[Paper Review] Enhancing Complex Question Answering over Knowledge Graphs through Evidence Pattern Retrieval
Abstract
KGQA(지식 그래프 기반의 Question-Answering)에서는 Subgraph Extraction과 Answering Reasoning 2개의 단계로 이루어집니다.
→ 이 과정에서, subgraph extraction은 증거 사실들 간의 구조적 의존성의 중요성을 충분히 고려하지 못한다는 문제점을 가지고 있습니다.
이에 대한 해결책으로, 위 논문에서는 구조적 의존성에 대해 명식적으로 모델링하는 증거 패턴 추출(Evidence Pattern Retrieval, EPR)을 제안합니다.
EPR은 질문과 관련된 원자 패턴(atomic patterns)을 검색하고 이를 조합하여 최적의 증거 패턴(Evidence Pattern)을 선택함으로써, 하위 그래프를 생성하는 방법입니다.
원리 및 설명은 다음과 같습니다.
- EPR은 리소스 쌍의 원자 인접 패턴(Atomic adjacency patterns)을 인덱스화한 뒤, Dense retrieval로 질문과 관련된 원자 패턴을 검색합니다.
- 검색된 패턴을 조합해 후보 증거 패턴을 생성하고, 이를 기반으로 질문에 적합한 하위 그래프를 추출합니다.
해당 연구로 ComplexWebQuestions 데이터셋과 WebQuestionsSP에서 좋은 성능을 달성하고, 유의미한 지표 향상을 이루었습니다.
💡 Atomic Patterns
- 지식 그래프에서 기본적인 관계 단위로, 개체(Entity)와 관계(Relation) 간의 간단하고 기본적인 연결구조를 말합니다.
- (Entity1, Relation, Entity2)의 형태로 표현되고, 이는 지식 그래프의 가장 작은 단위입니다.
- 자세한 설명은 Heterogeneous Graph 참조
💡 Dense Retrieval
- 고차원 임베딩 공간을 활용해 질의와 문서를 유사도 기반으로 검색하는 방법을 말합니다.
- 전통적인 검색 알고리즘과 달리, 단어의 정확한 일치보다는 의미적 유사성을 포착합니다
- 대규모 데이터셋에서도 빠른 검색이 가능합니다.
- BERT기반의 Bi-Encoder을 많이 사용합니다. (위 연구에서도 사용)
1. Introduction
대규모 Knowledge Graph가 발전함에 따라, KG에 저장된 정보를 쉽고 정확하게 접근하려는 수요가 증가하고 있습니다.
KG를 활용한 질의응답(KGQA)는 2가지 과정으로 나뉩니다.
- Semantic Parsing(SP, 의미 구문 분석)
- 자연어 질문을 실행 가능한 쿼리로 변환해 정답을 찾는 방식입니다.
- Gold query 데이터가 필수적이며, 없다면 성능 저하의 우려가 존재합니다.
💡 Gold Query Data
- QA 시스템을 학습시키기 위해 사람이 직접 생성하거나 주석을 단 데이터입니다.
- 시스템이 학습할 때 정답에 근접한 이상적인 쿼리를 말합니다.
- Gold Query가 충분히 많을수록, 모델이 Question-Query 매핑을 잘 학습하여 정확한 답을 도출할 수 있습니다.
- Information Retrieval(IR, 정보 검색)
- 질문과 관련된 하위 그래프를 추출하고, 해당 정보를 활용해 답을 도출합니다.
- 효율적이지만, 하위 그래프에 노이즈가 포함될 경우, 성능은 저하됩니다.
아직은 복잡한 질문을 다루고, 노이즈 속에서 답을 찾아내는 과정에서 한계점이 존재합니다.
