[Paper Review] TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation
Abstract
언어모델은 많은 지식, 일반화 능력을 통해 자연어 분야에서 우수한 성능을 보여왔습니다. 그렇지만, 추천 분야에서는 기존에 In-context Learning을 통해서 LLM이 추천 작업을 수행하도록 학습했지만, 언어 생성과 추천 작업의 간극으로 인해 성능이 제한적이었습니다.
→ 이를 해결하기 위해 TALLRec 모델이 제안되었습니다.
TALLRec 모델은 추천 데이터을 LLM에 튜닝하여 추천 언어 모델을 구축하는 프레임워크입니다. 이 모델은 다음과 같은 특징과 장점을 가지고 있습니다.
- RTX 3090과 같은 적은 VRAM으로도 사용이 가능합니다.
- 100개 미만의 소규모 데이터셋에서 좋은 성능을 보입니다.
위 모델은 소규모 데이터로도 충분한 능력을 보여줬으며, 추천 능력을 상승시켰고, 도메인 간 일반화 성능이 뛰어나, 다른 분야에서의 추천 작업 모두 좋은 성과를 보였습니다. (ex, 도서 및 영화)
1. Introduction
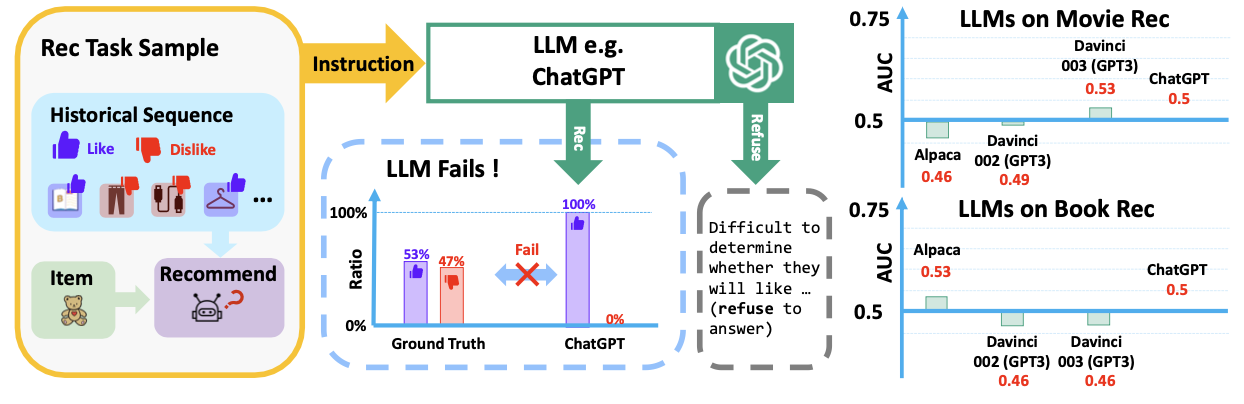
LLM은 자연어 처리를 중심으로 다양한 분야에서 성과를 도출하고 있습니다. LLM은 또한 많은 지식과, 명령에 따라 새로운 작업을 수행하는 일반화 능력 역시 좋은 성능을 보여줍니다.
이런 상황에서, 추천 영역에서 강력한 일반화와 풍부한 지식이 잘 적용될 수 있는지 대두되기 시작했습니다. 다만, 전통적으로 LLM은 In-context Learning을 활용해 LLM이 추천 작업을 수행하도록 시도했지만, 아직 추천 시스템에서는 그러한 성능이 잘 나오지는 않았습니다.
그 원인은 다음과 같습니다.
- 작업 간 격차 : LLM은 추천보다는 자연어 처리 중심의 모델입니다. 즉, 목적의 간극이 크다는 것이죠.
- LLM 훈련 과정에서 추천 중심의 데이터가 너무나도 부족합니다.
실제로, In-context Learning 만으로는 추천 작업 성능이 랜덤 수준(AUC=0.5)와 별 차이가 없고, 일부는 심지어 응답을 거부하거나 긍정의 답변만 내놓았습니다. 무언가 추가로 더 필요하다는 점이죠.
