1. 데이터
- y 값 그대로 사용하면 error 값이 y값에 영향을 받아서 편향된 결과를 가져올 수 있다. 이것을 막기위해
OneHotEncoder을 사용 OneHotEncoder:n개의 범주형 데이터를 n개의 비트(0, 1) 벡터로 표현- 주의:
1) 판다스의 시리즈가 아닌 numpy 행렬을 입력해야함 → values 이용
2) 벡터 입력을 허용하지 않음 → reshape을 이용해 Matrix로 변환 필요
3) sparse=True가 디폴트이며 이는 Matrix를 반환 현재는 array이므로 False
- 주의:
from sklearn.datasets import load_iris
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
# load
iris = load_iris()
X = iris.data
y = iris.target
# OneHotEncoder
enc = OneHotEncoder(sparse=False, handle_unknown='ignore')
enc.fit(y.reshape(len(y), 1))
y_onehot = enc.transform(y.reshape(len(y), 1))
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=13)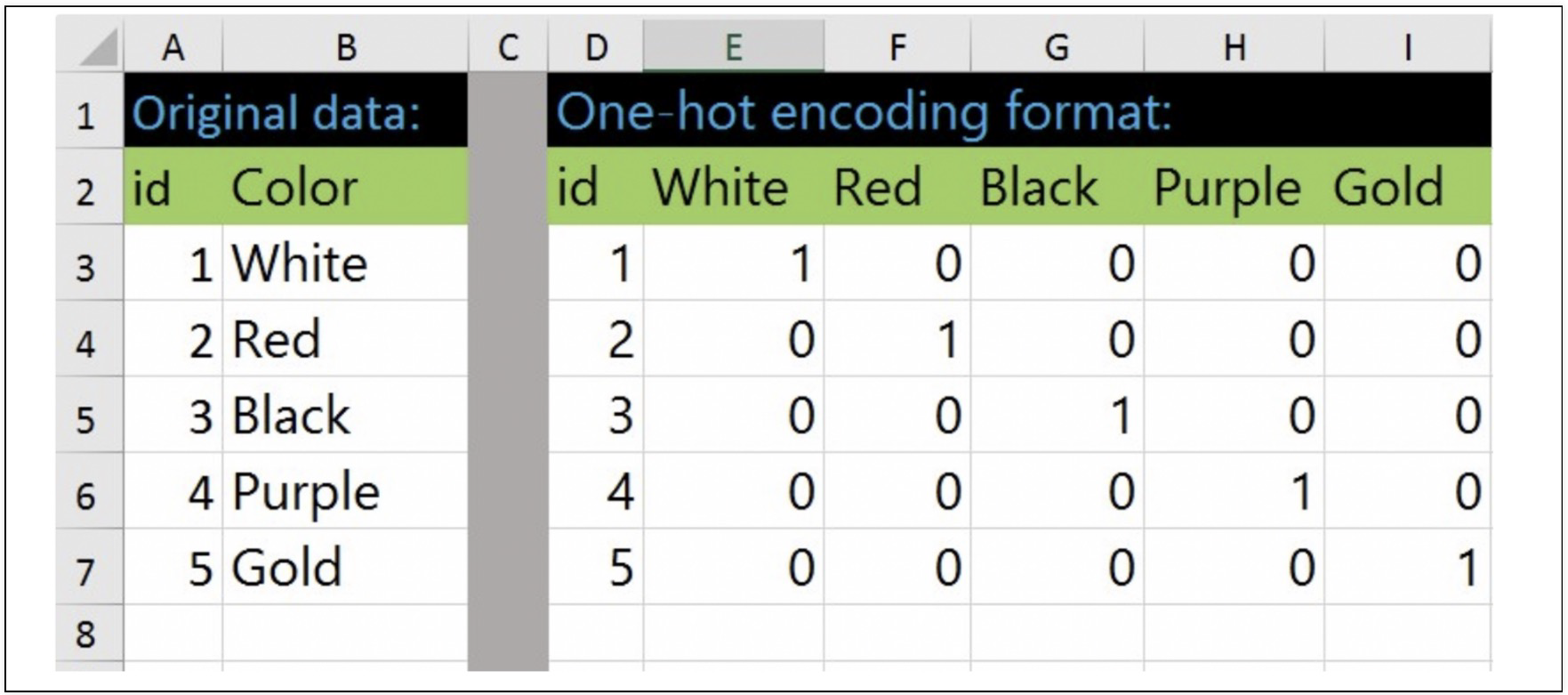
2. 모델 & 학습
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape=(4, ), activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax'),
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
hist = model.fit(X_train, y_train, epochs=100)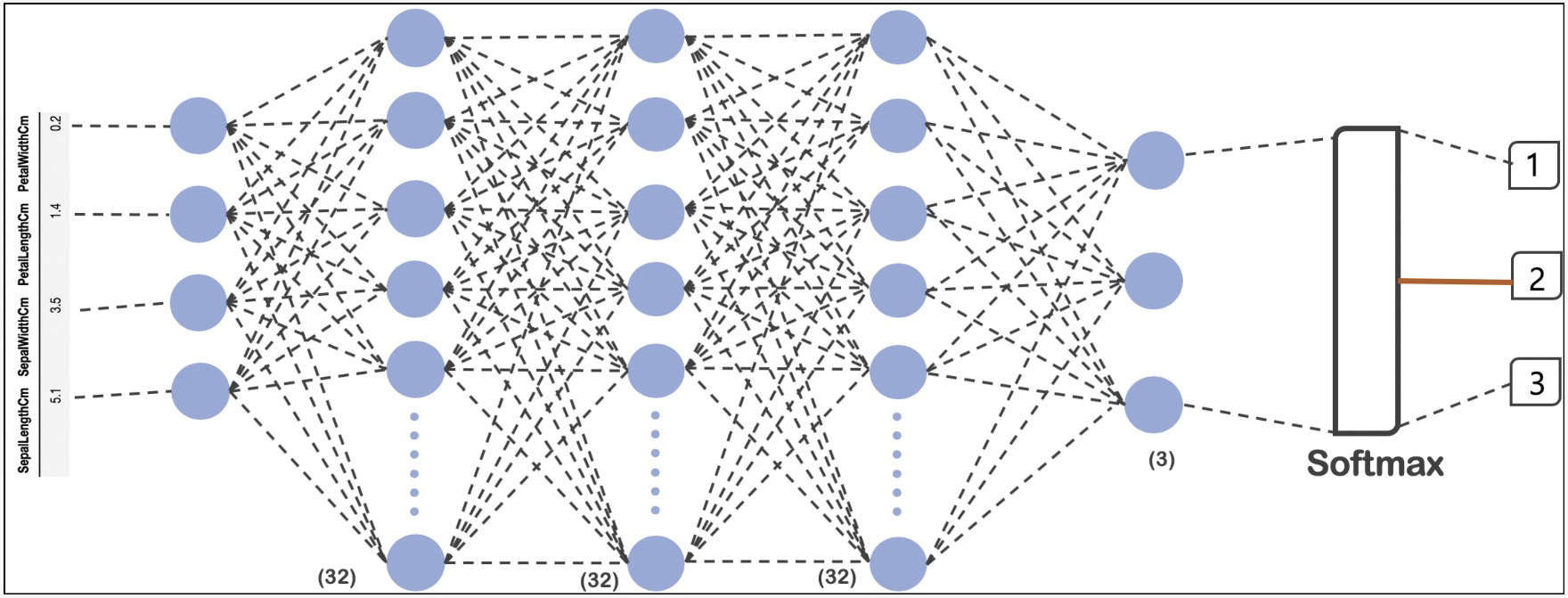