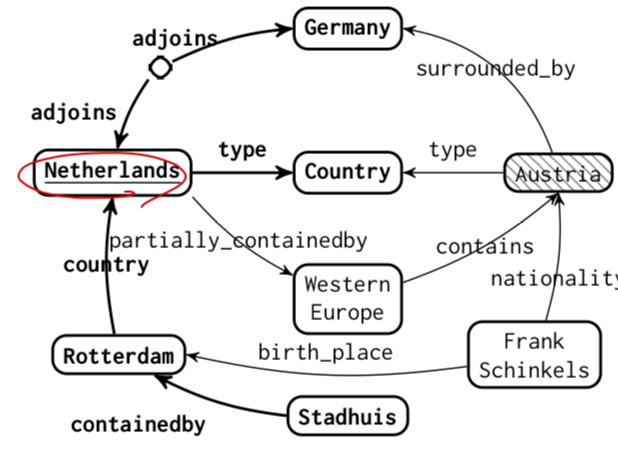
→ SP는 복잡한 질문에는 효과적이지만, 대량의 질문-쿼리 매칭 데이터인 Gold Query가 필수적고, IR은 복잡한 라벨링 없이 동작하지만, 복잡한 질문에서 성능이 낮고, 노이즈에 취약합니다.
이를 위해서 해당 연구에서는 다음과 같은 해결책을 제시합니다.
Evidence Pattern Retrieval(EPR, 증거 패턴 추출)은 주제 Entity와 답 사이의 구조적인 관계를 모델링하여 하위 그래프 추출 과정에서 노이즈를 줄이는 방법입니다.
이는 질문과 관련된 “증거 패턴”을 검색하고, 이를 활용해 적합한 하위 그래프를 생성합니다. 이후, 신경망 모델로 점수를 매겨 가장 적절한 서브그래플르 선택합니다.
위 연구는 복잡한 질문 응답 성능을 크게 향상시켰습니다.
ComplexWebQuestions 데이터 셋에서 F1-score를 10점 이상 향상시켰으며, WebQuestionsSP에서도 경쟁력 있는 성과를 보였습니다.
2. Related Work
2.1 KGQA Benchmarks
몇 년 동안, KGQA를 위해 많은 데이터 셋이 제안되었고, 최근에는 다단계 추론이 필요한 복잡한 질문에 초점을 맞춘 데이터 셋이 대두되고 있습니다.
일부 데이터셋은 WebQuestions의 방식을 따라 질문을 먼저 수집한 뒤, 주석 작업을 진행합니다.
- ComplexQuestions는 WebQuestions에서 수집한 Question-Answer pair과 수작업으로 레이블링한 QA 쌍을 활용해 구성했습니다.
- ComplexWebQuestions는 WebQuestionsSP의 단순한 질문을 조합해 복잡한 질문을 생성했습니다.
- LC-QuAD 계열은 미리 정의된 템플릿으로 질문을 생성했습니다.
- GrailQA는 사람이 직접 주석을 달고, 다양한 수준의 일반화 평가를 위해 설계되었습니다.
- KQA Pro는 명시적인 추론 과정을 표현하기 위해 프로그래밍 언어를 사용해 구성했습니다.
2.2 Information Retrieval Methods for KGQA
KGQA를 위한 정보 검색 방법은 다음의 과정을 준수합니다.
- 질문에서 주제에 적합한 엔티티를 식별합니다.
- 해당 엔티티 주변에서 답을 찾기 위해 하위 그래프를 검색합니다.
초기에는 1단계 추론(1-hop reasoning)을 초점으로 했지만, 복잡한 질문에 대해서는 검색 범위를 좁히기 위해 Subgraph를 추출하고, 해당 그래프에서만 작업합니다.
이를 위해서 PPR, PullNet, Subgraph Retriever, UniKGQA 등이 제안되었습니다.
PPR : 주제 엔티티의 이웃에서 계산된 Personalized PageRank를 사용해 점수를 계산합니다.
PullNet : 질문에 특화된 하위 그래프를 반복적으로 구성하는 프레임워크입니다.
Subgraph Retriever : 관계 경로를 확장하는 순차적인 의사결정 프로세스를 통해 하위 그래프를 생성합니다.
UniKGQA : 질문과 관련된 관계를 매칭하는 모듈과 정보를 전파하는 모듈을 통합해 하위 그래프 추출과 답변 추론을 통합합니다.
→ 다만, 이 방법들은 관계나 답변을 찾아내는 것에 초점을 맞췄기에, 구조적 의존성을 명시적으로 고려하지 않았습니다. 이에 따라 중요한 정보를 놓칠 가능성이 존재합니다.
