MNIST 데이터(숫자)
1. Tensorflow에서 MNSIT 읽기
- 각 픽셀이 255값이 최댓값이어서 0~1사이의 값으로 조정 (일종의 min max scaler)
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.02. 모델
- one-hot-encoding →
loss='sparse_categorical_crossentropy'같은 효과
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])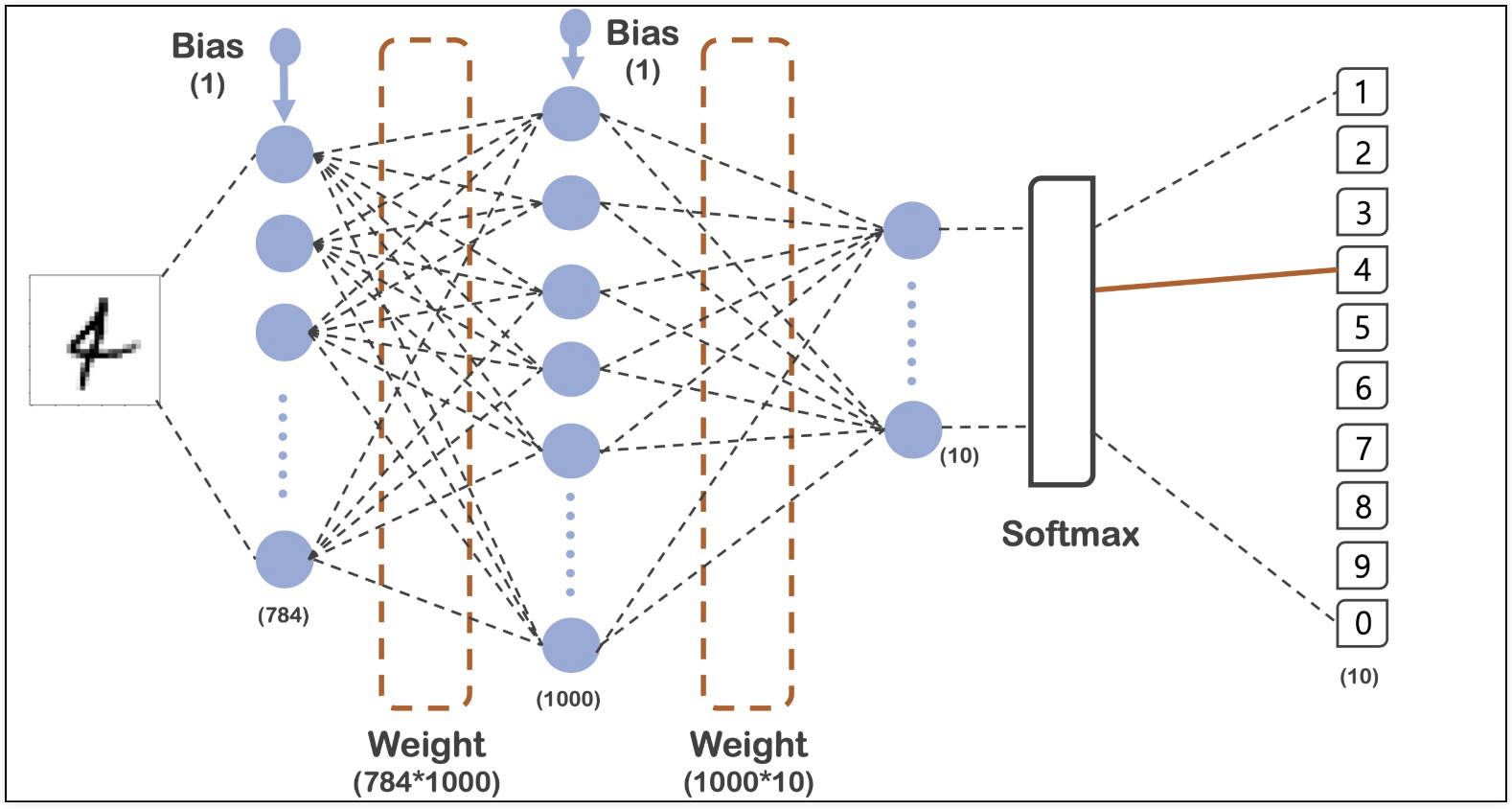
3. 학습
import time
start_time = time.time()
hist = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=100, verbose=1)
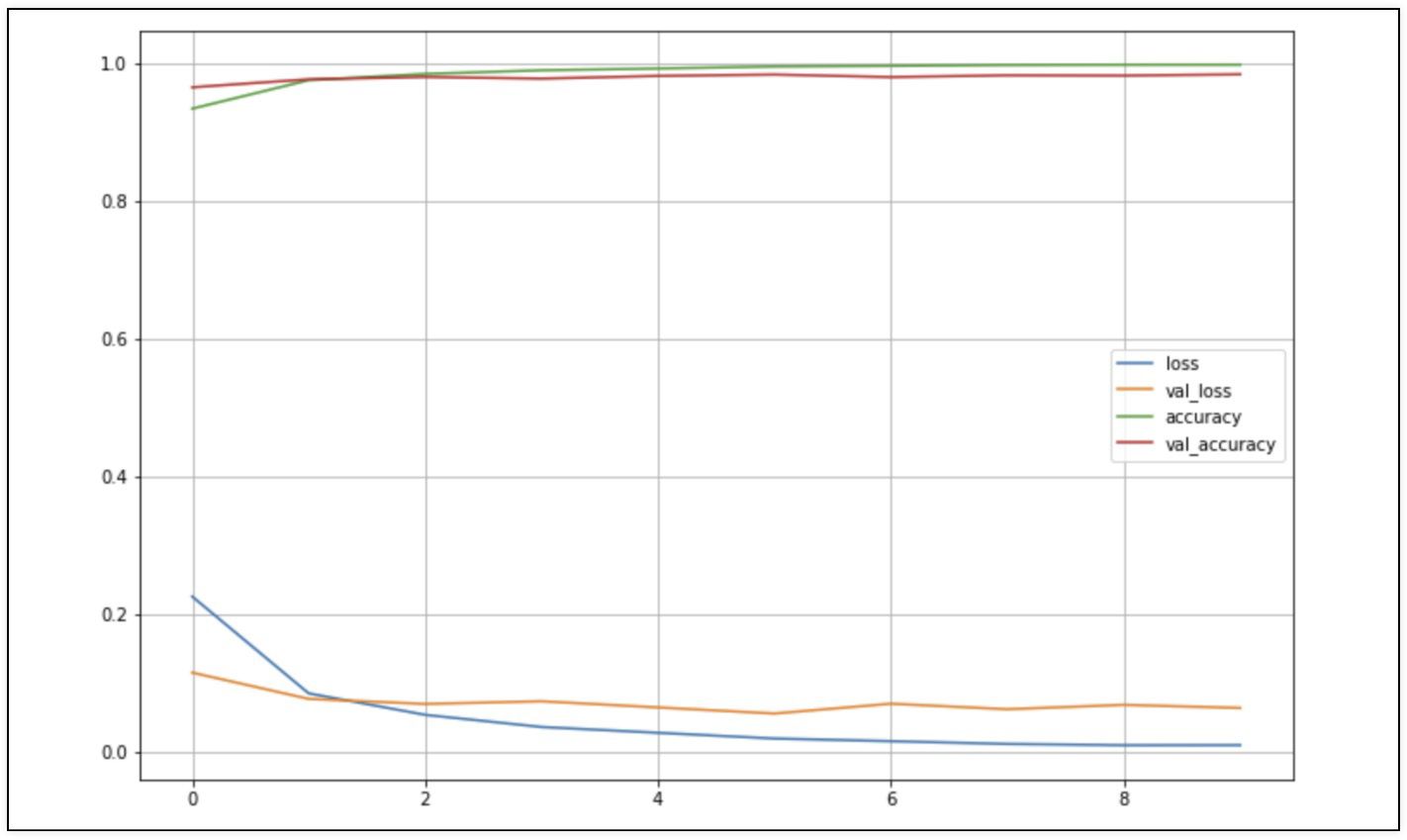
print('fit time: ', time.time() - start_time)4. acc와 loss 그래프 & score
- 머신러닝에서 93%쯤 나왔던 결과대비 5%쯤 향상되었다
import matplotlib.pyplot as plt
%matplotlib inline
plot_target = ['loss', 'val_loss', 'accuracy', 'val_accuracy']
plt.figure(figsize=(12, 8))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()
score = model.evaluate(X_test, y_test)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
'''
313/313 [==============================] - 3s 8ms/step - loss: 0.0683 - accuracy: 0.9826
Test loss: 0.06830286234617233
Test accuracy: 0.9825999736785889
'''
5. Worng result
# 예측
import numpy as np
