[Paper Review] KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph
Abstract
LLM은 지금까지, 자연어 이해, Zero-shot capacity를 활용해 다양한 분야에서 좋은 성과를 보였지만, 복잡한 추론이나, 논리적 순서가 필요한 작업에는 한계점이 존재합니다.
특히 Question-Answering에서 부정확성, Hallucination을 유발하는 문제가 발생합니다.
위 연구에서는, 이러한 문제를 해결하기 위해 KnowledgeNavigator 프레임워크를 제안합니다.
기본적으로 KnowledgeNavigator은 지식 그래프에서 외부 지식을 정확하고, 효율적으로 검색하여 LLM의 추론 능력을 향상시키는 것을 목표로 하는 프레임워크입니다.
KnowledgeNavigator은 다음의 과정을 거칩니다.
- 질문의 제약 조건 분석하여 추론 방향 설정 (Question Analysis)
- 지식 그래프로부터 필요한 정보를 반복적으로 수집(Knowledge Retrieval)
- 구조화된 정보를 LLM 친화적인 형식으로 변환해 Qnestion Answering 진행 (Reasoning)
해당 프레임워크의 성과로, 다른 모델에 비해 효율적이고, 일반화 능력이 상승했습니다.
Why?
기존 Question-Answering에서 LLM이 복잡한 추론에 있어서 정확하지 못한 답변과 Hallucination을 유발하는 케이스 발생
How to solve?
KnowledgeNavigator을 도입 (3가지 과정을 통해) : Question Analysis → Knowledge Retrieval → Reasoning
1. Introduction
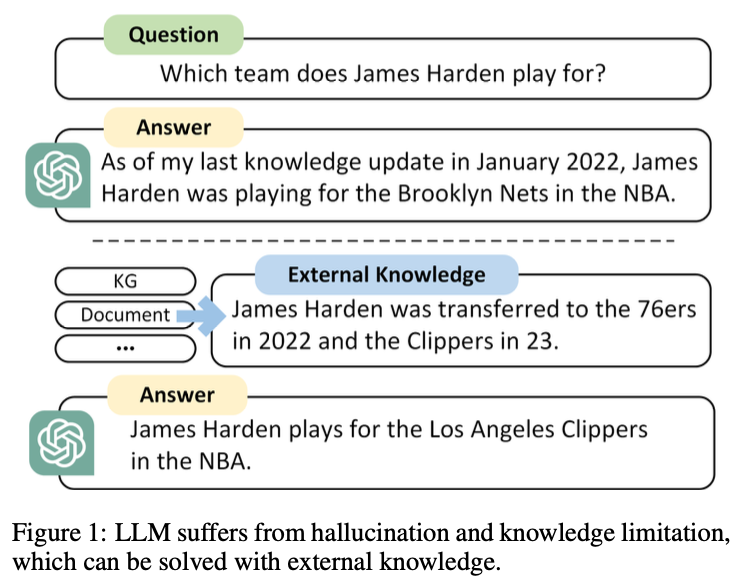
LLM은 현재, 다양한 Downstream Task에서는 좋은 성능을 발휘하고, NLP 연구 등에서 높은 성과를 보입니다. 하지만, 다음의 문제가 존재합니다.
- Knowledge limitation : 오래되거나 부정확한 정보 및 전문 지식 부족으로 인한 문제
- Hallucination : 존재하지 않는 정보 생성 (ex, 세종대왕 맥북 사건)
- 긴 논리적 순서나, 복잡한 구조를 다루는 내용에 대해서는 어려움 존재
→ 이 문제를 해결하기 위해서, 지식 그래프를 활용하여 external knowledge에 접근합니다.
지식 그래프, Knowledge Graph는 구조화된 데이터로 지식을 표현하기에, 논리적 추론을 지원하기에 적합합니다. 또한, Multimodal knowledge를 제공하며, LLM의 Knowledge limitation 문제를 보완할 수 있습니다.
💡 의 형태로 정보 제공하여, 논리적 추론 작업에 더 적합함.
다만, LLM의 성능을 향상시키기 위해서는 다양한 엔티티, 관계로 구성된 Multi-hop 추론 경로를 기억해야 합니다. 이에 관련해서, 3가지의 해결해야 할 사항이 있습니다. 다음의 Multi-hop으로 인해, KG와 LLM을 결합하려 할 때 문제가 발생합니다.
