[Paper Reveiw] Improving Language Understanding by Generative Pre-Training (GPT-1)
Abstract
- 자연어 처리 부분은 그동안 많은 발전을 이루어왔고, 본문 요약, Question Answering 등 많은 분야에서 발전해 왔습니다.
- 단, 기존의 NLP 작업은 Supervised Learning에 크게 의존해왔습니다. 그렇지만, 반대로 자연어 데이터에는 Unlabeled Data는 많지만, Labeled Data는 많지 않습니다.
- 해당 논문에서는 Unlabeled Data를 Generative Pre-Training하고, 특정한 태스크에 맞게 Labeled된 데이터를 Discriminative Fine-Tuning하여 성과를 도출했습니다.
- 이 과정을 통해 다양한 Downstream task들에서 성능을 향상시켰습니다.
- 그 결과, Pretraining → Fine-tuning하는 과정에서 모델의 구조를 최소한으로 변경해 12개의 Task 중 9개에서 State-of-the-art를 달성했습니다.
1. Introduction
- NLP 분야에서 딥러닝으로 문제를 해결하기 위해서는 Labeled data가 많이 필요하지만, 현실적으로 어려움이 있습니다.
- 위 문제를 해결하기 위해 Unlabeled Data를 최대한 활용해 지도 학습에 대한 의존도를 줄이는 것이 필요합니다.
→ 미리 Unlabeled 데이터로 학습하여 좋은 Presentation을 학습하고, Labeled 데이터로 학습했을 때 전략이 취해져 왔습니다.
- 그렇지만, 지속적으로 다음의 2가지 문제가 언급되어왔고, 이번 논문에서 해결해야 할 점이 존재합니다
- Pre-train모델을 학습하는데 어떤 것이 과연 Optimization이고, 효과적일까? (어떤 목적함수로 비지도 학습을 진행해야 효과적일까?)
- Pre-trained 모델을 Fine-tuning하는데 무엇이 가장 효과적일까? (input을 어떻게 넣어야 효과적일까?)
→ 단순하게, Pretrain, Fine-tuning에 대한 방법이 명확하지 않았기에, 단순하게 task에 맞게 모델의 구조를 바꾸고, 스키마를 추가하는 것은 Semi-supervised-learning을 제시하는 것에 어려움을 가지고 있습니다.
💡Semi-Supervised Learning (준지도학습)
- Unsupervised Pre-training + Supervised Fine-Tuning
- 라벨 x 데이터와 일부 라벨이 있는 데이터를 함께 사용해 모델 학습
→ 많은 양의 Unlabeled Data를 활용해서 사전 학습 모델을 만들고, 비지도 학습을 통해 Pre-train하고, 지도 학습으로 Fine-tuning하는 방법론
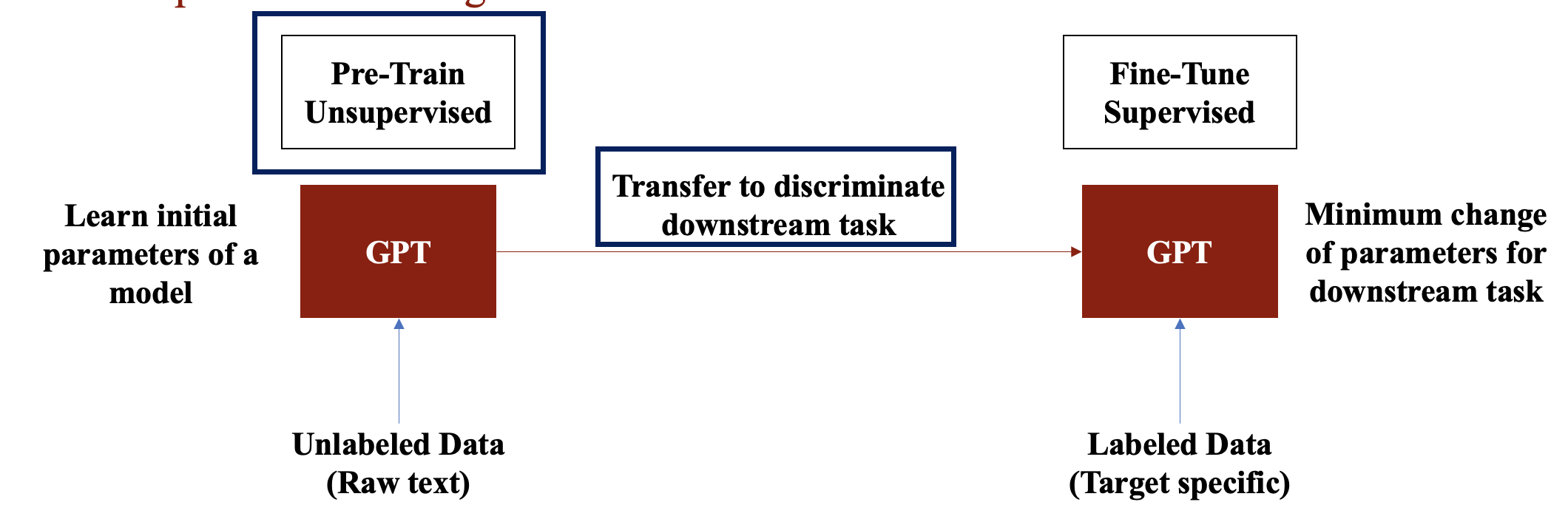
위 문제를 해결하기 위해서는 해당 논문에서는 다음과 같은 과정으로 진행합니다.
