Word2Vec의 장점
- 1) word2vec은 word를 다차원 벡터(vector)공간에 표현하여 벡터간의 유사도를 계산할 수 있게함
- 2) 앞뒤 단어를 고려하여 임베딩을 하기 때문에 단어의 문맥상의 의미까지 정량화된 벡터로 표현 가능
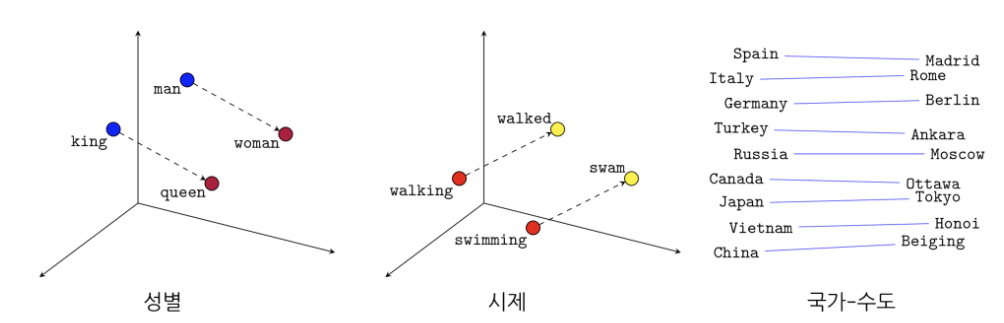
희소표현과 분산표현
1. 희소표현(sparse representation)
- one-hot encoding은 희소표현
- 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법을 희소 표현 이라고 함
- 원-핫 벡터는 희소 벡터(sparse vector)
- 원-핫 벡터 단어간의 유사도를 계산할 수 없다는 단점이 있음
예를 들어서 늑대, 호랑이, 강아지, 고양이라는 4개의 단어에 대해서 원-핫 인코딩을 해서 각각 [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]이라는 원-핫 벡터를 부여받았다고 합시다.
이때 원-핫 벡터로는 강아지와 늑대가 유사하고, 호랑이와 고양이가 유사하다는 것을 표현할 수가 없습니다. 좀 더 극단적으로는 강아지, 개, 냉장고라는 단어가 있을 때 강아지라는 단어가 개와 냉장고라는 단어 중 어떤 단어와 더 유사한지도 알 수 없습니다.
2. 분산표현(distributed representation)
- word2vec은 분산표현임
- 분산 표현 방법은 기본적으로 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법
- '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'라는 가정
- Word2Vec의 2가지 방식 : CBOW(Continuous Bag of Words)와 Skip-Gram
1) CBOW(Continuous Bag of Words)
- CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
- 주변단어로 중심단어를 예측하는 CBOW는 한번의 업데이트 기회만 주어짐

2) Skip-Gram
- Skip-Gram은 중간에 있는 단어로 주변 단어들을 예측하는 방법
- Skip-gram의 경우 업데이트 기회 아래 예시에서 4번이나 확보
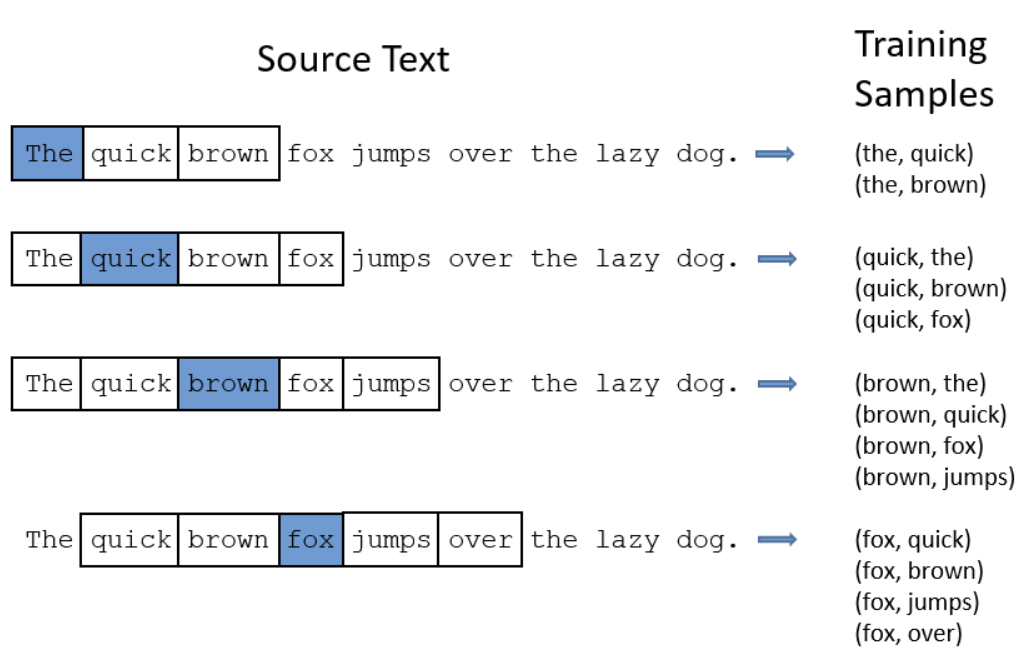
3. 성능 비교
- 주변단어로 중심단어를 예측하는 CBOW에 비해 Skip-Gram의 성능이 좋음
- 언뜻 생각하기에는 주변의 네 개 단어(윈도우=2인 경우)를 가지고 중심단어를 맞추는 것이 성능이 좋아보일 수 있지만(변수가 많으면 성능이 좋아질 것 같다는 생각) 업데이트 횟수 차이로 인해 Skip-Gram의 성능이 더 좋습니다.
- 윈도우 크기가 2일때, CBOW의 경우 주변단어 4개로 단 한번의 중심단어 업데이트를 합니다. 하지만, Skip-gram의 경우 업데이트 기회를 4번이나 확보할 수 있습니다. 말뭉치 크기가 동일하더라도 학습량이 네 배 차이가 난다는 의미입니다.
- 위 그림을 보면
quick단어가 4번의 과정 모두에서 업데이트 됨을 확인할 수 있음
참고url

oneofakindscene