- 주어진 질문과 무관한 경우가 발생하여, 비효율적 검색과 추론 발생
- Multi-hop으로 인해 검색량이 늘어나, 효율성 감소
- 구조화된 데이터를 처리하기 위한 LLM의 제한적인 역량 (Pre-train, Fine-tuning 필요)
→ 이러한 문제를 해결하기 위해, KnowledgeNavigator 프레임워크를 제안합니다.
KnowledgeNavigator
KnowledgeNavigator은 다음 3가지 과정을 거치며 진행됩니다.
- Question Analysis : 질문의 논리적 구조를 분석해, 필요 검색 범위 예측, 유사 질문 생성
- Knowledge Retrieval : 필요한 지식만 반복적으로 검색 및 필터링
- Reasoning : 검색된 지식을 LLM 친화적인 프롬프트 형태(자연어 형태)로 변환합니다.
이 과정을 거쳐, LLM의 Knowledge limitation을 보완하고, KG를 사용해 Multi-hop 추론을 지원합니다. → 데이터 중복 최소화와 Triple 데이터 처리의 한계를 극복합니다. (Natural Language Understanding)
해당 프레임워크의 성능을 평가하기 위해, MEtaQA, WebQSP 데이터에 Multi-hop 지식 그래프 추론을 사용하였습니다. LLM에는 LLaMA-2-70B, Chatgpt를 사용했습니다.
추가로, Ablation Study(소거 연구)를 이용해 각 구성 요소의 중요성을 확인해본 결과, 모든 구성요소가 효과적임을 확인했습니다.
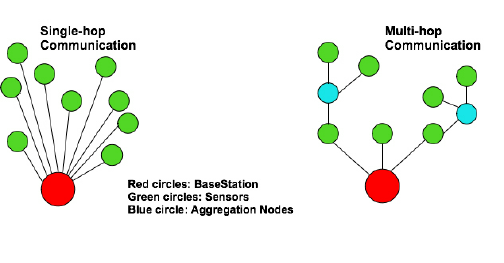
Multi-hop
여러 단계의 추론이나 검색 과정을 거쳐 답을 도출하거나 정보를 연결하는 방법을 말합니다.
Single-hop에서 찾을 수 없는 복잡한 질문이나 문제를 해결합니다.
ex) Q : 제임스 카메론이 감독한 영화의 주연 배우가 출연한 다른 영화는?
A1 : 제임스 카메론이 감독한 영화 찾기
A2 : 해당 영화의 주연 배우가 출연한 다른 영화 찾기
2 Related Work
2.1 Knowledge Reasoning for KGQA
KGQA는 지식 그래프를 활용해 주어진 질문에 대한 답변을 생성하는 것을 말합니다. 이는 entity, concept, relation을 포함하는 구조화된 네트워크를 말합니다. 불완전성, 다양한 노이즈 같은 Question Answering의 한계를 극복하기 위해 지식 그래프에 대한 추론이 필수라고 할 수 있습니다.
초기 지식 그래프의 경우는, 주로 논리 규칙에 의존했습니다.
이 과정에서는, 특정 도메인에 맞게 설계했으며, 해석 가능성이 높았지만, 수작업 문제와, 일반화되지 못하는 문제가 발생합니다.
다음으로는 Representation Learning(표현 학습)을 사용했습니다.
이는 엔티티와 관계를 저차원 벡터 공간으로 임베딩하여 잠재적 의미 관계를 학습하고, 이를 통해 최적의 답을 도출하는 방법입니다. 해당 케이스의 결과, 성능 향상은 이루었지만, 임베딩 모델의 표현력에 크게 의존하고, 해석 가능성이 낮다는 문제가 발생합니다.
최근에는 복잡한 Multi-hop 문제를 해결하기 위해, Neural Network를 도입했습니다.
이 과정에서는 그래프, 엔티티 간의 상호작용 패턴을 학습하여 자동화된 정확한 추론을 가능하게 합니다. 이로 인해, 추론 모델의 일반화 성능을 높였습니다.
→ 지식 그래프에서는 불완전성 문제와 노이즈가 아직 존재합니다. 데이터에서 올바르지 못한 데이터를 많이 포함할 수 있다는 것이죠. 이를 해결해야 합니다.
2.2 Knowledge Graph Enhanced LLM
지식 그래프는 지식을 구조화된 형태로 표현하여 ,다양한 지식을 저장하고 활용할 수 있는 장점을 가지고 있습니다.
구조화된 형태, 명확한 논리, 추론 경로를 가지고 있어, 다양한 지식 저장 및 사용 요구를 충족할 수 있습니다. 그로 인해서 LLM의 추론 능력과 Knowledge limitation문제를 해결할 수 있습니다.
