[Paper Review] USER-LLM: Efficient LLM Contextualization with User Embeddings
Abstract
LLM에서는 최근, 노이즈가 많은 user timeline 데이터를 LLM에 효과적으로 통합하는 것이 도전과제로 자리잡고 있습니다.
주로 사용하는 사용자 타임라인을 텍스트 설명으로 변환해서 LLM에 통합하는 것은 비효율적이고, 미묘한 차이를 반영하지 못하는 가능성이 존재합니다. 그렇기에, 이러한 문제에 대한 보완이 필요합니다.
해당 논문에서 제시하는 USER-LLM 프레임워크는 User Embedding을 활용해 LLM을 사용자 history interaction과 직접적으로 맥락화하는 프레임워크입니다.
USER-LLM의 특징이라면, User Embedding이 Self-Supervised Learning으로 사전학습된 User Encoder에 의해 생성되고, 행동, 관심사의 잠재적 특징만이 아닌, 시간에 따른 변화도 포착한다는 이점이 있습니다. 또한, 사용자 임베딩을 cross attention 방식으로 통합해 LLM이 사용자의 과거 행동과 선호도를 발판삼아 동적으로 응답할 수 있게 한다는 특징을 가지고 있습니다.
USER LLM을 평가한 결과, 심층적 사용자 이해가 필요한 작업에서, Text prompt based contextualization보다 우수한 성능을 보였습니다. 즉, 추론 속도 향상을 이끌어 냈고, 효율성을 개선했다는 것이죠. 추가로, Perceiver 레이어의 통합으로 사용자 인코더와 LLM 간의 통합을 간소화하고, 추가적인 계산 절감을 이끌어냈습니다.
Why?
LLM에서 복잡하고 노이즈가 많은 데이터를 통합하여 처리하기가 어렵고, 텍스트로 변환해서 처리하는 경우에는 사용자 행동의 미세한 차이를 충분히 반영하지 못하고, 계산 비용이 높습니다.
How to solve?
USER-LLM에서 사전학습된 User Encoder을 통해 사용자의 행동, 특징 등을 포착하고, Cross Attention을 통해 LLM에 통합하여, 동적으로 응답할 수 있게 합니다. 이를 통해 데이터의 압축, 효율적인 맥락화를 통해 계산 비용이 줄고, 사용자 행동, 선호를 더 깊게 반영할 수 있습니다.
1 Introduction
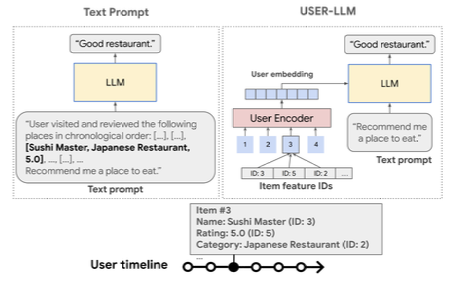
LLM이 대세가 됨에 따라 개인화 AI Agent가 사용자의 요구를와 선호를 이해하고, 응답할 수 있는 시스템 개발에 관심이 커지게 되었습니다. 다만, LLM의 성능이 학습 데이터의 품질과 적절성에 의존하는데, 사용자 타임라인 데이터를 효과적으로 통합하는 것은 여러 이유에서 도전 과제가 됩니다. 지금까지 수행해오던 기존 방식에는 다음의 문제가 존재합니다.
- 사용자 타임라인 데이터에는 복잡하고 노이즈가 포함될 가능성 존재
- 긴 텍스트로 변환 후 모델에 입력하는 방식은, context window가 필요해 높은 계산비용을 초래함
- 텍스트 변환 방식은 사용자 행동의 미묘한 변화를 캐치하지 못할 가능성 존재
하지만, 사용자 타임라인 데이터를 별도의 modality로 간주하고 직접 임베딩한다면
- context window 길이 감소
- 사용자 상호작용의 잠재적 패턴, 시간적 동적 변화 효과적으로 모델링해 LLM이 직접 포착하여 더 깊게 이해할 수 있음
이렇게 2가지의 효과로 기존의 문제를 보완할 수 있습니다.
이를 구현하기 위해 도입한 USER-LLM 프레임워크는 2가지 특징을 가집니다.