In-context Learning
LLM이 파라미터 업데이트를 별도로 수행하지 않고, 주어진 context에서 학습하는 능력을 말합니다. 이는 모델이 사전 학습된 후, 별도의 Fine-tuning없이 새로운 작업을 수행하게 할 수 있습니다.
Zero-shot, One-shot, Few-shot 등 예제를 프롬프트에서 제공합니다.
이러한 문제를 해결하기 위해, 대규모 추천 언어 모델(LRLM)을 구축할 필요가 있습니다. 이를 위해서 Tuning을 수행해 추천 작업에서 더 잘 수행할 수 있도록 모델을 정렬하는 과정이 필요합니다.
이를 위해 제안된 방법이 TALLRec입니다.
TALLRec을 말하면, 추천 시스템을 위한 작업에 특화되게, 효과적이고 효율적으로 조정하는 튜닝 프레임워크입니다.
- TALLRec은 가벼운 데이터셋(샘플 100개 미만)으로도 LLM 추천을 쉽고 정확하게 수행할 수 있습니다.
- 다양한 도메인에서도 일반화 역시 강력한 성능을 보이고, 적은 자원을 소모합니다,
이 과정에서 LORA Fine-tuning과 같은 경량 튜닝 기술을 사용하였고, LLaMA-7B 모델을 기반으로 수행했습니다.
LORA (Low-Rank Adaptation of Large Language Model)
LLM과 같은 사전 학습된 신경망을 효율적으로 fine-tuning을 수행하기 위한 방법입니다.
→ 모델 전체를 다시 학습시키는 방법이 아닌, 모델 파라미터의 저차원 부분만 학습하여 학습 속도를 높이고 메모리 사용을 줄이는 효과를 낳습니다.
LORA에 대한 자세한 설명은, LORA 논문을 읽어보시면 좋을 것 같습니다.
2. TALLREC
2.1 Preliminary
Instruction Tuning
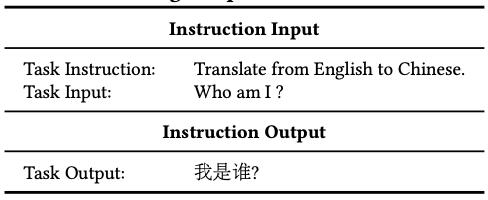
Instruction Tuning은 사람의 지시(자연어), 응답 데이터를 사용해 LLM을 훈련합니다. 여기서는 다음의 과정을 거칩니다.
- Task Instruction : 자연어로 수행해야 할 작업을 정의합니다.
- Task Input, Output : 작업 입력과 출력을 자연어로 구성합니다.
- Instruction Input: 작업 정의와 입력을 통해 모델에 제공할 Instruction input을 지정합니다. 이에 대응하는 Instruction output 역시 지정합니다,.
- Instruction tuning : instruction input, output을 사용해 튜닝을 진행합니다.
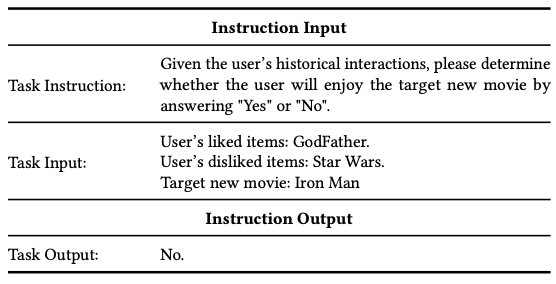
Rec-tuning Task Formulation
해당 과정에서는 사용자의 과거 상호작용 데이터를 기반으로, 새 항목에 대한 사용자의 선호도를 예측하도록 구성됩니다.
이 과정에서 데이터는 다음의 구성을 가지고 있습니다.
- 사용자가 좋아하는, 싫어하는 항목 목록
- 새로운 추천 항목(goal)
- Yes or No의 결과
2.2 TALLRec Framework

해당 프레임워크에서는 2단계의 Tuning Stage를 거칩니다. Alpaca Tuning, Rec-Tuning 2단계로 구성이 됩니다.
