[Paper Review] Sequential Recommendation with Latent Relations based on Large Language Model
Abstract
Sequential Recommender System(순차 추천 시스템)은 보통 사용자의 historical interaction 데이터를 바탕으로 다음에 선호할 아이템을 예측합니다.
기존 방법의 경우, 아이템 간의 암묵적인 Collavorative filtering을 활용하지만, 명시적인 아이템 간의 관계를 고려하지 않거나, 수동으로 정의된 관계에 의존하는 경향이 있습니다.
이러한 방법에는 2가지 문제점이 존재합니다.
- 사전에 정의된 관계 및 규칙에 의존합니다.
- 희소성 문제로 인해, 관계 데이터가 부족하거나 불완전해 일반화 능력이 저하됩니다.
이러한 문제를 해결하기 위해, Latent Relation Discovery, LRD 프레임워크를 제안합니다.
이 프레임워크는 LLM을 활용해 아이템 간의 Latent Relation(잠재적 관계)를 탐색하고, LLM의 셀 수 없이 많은 지식을 활용해 자연어 기반으로 아이템 간 관계를 도출합니다. 이 과정에서 DVAE(이산 상태 변분 오토인코더)를 사용해 잠재적 관계를 Semi-Supervised Learning 방식으로 학습하고, 이를 Discovery, 추천 작업과 함께 공동최적화 과정을 진행합니다.
해당 과정을 통해 다음과 같은 성과를 도출했습니다.
- 기존 관계 인식 순차 추천 모델의 성능 향상
- 추가 분석을 통해 LRD가 발견한 잠재적 관계가 합리적이며, 신뢰할 수 있음
- 제안된 프레임워크가 기존 관계 인식 모델에 통합될 수 있어 확장성이 높음.
DVAE (Discrete state Variational AutoEncoder)
- 일반적인 VAE와는 비슷하지만, 연속적인 잠재 공간 대신, 이산적인 잠재 상태(Discrete Latent States)를 사용하는 모델 (여기서는 특정 클래스 혹은 카테고리로 표현됩니다.)
- 텍스트, 카테고리 데이터, 이산적 구조를 가진 데이터를 분석하거나 생성하는 것에 적합한 모델입니다.
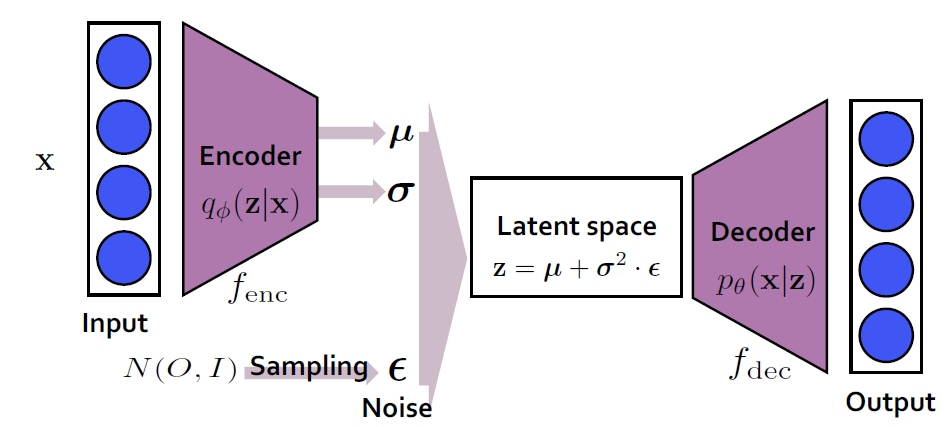
💡 VAE (Variational AutoEncoder)
입력 데이터를 잠재 공간으로 압축한 뒤, 그 잠재 공간에서 다시 데이터를 복원하도록 학습하는 Generative Model입니다.
현실과 비슷한 데이터들을 만들어내는 것을 목적으로 하는 모델입니다.
- Encoder : Input Data를 잠재 변수로 변환합니다.
- Decoder : 잠재 변수에서 Input Data를 재구성합니다.
- 잠재 공간(Latent Space) : 데이터의 중요 특징을 표현하는 저차원 공간입니다.
학습 단계에서는 Encoder, Decoder의 파라미터를 학습하는 것을 목표로 합니다.
각 Latent State 속성을 설명하기 위해, Single value를 출력하는 Encoder를 만드는 것 대신, 각 Latent 속성에 대한 확률분포를 설명하는 Encoder를 만듭니다.