그렇지만, Retraining, Pre-train을 하게 된다면, 자원 소모량이 많아지고, 그에 따라 시간과 비용 소모가 큽니다.
그렇기에 이것을 해결할 수 있는 방법으로, 지식 강화 프롬프트를 활용하고 있습니다.
이는 external retrieval 알고리즘을 활용해 질문에 대한 지식을 검색하고, 이 결과를 프롬프트에 포함하는 방법입니다. 그렇기에, 자연어 기반 표현으로 변환하여 LLM에서도 논리적인 추론이 가능합니다.
3 Method
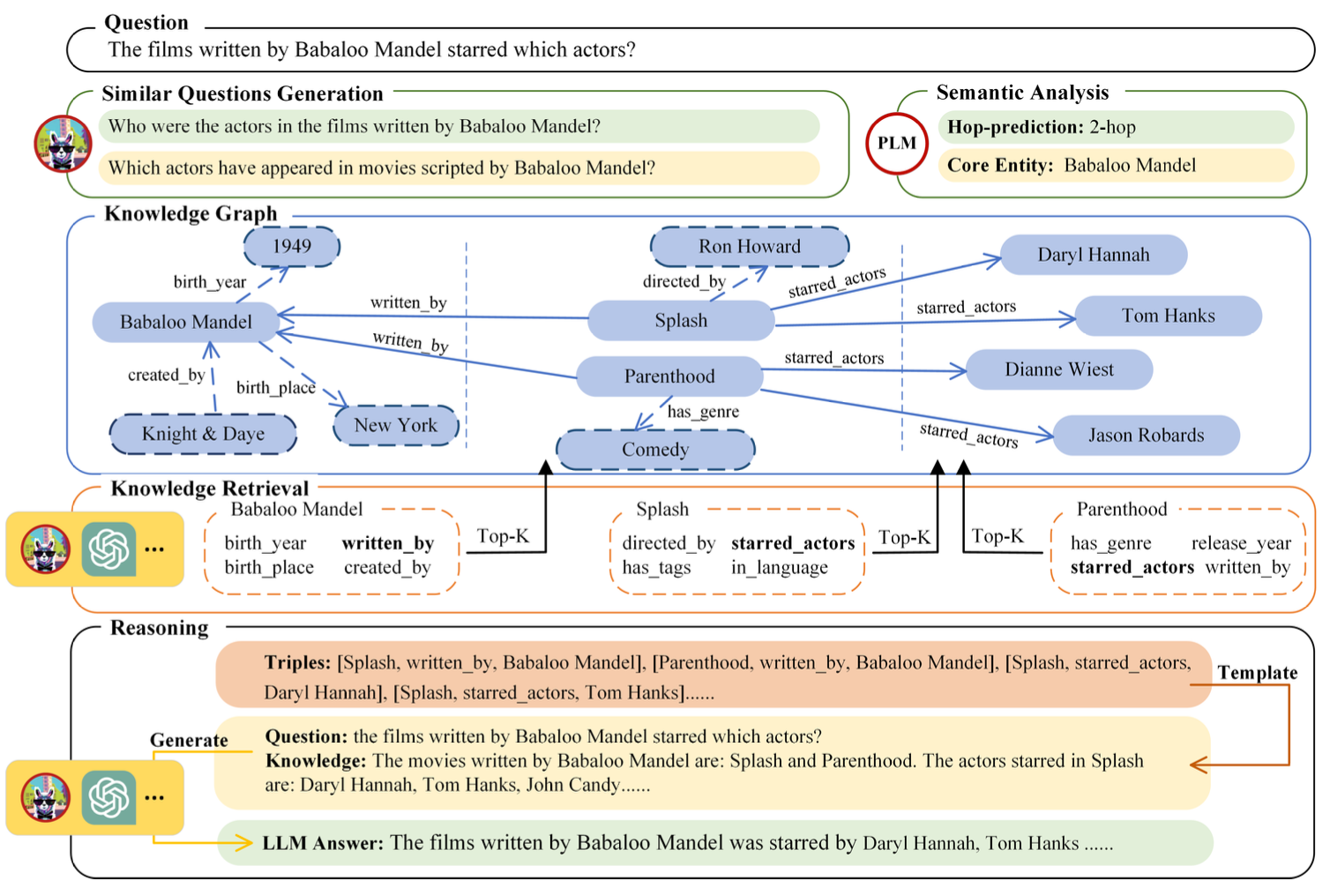
3.1 Question Analysis
Question Analysis에서는 다음의 2가지를 목표로 수행합니다.