전자는 LLM의 일반화 능력을 향상시키는 훈련 과정이라면, 후자는 Instruction tuning pattern을 활용해 LLM을 추천 작업에 맞게 조정하는 것이라고 할 수 있습니다.
- Alpaca Tuning : Self-instruction Data를 활용해 LLM을 훈련합니다.
위 식의 주요 설명은 다음과 같습니다.
Z : 훈련 데이터 집합 (alpaca instruction data)
: instruction input
: instruction output
: 출력 y의 t번째 토큰
: t번째 이전의 모든 토큰
alpaca tuning 모델은 입력 와 출력 의 앞부분 를 조건으로 현재 토큰 가 생성될 확률 을 최대화하도록 학습합니다. 이는 LLM의 언어 모델링 목표를 나타내며, 조건부 언어 모델링 접근 방식입니다.
- Rec-Tuning : 추천 튜닝 샘플을 사용해 LLM을 튜닝합니다.
Lightweight Tuning (경량 튜닝)
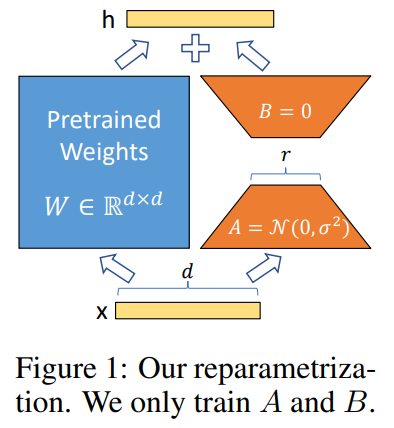
직접적인 LLM 튜닝은 계산 비용이 높기에, LoRA를 사용하여 경량 튜닝을 수행합니다. 우리는 이를 사용해서 Alpaca, Rec-tuning을 모두 수행합니다.
이 과정에서 핵심은 현재 언어 모델이 과도한 매개변수를 가지며, 정보가 낮은 고유 차원에 집중되는 것입니다. 즉, 전체 모델을 튜닝하지 않아도 일부 파라미터만 조정해 유사 성능을 낼 수 있습니다.
- 이 과정에서, 모델의 주요 매개변수를 고정하고, 변형 행렬(Decomposition Matrices)만 학습합니다.
- 전체 매개변수의 1/1000만 튜닝해도 원래 모델과 유사한 성능을 얻을 수 있습니다. (추가 정보를 효율적으로 통합)
이 과정에서는 LLM의 고정된 파라미터 와 LoRA 튜닝 파라미터 를 결합해 모델의 성능을 최대화합니다. 여기서는 오직 LoRA 튜닝 파라미터만 훈련됩니다.
Backbone Selection
TALLRec는 오픈 소스 모델 중 LLaMA-7B 모델을 선택했습니다.
3. Experiments
주요 실험은 3가지로 나뉩니다.
- RQ1 : TALLRec은 기존 모델과 비교해 얼마나 뛰어난 성능을 보여주는가?
- RQ2: TALLRec의 각 구성 요소는 모델 성능에 어떤 영향을 미치는가?
- RQ3: TALLRec은 도메인 간 일반화 성능이 우수한가?
데이터셋은 MovieLens100K(영화 부분), BookCrossing(도서) 데이터를 사용합니다. 그리고 이 데이터에서 각각의 기준에 따라 likes, dislikes로 구분하였습니다.
Few-shot training setting에서는 제한된 수의 샘플만 무작위로 선택해 학습시켰습니다. 예를 들어 K=64이면, 64개의 훈련 샘플을 사용한다는 것입니다.
비교하는 기준 모델은 다음과 같습니다.
- LLM-based Methods
- In-context Learning 접근 방식을 사용하여 사용자가 추천합니다.
- 동일한 Instruction input을 사용해 평가했습니다.
