최근 추천 시스템에서 대세가 되고 있는 Sequential Recommender System에 대한 기본 개념들을 담아봤습니다. 해당 모델들에 대한 자세한 리뷰는 천천히…
조금씩 채워나가는 느낌이라, 계속 수정 예정입니다.
What is Sequential Recommender System?
- 사용자의 이전 행동 순서를 분석해, 다음에 선호할 아이템을 예측하는 추천 시스템
- 전통적인 추천 시스템(Collaborative Filtering, Content-based Filtering 등)과 다르게, 사용자의 시계열 데이터 or 행동의 순서를 활용해 사용자의 관심사와 선호도의 변화를 모델링함
- Sequence Data : 시간이나 순서에 따라 발생하는 데이터를 통합해서 Sequence Data라고 함.
- 사용자의 행동 데이터의 시간적 흐름과 순서를 고려하여 더 개인화되고 맥락에 맞는 추천을 제공하는 Next Item Production
- 현재 존재하는 Sequential Recommender System 예시
- Self-Attentive Sequential Recommendation (SASRec)
- BERT4Rec
- Neural Attentive Session-Based Recommendation (NARM)
- 카카오, 유튜브 등 다양한 웹 매체에서 추천 시스템의 주요 모델로 사용중.
- 카카오의 경우는 BERT4Rec 사용
Why appear?
- 기존 추천 시스템의 한계
- 기존의 Collaborative Filtering, Content-Based Recommendation은 사용자의 행동, 데이터를 변하지 않는 것이라고 간주함. → 특정 시점에서의 선호도, 트렌드를 반영하지 못함. (사용자의 관심도는 계속해서 변함)
- 기존 추천 시스템의 경우, 시간적 순서나 행동의 흐름을 고려하지 않는 문제 존재 → 최근의 행동이 더 중요한 경우, 이를 반영하지 못함.
- 사용자의 선호도를 단일 데이터 스냅샷으로 추출해 추천에 활용함. → 과거에는 좋아하지만, 현재에는 선호하지 않는 항목이 추천될수도 있는 문제 존재
→ 기존의 추천 시스템들은 추천의 퀄리티에 대한 이슈가 존재했음.
- 사용자 행동의 Dynamic한 특성을 반영할 수 있어야 함
- 시간에 따른 관심사 변화를 반영하는 것이 필요
- 사용자는 특정 행동에서 일정한 패턴을 보이는데, 이러한 패턴을 학습해야 맥락에 맞는 추천이 이어질 수 있음
- ex) 오전에는 축구 관련 영상을 보는데, 저녁에는 게임 관련 영상을 보는 사람을 기준으로, 저녁 시간에 추천을 할 때 게임 관련 영상을 추천할 수 있어야 함
- 기술의 발전
- 딥러닝 기반 기술의 등장으로, 시간적 순서를 학습하는 것에 있어 제약이 없어짐.
- 개인화의 필요성
- 즉각적이고 맥락에 맞는, 사용자 개개인에 특화된 추천이 필요함
- 추천의 실시간성과 정확성이 충분히 반영되어야 함
History of Recommender System
- Markov Chain base Models
- 사용자의 이전 상태에 기반한 다음 행동 예측
- 복잡한 순서 패턴이 존재한다면, 이를 모델링하는 것에 한계가 있음.
- RNN 계열의 Neural Network Model
- 순차 데이터 처리에 중심, 오랜 기간의 데이터를 학습할 수 있음
- 많은 데이터(긴 시퀀스)에서 기울기 소실 문제가 발생할 수 있음.
- Transformer 기반 모델
- Self-Attention Mechanism을 활용해 병렬 처리가 가능하며, 장기 의존성 문제를 해결한 모델
- SASRec: Self-Attention을 기반으로 한 대표적인 순차적 추천 모델
- BERT4Rec: BERT 구조를 활용하여 양방향 추천을 가능하게 한 모델
- 강화 학습 기반 모델
- 사용자의 행동을 상태로 보고, 행동과 보상 간의 관계를 학습하여 최적의 추천을 생성.