- 초기에 네트워크 파라미터를 학습하기 위해 Unlabeled data를 활용해 학습을 진행합니다.
- 목표하는 Task에 맞게 사전학습 된 parameter를 사용합니다.
- 해당 연구에서 Transformer 구조를 사용했고, 이는 기존의 RNN과 다르게, 텍스트의 Long-term dependency 문제를 처리하는 데 있어서 더 좋은 성능을 발휘합니다.
- 그렇기에, 사전 학습된 모델의 아키텍처에서 최소한의 변경만으로 Fine-tuning을 가능하게 함을 보여줍니다.
2. Related Work
Semi-Supervised learning for NLP
- GPT 이전, Word-embedding 기반의 Semi-supervised learning이 효과적임이 보여졌습니다. 하지만, 이러한 Embedding은 아직 단어 수준에 지나지 않습니다.
- 해당 연구에서의 목표는, 단어 수준을 넘어서 구, 문장 수준의 단계로 사용하는 것을 목표로 합니다.
Unsupervised Pre-training
- Unsupervised pre-training시키는 것은 좋은 초기화 지점을 찾는 것에 초점을 둡니다. 이는 Supervised learning에서 잘 동작하게 하기 위함입니다.
- 초기 연구는 이미지 분류, 회귀 작업에 사전 학습을 적용해 딥러닝 모델의 일반화 성능을 개선했으며, 텍스트 분류, 음성 인식 등 다양한 작업에서 딥러닝 모델 학습을 돕는데 사용되었습니다.
- 다만, 기존 LSTM과 같은 것들은 Long-term dependency로 인해 긴 문장에 대한 정보를 수용하는 것에 한계가 존재합니다.
- 그렇기에, 이번 연구에서는 Transformer 네트워크로 더 긴 범위의 언어 구조를 학습하는 것을 목표로 합니다.
Auxiliary training objectives (보조 학습 목표)
- 위 논문에서는 Unsupervised pre-training의 목적 함수(Optimization)를 supervised fine-tuning할 때 auxiliary objective로 추가했습니다.
- 단순하게 supervised learning의 목적 함수에 unsupervised learning 목적 함수를 추가했습니다.