- Self-Supervised Learning을 통해 다양한 사용자 상호작용 데이터를 학습해 사용자 임베딩을 사용합니다. 이렇게 생성된 임베딩은 사용자 행동, 관심사, 시간에 따른 변화 효과적으로 캡처합니다.
- 생성된 사용자 임베딩을 LLM에 Cross Attention을 통해 LLM에 통합합니다. 이로써, LLM이 사용자의 과거 행동과 선호를 기반으로 동적 응답 생성할 수 있도록 지원합니다.
성과를 간단하게 말한다면, USER-LLM은 텍스트 프롬프트보다 최대 78.1배 빠른 추론 속도를 냈고,긴 사용자 이력을 필요로 하는 작업에서 16%의 성능 개선을 이루었습니다.
결론적으로, LLM을 사용자 상호작용 데이터와 통합하는 데 있어 새로운 접근 방법을 제공했고, 개인화에 AI Agent에 기여를 할 수 있습니다.
2 Related Work
2.1 Multimodal LLM
초기 Multimodal LLM에는 이미지, 텍스트 표현을 정렬하는데 초점을 두었습니다.
이후에는 Flamingo, Coca와 같이 cross attention을 활용해 입력 데이터 융합하는 케이스가 등장을 했습니다
PaLl, Palm-E는 소프트 프롬프트를 통해 modality에 대한 융합 시도가 있었습니다.
NextGPT, OneLLM과 같은 통합 프레임워크는 다양한 입력 모달리티를 단일 프레임워크에 통합하는 것에 대해 탐구를 진행했습니다.
이러한 케이스에 기안해 USER-LLM의 경우, 사용자 임베딩을 직접 활용하여 LLM을 맥락화하는 것에 초점을 맞췄습니다.
2.2 Language Model based Personalization
텍스트 프롬프트를 사용하는 경우, 사용자의 상호작용 이력을 텍스트로 변환하여 LLM에 입력한다면, 문맥이 길어짐에 따라 계산량이 증가했습니다.
사용자 활동을 기반으로 임베딩 생성하고 이를 활용해 효율적으로 LLM을 맥락화하는 것으로 계산적 부담을 줄이는 것에 초점을 맞추고 있습니다. 최근 연구에서는, soft prompt를 통합하는 방식으로 단순한 텍스트 기반 사용자 활동에 주로 초점을 맞췄습니다.
USER-LLM은 cross attention과 같은 융합 기술을 활용해 효율적으로 LLM 컨텍스트화해 다양한 데이터에서 우수한 성능을 보였습니다.
2.3 Long Context in LLMs
긴 사용자 데이터를 처리하기 위해, 다양한 접근법을 활용했었습니다.
context window 확장 방법으로, 위치 인코딩 재매핑, 특정 attention layer만 추가 컨텍스트 노출시키는 방식을 사용했었고, 정보 압축, modified attention machanism, linear attention framework 등을 사용했습니다.
USER-LLM에서는 각 사용자의 이벤트를 단일 토큰으로 표현하는 방법을 사용했습니다.
2.4 User Modeling
기존 User modeling은 주로 LLM 외부에서 수행했습니다.
- Dual Encoder : 2개 인코더로 사용자, 항목을 임베딩
- Self-Supervised learning : 사용자 데이터에서 특징 추출
- Pretrained Model : BERT 기반 모델 사용해서 사용자 행동 모델링
이런 방법을 사용했습니다.
USER-LLM에서는 사용자 표현을 통해 LLM의 개인화 기능을 향상하는 것에 중점을 둡니다. 사용자 표현을 LLM에 직접 맥락화함으로써 이를 시도했습니다.
3 Methodology
3.1 Problem Statement
는 사용자 집합, 를 아이템 집합이라 한다면,
한명의 사용자 는 timeline sequence 를 가지고 있습니다.
각 아이템 는 특징 집합 을 가지고 있고, 여기서 각 특징 은 해당 값들을 고유한 정수 ID로 매핑하는 vocabulary 을 가지고 있습니다.
예를 들어 설명하면, item이 영화일 때, 을 가지고 있고, 는 text가 ID로 매핑되고, 은 수치형 변수가 ID로 매핑됩니다.