1. Introduction
순차 추천 시스템은 사용자의 과거 상호작용 데이터를 기반으로, 사용자가 다음에 관심을 가질 아이템을 예측하는 것을 목표로 합니다.
이를 위해 초기에는 Markov Chain을 기반으로 아이템 간 전이 관계를 모델링하는 것에 주력했습니다. 그렇지만, 시간이 지나 딥러닝 기법이 사용자의 상호작용 데이터를 더 효과적으로 모델링하기 위해 도입되었습니다.
Markov Chain
마르코프 성질을 지닌 이산확률 과정을 말합니다.
여기서 마르코프 성질이란, n+1회의 상태는 n회의 상태나 그 이전 상태에 의해 결정되는 것입니다.
간단하게 말해, 과거 상태가 현재/미래 상태에 영향을 미치는 것입니다.
기존의 암묵적인 협업 필터링에 의존해 아이템 간 유사성을 계산하지만, 명시적 관계(explicit relation)을 간과하는 경우가 많았습니다.
그 결과, 기존의 연구에서는 2가지 한계점이 있습니다.
- 수동으로 정의된 관계에 의존함.
- 기존 관계 인식 순차 추천 모델은 Knowledge Graph에서 수집한 관계를 사용합니다.
- 그렇지만, 이는 사용자가 사전에 정의한 규칙에 의존하기에, 실제 세계에서의 다양한 아이템 간의 관계를 고려하지 못하는 문제가 발생합니다.
- Sparsity Problem (희소성 문제)
- Relation Sparsity on Edge
- 사전 정의된 관계는 제한적이며, 모든 잠재적 관계를 포함하지 못합니다.
- 사전 정의된 관계에는 동일 카테고리, 공동 구매같은 케이스가 있습니다.
- Item Sparsity on Vertex
- 많은 데이터를 필요로 하는 관계 기반 모델은 데이터가 부족한 경우 성능이 저하됩니다.
- 그렇기에, 관계 정의를 위해 많은 interaction data가 필요합니다.
이러한 한계점들을 해결하기 위해, Latent Relations(잠재적 관계)를 탐색할 수 있는 방법이 필요합니다.
여기서 이번 논문을 통해 제안되는 방법은 Latent Relation Discovery, LRD입니다.
위 프레임워크는 LLM을 활용해 Latent Relations를 발견하는 것을 목표로 합니다.
이를 위해 다음의 과정을 거칩니다.
- 인간이 자연어를 통해 아이템 간 관계를 설명할 수 있다는 것에 기안해, LLM을 활용해 아이템의 언어적 지식 표현을 생성합니다. 이후, 관계 추출 모델이 두 아이템 간의 잠재적 관계를 예측하도록 구성합니다.
- Self-supervised learning을 통해 잠재적 관계를 추출하여 아이템 표현을 재구성합니다.
- 이 과정에서 예측된 관계와 다른 아이템을 기반으로 아이템의 표현을 재구성합니다.
- 잠재적 관계를 기존 관계 인식 순차 모델과 통합하여 공동 최적화 과정을 진행합니다.
해당 연구는 다음의 효과를 지니고 있습니다.
- 수동으로 정의된 관계에 의존하지 않는 모델로서, 잠재적 관계를 다각적으로 탐색 가능한 프레임워크입니다.
- 최적화 목표가 관계 발전 과정을 안내하는 감독 신호로, 추천에 더 유용한 관계를 발견해냅니다.
- LRD가 예측한 아이템 관계를 분석하여, 관계 인식 순차 추천 모델의 해석 가능성을 높였습니다.
2. Problem Statement
우선, 다음의 기호를 주로 사용합니다.
여기에서 각 사용자 의 시간순 상호작용 이력은 { }으로 표현됩니다.
또한 아이템 는 relation 을 통해 다른 아이템 와 연관될 수 있고, 이는 Triplet(삼중항) 로 나타냅니다.
또한 관계 집합 은 사전 정의된 관계 집합 , 잠재적 관계 집합 로 나뉩니다. 여기서 사전 정의된 관계와 관련된 모든 triplet 는 지식 그래프 에 저장될 수 있습니다. 여기에서 vertex 집합은 모든 관계 아이템 쌍으로, edge 집합은 모든 사전 정의된 관계로 구성됩니다.
순차 추천 작업의 목표는 사용자 의 상호작용 를 고려해 다음 아이템에서 추천할 아이템의 순위를 제공하는 것입니다. 여기에서, 각 과거아이템 와 목표 아이템 간의 관계를 추가적으로 고려합니다.