- 질문의 논리적 추론 경로를 파악하고, 필요한 검색 범위와 hop 수(추론 깊이)를 예측합니다.
- 유사 질문(variants)를 생성하여 다양한 관점으로 추론을 보완합니다.
Pre-analysis 단게에서는 추론을 제한 및 향상시켜 지식 그래프에서 추론을 지원합니다. 이를 통해서 검색 효율성과 정확성을 높이는 효과를 보입니다.
여기서, 질문 에 답하기 위해, KnowledgeNavigator은 잠재적 hop number 를 찾아야 합니다. 이러한 과정을 거쳐, 핵심 엔티티에서 필요한 정보를 제공합니다.
이를 위해, Hop number을 예측하는 과정은 다음 2가지 식을 사용합니다.
예측 방법을 간단하게 설명하면, Pretrained LM과 Linear Classifier을 결합해 hop number을 예측합니다.
먼저, 질문 에 대한 PLM으로 벡터 표현 를 생성합니다.
다음으로, 각 hop 수 에 대한 확률 분포를 통해 최댓값을 선택합니다. (여기서, 는 깊이 에 대한 확률 분포를 말하고, 여기서는 최대의 확률 하나만 계산합니다.
다음 과정으로는, 원래 질문을 변형하여 유사 질문을 생성합니다.( {}) 이때, LLM을 활용해서 같은 의미를 가진 다양한 질문 변형을 생성하며, 이는 추론 논리를 다양한 관점에서 보완합니다.
💡여기서 유사 질문을 생성하는 수는 예측된 hop number, 의 개수만큼입니다.
Ex) Babaloo Mandel에 참여한 영화의 배우는?
- "Babaloo Mandel이 각본을 쓴 영화에 출연한 배우는 누구인가?"
- "Babaloo Mandel의 영화에서 활동한 배우는 누구인가?"
이러한 프로세스로 Knowledge Retrieval과정에서 사용할 정보를 더 풍부하게 만드는 것이 Question Analysis에서 수행하는 과정입니다.
3.2 Knowledge Retrieval
Knowledge Retrieval에서는 질문에 관련된 지식만 선택적으로 검색하고, 불필요한 정보를 줄이는 과정을 수행합니다. 즉, Multi-hop 추론에 필요한 경로를 구축하는 것이죠.
지식 그래프에서 관련 정보를 검색해서 논리 경로를 구성한다면, 집중적이고, 효과적인 하위 그래프로 답변 생성에 도움을 줍니다. 해당 연구에서는 라는 제한된 깊이로 반복 검색 과정을 수행합니다.
이 과정에서 핵심 엔티티 집합을 으로 설정합니다.
먼저, 각 엔티티에 연결된 1-hop 관계를 탐색해 후보 관계 집합 을 탐색합니다. 이 과정에서 불필요하거나, 노이즈에 대해 답변 생성이 영향을 미치지 않도록 하는 것이 중요한데, 각 엔티티에 대한 후보 관계를 문자열로, 질문 변형 과정을 통해 LLM 프롬프트로 제공합니다. 여기서 LLM은 질문 변형을 기반으로 에서 가장 관련성 높은 K개의 relation(관계)를 선택합니다.
relation filtering 결과를 바탕으로, 릴레이션을 순위화합니다. 그 과정에서 다음의 식을 사용합니다. (가중치 기반 투표 매커니즘)
점수 측정 시, 은 하나의 질문 에 대한 가중치를 말하며, 은 LLM이 relation r을 선택했는지의 여부입니다.
여기서 는 원래 질문과, 생성된 질문 변형에 따라 가중치를 다르게 주며, 원래 질문에는 2배의 가중치를 부여합니다. 그리고 여기에서 선택이 되었다면 1, 그렇지 않으면 0으로 설정합니다.
다음으로, 개의 최적 관계를 선택한 다음, 지식 그래프로부터 triple을 검색합니다. (head, relation, tail)
두가지 형태로 query를 수행하는데, 의 형태로 나타냅니다.
검색된 triple은 여기서 추론 경로의 일부가 되며, 검색된 지식 집합 에 포함됩니다. 그리고 탐색되지 않은 tail 및 head 엔티티는 다음 반복 단계의 핵심 엔티티 집합 로 컴파일됩니다.
이 과정은 Question Analysis에서 예측된 hop number에 도달할 때까지 진행합니다. 완료 이후, 는 Reasoning 단계에서 사용될 지식으로 활용합니다.