여기서 목표는 주어진 사용자 타임라인 시퀀스 와 쿼리 를 기반으로 LLM이 개인화된 응답 를 생성할 수 있도록 프레임워크 개발하는 것입니다.
3.2 USER-LLM
USER-LLM은 ID 기반의 인코더, Only LLM 전용의 Decoder를 포함합니다.
Inference 과정은 2단계로 이루어집니다.
- 사용자 인코더가 사용자 임베딩 생성
- cross attention을 통해 생성된 임베딩을 LLM에 통합하여 사용자에게 추가적인 맥락을 제공하고 개인화된 응답을 생성하도록 지원
User Embedding Generation
USER-LLM은 Transformer 기반 인코더를 활용해 ID-based interaction sequences로부터 사용자 임베딩을 생성합니다.
각 아이템이 개의 속성을 가지고 있다면, 사용자 타임라인 시퀀스에서 개의 아이템은 다음과 같이 표현됩니다.
여기서, 은 아이템 의 속성 에 대한 ID를 나타냄.
이 한명의 사용자의 timeline sequence임을 기억하면, 해당 식을 이해하기 편할 겁니다. ㅎㅎ 그리고 는 에 포함되어 있는 vocabulary이죠.
여기서 각 ID는 고유한 임베딩 표현을 가지고, 아이템에 대한 통합 표현을 얻기 위해, 서로 다른 속성에서 생성된 임베딩 결합합니다.
임베딩 행렬 은 속성 의 특징에 대한 임베딩 행렬, 는 임베딩 차원입니다.
아이템 의 임베딩은 다음과 같이 결합됨을 알 수 있습니다.
여기서 는 concatenation을 나타내며, 결합된 임베딩의 차원을 줄이기 위해, 를 차원의 로 projection합니다.
Autoregressive User Encoder
Autoregressive Transformer 는 결합된 임베딩 을 Transformer decoder에 입력으로 받아, 임베딩 결과 를 출력합니다.
여기서 은 LLM 맥락화를 위해 사용됩니다.
LLM Contextualization with User Embeddings
USER-LLM은 Cross Attention을 사용해 사용자 임베딩 통합 진행
사용자 인코더의 출력 임베딩 는 projection layer을 통과한 후, LLM의 중간 텍스트 표현과 Cross Attention을 통해 결합됨.
Cross Attention은 다음과 같은 방식으로 수행이 되는데, 우선 에서 는 LLM의 input, 는 와 호환되는 차원을 말합니다.
Cross Attention은 다음 3가지 방식으로 수행됩니다.
추가적으로, USER-LLM은 Gated Cross Attention을 활용해 (scalar value)로 각 layer에서 Cross Attention의 기여도를 조절할 수 있습니다.
여기서 는 Cross Attention을 조절하는 훈련 가능한, 0으로 초기화된 scalar gate입니다. 이 방식으로, Transformer layer, Encoder 출력 간 Cross Attention을 가능하게 하고, 에 의해, 각 레이어별 가중치를 조절할 수 있습니다.
추가로, 임베딩을 소프트 프롬프트로 추가하는 방식으로, 다양한 매커니즘에 대한 적응성을 높일 수 있습니다.
3.3 Training Framework
Training Framework는 2단계로 구성되는데, 사용자 상호작용 데이터에서 정보를 효과적으로 추출하고, 사용자 임베딩에 인코딩된 정보를 이해하도록 LLM을 학습시키기 위해 2단계로 학습을 진행합니다.
User-encoder Pretraining
Autoregressive Transformer을 사용해 사용자 상호작용 시퀀스에 대해 Pretrain하여 입력 데이터에서 정보를 추출하는 방법을 학습합니다.
여기서, Autoregressive Transformer은 ID-based user interactions를 입력으로 받아 임베딩 를 output으로 내놓습니다.
Pretrain을 위해 디코더 출력은 속성별 투영 행렬 을 사용해 원래 특성 차원으로 다시 투영됩니다.
여기서 는 Transformer에서 출력된 번째 임베딩을 말합니다.
Loss Calculation
각 속성에 대해 Cross Entropy Loss가 속성별 projection logit을 사용해 계산됩니다.