기존의 방법은 만 고려했지만, 본 연구에서는 잠재적 관계 집합 도 함께 고려합니다.
3. Method
3.1 Framework Overview
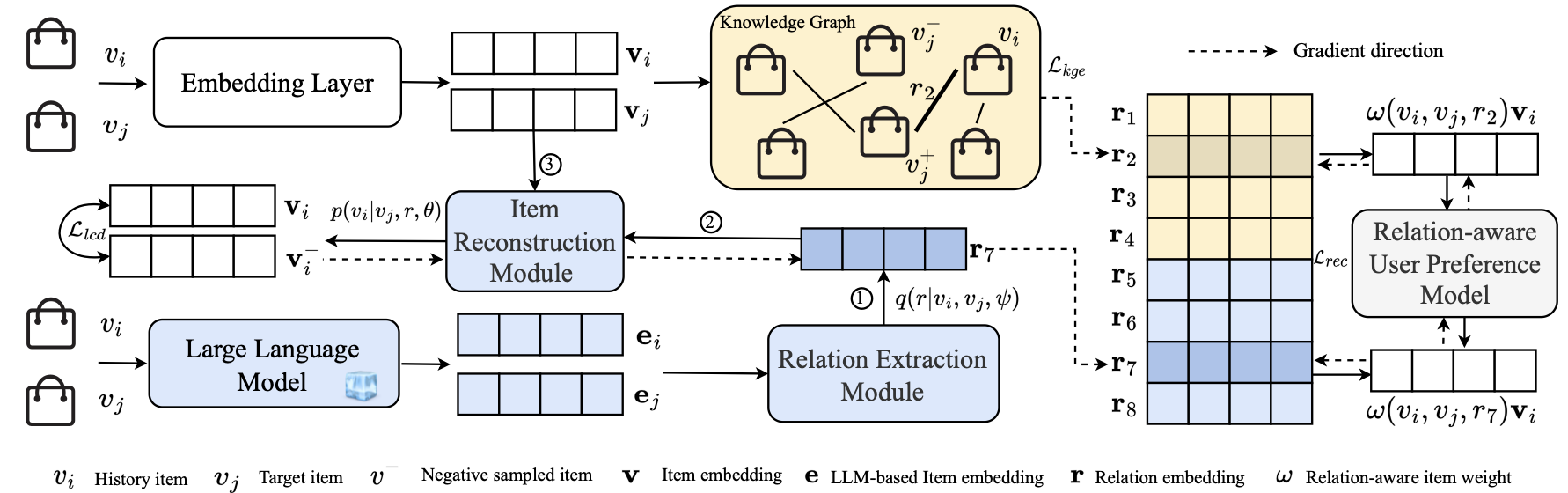
해당 프레임워크의 핵심 구성 요소는 DVAE에서 기안한 Semi-Supervised Learning으로 설계된 잠재적 관계 발견 모듈입니다. 그리고, 기존의 관계 인식 추천 시스템과 통합됩니다. 여기에는 2개의 하위 모듈로 구성됩니다.
- Relation Extraction Module
- LLM을 이용해 아이템 간의 언어적 지식 표현을 얻고, 두 아이템 간의 잠재적 관계를 예측합니다.
- Item Reconstruction Module
- 예측된 잠재적 관계와 하나의 아이템 표현을 기반으로 다른 아이템 표현을 재구성합니다.
이 두 모듈을 수행하면, 추천 시스템에 통합하는 과정을 수행합니다. 이 과정에서 기존의 사전에 정의된 관계, 새로 발견된 잠재적 관게를 모두 활용해 사용자 선호도를 더 정확하게 모델링합니다.
3.2 Latent Relation Discovery (LRD)
3.2.1 Optimization Objective (최적화 목표)
연구의 목표는 데이터 속에 포함되지 않은 관계를 예측하는 것입니다. 이는 눈으로 보이는 데이터셋에 포함되지 않은 것이기에, Supervised Learning을 통해서 훈련할 수 없습니다. 다만, DAVE에서 기안한 Semi-Supervised Learning을 사용합니다. 여기에서는, 모든 관계가 균등 분포 을 따른다고 가정하며, 최적화 목표는 다음의 의사 가능성(pseudo-likelihood)으로 정의됩니다.
여기에서 는 아이템 쌍을 나타내며, 는 Relation Item간 조건부 확률을 나타냅니다. 또한, 는 모델의 파라미터를 말합니다.