2.3 Semantic Parsing Methods for KGQA
위 방법은, 질문을 실행 가능한 쿼리로 변환하여 답을 구하는 방법입니다. 최근에는 사전 학습된 Seq2Seq 모델을 활용하여 질문 관련 맥락 또는 중간 결과를 사용해 입력을 확장하거나 디코딩 범위를 제한하는 방법을 사용합니다.
이를 활용하는 방법론으로는 Case-based Reasoning, Candidate Queries, Multi-grained Retrieval 등이 있습니다.
위 방법들은 Gold-Query 데이터가 필요하며, 이것이 없다면, 성능 저하가 우려됩니다. 최근에는 소수의 쿼리 데이터만으로 학습이 가능한 Few-Shot KGQA 방법이 개발되었으나, SOTA를 달성하지 못했습니다.
3. Task Formulation
먼저, 지식 그래프 를 엔티티 와 관계 로 이루어진 사실 집합으로 가정합니다.
즉, 로 정의합니다.
주어진 질문 에 대해, KGQA의 과제는 를 기반으로 정답 엔티티 를 찾는 것입니다.
IR 기반 KGQA 방법은 일 확률 를 최대화하여 를 다른 엔티티와 구분합니다. 단, 전체를 탐색하는 것보다는, 질문과 관련된 서브 그래프 가 존재한다고 가정하고, 다음의 식으로 단순화합니다.
즉, IR 기반 KGQA(IR-KGQA)는
- 서브 그래프 추출 (subgraph extraction)
- 답변 추론 (answer reasoning)
이렇게 두 단계로 나뉩니다.
이를 확률적 관점에서, 다음과 같이 나타낼 수 있습니다.
- 서브 그래프 추출은 잠재 분포 를 모델링하여 를 최대화합니다.
- 답변 추론은 추출된 서브 그래프에서 분포 를 모델링하여 을 근사합니다.
는 서브 그래프 추출기를, 는 예측된 답변, 는 답변 집합을 결정하는 신뢰도 임계값을 나타냅니다.
위 연구는 subgraph를 추출하는 것에 초점을 맞추고 있습니다. 여기서, 그래프 추출과정에서 발생하는 노이즈가 이후 추론 단계에 영향을 미친다고 언급합니다.
→ 즉, 질문 에 대한 이상적인 하위그래프 는 최소한의 Evidence facts 집합으로 이루어져야 합니다.
수학적으로는 다음과 같이 정의됩니다.
Similarity는 주제 엔티티간 adjacency structure에 의해 결정됩니다. → 이를 “Evidence Pattern”으로 모델링합니다. 의 증거 패턴 는 에서 질문 에 등장하지 않는 모든 엔티티를 변수로 대체한 것입니다.
이 과정을 통해서 서브 그래프 추출 문제를 해결할 수 있습니다.
가장 적합한 증거 패턴 P를 검색한 후, 이를 만족하는 최대 크기의 그래프를 사용해 서브 그래프를 추출합니다. 이 결과는, 이후 정답 추론 단계에 제공됩니다.
4. Evidence Pattern Retrieval
주어진 지식 그래프의 검색공간은
로 나타낼 수 있습니다. 이 공간은 관리 가능한 저장 용량을 초과하기에, 엔티티와 관계 간의 adjacency structure을 원자 패턴(Atomic Patterns, AP) 단위로 분석합니다. 여기에서 각 AP는 인접 자원의 쌍과 해당 연결 구조로 정의됩니다.
AP는 엔티티-관계(ER-AP), 관계-관계(RR-AP)의 방향성 있는 연결을 포함합니다.
RR-AP의 검색 공간은 모든 인접 관계 상을 포함하기에, 빠른 검색을 위한 인덱스를 구축해야 합니다.
이를 위해서 Pretrained BERT 모델을 통해 AP를 검색합니다. 질문 와 AP 에 대해 다음과 같이 유사도를 계산합니다.
4.1 Atomic Pattern Retrieval
AP는 엔티티-관계(ER-AP), 관계-관계(RR-AP)의 방향성 있는 연결을 포함합니다.