Representation Learning
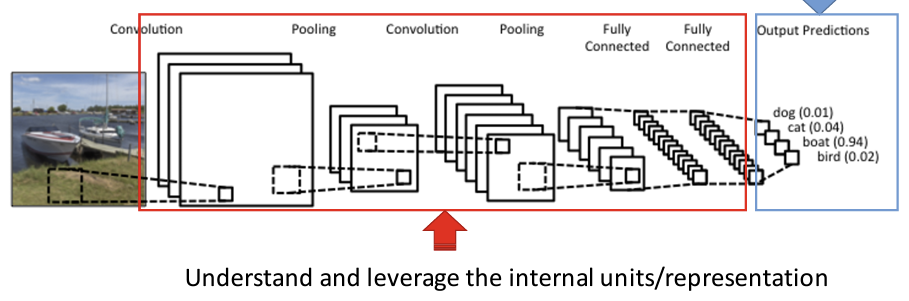
- 원본 데이터에서 유의미한 정보를 추출하고, 이 정보를 새로운 형태의 표현으로 변환하는 과정
- 사람의 직관이나 간섭 없이 데이터로부터 기계가 어떻게 데이터가 표현될 수 있는지를 학습함
- 고차원 데이터를 더 간결한 저차원 공간에 표현해 데이터의 구조적 또는 내재적 특성 반영
- 이미지를 예시로 든다면, 객체를 인식하는 문제에서 표현 학습은 이미지의 원시 픽셀 값에서 유용한 특징(예: 모서리, 질감, 색상 등)을 자동으로 학습하여, 이를 바탕으로 객체를 인식하는 데 필요한 정보를 추출한다.
- 쉽게 말하면, Self-Supervised Learning의 한 종류이다!!
Contrastive Learning
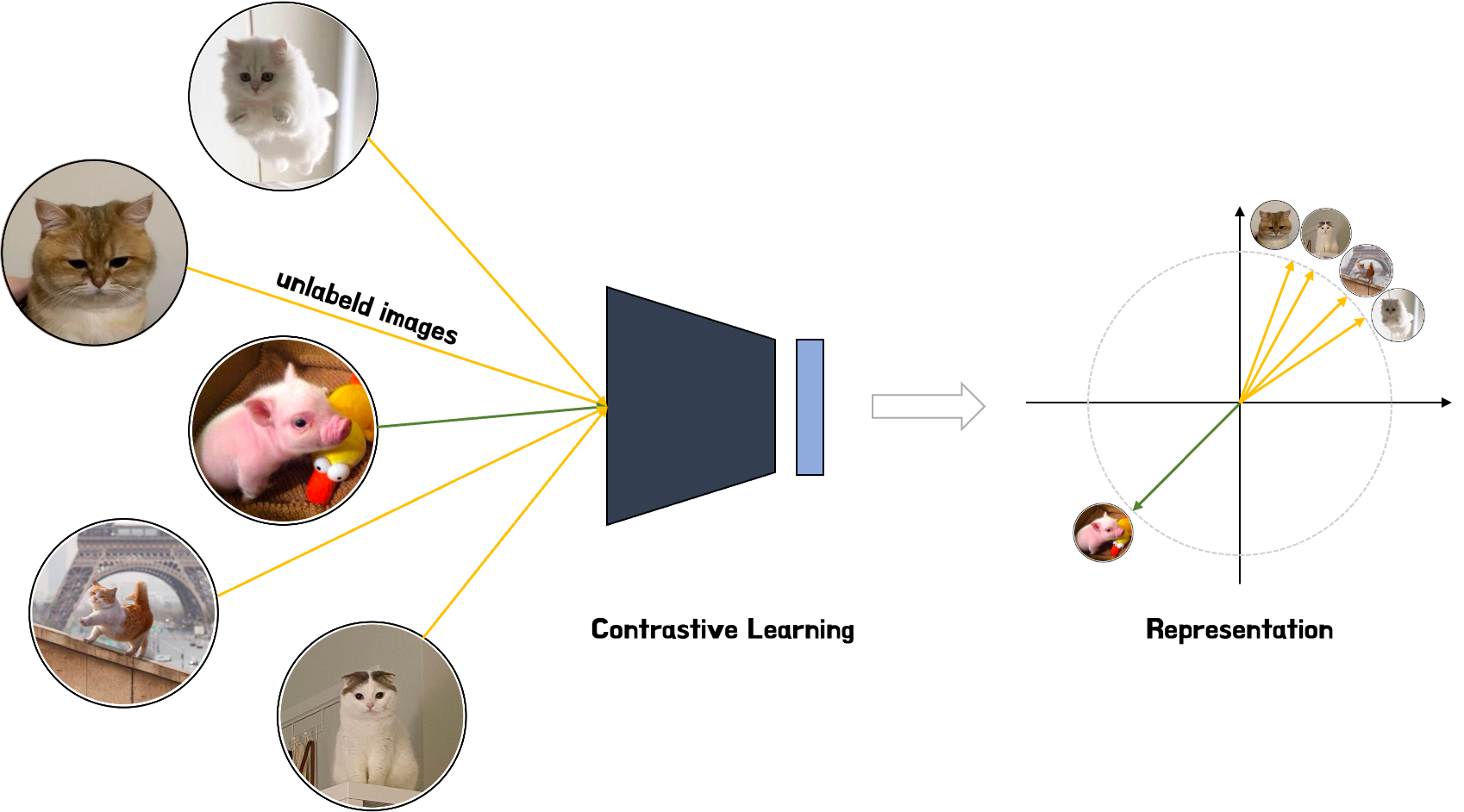