3. Framework
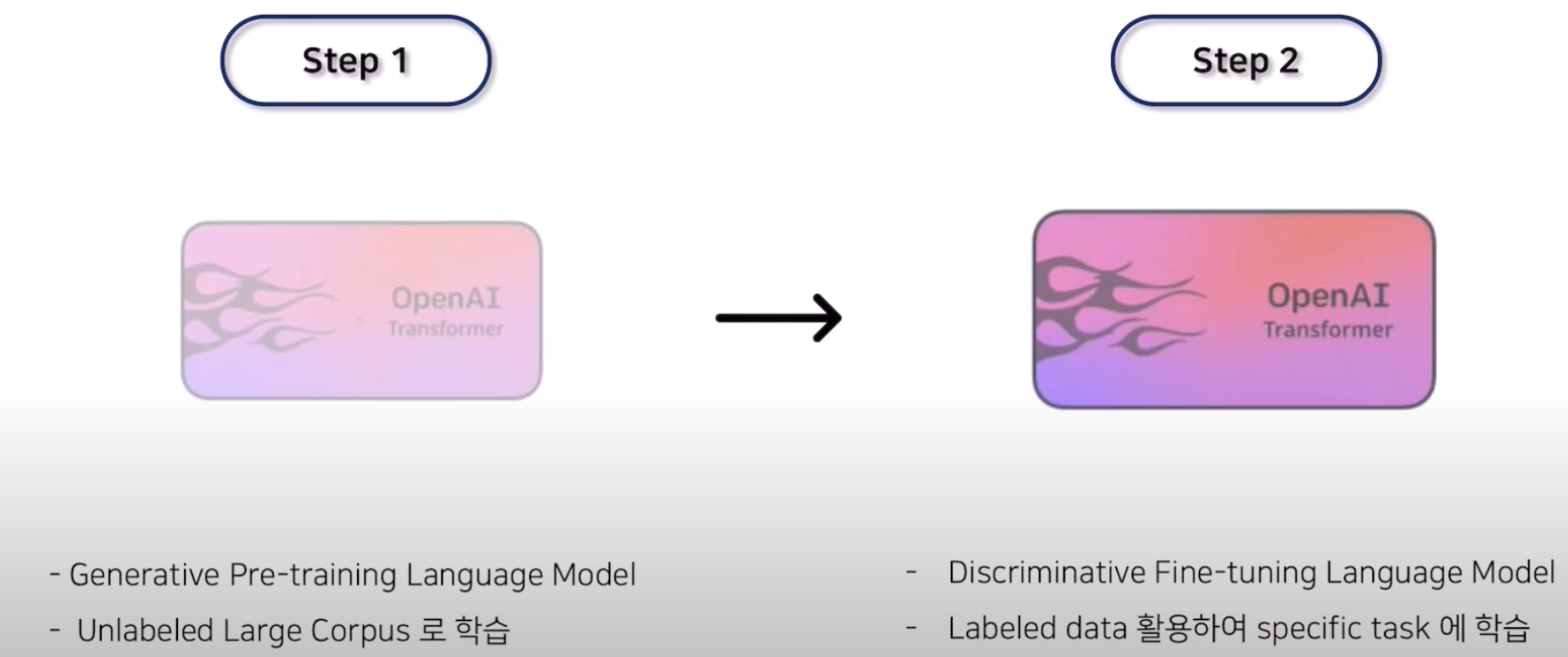
GPT-1 학습 절차에서는 2가지 절차로 학습이 진행됩니다.
- 대규모 텍스트 corpus를 기반으로 high-capacity 언어 모델을 학습합니다.
- Labeled data를 사용해 모델을 판별 작업에 적응하는 fine-tuning 작업을 수행합니다.
3-1. Unsupervised pre-training
- 대규모 unsupervised corpus에서 토큰이 있다고 하면, 표준 likelihood가 maximize하는 식을 따릅니다.
- 먼저 corups를 tokenization하는 과정을 수행합니다.
- 이 과정에서, 주어진 문맥 을 기반으로 다음 토큰 의 확률을 최대화하는 언어 모델링 목표를 사용합니다.
- k : context-window의 크기
- Θ : 신경망 모델의 파라미터
- P : 조건부 확률
→ 예를 들면, I want to go home이라는 문장에서, I want to go가 주어졌을 때, home을 예측하는 확률값입니다.
- 해당 연구에서는 multi-layer Transformer decoder 구조를 사용합니다.
- 즉, Encoder layer가 없기에, encoder-decoder attention을 제외합니다.
- Multi-head self-attention을 적용해 입력 토큰의 문맥을 처리합니다. (처음의 corpus를 tokenize하는 작업 포함)
- U : () 문맥의 토큰 벡터
- : 토큰 임베딩 행렬
- : Position embedding 행렬
- n : Transformer 층 수
💡 위 부분에 대해 자세히 설명하면 다음과 같습니다.
