
String firstChar = array[i].split("")[0];
if ("a".equals(firstChar))
aStringsArr.add(array[i]);
}
return aStringsArr.toArray(new String[aStringsArr.size()]);
}N은 함수에 전달된 배열의 원소 갯수이다.
전달된 배열의 원소 갯수만큼 for루프가 실행되므로 O(N)알고리즘이다.
🔶 정렬된 배열의 중앙값을 계산함.
public static int median(int[] array) {
int middle = array.length / 2;
if (array.length % 2 == 0)
return (array[middle-1] + array[middle]) / 2;
else
return array[middle];
}N은 함수에 전달된 배열의 길이이다.
전달된 배열의 길이가 얼마든 상관없이 한 단계면 중앙값이 계산되어 반환된다.
N이 얼마든 상관없이 정해진 단계수만 걸리므로 O(1)알고리즘이다.
🟦 출처
🔷 그림 1
벨로그 사이트의 welloff_jj님의 hyeojung.log블로그의 '복잡도(Complexity): 시간 복잡도와 공간 복잡도, 그리고 빅오(Big-O) 표기법' 게시물 보러가기
🔷 그림 2
Towards Data Science사이트의 Semi Koen의 The Big O Notation 게시물 보러가기
🔷 글의 내용
이 글 내용은 '제인 웬그로우'의 '누구나 자료구조와 알고리즘 개정 2판' 책을 100% 참고하여 작성하였습니다. 설명에 전문적인 용어보다는 일상적인 용어를 사용하고 그림으로 원리를 설명해주어 왕초보인 저가 이해하기에 아주 좋았습니다. 가격이 많이 나가는 편이지만 꼭 배워야 하는 내용이 모두 들어있고 그것을 제가 이해할 수 있는 수준으로 쓰여있어 전혀 아깝지 않은 소비였습니다.



잘 보고 갑니다!