- Alpaca-LoRA : LoRA, Alpaca 튜닝 활용한 LLaMA 모델
- Text-Davinci-002: OpenAI의 GPT 모델
- Text-Davinci-003: OpenAI의 최신 GPT 모델
- ChatGPT: OpenAI의 ChatGPT 모델
-
Traditional Methods
- GRU4Rec: 사용자의 상호작용을 순차적으로 인코딩하는 RNN 기반 모델
- Caser: CNN 기반의 시퀀스 추천 모델
- SASRec: Transformer 기반의 시퀀스 추천 모델
- DROS: 강건한 추천을 위한 최신 시퀀스 추천 모델
텍스트 결합 모델은 GRU-BERT, DROS-BERT를 사용했습니다.
평가 지표는 ROC-AUC를 주요 평가 지표로 사용했습니다.
그 과정에서 세부사항은 다음과 같습니다.
- Adam Optimization, MSE를 사용해서 학습하였고 lr은 0.001을 사용했습니다.
- 상호작용 시퀀스의 길이가 기준보다 짧은 경우, 마지막 상호작용 항목으로 패딩했습니다.
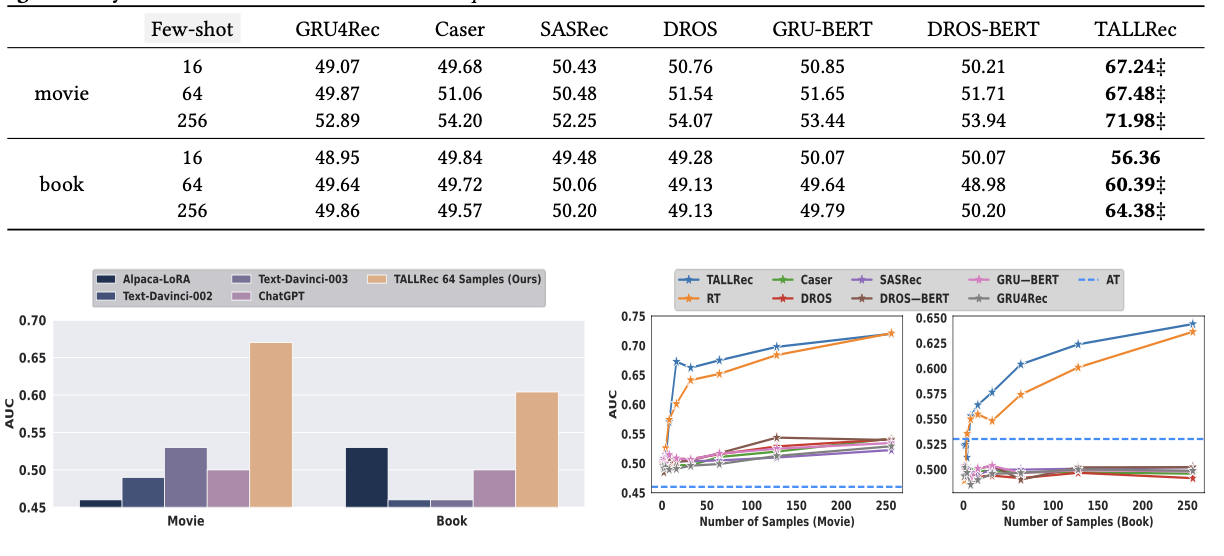
3.1 Performance Comparison(RQ1)
해당 과정에서는 소수 샘플 학습 설정에서 다양한 기준선 모델과 TALLRec의 추천 성능을 평가했습니다.
TALLRec은 기존 추천 모델과 LLM 기반 모델을 모두 능가했으며, 소수 샘플 학습에서도 뛰어난 성능을 보였습니다.
이는 전통적인 추천 모델의 소량 데이터에서의 약점, In-context Learning의 한계를 극복했다고 할 수 있습니다.
3.2 Ablation Study(RQ2)
해당 과정에서는 3가지로 구분해서 결과를 평가했습니다.
- AT : Alpaca Tuning만 → 훈련 샘플이 적을 때 일반화 성능 향상
- RT : Rec-Tuning만 → 추천 데이터 학습
- AT + RT : Alpaca, Rec Tuning 모두 수행
평가 결과, Rec-Tuning의 중요성을 확인했습니다. AT를 적용하지 않아도, RT만 적용했을 때, 더 높은 성능을 보였고, 추천 데이터가 LLM의 성능 향상에 필수임을 확인할 수 있었습니다.