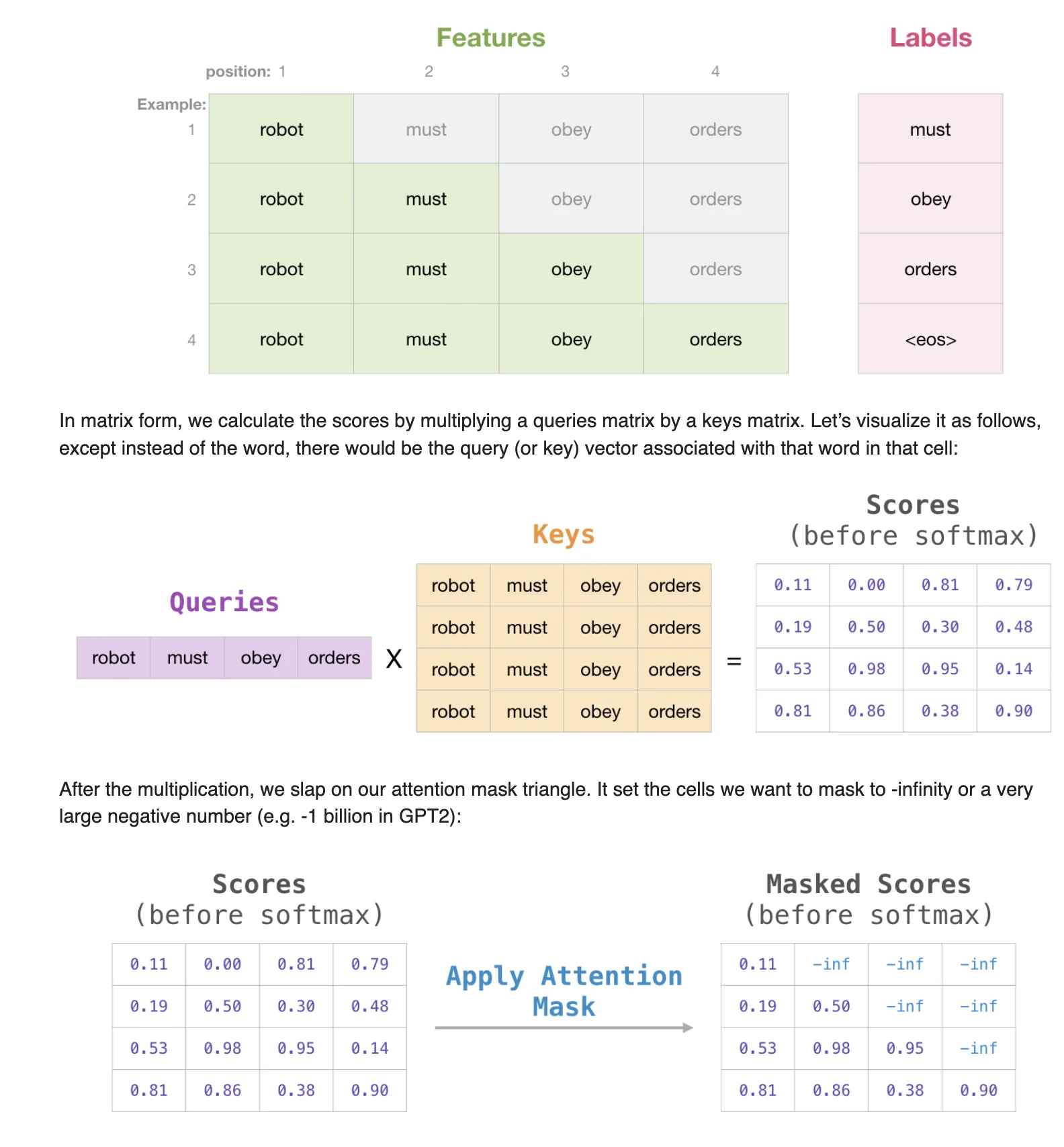
- Transformer의 Decoder 블록은 Masked multi-head self-attention을 기반으로 연산됩니다. multi-head self-attention시에 자기보다 미래에 생성되는 token의 정보를 masking해 token에 대한 contextual embedding 학습시에 앞쪽의 token에만 attention을 주도록 하고 있습니다.
- 이 과정에서 실제 계산은 아래와 같이 행렬의 오른쪽 값을 -inf로 변경해 softmax 계산 시 낮은 값이 도출되도록 합니다.
(참조 : https://velog.io/@tobigs-nlp/Improving-Language-Understandingby-Generative-Pre-Training-GPT-1)
3-2. Supervised fine-tuning
- 해당 과정에서는 Supervised learning이기에, task에 따른 레이블 값이 있어야 합니다.
- C는 데이터 세트(레이블 포함), 각 시퀀스마다 토큰들 (), label=y라고 가정합니다.
- Pretrained된 모델의 Position-wise layer과 Softmax layer 사이 linear layer을 추가해 각 task마다 label y를 예측합니다.
이 식을 모든 데이터 세트의 log우도를 최대화하는 식으로 바꾼다면,
로 변환할 수 있습니다.
💡
- 전반적인 과정은, input=x의 길이가 m인 경우, 마지막 token의 마지막 layer의 임베딩 값(= )에 Linear Transform → softmax를 거쳐 y값과의 cross entropy를 통해 fine-tuning을 진행합니다.