3. 결과
model.evaluate(X_test, y_test, verbose=2)
'''
1/1 - 0s - loss: 0.0952 - accuracy: 1.0000 - 123ms/epoch - 123ms/step
[0.09515346586704254, 1.0]
'''
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(hist.history['loss'])
plt.plot(hist.history['accuracy'])
plt.title('model loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()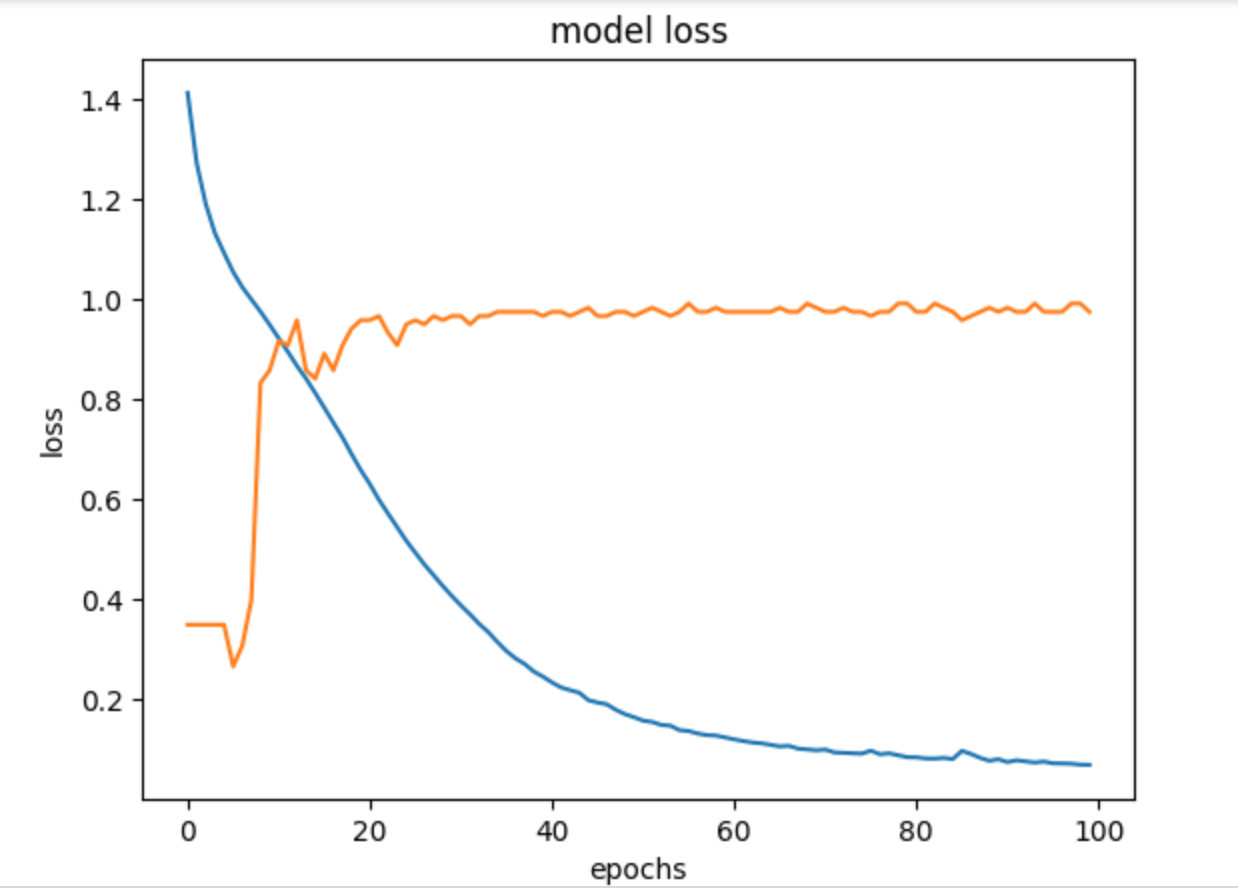
Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://steadiness-193.tistory.com/244

데이터 사이언스 / just do it