여기서 는 속성 에 대한 다음 스텝 의 projection된 결합 임베딩을 말하고, 전체 손실은 속성별 Cross Entropy loss의 손실의 평균으로 계산합니다.
Encoder-LLM Finetuning
다음 단계에서는 사전 학습된 Autoregressive Transformer과 디코더 전용 LLM을 Cross Attention으로 연결하고, 사용자 임베딩과 LLM의 텍스트 표현을 정렬하기 위해 전체 USER-LLM 모델을 파인튜닝하는 과정을 거치게 됩니다.
USER-LLM에서는 다음 4가지 전략을 사용합니다.
- Full : 모델 전체(LLM, 사용자 인코더, projection layer)를 파인튜닝 사용자 상호작용에 최대한 적응하도록 합니다.
- Enc : 사용자 인코더, projection layer만 파인튜닝합니다.
- LoRA : 사용자 인코더와 projection layer와 함께, LLM을 LoRA로 파인튜닝해서 파라미터 효율성을 제공합니다.
- Proj : projection layer만 파인튜닝하고, LLM과 사용자 인코더는 고정합니다.
3.4 Efficiency
text-prompt-based 방법과 비교해서, USER-LLM은 많은 부분에서 효율성을 제공합니다.
1 사전학습된 가중치를 활용하여 모델의 수렴 속도를 높이고, 학습해야 할 파라미터 수를 줄입니다.
2 사용자의 활동을 단일 이벤트 당 하나의 토큰으로 압축해서 표현하기에, 추론 효율성을 높이고, 메모리 사용량이 감소합니다.
3 Cross Attention을 활용해서 사용자 임베딩을 LLM 차원보다 작은 차원으로 유지하기에, train, inference 중 계산 비용이 크게 감소합니다.
4 Perceiver 모듈을 projection layer에 통합합니다.
이때, Perceiver은 학습 가능한 latent query를 사용해서 사용자 임베딩을 압축하여 사용자 히스토리를 나타내는 토큰 수를 줄임.
4. Experiments
실험에는 MovieLens20M, Amazon Review, Google Local Review 데이터를 사용했습니다.
데이터 처리를 진행할 때, 각 사용자의 특징 시퀀스를 슬라이딩 윈도우를 적용해 훈련하고, 테스트 예제를 생성했습니다. 이 경우, N개의 아이템을 포함, 이후 아이템은 라벨로 사용됩니다. 일관된 모델 평가를 위해, 각 사용자의 가장 최근 상호작용은 테스트 예제로 사용했습니다.
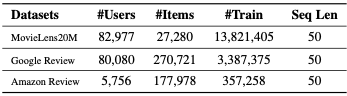
USER-LLM의 성능은 다음의 3가지 관점에서 평가했습니다.
- Next Item Predict : 과거 아이템 시퀀스를 기반으로 다음에 interaction할 아이템 예측
- Favorite Genre or Category Prediction : 아이템 시퀀스를 기반으로 사용자의 선호 장르나 카테고리 예측
- Review Generation : 실제 리뷰 생성
USER-LLM의 성능을 평가하기 위해, 2가지 척도를 제시했습니다.
- Text Prompt (TP) : 사용자 타임라인에서 도출된 raw text input을 사용해 LLM 파인튜닝
- Text Summarization (TS) : 사용자 타임라인에서 도출된 텍스트 요약을 사용해 LLM 파인튜닝
- TS의 경우, 시간 소모가 커서 데이터 개수가 적은 Amazon Review만 사용했습니다.
USER-LLM은 기존 모델들보다 대개 좋은 성과를 보인 것을 확인했습니다.
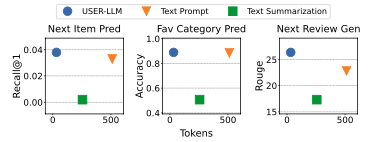
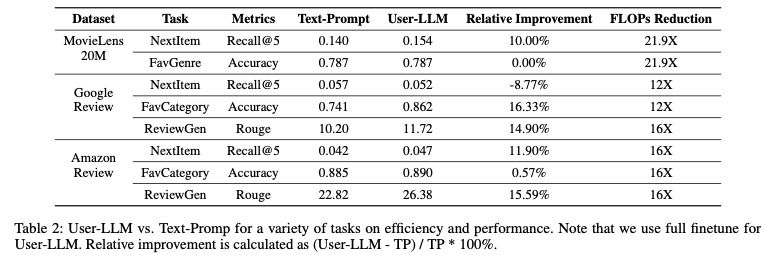
TP 방식에 비해 FLOPs가 12~21.9배 감소했고, 대부분의 작업에서 TP 기준선을 초과하는 성능을 보였습니다.