RR-AP의 검색 공간은 모든 인접 관계 상을 포함하기에, 빠른 검색을 위한 인덱스를 구축해야 합니다. 이를 위해서 Pretrained BERT 모델을 통해 AP를 검색합니다. 질문 와 AP 에 대해 다음과 같이 유사도를 계산합니다.
위 과정을 위해 Pretrained BERT 모델을 통해 AP를 검색합니다. 질문 와 AP 에 대해 다음과 같이 유사도를 계산합니다.
RR-AP의 직렬화는 관계 레이블, 연결 유형 태그를 사용핮여 지정하고, 나뉩니다. 예를 들면,
| RR-AP 구조 | 직렬화 형식 |
|---|---|
| rel1 ← ⃝ rel2 → | [CLS] rel1 SS rel2 [SEP] |
| rel1 ← ⃝ rel2 ← | [CLS] rel1 SO rel2 [SEP] |
| rel1 → O rel2 → | [CLS] rel1 OS rel2 [SEP] |
| rel1 → O rel2 ← | [CLS] rel1 OO rel2 [SEP] |
과 같이 구성되는 것이죠.
Train시에는 Cross Entropy loss를 사용해 모델을 학습합니다. 긍정 샘플은 가짜 패턴에서, 부정 샘플은 랜덤으로 선택합니다. (랜덤으로 선택하는 과정에서 임의로 관계 라벨을 바꾸거나 무작위로 선택합니다.)
4.2 Candidate Evidence Pattern Construction
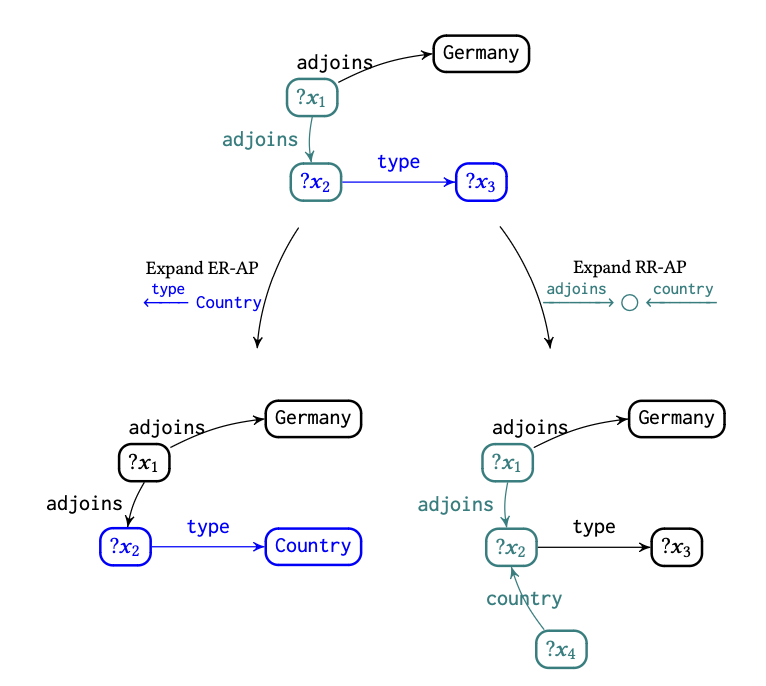
후보 패턴(Candidate Evidence)을 생성하는 과정은 다음과 같습니다.
먼저, AP에서 출발해, 가능한 모든 증거 패턴(EP)을 생성합니다. 당므으로, IterExpand 알고리즘을 사용해 EP를 확장합니다. 확장 과정에서 데이터 크기를 제한하기 위해 임계값(τ)을 사용합니다.
확장은 다음과 같은 기준으로 이루어집니다:
- AP가 기록한 관계(adjacency)가 현재 구성중인 EP와 일치하는지 확인하며 확장합니다.
- 특정 임계값을 초과하지 않는 범위에서 변수 노드를 확장하거나, 관계(RR-AP)를 추가하는 방식으로 이루어집니다.
각 주제 엔티티는 한 번만 확장할 수 있지만, 관계는 제한없이 추가 가능합니다. 또한, 응답을 제공할 수 있는 패턴만 후보로 간주합니다.