- Self-Supervised Learning 방식 중 하나
- 유사한 데이터는 저차원 공간에서 가깝게, 동시에 다른 데이터는 서로 멀리 떨어지도록 하는 학습 방법
- 유사한 양수 쌍 또는 샘플들의 표현 사이의 거리를 최소화하고, 다른 음수쌍 또는 샘플의 표현 거리를 최대화해 특징을 추출 학습하는 방법
- 특정 예측을 위한 Classification이 아닌, 표현 자체가 의미가 있는지 확인하는 방법이라고 할 수 있음 → 주석이나 레이블이 없어도, 데이터에 대해 많은 것을 학습하도록 모델을 훈련시킬 수 있음.
Contrastive Learning의 작동 방법
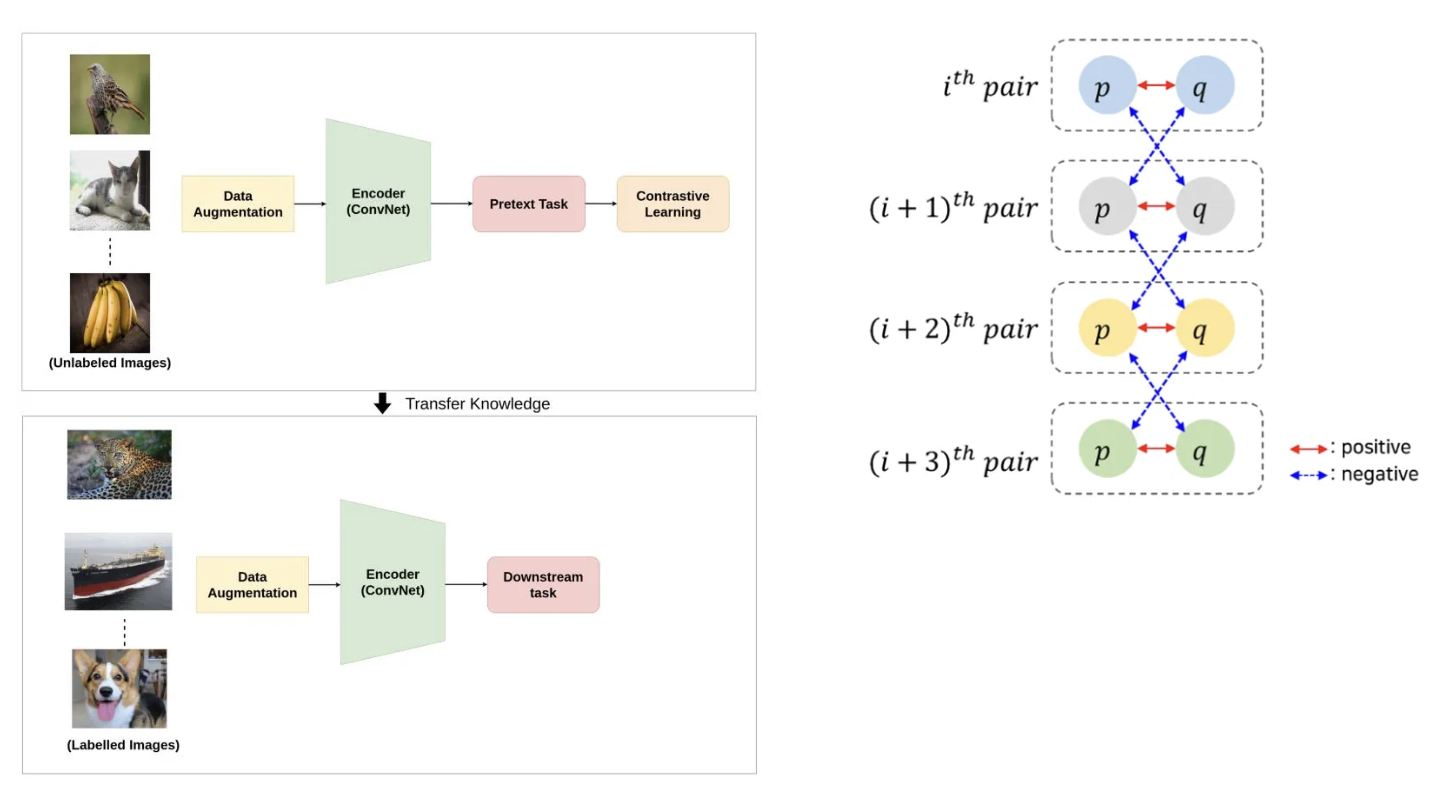
레이블이 지정되지 않은 데이터셋에서 Contrastive loss를 최소화하는 인코더 파라미터를 찾는 것으로 수행된다.
