1. 데이터 정리
from tensorflow.keras import datasets
mnist = datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
X_train = X_train.reshape((60000, 28, 28, 1))
X_test = X_test.reshape((10000, 28, 28, 1))2. 모델
from tensorflow.keras import layers, models
model = models.Sequential([
# 32개 특성, input_shape 차원 맞춰줌 28 * 28 * 32개의 layers -> (28, 28, 1)
layers.Conv2D(32, kernel_size=(5, 5), strides=(1, 1), padding='same', activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
# 줄였으니 특성을 더 잡기 64개 특성
layers.Conv2D(64, (2,2), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Dropout(0.25),
# 특성 모두 펼치기
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 32) 832
max_pooling2d (MaxPooling2D (None, 14, 14, 32) 0
)
conv2d_1 (Conv2D) (None, 14, 14, 64) 8256
max_pooling2d_1 (MaxPooling (None, 7, 7, 64) 0
2D)
dropout (Dropout) (None, 7, 7, 64) 0
flatten (Flatten) (None, 3136) 0
dense (Dense) (None, 1000) 3137000
dense_1 (Dense) (None, 10) 10010
=================================================================
Total params: 3,156,098
Trainable params: 3,156,098
Non-trainable params: 0
'''3. 훈련
import time
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
start_time = time.time()
hist = model.fit(X_train, y_train, epochs=5, verbose=1, validation_data=(X_test, y_test))
print('fit time: ', time.time() - start_time)4. 학습 결과
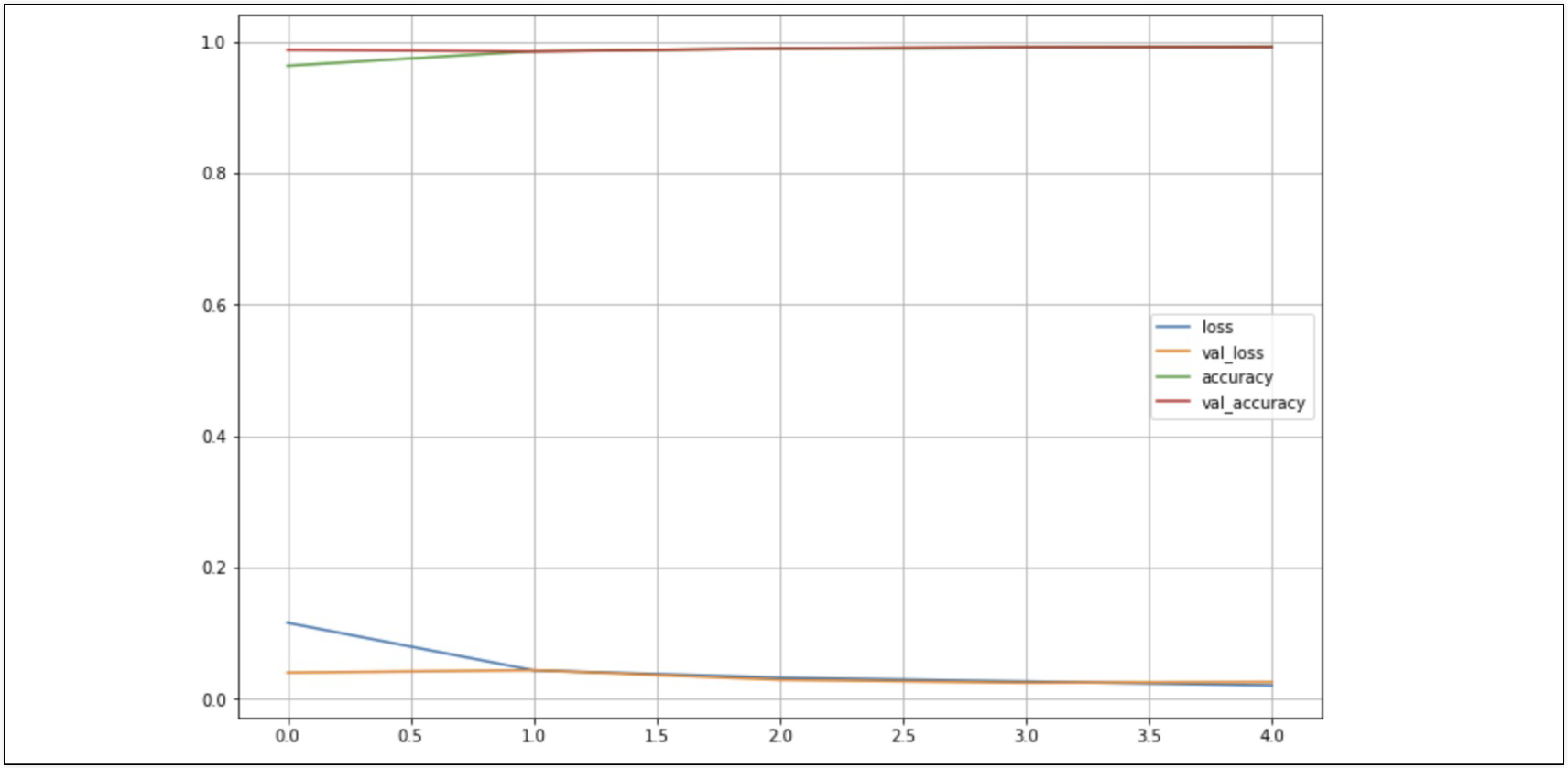
- 결과가 좋다
import matplotlib.pyplot as plt
%matplotlib inline
plot_target = ['loss', 'val_loss', 'accuracy', 'val_accuracy']
plt.figure(figsize=(12, 8))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()
score = model.evaluate(X_test, y_test)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
'''
313/313 [==============================] - 3s 11ms/step - loss: 0.0304 - accuracy: 0.9908
Test loss: 0.030372295528650284
Test accuracy: 0.9908000230789185
'''
5. 틀린 데이터
import numpy as np
import random
predicted_result = model.predict(X_test)
predicted_labels = np.argmax(predicted_result, axis=1)
worng_results = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
worng_results.append(n)
samples = random.sample(worng_results, 16)
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_test[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.title('Label: ' + str(y_test[n]) + 'Predict' + str(predicted_labels[n]))
plt.axis('off')
plt.show()
6. 모델 저장
model.save('/content/drive/MNIST_CNN_models.hs')Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it