검증 기준은 다음과 같습니다.
- IsValidPat : 패턴이 문제의 의미와 일치하는지
- 모든 주제 엔티티를 포함해야 하며, 단순하거나 의미없는 관계는 허용하지 않습니다.
- 두가지 유효한 구조만 허용합니다.
- 패턴의 끝 점이 모두 주제 엔티티인 경우
- 변수 끝점이 하나인 경우
- Expandable : 패턴이 새로운 관계로 확장가능한지
- 확장된 패턴이 기존 원자 패턴 내에서 유효한지를 평가합니다.
예를 들어, "adjoins → country →" 관계를 확장하려면, "type → country" 같은 관계가 존재해야 합니다.
4.3 Evidence Pattern Ranking
후보 패턴이 생성되면, Cross Encoder 모델을 사용해 각 패턴의 유사성을 평가합니다.
평가 과정은 다음과 같습니다.
-
질문과 후보 패턴을 직렬화한 텍스트 시퀀스로 결합한다.
-
모델 입력 형식은 다음과 같이 조정한다.
[CLS] 질문 텍스트 [SEP] 패턴 텍스트 [SEP]
-
BERT 모델은 [CLS] 임베딩을 기반으로 패턴과 질문 간의 유사성을 계산합니다.
-
모델은 Cross Entropy Loss를 통해 학습, 최적의 패턴이 선택됩니다.
모델은 교차 엔트로피 손실을 사용해 훈련하며, 정답을 포함하는 패턴은 긍정적 예로, 나머지는 부정적 예로 간주됩니다.
5. Evaluation
5.1 Experimental Settings
평가에는 다음 2가지 데이터셋을 사용합니다.
- Complex WebQuestions (CWQ) : 복잡한 웹 기반 질문 응답 데이터셋
- WebQuestionsSP(WebQSP) : 간단한 웹 질문 응답 데이터셋

이 과정에서, 최신 Freebase 덤프를 사용했고, 총 2366590개의 RR-AP를 포함하는 pattern index를 구성했습니다.
평가에 있어, 다양한 기존 방법과 비교하였습니다. 이를 크게 두 가지로 분류했습니다:
- 정보 검색(IR) 기반 방법:
- R-Prune + EmbedKGQA: 관계 제거 기반 서브그래프 추출
- PPR + GCN: 개인화된 PageRank 점수를 사용하는 그래프 컨볼루션 네트워크
- PullNet + GCN: 텍스트 및 지식 그래프 통합 검색
- SR + NSM: 서브그래프 검색과 신경 상태 기계(NSM) 기반 응답 추론
- UniKGQA + NSM: 통합 검색 및 추론 모델
- 의미 해석(Semantic Parsing) 기반 방법:
- DecAF: 논리적 쿼리 생성 모델
- Program Transfer: 프로그램 전이 모델
- KB-Coder: 소수 샘플 학습 기반 모델
(구현 세부 사항은 생략합니다. 장비에 대한 정보이기 때문)
성능 평가 지표는 3가지를 사용합니다.
- Hits@1 : 상위 1개 예측이 정답인 비율
- F1 Score : Precision, Recall의 조화 평균
- 정답 포함률(C.R.) : 추출된 서브그래프에서 최소한 하나의 정답이 포함된 질문 비율
모델 성능을 종합적으로 평가하는 데 사용되었으며, 정확한 응답뿐만 아니라 서브그래프 추출 및 후보 패턴 선택의 품질을 측정합니다.