여기서 의사 가능성은 젠슨 부등식을 통해 변분 사후 분포(variational posterior) 를 기반으로 하여 하한선을 설정할 수 있습니다.
여기에서,
- 는 관계 추출 모델을 말합니다.
- 는 관계와 또다른 아이템을 기반으로 한 아이템 재구성 모델입니다.
- 는 관계 추출 모델이 예측하는 확률을 정규화하는 엔트로피입니다.
- 는 정규화 강도를 조정하는 하이퍼파라미터입니다.
3.2.2 Relation Extraction (관계 추출)
관계 추출 모델의 목표는, 두 아이템 간의 잠재적 관계를 예측하는 것입니다. 여기에서 언어 지식을 기반으로 아이템 간의 잠재적 관계를 발견합니다. 여기에, LLM을 활용합니다.
주어진 아이템 { }의 각 토큰 를 LLM에 입력해 언어 지식 표현을 얻습니다.
- 은 LLM의 최종 hidden state에 특정 풀링 전략을 적용해 출력 아이템 표현을 얻는 과정을 말합니다.
- 는 LLM 출력의 차원을 축소해 추천 모델의 입력 크기와 일치시키는 투영 레이어의 가중치와 편향을 나타냅니다.
LLM에서 얻은 언어 지식 표현은 수작업으로 정의된 관계 집합에 포함되지 않은 중요 정보를 포함할 가능성이 있다는 것을 기반으로, 관계 추출 모델 는 두 아이템의 언어 지식 표현()을 사용해 관계를 예측합니다. 구현 과정서는 Gradient Backpropogation을 허용하는 모든 분류기를 사용할 수 있습니다. 해당 연구에서는 경량화된 선형 분류기를 사용합니다.
- 는 선형 분류기의 가중치, 바이어스입니다.
- 은 연결 연산을 나타냅니다.
3.2.3 Relational Item Reconstruction (아이템 관계 재구성)
관계 추출 모델을 통해 두 아이템 의 관계를 추정하는 단계입니다. 여기서는 예측된 관계와 아이템 중 하나를 기반으로, 다른 아이템을 재구성합니다.
여기서
위 식은 두 아이템과 관계에 대한 점수 함수이며, DistMult와 같은 함수를 사용합니다.
- 은 관계 임베딩 의 대각 요소를 포함하는 대각 행렬을 말합니다.
(아이템 id 표현)을 사용하는 이유는 관계 인식 추천 모델과 예측된 관계 의 표현 공간을 재정렬하기 위함입니다.
여기서, 계산 복잡성이 높은 전체 아이템 집합 에 대한 계산을 포함하는 바로 위 식을 처리하기 위해, negative sampling을 활용해 를 다음과 같이 근사합니다.
- 는 시그모이드 활성화 함수
- 는 무작위로 샘플링된 negative 아이템입니다.
이 점을 참고해, 최적화 식은 다음과 같이 변경됩니다.
3.3 LRD-based Sequential Recommendation
LRD를 기반으로 한 관계 인식 순차 추천 모델은 다음의 과정을 활용합니다.
3.3.1 Relation-aware Sequential Recommendation (관계 인식 순차 추천)
사용자 의 상호작용 이력 와 목표 아이템 가 주어질 때, 사용자의 선호도는 상호작용된 아이템의 이력에 반영됩니다. 나아가, 각 이력 아이템, 목표 아이템 간의 관계를 명시적으로 고려해 사용자의 선호도를 모델링합니다. 사용자 의 목표 아이템 에 대한 선호도 점수는 다음과 같이 정의합니다.
- 는 사용자와 목표 아이템의 표현을 나타냅니다.
- 은 historical items과 목표 아이템 간의 관계를 고려한 사용자의 이력 시퀀스 표현입니다.
- 는 편향입니다.
여기서 는 다양한 관계 유형을 고려한 사용자 시퀀스 표현의 집계로 계산됩니다.
- 는 mean, max, attention pooling과 같은 다양한 집계 방법을 선택할 수 있습니다.
- 은 사전 정의된 관계, LRD로 발견된 잠재적 관계를 포함하는 집합을 말합니다.
은 사용자 의 역사적 시퀀스 표현으로, 특정 관계 과 목표 아이템 를 고려하여 정의합니다.
- 는 관계 아래에서 historical item , 목표 아이템 간의 관계 강도를 나타내며, 이는 모든 관계에 걸쳐 정규화된 가중치를 표현합니다.
