SQL레벨업
1.Ch.1 DBMS 아키텍처

성능 관점에서 가장 중요한 부분 → 특히 실행계획!!계획 세우고 실행하는 DBMS 핵심기능 담당 모듈SQL 구문 분석기억장치 데이터 접근 순서 결정 (실행계획)접근 메소드실행계획에 기반 둬서 데이터에 접근하는 방법버퍼 메모리 영역 관리데이터 저장 관리데이터 Read /
2.Ch.2 SQL 기초

SQL 관련 기초 설명검색 = 질의(query) = 추출(retrieve)대부분의 경우 FROM 구 사용해야 함.SELECT 1 처럼 상수 접근에는 안 써도 됨.불명한 데이터는 NULL로 처리레코드 선택 시 추가 조건 지정벤 다이어그램을 생각하면 쉽다ANDORINNUL
3.Ch.3 SQL 조건 분기 - 구문에서 식으로

UNION을 이용해 조건분기하는 방식은 성능적 측면에서 굉장히 큰 단점내부적으로 여러 SELECT 구문을 실행하는 실행계획테이블 접근 횟수 증가 → I/O 비용 증가CASE를 이용한 조건분기 권장CASE 식 사용한 조건 분기식을 바탕으로 하는 사고SQL 마스터키 = 구
4.Ch.4 집약과 자르기 - 집합의 세계

집합 지향레코드 단위가 아닌, 레코드 집합 단위로 처리 기술GROUP BYHAVING집약함수윈도우함수집약 함수 (aggregate function)COUNTSUMAVGMAXMIN필드 수가 다르고 한 사람에 대한 정보가 여러 레코드로 나눠져 있는 테이블집약을 사용하면 한
5.Ch.5 반복문 - 절차 지향형의 속박

SQL은 절차 지향적인 사고 방식보다 집합 지향적인 사고가 좋음문제를 레코드 단위까지 작게 나누어 반복문으로 문제를 해결하려는 태도응용 레벨 언어로 프로그래밍을 배웠을때의 폐혜SQL은 반복문이 없음관계 조작(SQL)은 관계 전체를 모두 조작 대상으로 삼음목적은 반복을
6.Ch.6 결합

RDB는 설계적으로 정규화를 거치기 때문에 테이블 수 많아짐여러 테이블에 산재하는 데이터 통합하려면 역정규화 혹은 결합 필요결합은 성능에 영향을 줄 수 있으므로 유의수학에서의 데카르트 곱2개 테이블 레코드에서 가능한 모든 조합 구하는 연산실무에서 잘 쓰지 않음크로스 결
7.Ch.7 서브쿼리

💡 곤란한 부분은 분할해야만 할까? 서브쿼리 SQL 내부에서 작성되는 일시적인 테이블 (일시적 테이블을 영속화한 것이 뷰) 테이블과 기능적 관점에서 차이 없음 SQL은 서브쿼리, 테이블을 같은 것으로 취급 개념정리 테이블 : 영속적
8.Ch.8 SQL 순서 - 깨어나는 절차 지향

SQL 은 순번을 다루기 위한 기능 없음관계 모델 이론 때문테이블 레코드를 순서 없게 정의하지만 순번은 필요한 경우가 많기 때문에 윈도우 함수를 이용해 절차지향의 순번을 활용테이블 스캔 횟수 1회인덱스 온리 스캔 사용하므로 테이블 직접 접근 회피row_number 함수
9.Ch.9 갱신과 데이터 모델
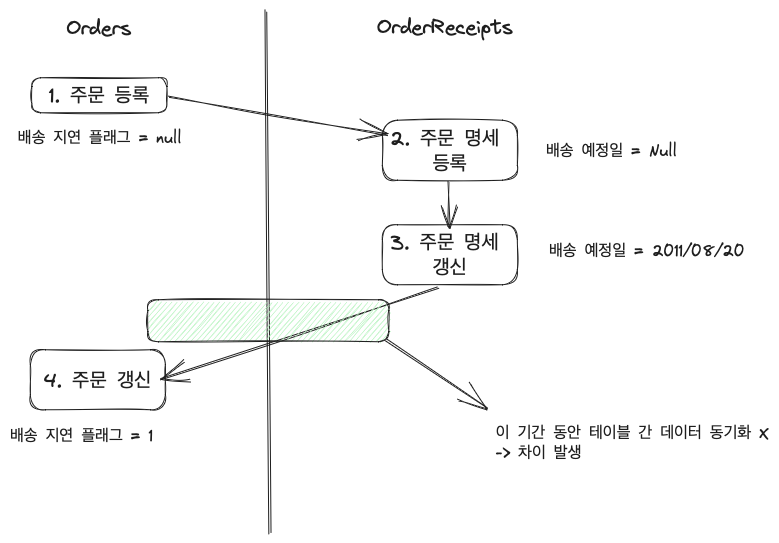
SQL 은 질의. 즉, 검색에 초점이 맞춰진 언어검색에 비해 갱신은 상대적으로 비효율적이고 성능이 떨어지는 경향같은 keycol 필드 가짐현재 레코드보다 작은 seq 필드 가짐val 필드가 NULL이 아님입력 횟수를 줄이고자 null 값을 넣어 생략하는 경우 존재하지만
10.Ch.10 인덱스 사용
데이터를 트리 구조로 저장하는 형태 인덱스뛰어난 범용성균형이 잘 잡혀 있음사실 B+tree를 채택해서 사용트리 리프 노드에만 키 값을 저장B-tree 보다 검색 효율 높은 알고리즘DB, 파일 시스템에서 사용Root ↔ Leaf 거리를 일정하게 유지안정적인 검색 성능데이