predicted_result = model.predict(X_test)
predicted_labels = np.argmax(predicted_result, axis=1)
# worng_results 모으기
worng_results = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
worng_results.append(n)
# 16개만 추출
import random
samples = random.sample(worng_results, 16)
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_test[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.title('Label: ' + str(y_test[n]) + 'Predict' + str(predicted_labels[n]))
plt.axis('off')
plt.show()
MNIST fashion 데이터
- 숫자로 된 MNIST데이터처럼 28*28 크기의 패션과 관련된 10개 종류의 데이터
1. 데이터 읽기
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.02. 모델
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 1000) 785000
dense_1 (Dense) (None, 10) 10010
=================================================================
Total params: 795,010
Trainable params: 795,010
Non-trainable params: 0
'''3. 학습
import time
start_time = time.time()
hist = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=100, verbose=1)
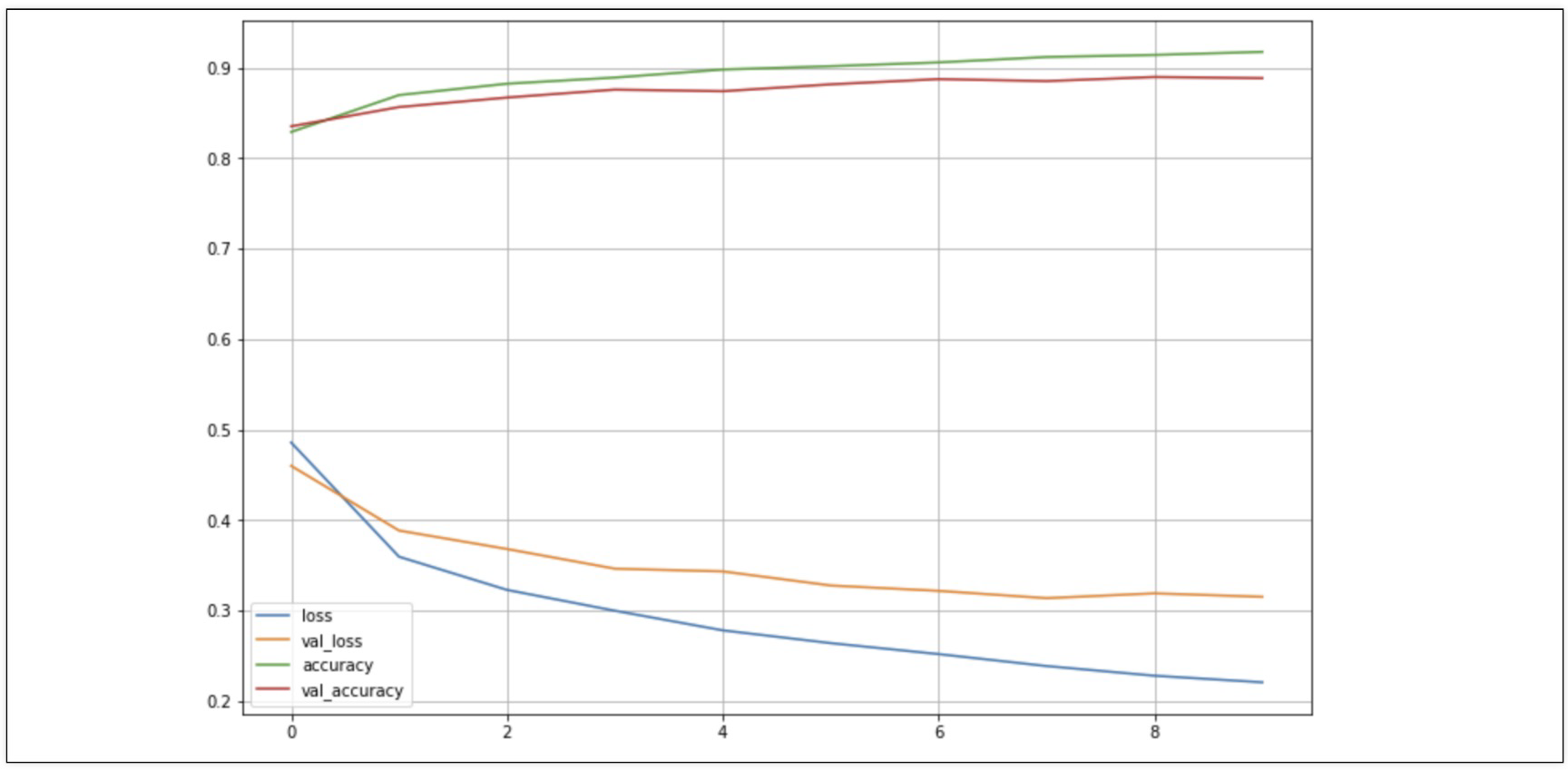
print('fit time: ', time.time() - start_time)4. acc와 loss 그래프 & score
- val_loss와 train loss사이에 간격이 발생
import matplotlib.pyplot as plt
%matplotlib inline
plot_target = ['loss', 'val_loss', 'accuracy', 'val_accuracy']
plt.figure(figsize=(12, 8))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()
score = model.evaluate(X_test, y_test)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
'''
313/313 [==============================] - 1s 4ms/step - loss: 0.3503 - accuracy: 0.8787
Test loss: 0.35026848316192627
Test accuracy: 0.8787000179290771
'''
5. Worng result
import numpy as np
import random
# 예측
predicted_result = model.predict(X_test)
predicted_labels = np.argmax(predicted_result, axis=1)
# 모으기
worng_results = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
worng_results.append(n)
# 16개 추출
samples = random.sample(worng_results, 16)
# 그리기
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(X_test[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
plt.title('Label: ' + str(y_test[n]) + 'Predict' + str(predicted_labels[n]))
plt.axis('off')
plt.show()
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it