5.2 Main Results
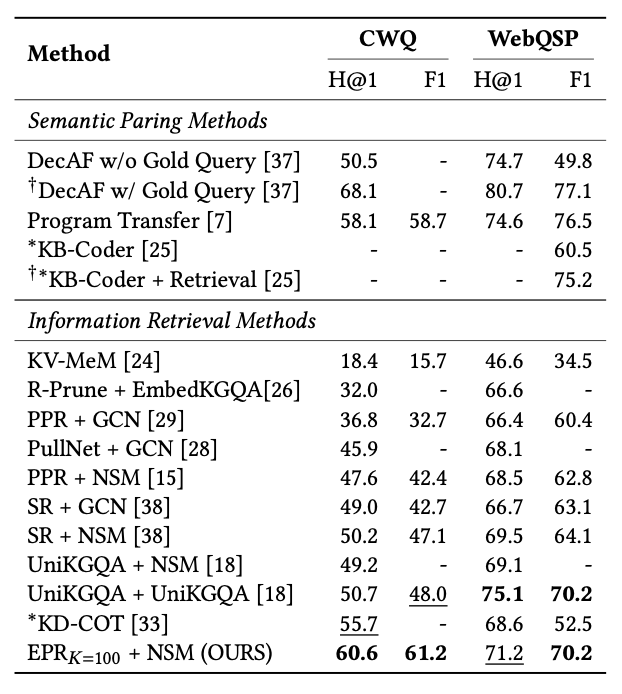
IR 및 Semantic Parsing 기반 모델링과 비교를 수행한 결과입니다.
결과는 다음과 같이 정리할 수 있습니다. 최대 100개의 RR-AP를 검색한 구현 결과가 포함되어 있다.
Complex WebQuestions(CWQ) : EPR 기반 접근 방식은 복잡한 질문 응답에서 H@1, F1 Score에서 SOTA를 달성했습니다.
WebQuestionsSP(WebQSP) : 단순 질문 응답에서는 기존 최상위 모델과 유사 성능, 일부는 우수한 성과를 냈습니다.
→ 복잡한 질문에서는 기존 모델들을 웃도는 성과를 달성했습니다. 또한, 간단한 질문에서는 일부 성능이 감소했지만, F1 Score는 유사합니다.
5.3 Results with Various Number of Retrieved Atomic Patterns
AP의 개수가 시스템의 성능과 효율성에 미치는 영향을 분석한 결과는 다음과 같습니다.
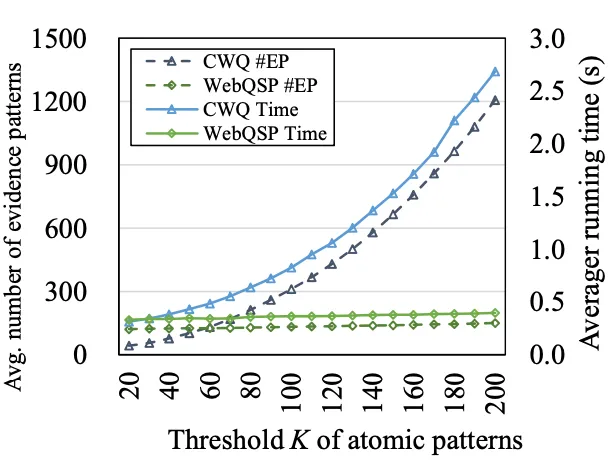
CWQ(복잡한 질문)에서의 결과는 다음과 같습니다. 원자 패턴 수가 증가함에 따라 후보 증거 패턴의 조합이 폭발적으로 증가해 실행시간이 길어졌습니다. 또한, 원자 패턴 개수가 증가할수록 성능은 개선되지만, 그 폭은 점점 감소됩니다.
→ 지나치게 많은 AP는 효율성 저하를 유발합니다.
WebQSP(단순한 질문)에는 검색된 원자 패턴의 조합이 상대적으로 적기 때문에, AP 개수 임계값 증가가 시스템 성능에 미치는 영향이 미미했습니다.
→ AP 개수 임계값과 관계없이, 효율성과 성능 모두 안정적이였습니다.
5.4 The Impact of Training Data Size on Pattern Ranking
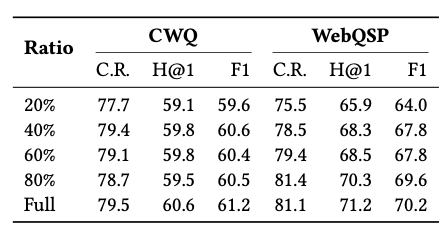
학습 데이터의 크기가 후보 증거 패턴 순위에 미치는 영향을 평가하기 위해, 다음의 과정을 진행합니다.
학습 데이터를 무작위로 5개의 동일한 크기로 나누고, 다양한 비율의 데이터를 사용했습니다.