단, AT만 적용한다면 성능이 향상되지 않습니다.
또한, AT, RT를 모두 결합했을 때, 가장 높은 AUC 점수를 기록했으며, 데이터 샘플 수가 적은 경우에는 AT의 일반화 성능이 큰 기여를 했습니다.
3.3 Cross-domain Generation Analyses(RQ3)
다음의 케이스로 구분하여 일반화 성능을 평가했습니다.
- TALLRec(Movie): 영화 데이터로만 학습
- TALLRec(Book): 도서 데이터로만 학습
- TALLRec(Both): 두 도메인 데이터를 함께 학습
평가 결과, TALLRec(Movie) 모델은 도서 추천에서도 높은 성능을 보였으며, 반대의 경우도 유사했습니다. 이는 LLM이 특정 도메인에만 집중되는 것(과적합)이 아닌, 좋은 성능의 일반화 능력을 보여줍니다.
또한, 두 도메인 데이터를 함께 학습했을 때, 둘 다 최고의 성능을 보였습니다. 즉, 다중 도메인 학습이 모델 성능을 추가로 높일 수 있다는 것을 확인했습니다.
4. Related Work
LM for Recommendation (언어 모델 기반 추천)
언어 모델을 추천 시스템에 통합하는 경우는 기존에도 여러번 존재했습니다.
일부 기존 연구는 여전히 사용자와 항목 ID를 사용해 사용자와 항목을 나타내므로, 언어 모델의 의미적 이해 능력을 충분히 반영하지 못합니다.
반대로, 일부 연구는 리뷰와 같은 텍스트 정보를 사용해 언어 정보를 사용자 및 항목 임베딩의 일부로 통합했습니다. 이 과정을 통해 범용성에 대한 문제를 해결했습니다.
모델 상으로는, 이미 추천 기능이 포함된 비공개 모델이나, 소형 모델을 사용해 Downstream task 데이터를 학습했지만, 추천 작업에 맞게 조정하는 방법을 성공하지는 못했습니다.
최근 연구들의 경우는 In-context Learning 접근 방식을 사용했는데, Chat-Rec와 같은 대화형 추천 시스템, 기존 추천 모델을 사용해 후보를 생성하고 다단계 튜닝으로 Reranking하는 NIR(Natural Interaction Recommender) 등이 있습니다.
Sequential Recommendation(순차적 추천)
순차 추천은 사용자의 과거 상호작용 시퀀스를 기반으로 다음 상호작용을 예측하는 것을 목표로 진행했습니다.
초기에는 Marcov chain 을 기준으로 시퀀스 추천을 진행하고, 이후 심층 학습 기반 모델이 대세가 되었습니다.
GRU4Rec, Caser 등의 RNN, CNN 활용 모델이 있었고, Transformer 활용 모델인 SASRec도 있었습니다.
추가로, Robust Recommendation 부분에서는 분포 강건 최적화(Distributionally Robust Optimization)를 활용해 최악의 경우 사용자 경험을 개선했습니다.
5. Conclusion
LLM의 발전에 따라 추천 시스템의 잠재성은 올라갔고, 이를 활용하는 연구가 많이 등장하고 있습니다. 단, 최고 수준의 LLM에서도 아직은 추천작업에서 좋은 성능을 보이지는 않았습니다.
하지만, TALLRec는 Alpaca Tuning, Rec-Tuning을 통해 기존 모델을 능가하는 추천 시스템 프레임워크를 갖췄고, 도메인 간 일반화 성능이 무엇보다도 뛰어났습니다. 이로써, LLM이 특정 도메인에 얽매이지 않고, 여러 도메인에서 강력한 추천 성능을 발휘할 수 있음을 확인했습니다.
이제는, 더 큰 모델에서 추천 능력을 높이고, LLM이 여러 추천을 동시에 처리할 수 있도록 방향으로 나아가야 합니다.