- 는 두 아이템과 관계를 고려한 triplet 점수 함수입니다. (3.2.3에서 사용된 식과 같습니다.)
3.3.2 Joint Learning
관계 인식 순차 추천 작업에 대해 BPR pairwise loss를 사용해 최적화 목표를 정의합니다.
- 는 무작위로 샘플링된 negative 아이템을 말합니다.
여기서, 잠재적 관계 발견을 추천 작업에 활용하고, 동시에 사용자 상호작용 데이터가 관계 발견 과정을 안내할 수 있도록, 잠재적 관계 발견 작업과 추천 작업의 목표를 공동최적화하는 과정을 수행합니다.
추가로, 모델이 사전 정의된 관계를 적절히 모델링할 수 있게, 사전 정의된 관계가 포함된 triplet 를 지식 그래프로 구성하고, 지식 그래프 임베딩 방법을 사용해 아이템과 관계의 표현을 최적화합니다. 여깃에서 최적화 목표는 다음으로 정의됩니다.
마지막으로, 공동 최적화 공식은 다음과 같이 정의됩니다.
- 는 지식 그래프 임베딩 작업, 잠재적 관계 발견 작업에서의 가중치 계수를 말합니다.
4. Experiments
여기에서는 3가지 질문에 대해 답하며 평가를 진행합니다.
- RQ1 : LRD로 강화된 관계 인식 순차 추천 모델의 효과는 어떤가?
- RQ2: LRD로 강화된 관계 인식 순차 추천 모델의 각 구성 요소는 추천 성능에 기여하는가?
- RQ3: LRD는 신뢰할 수 있고 중요한 항목 간 관계를 발견하는가?
4.1 Experimental Settings
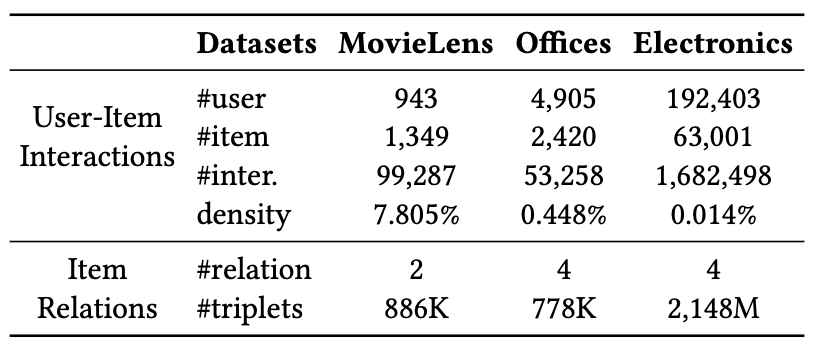
테스트에 있어, 데이터는 MovieLens, Amazon Office Products Electronics를 사용합니다.
모든 데이터셋에서 상호작용이 5회 미만인 사용자와 아이템은 필터링했습니다.
비교 대상 모델은 Caser, GRU4Rec, SASRec, TiSASRec, RCF, KDA 등의 모델을 사용했습니다. Caser, GRU4Rec, SASRec, TiSASRec은 항목 기반 협업 필터링 모델에 속하며, RCF와 KDA는 항목 관계를 명시적으로 통합한 모델입니다.
LRD는 기존 관계 인식 순차 추천 모델을 강화하여, 강화된 RCF, KDA, 즉 RCFLRD, KDALRD의 성능을 비교합니다.
평가 지표로는 HR@K(Hit Ratio@K), nDCG@K를 사용합니다. 여기서 K는 5, 10으로 구성하며, 데이터셋은 leave-one-out 방식으로 구성됩니다.
Leave-one-out 방식
교차 검증 중 하나로, 데이터셋에서 각 데이터를 한 개의 데이터를 테스트 데이터로 사용, 나머지 데이터를 모두 학습 데이터로 사용하는 방식입니다.
해당 연구에서는 마지막 아이템을 테스트, 마지막에서 2번째는 validation, 나머지 아이템은 학습에 사용됩니다.