3.3 Reasoning
Reasoning 단계에서는 지식 검색 단계에서 추출된 정보를 활용해 질문에 대한 최종 답변을 생성하는 과정을 수행합니다.
필요한 지식을 Knowledge Retrieval 과정에서 담은 를 바탕으로 질문에 대한 답변을 생성합니다.
해당 형태에서 데이터는 의 형태로 담겨있으며, 질문에 관련된 정확한 답을 찾기 위해서는 여러 triple에서 관계, 엔티티를 연결해 추론 경로를 구성하고, reasoning sub-graph를 생성해야 합니다. 그 과정에서, 이 triple을 병합하여 추론 경로를 단순화해야 LLM의 추론 효율성을 높일 수 있습니다.
여기서, 병합 식은 2가지를 사용합니다.
동일한 head를 가진 triple을 병합할 때에는 (5)의 식을, 동일한 tail을 가진 triple을 병합할 때는 (6)의 식을 사용합니다.
이후에 병합된 triple을 자연어 템플릿으로 변환합니다. 변환 예시는
“The {relation} of {head} is(are) {tail}.” 입니다.
다음의 형태로 자연어 형태로 LLM에 프롬프트를 제공하고, 이를 기반으로 최종 답변을 생성합니다. 이때, LLM은 검색된 외부 지식만을 사용하며, 자체 학습된 지식을 사용하지 않습니다.
4 Experiments
실험 데이터셋에는 2가지를 사용합니다.
- MetaQA : 영화 도메인에서 사용
- WebQSP : 지식 기반 벤치마크
성능 평가에 있어, 다음의 모델과 비교할 것입니다.
Fully Supervised Models:
- KV-Mem: 메모리 기반 질의응답 모델.
- GraftNet: 지식 그래프와 텍스트를 결합하여 사용하는 모델.
- EmbedKGQA: 임베딩 기반으로 지식 그래프를 학습.
- NSM, UniKGQA: 다중 홉 추론을 지원하는 최신 모델들.
LLM 기반 모델:
- StructGPT: LLM을 통해 지식 그래프 데이터를 구조적으로 활용.
- TOG: LLM과 지식 그래프를 결합한 추론 모델.
사용될 LLM은 다음과 같습니다.
- Llama-2-70B
- Chatgpt
데이별로, 다음의 과정 평가를 진행합니다.
MetaQA에서는 1,2,3 hop을 예측하도록 설정합니다.
WebQSP에서는 각 엔티티와 관계를 2-hop까지 확장하도록 설정합니다.
그리고, 일부 실험에서는 훈련 데이터의 예제 2개를 추가로 제공해 Few-show 학습 효과를 확인합니다.
실험 결과는 다음과 같습니다.
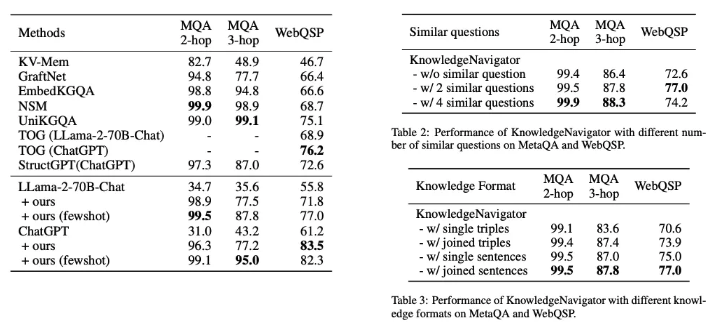
METAQA에서는 기존 모델들에 비해 더 좋은 성과를 낸 것을 확인했습니다.
WebQSP에서는 KnowledgeNavigator가 83.5%로 다른 LLM 기반 모델보다 월등히 좋은 성능을 보였습니다.
다음으로는, 각 부분이 성능에 미치는 영향을 분석하기 위해, Ablation Analysis(소거 연구)를 진행했습니다.
여기서는 유사 질문 변형의 개수, 지식 표현 형태가 성능에 미치는 영향을 분석했습니다.
Impact of Number of Similar Questions
MetaQA에서는 변형 질문이 많아질수록, 성능은 좋아졌지만, 그만큼 계산비용이 증가했습니다.
WebQSP의 경우에는 ,질문의 퀄리티가 낮아, LLM이 동일한 의미를 가지는 유사 질문 생성에 어려움이 있었습니다.
최적 설정의 경우, 2-hop입니다.