- GPT의 경우, Fine-tuning 시에 pre=training에 사용했던 loss()를 auxiliary training objectives로 추가해 로 가중치를 주며 학습합니다.
위의 auxiliary objective를 추가하면, 2가지 성능 향상 효과가 있습니다.
- Supervised model에 일반화 성능을 향상
- 수렴 속도를 가속
Fine-tuning을 수행할 때, Unsupervised learning도 가중치()를 곱해주어 log likelihood를 최대화하면 위의 2가지 장점을 가진다고 할 수 있습니다.
- 밑의 식은, 언어 모델링을 Auxiliary Objective로 추가해 일반화와 수렴 속도를 향상시키는 것을 목표로 나아가는 식입니다.
3-3. Task-specific input transformations
- GPT-1은 최소한의 변화로 여러가지 Task들을 다룹니다.
- 이전 모델들과는 다르게 GPT-1의 Traversal-style은 구조화된 input으로 전이 학습을 최소한의 변화로 가능하게 했습니다.
- GPT는 pre-training부터 여러 문장을 input으로 받기에, 큰 변형 없이 downstream task를 처리할 수 있습니다.
- 단, deliminator 토큰만 문장 사이에 추가해주면 됩니다.- 모든 task의 input의 처음과 끝에는 random initialize된 <S>, <E> 토큰을 추가합니다. - 활용 예시
- Classification : 기존 분류 문제와 일치합니다.
- Textual entailment : 전제(premise)와 가설(hypothesis) 두 가지의 시퀀스 토큰들을 중간 구분 문자 ($)를 사용해 한번에 네트워크에 포워딩합니다.
💡 Textual entailment : 전제와 가정의 관계가 함의(entailment)인지, 중립(neutral)인지, 모순(contradiction)인지 분류하는 문제
- Similarity : 두 문장의 유사성을 비교할 때 순서가 존재하지 않습니다. 그렇기에, 문장을 반영하기 위해 (t1,t2), (t2, t1) 두 케이스를 각각 모델에 포워딩합니다. 마지막 linear layer에 들어가기 전, element-wise로 합해 출력합니다.
- Question Answering and Commonsense Reasoning : 지문 z, 질문 q, 정답 리스트 ()가 있습니다. 각 정답 리스트 k개만큼의 각가 모델에 포워딩해 softmax를 구해 가장 정답에 가까운 값을 찾아냅니다.
4. Experiments
4.1 Setup
- Pre-training시에 사용한 BooksCorpus dataset은 의미가 이어져 있는 문장 들이 많아서 long-range information을 학습하기에 용이했습니다.
- ELMO가 활용한 Word benchmark 역시 사용했는데, 18.4의 낮은 perplexity가 도출되었습니다.
💡 Perplexity
언어 모델이 얼마나 높은 확률로 문장을 생성했는지 보여주는 지표를 나타냅니다.
Perplexity 문장 생성확률의 역수를 취함으로 낮을수록 좋은값입니다.
- transformer decoder layer는 총 12층으로 구성되어 있고, self-attention head는 각 64개의 Q, K, V과 총 12개의 heads로 구성되어 있습니다.
- position-wise feed-forward는 총 3072차원이며 Adma optimizer를 사용했습니다.
- Fine-tuning은 를 0.5로 설정한 것을 제외하고는 나머지 하이퍼파라미터는 Unsupervised와 동일합니다.