데이터 샘플들 간의 유사성, 차이를 학습해 표현을 효과적으로 학습하는 Self-Supervised Learning의 종류임을 알아야 한다.
비슷한 데이터 샘플(positive pair)은 서로 가깝게, 다른 데이터 샘플(negative pair)은 멀게 위치하도록 임베딩 공간을 학습시키는 것을 진행한다.
(여기서는 이미지를 위주로 설명하지만, 시계열 데이터 등 역시 같은 원리로 작동됩니다.)
-
데이터셋의 각 데이터에 대해 서로 다른 Augmentation을 적용해 Positive pair을 생성 (Data Augmentation)
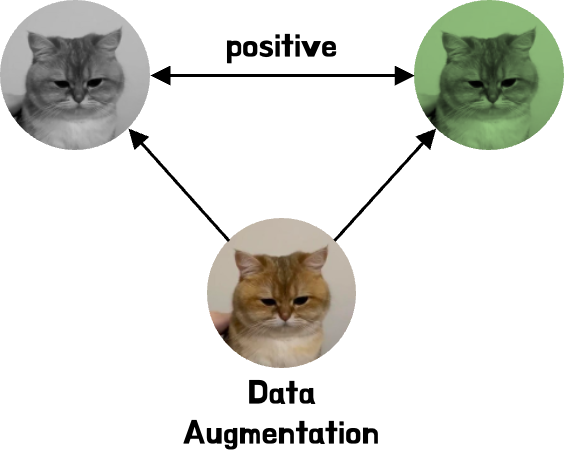
- 이때, 두 이미지는 본질적으로 동일한 이미지의 다른 버전이기에, 두 이미지가 유사하다는 것을 학습하는 것이 목표입니다.
-
임베딩 생성
- 데이터 변환 후, 모델을 통해 임베딩 벡터 생성
- 임베딩의 경우 동일한 공간에서 비교 가능
-
Positive/Negative Pair 비교:
- Positive pair는 임베딩 공간에서 더 가깝게, Negative pair는 더 멀게 학습
- 이 과정에서 입력 쌍에 대해 유사도를 라벨로 Discrimination model 학습을 진행한다.
- 손실 함수 최적화:
- Contrastive Loss or InfoNCE Loss 둘 중 하나로 Positive pair, Negative pair 간의 관계를 학습
-
Contrastive Loss
-
: 배치 크기
-
: 샘플 쌍 가 positive pair인 경우 1, negative pair인 경우 0
-
: 두 샘플 간의 거리, Euclidian 사용
- : 샘플 의 positive pair 임베딩
-
: 마진, Negative pair의 경우, 가 이상이 되도록 유도
-
: positive pair에서 거리를 최소화하기 위한 제곱 거리
-
InfoNCE Loss
-
: 배치 크기
-
: 샘플 의 임베딩 벡터
-
: 샘플 의 Positive Pair
-
: 벡터 간 유사도, Cosine Similarity 사용
-
: 온도 스케일링 파라미터
- Softmax의 스케일을 조정해 Positive pair, Negative pair 간의 구별을 얼마나 강조할지 결정
- 작을수록 민감함
-
- Contrastive Loss or InfoNCE Loss 둘 중 하나로 Positive pair, Negative pair 간의 관계를 학습
- 임베딩 공간 구축:
- 학습이 완료되면 임베딩 공간에서 유사한 데이터가 군집화됨
주요 평가 지표
참조
https://www.blossominkyung.com/deeplearning/contrastive-learning
https://hidemasa.tistory.com/226
https://medium.com/@hugmanskj/표현학습-representation-learning-개요-ea8d6252ea83