Impact of Knowledge Formats
KnowledgeNavigator의 성능에 지식 표현 형식이 미치는 영향, 동일한 지식을 다른 표현 형식으로 변환하여 LLM에 프롬프트로 제공하는 과정을 거칩니다.
지식 입력의 경우, triple 본래보다, 자연어 형태로 제공할 때 성능이 올라간 것을 확인했습니다. 추가로, 지식 표현의 논리적 밀접성(logical closeness)이 증가함에 따라 향상된 것을 확인했습니다. 즉, 병합된 지식을 자연어 형태로 사용하는 것이, 중복 정보를 효과적으로 줄이고, LLM에서 추론의 난이도와 오류를 낮출 수 있었습니다.
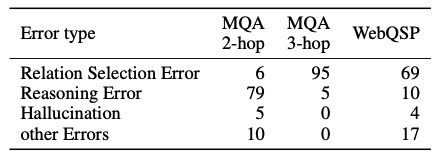
Error Analysis에는 다음 4가지가 존재합니다.
- 관계 선택 오류 : 잘못된 관계 선택
- 추론 오류 : 답변 생성 과정에서 잘못된 경우
- Hallucination : 외부 지식 기반하지 않고, 답하는 경우
- 기타 오류 : 검색 중단 or 긴 컨텍스트로 지식이 잘리는 경우
MetaQA의 경우, 2-hop에서는 추론 오류, 3-hop, WebQSP에서는 관계 선택 오류가 중심이였습니다.
MetaQA 3-hop과 WebQSP의 경우는, 질문 자체가 더 복잡한 의미적 구조를 가지고 있어, 관계 추론 능력이 요구됩니다.
반대로, MetaQA 2-hop의 경우는 논리가 간단해 LLM이 잘못된 관계를 선택하는 경우는 적었지만, 추론 능력이 부족한 경우가 많이 있었습니다.
이 정보를 바탕으로 KGQA 작업에서 LLM의 성능을 향상시키기 위해, 2가지 방향으로 진행해야 합니다.
- 질문의 의미를 강화하거나, 지식 그래프와 추론 경로 간의 연결을 강화해 관련 관계 선택하게 해야 합니다.
- 프롬프트와 지식 표현을 최적화해 LLM이 보다 효과적으로 추론할 수 있도록 지원해야 합니다.
5 Conclusion
KnowledgeNavigator은 LLM의 Knowledge limitation 문제와 복잡한 추론 능력의 한계를 극복하기 위해 도입되었습니다. 이는 다음 3가지 과정을 거쳤습니다.
- Question Analysis : 질문 사전 분석, 변형 질문 생성해 추론 지원
- Knowledge Retrieval : LLM의 지도 학습으로 지식 그래프 내 후보 엔티티와 관계를 반복적으로 검색하고 필터링해 관련 외부 지식 추출
- Reasoning : 효과적인 프롬프트로 변환해 LLM이 지식 집약적인 작업에서 성능 개선할 수 있도록
KGQA 작업에서 KnowledgeNavigator을 평가한 결과, 지식 그래프에서 제공되는 External knowledge를 활용하면, LLM이 복잡한 작업을 처리하는 데 큰 도움이 됨을 확인했습니다. 또한 기존 KGQA 프레임워크보다 여러 방면에서 우수한 결과를 확인하였고, 이전의 Fully Supervised Model과도 경쟁력 있는 성능을 보입니다.
또한, Ablation Study(소거 연구)를 통해 각 구성 요소가 전체 성능에 미치는 효과를 확인했고, 오류 분석으로 향후 연구 방향을 도출했습니다.
6 Limitations
기존의 KGQA보다 성능이 좋은데도, 다음의 한계점이 존재합니다.
- KnowledgeNavigator은 여러 문장으로 구성된 프롬프트를 기반으로 구성됩니다. 이는 즉, 자연어 이해 및 추론 능력에 크게 의존하기에, 파라미터 개수가 작은 모델이나, context 길이가 짧은 LLM에서는 힘들 수 있습니다.
- KnowledgeNavigator은 LLM과 여러 번 상호작용하면서 수행합니다. 그렇기에, 처리 시간이 길어질 수 있고, 응답 시간에 제한이 있다면, 잘 맞지 않게 됩니다.
그렇기에, LLM의 성능에 의존하지 않고, 논리적 추론을 향상시킬 수 있는 방법에 대한 연구가 필요합니다. 이는 응답 속도 개선과 처리 효율성을 높이는 것이 필요합니다.