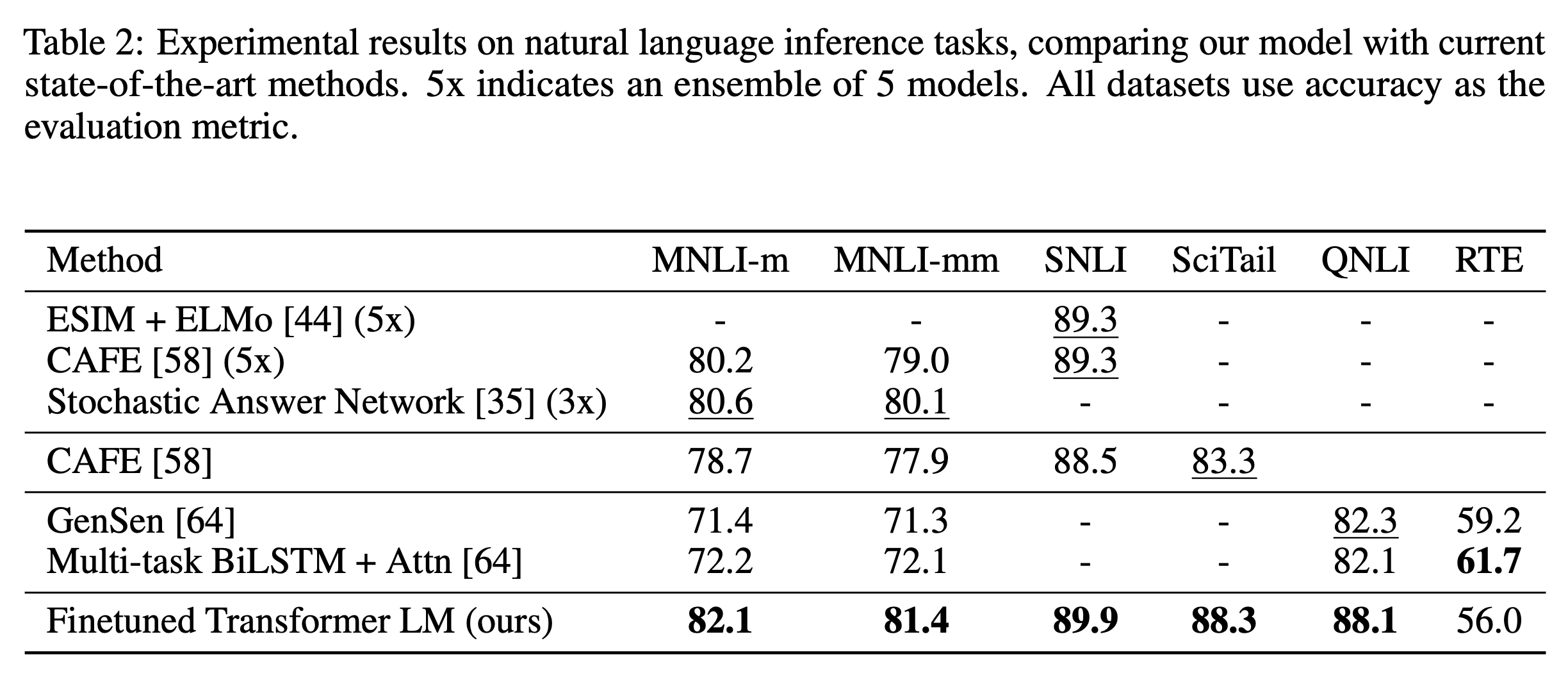
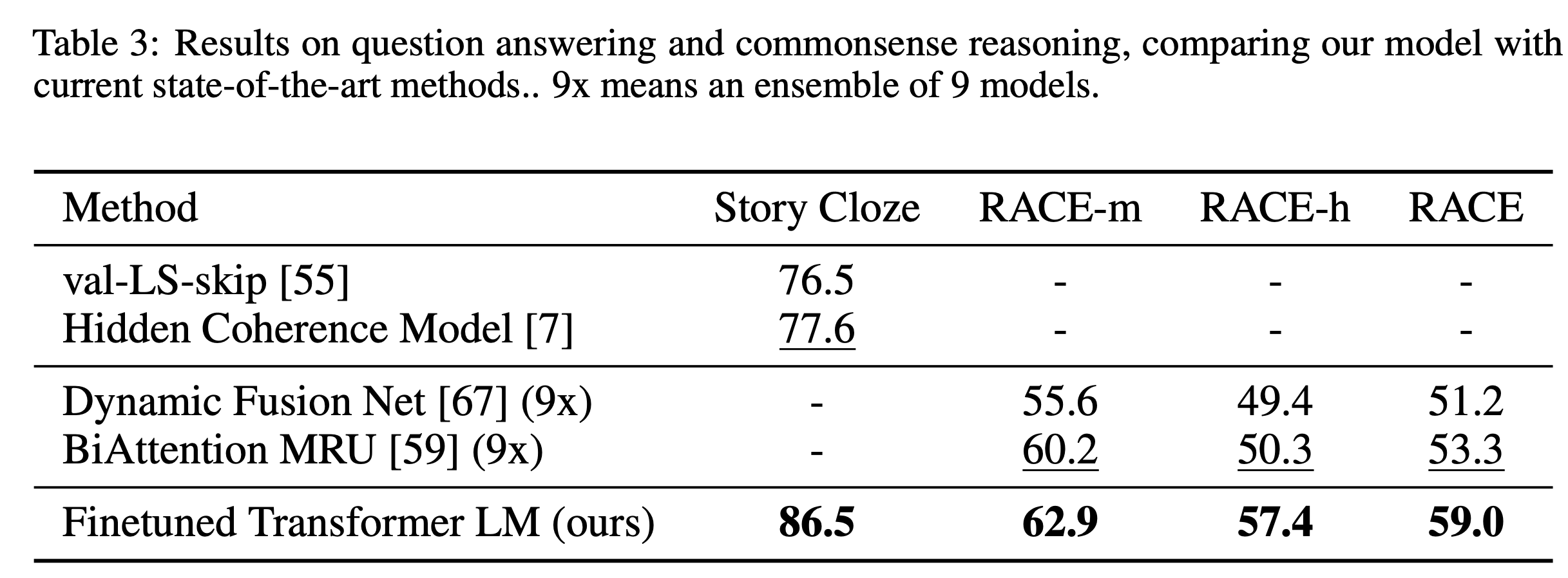
