Data Science
1.MCMC(Markov Chain Monte Carlo)

(Reference)참고링크 : 공돌이의 수학정리노트참고링크 : 잠재 디리클레 할당 파헤치기 1~3탄(용어 정리)타켓 분포 : 우리가 샘플을 추출하고자 하는 유사 확률 분포 $\\Rightarrow$ $f(x)$ 로 표기함제안 분포 : 제안 분포 는 우리가 쉽게 샘플을
2.시계열 방법론 : Box-jenkins 방법론
Box-jenkins 방법론 : 시계열 모형의 통계이론 위키 설명 : 박스-젠킨스(Box–Jenkins) 방법은 자동회귀이동평균(ARMA) 또는 자동회귀누적이동평균(ARIMA) 모델을 적용하여 시계열 과거 값에 대한 시계열 모델 최적합을 찾는다 Box-jenki
3.거리 기반 유사도(유클리디안 거리) vs 각도 기반 유사도(코사인 유사도)
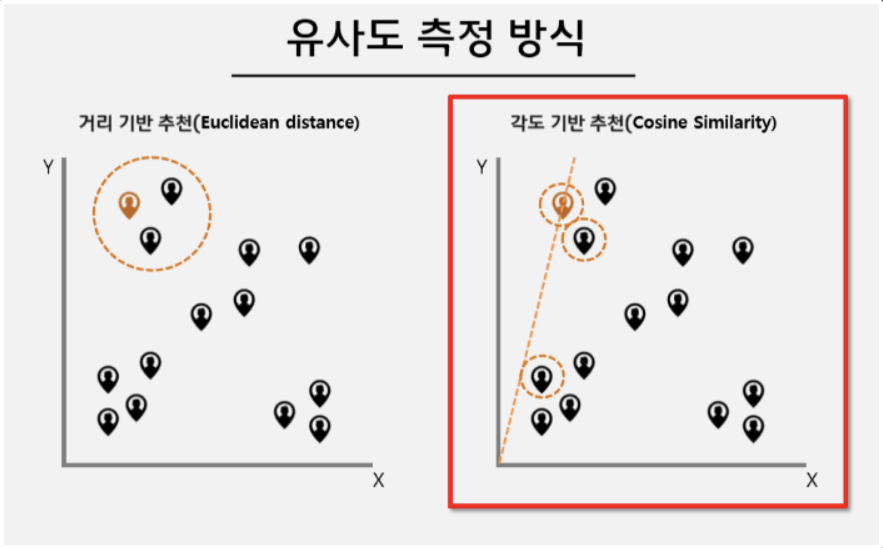
벡터화한 A, B의 유사도를 구하는 방법에는 유클리디안 유사도로 대표되는 거리 기반 유사도와코사인 유사도로 대표되는 각도 기반 유사도가 있다.각도 기반 유사도와 거리 기반 유사도는 언제 사용해야 좋은지 알아보자.유사도 측정 방식 위 그림 중 좌측 그림을 보면 거리 기반
4.PCA는 언제? 왜? 쓸까?
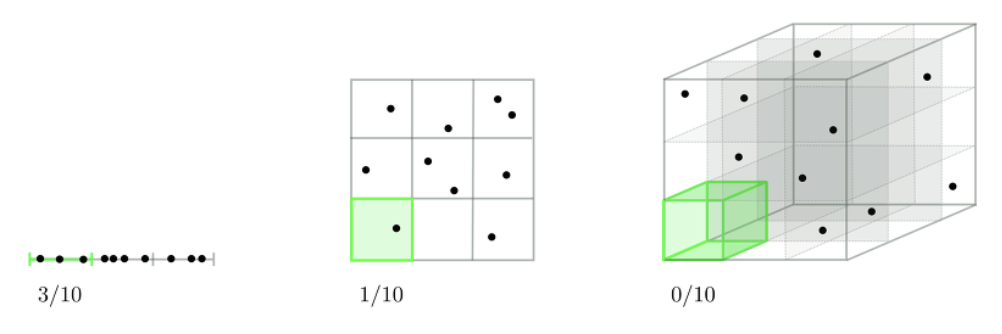
목표 차원축소 알고리즘인 PCA알고리즘에 대해서 정리하고자 함 PCA를 왜 쓰는지 그리고 쓰면 머가 좋은지에 대해서 결론적인 얘기만 하고자함 (질문) PCA를 왜 사용하셨나요?? 흔히, PCA 알고리즘을 차원축소 알고리즘으로 알고있다. 그렇기 때문에 면접때 PCA를
5.word2vec 이해하기
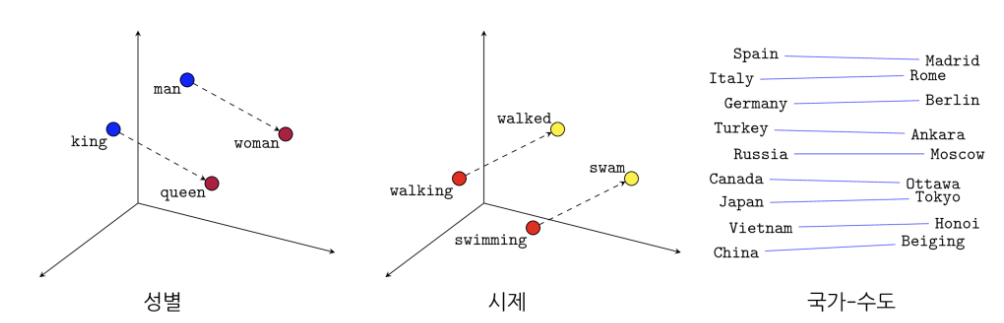
1) word2vec은 word를 다차원 벡터(vector)공간에 표현하여 벡터간의 유사도를 계산할 수 있게함2) 앞뒤 단어를 고려하여 임베딩을 하기 때문에 단어의 문맥상의 의미까지 정량화된 벡터로 표현 가능one-hot encoding은 희소표현벡터 또는 행렬(mat
6.SH-ESD 이상치 탐지
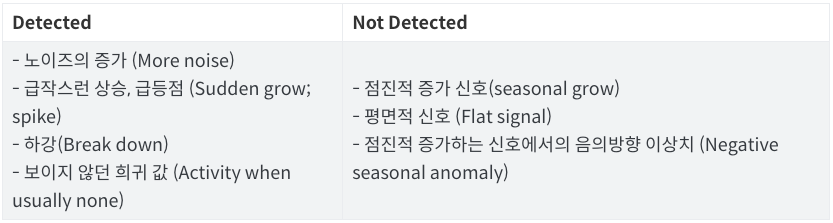
SH-ESD 이상치 탐지
7.정규화(Regularization) 요약
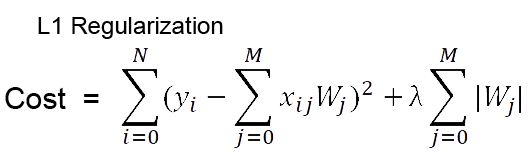
정규화(Regularization) 요약