실험 결과, 시스템의 성능은 데이터 크기에 민감하지 않은 것으로 밝혀졌습니다.
→ 이를 통해, AP 검색 과정에서 이미 질문과 관련된 지식 그래프 문맥을 충분히 설정해서 랭킹 모델은 주로 구조적 정보에 초점을 맞추며 데이터 크기에 덜 의존하게 됩니다.
5.5 Error Analysis
주요 오류 분석은 다음과 같습니다.
| 오류 유형 | CWQ 비율 (%) | WebQSP 비율 (%) |
|---|---|---|
| 불충분한 원자 패턴(AP) | 20% | 28% |
| 패턴 구성 오류 (EP Construction) | 6% | 8% |
| 패턴 순위 평가 오류 (EP Ranking) | 4% | 20% |
| 비개체 증거 문제 (Non-Entity Evidence) | 54% | 30% |
| 정답 추론 오류 (Answer Reasoning) | 8% | 0% |
| 데이터 품질 문제 (Data Quality) | 8% | 14% |
관찰된 결과는 다음과 같습니다.
숫자 추론이 많은 경우 어려움이 발생합니다. 많은 오류가 수치와 관련되어 있으며, 현재의 IR-KGQA로는 한계가 있습니다. 또한, 비엔티티 정보나 수치적 패턴을 포함시키는 방법이 필요하지만, 현재의 답변 추론은 이러한 정보를 처리하는 것에 한계가 존재합니다.
반대로, EPR의 경우, 노이즈를 줄이는 것에 효과적임을 확인했습니다. 그 근거로, CWQ 데이터셋에서 추론 단계에서 단 8%만의 불완전한 답변 추론 오류가 발생했습니다.
그리고 번외로, 일부 질문에서는 주석의 품질 문제가 확인되었습니다. 예를 들어, "What kind of language do Egyptians speak?"라는 질문에 대해 시스템은 "Egyptian Arabic"을 정답으로 예측했지만, 이는 주석된 정답 집합에 포함되지 않아 오류로 간주되었습니다.
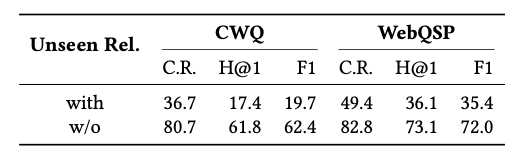
추가로, 훈련 데이터에 없는 관계(Unseen relation)이 구현 과정에서 문제로 드러났습니다. 이러한 상황에서 성능은 급격히 감소합니다.
6. Conclusion
위 연구에서는 IR-KGQA의 성능을 향상시키기 위해 EPR(증거 패턴 검색)이라는 새로운 접근법을 제안했습니다. 해당 연구의 목표는 Subgraph Extract단계에서 구조적 의존성을 명시적으로 모델링하여 노이즈 감소 및 응답 속도 개선을 달성하는 것이였습니다.
해당 모델은, 엔티티, 관계가 연결되어 특정 질문에 대한 정답 노드를 지원하는 Evidence Pattern 개념을 도입하고, 이를 통해 기존 방법의 한계였던 구조적 종속성에 대해 해결했습니다.
하지만, 아직은 검색 임계값이 낮거나, 새로운 관계가 포함된 질문에서는 아직 한계점이 보입니다. 그렇기에, 더 강력한 모델 or 관계 인식 모델 개발이 필요합니다.
또한, 효율적인 패턴 열거 알고리즘과 속도 최적화 기법이 필요합니다. CWQ의 경우, AP 수가 증가하면, Combination Explosion이 발생해 실행 시간이 크게 증가했습니다.
또한 현재 EPR은 아직, 수치적 특성, Non-Entity Evidence에 대해 취약합니다.
그리고, In-context learning과 결합해 적은 학습 샘플로도 SOTA를 달성해야 합니다.
→ 결국, 구조적 의존성에 대한 모델링, 노이즈 감소 및 정확한 서브그래프에 대한 장점을 보이며 SOTA를 달성했습니다. 다만, 아직은 위와 같은 개선 사항이 더 필요합니다.