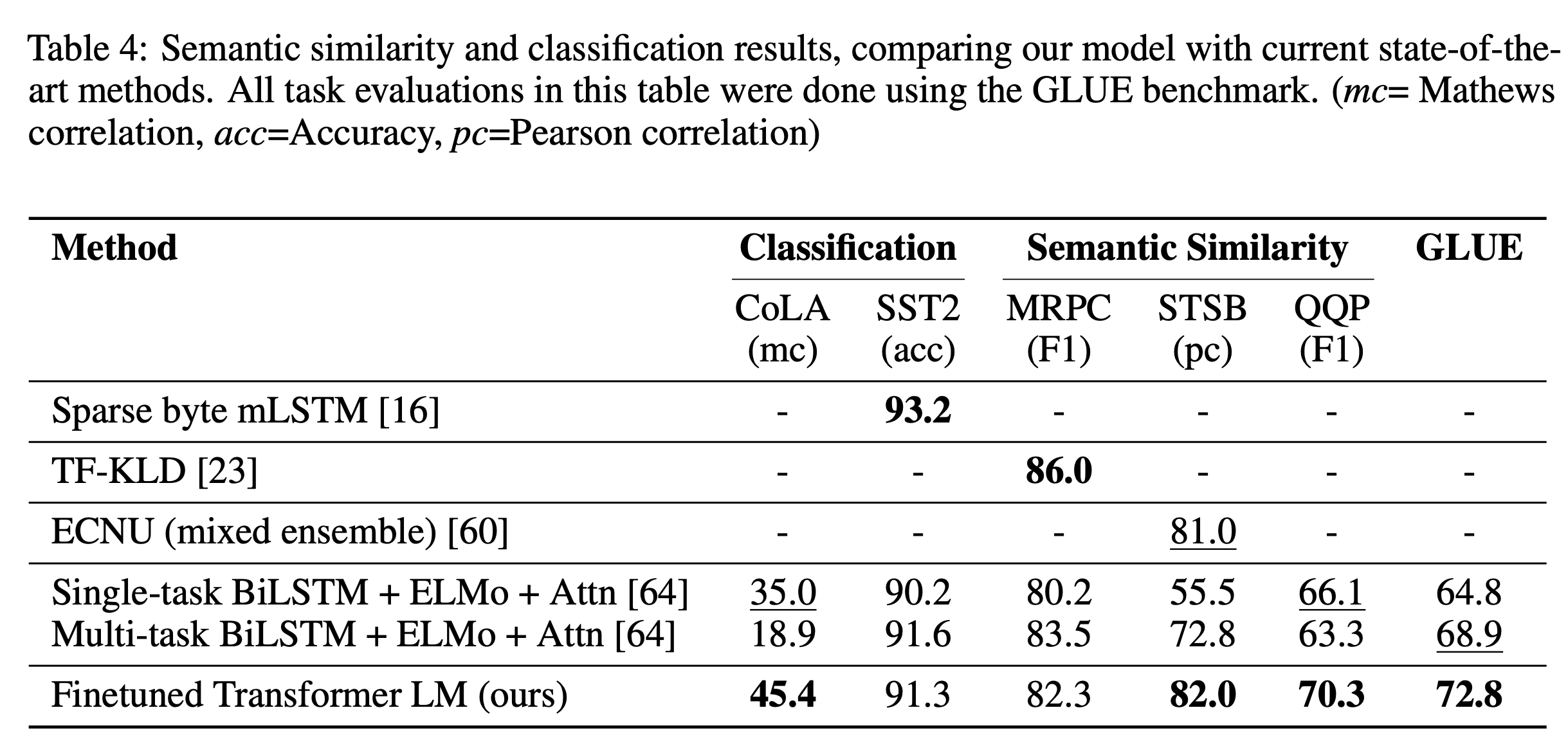
→Task 12개 중 9개의 Dataset에서 SOTA를 달성했습니다.
