1. 데이터
from tensorflow.keras import datasets
mnist = datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
X_train = X_train.reshape((60000, 28, 28, 1))
X_test = X_test.reshape((10000, 28, 28, 1))2. 모델
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(3, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(10, activation='softmax')
])3. 학습 전 conv layer의 웨이트의 평균 & 그래프
conv = model.layers[0]
conv_weight = conv.weights[0].numpy()
conv_weight.mean(), conv_weight.std()
import matplotlib.pyplot as plt
plt.hist(conv_weight.reshape(-1, 1))
plt.xlabel('weights')
plt.ylabel('count')
plt.show()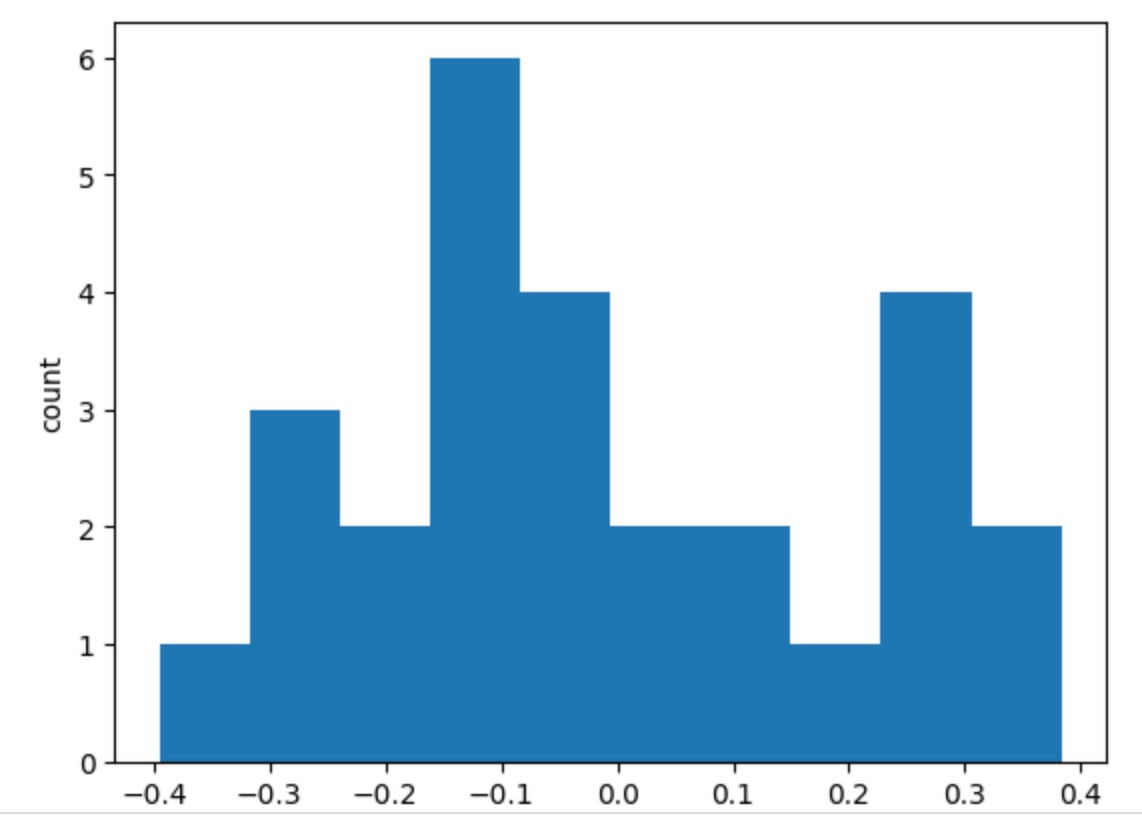
4. 학습 전 conv filter 확인
fig, ax = plt.subplots(1, 3, figsize=(15,5))
for i in range(3):
ax[i].imshow(conv_weight[:, :, 0, i], vmin=-0.5, vmax=0.5)
ax[i].axis('off')
plt.show()
5. 학습
import time
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
start_time = time.time()
hist = model.fit(X_train, y_train, epochs=5, verbose=1, validation_data=(X_test, y_test))
print('fit time: ', time.time() - start_time)6. 학습 후 conv filter의 변화
fig, ax = plt.subplots(1, 3, figsize=(15,5)) # 학습 후 conv filter의 변화
for i in range(3):
ax[i].imshow(conv_weight[:, :, 0, i], vmin=-0.5, vmax=0.5)
ax[i].axis('off')
plt.show()
7. draw_feature_map 함수
import tensorflow as tf
# Conv 레이어에서 출력
conv_layer_output = tf.keras.Model(model.input, model.layers[0].output)
def draw_feature_map(n):
inputs = X_train[n].reshape(-1, 28, 28, 1)
# 입력에 대한 feature map
feature_maps = conv_layer_output.predict(inputs)
fig, ax = plt.subplots(1, 3, figsize=(15,5))
ax[0].imshow(inputs[0, :, :, 0], cmap='gray');
for i in range(3):
ax[i].imshow(feature_maps[0,:,:,i])
ax[i].axis('off')
plt.show()
draw_feature_map(50)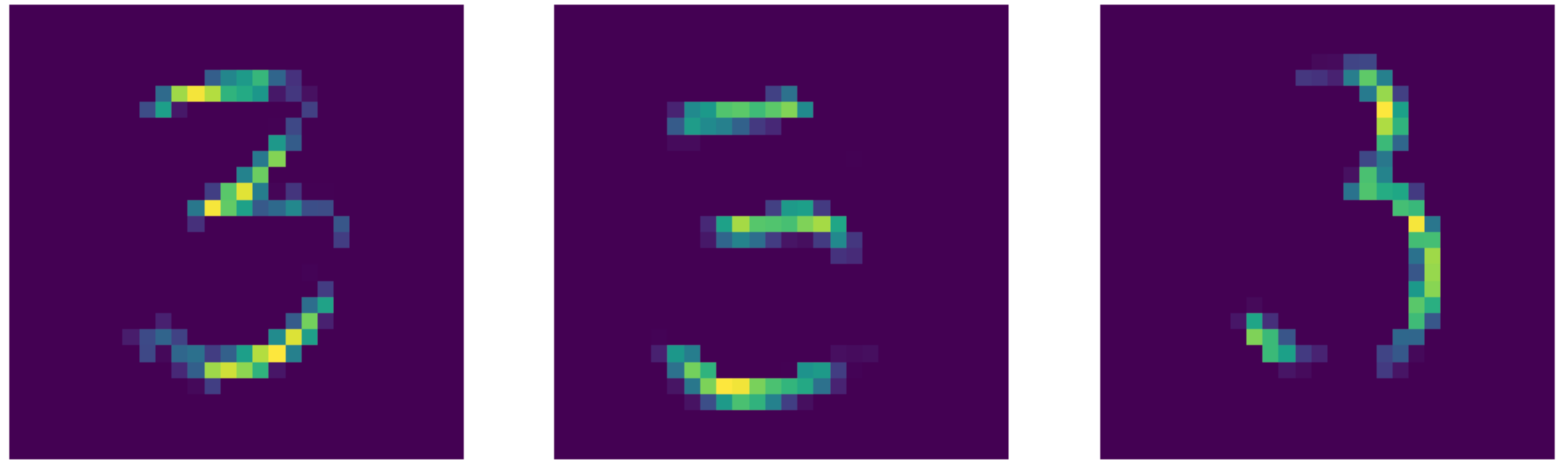
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it