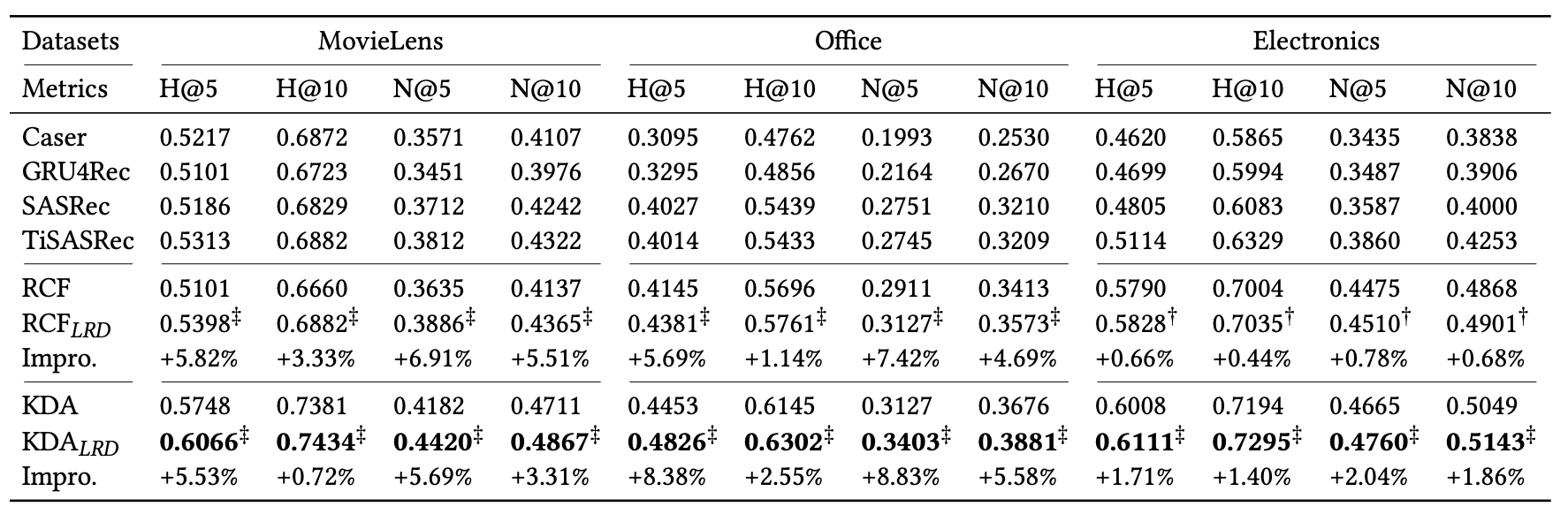
4.2 Performance Comparison (RQ1)
LRD를 통합한 모델인 RCFLRD와 KDALRD 모델이 기존 모델들에 비해 일관적으로 더 나은 성능을 보여줬습니다.
특히 데이터가 많지 않은 Amazon Office Products, Amazon Electronics에서 눈에 띕니다.
즉, LRD를 사용한 모델은 더욱 복잡한 사용자 선호도를 인지하고, 추천 정확도를 높였습니다.
4.3 Ablation Study (RQ2)
여기에서는 3가지 변형 모델을 사용했습니다.
- w/o LLM : LLM 사용하지 않고, 아이템 ID 임베딩만
- w/o KGE : 지식 그래프 임베딩 작업 제거
- w/o LRD : LRD 모듈을 제거하고 기존 모델만 사용
각 요소를 제거할 때마다, 성능이 모두 저하된 것을 확인했으며, 각 요소가 추천 과정에서 핵심적인 역할을 수행하는 것을 알 수 있습니다.
4.4 Latent Relation Analysis (RQ3)
LRD로 학습된 잠재적 관계 임베딩은 사전 정의된 관계 임베딩과 구별되는 특징을 보였습니다. 이는 LRD가 기존에 정의되지 않은 복잡하고 다양한 관계를 성공적으로 탐색함을 나타냅니다.
여기서 나타난 관계는 multi-hop 연결을 통해 파생될 수 있으며, 기존 사전 정의된 관계보다 더 복잡하고 유용한 정보를 제공합니다.
6. Conclusion
해당 논문에서는 LLM을 기반으로 잠재적 아이템 관계를 발견하는 LRD를 제안했습니다. LLM의 많은 지식과 Semi-Supervised Learning을 활용하여 잠재적 관계를 발견하여 더욱 정교한 아이템 간 연관성을 제공하며, 복잡한 사용자 선호를 모델링할 수 있었습니다.
또한, 사용자 상호작용 데이터에서 얻은 감독 신호가 관계 발견 과정을 효과적으로 안내했습니다.
실험 과정에서도 다수의 데이터셋에서 LRD가 기존 모델의 성능을 일관되게 개선했고, 신뢰성과 유용성을 입증했습니다.
이제는, 더 발전된 LLM을 활용해 LRD의 성능을 높이는 것이 과제입니다.

잘 보고 가요~