5. Analysis
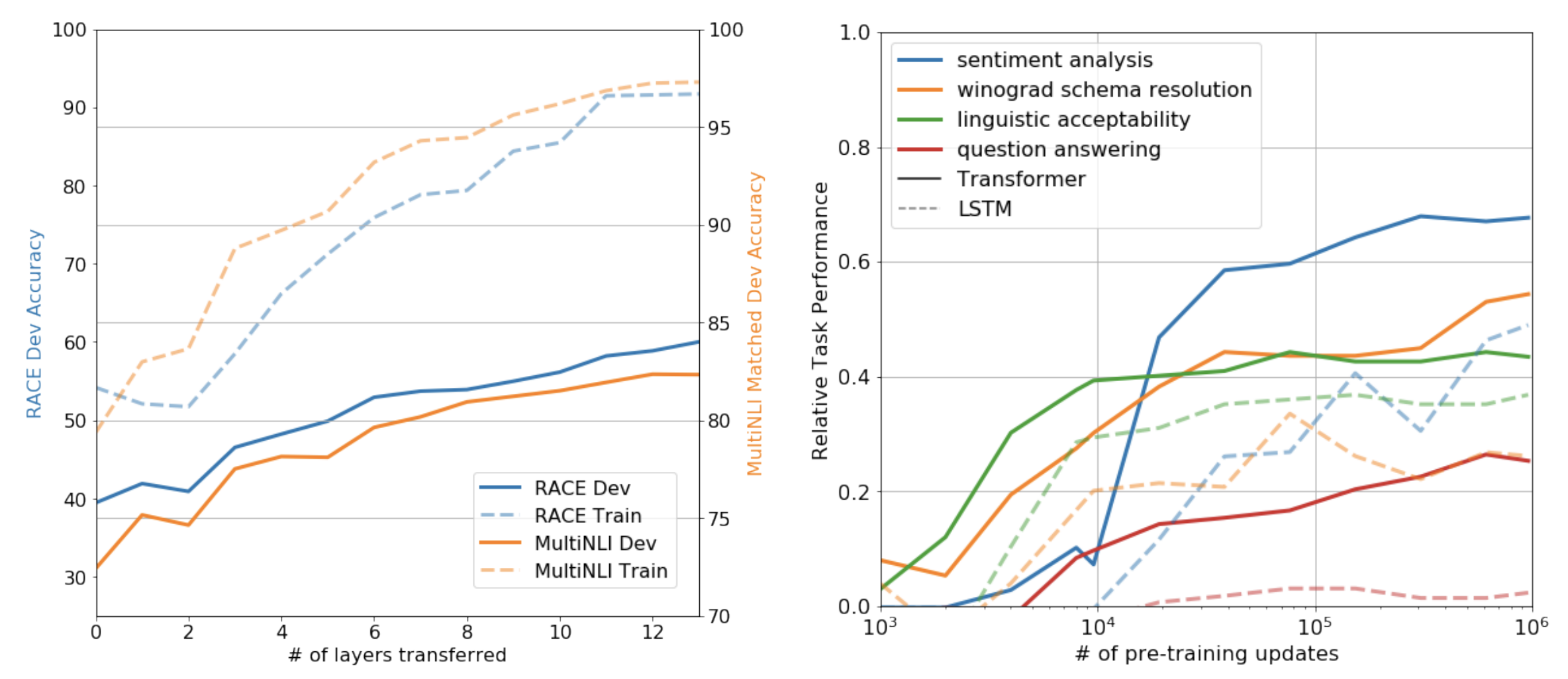
- Pre-train시에 사용했던 layer들을 fine-tuning 시에 더 많이 전이시킬수록 성능이 향상됨을 보였습니다.
- Transformer 구조가 LSTM에 비해 Pretrain step이 높아질수록, Zero-shot의 성능이 높아졌습니다.
6. Conclusion
- GPT-1 모델에서는 Task별이 아닌, Generative pre-training 모델, Discriminative Fine-tuning 모델을 제안해서 긴 문장의 장기 의존성 문제를 해결하고 높은 성능을 보였습니다.
- 또한, 언어 모델의 새로운 패러다임을 제시하면서 이후 LLM 모델에 대한 새로운 방향성을 제시했습니다.