단, Google 리뷰 데이터셋의 Next Item Prediction에서는 아직 TP 방식이 더 나은 것을 확인했습니다.
즉, 다양한 작업에 대한 일반화로, 사용자 상호작용 데이터에서 깊은 사용자 이해 능력을 선보였습니다.
텍스트 프롬프트 방식에서는 입력 길이가 증가할수록 필요 토큰 수가 증가해서 계산 비용 및 메모리 소모량 증가했습니다. 반대로, USER-LLM은 사용자 활동 시퀀스를 압축된 임베딩으로 변환해 시퀀스 길이와 관계없이 32개로 고정된 길이만 사용했기에, 계산 비용 및 메모리 소모량이 텍스트 프롬프트 방식보다 훨씬 덜 소모되었습니다.

Frozen LLM에서는 Enc 전략에서 TP를 초과하는 성능을 보였습니다. 이는, 사용자 선호도를 효과적으로 컨텍스트화하면서, LLM의 사전 학습된 지식을 보존했습니다. 그렇기에, Fine-tuning을 수행한 LLM과 유사한 성능을 보였습니다.
또한, USER-LLM은 더 적은 매개변수를 필요로 합니다. Enc 접근법에서는 인코더와 projection layer만 파인튜닝해도, 전체 파인튜닝과 유사한 성능을 보였습니다.

Ablation Study
Benefit of Pretraining

사용자 인코더를 Pretrain했을 때, 랜덤 초기화 했을 때와 성능을 비교한다면, Pre-trained encoder을 사용하는 모델이 모든 작업에서 일관되게 더 나은 성능을 보였습니다.
Pretrain이 사용자 선호를 효과적으로 캡쳐해 LLM이 사용자 컨텍스트를 더 잘 이해할 수 있도록 중요한 기초를 제공했다고 할 수 있습니다.
Soft Prompt vs Cross Attention
두 과정을 비교한 결과, Cross Attention이 전반적으로 더 우수한 성능을 보였습니다.
특히, Review Generation과 같은 깊은 사용자 이해가 필요한 경우, Cross Attention이 더 뛰어났습니다.
→ 즉, 사용자 임베딩에 인코딩된 풍부한 정보를 효과적으로 활용할 수 있도록 지원하고, 사용자 의도가 더 잘 반영된 것입니다.
Gated Cross Attention
LLM의 상위 layer에는 더 많이 주의를 기울이고, 하위 layer에는 그렇지 않은 것을 발견했습니다.
상위 layer는 의미적 특징을, 하위 layer은 표면적 특징을 잡는다고 할 수 있습니다. (더 고차원적으로)
5. Conclusion and Future Work
USER-LLM은 사용자 임베딩을 통해 LLM을 맥락화하는 프레임워크입니다.
다양한 사용자 상호작용 데이터에 대해 Self-Supervised Learning을 통해 사전 학습을 진행하고, 사용자 선호와 변화 포착합니다. 이러한 사용자 임베딩을 Cross Attention을 통해 LLM과 통합하여 사용자 맥락에 따라 동적으로 조정되는 응답을 생성하는 것을 목표로 합니다.
USER-LLM에 대한 평가 결과, 사용자 상호작용 기록을 포함하는 작업에서 우위를 보였고, 개인화를 필요로 하는 실시간 애플리케이션에 적합한 것을 알 수 있었습니다.
추후 방향성은 다음과 같이 말할 수 있습니다.
- 사용자 임베딩을 위한 사전 학습 방법 탐구
- 사용자 임베딩, 언어 모델간 alignment 탐구
거기에, 다양한 작업에 훈련하여 더 넓은 범위로 일반화할 수 있도록 나아가는 것 필요합니다.
