[논문스터디] Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
논문스터디

참고자료
Abstract
NeRF는 single ray per pixel(픽셀 당 1개의 ray)를 사용하기 때문에 다른 해상도로 관찰할 때 지나치게 흐릿하거나 aliased(계단현상)이 발생할 수 있다. 그러나 픽셀 당 여러 ray를 사용하여 렌더링 하기 위해서는 각 ray를 렌더릴 할 때 MLP를 수백번 query해야하므로 NeRF에서 실용적이지 않다.
mip-NeRF는 연속적인 값의 척도(continuosly-valued scale)로 scene을 represent할 수 있다.
Aliasing
데이터에 있는 정보를 캡쳐하기에 불충분한 해상도를 갖는 데이터를 샘플링 할 때 원래의 이미지에 대한 정보를 잃어버리는 현상이다. 대표적으로 계단현상이 있다. 해상도를 증가시키면 증가시킬수록 Aliasing현상이 줄어든다.
예를 들어 현재 사용중인 일반 PC의 모니터에 객체를 디스플레이 할 때 객체의 해상도는 96PPI(Pixel Per Inch)이다. 그러나 사람의 눈은 훨씬 높은 해상도를 가지고 있기 때문에 96PPI의 샘플 해상도가 사람의 눈으로 보여질 때 해상도가 낮기 때문에 Aliasing이 일어나게 된다.
[출처] : 지용준, 김명신, 이성태, 김판구, & 이윤배. 컴퓨터 그래픽 이미지에서의 새로운 Anti-Aliasing 알고리즘 설계

mip-NeRF의 특징
mip-NeRF는 rays 대신에 anti-aliased conical frustums(원추형 좌절)을 효율적으로 렌더링하여 부적절한 에일리어징 현상을 줄이고 섬세한 디테일 표현 능력을 대폭 향상시킨다.
NeRF보다 속도가 7% 빠르고 크기가 절반이다. 그리고 NeRF와 비교하여 NeRF에 제공된 데이터셋에서 평균 오류율을 17%, 자체제작한 데이터셋(multiscale variant)에서 오류율을 60%까지 줄였다. 또한 multiscale 데이터셋에서 NeRF보다 22배 빠른 속도를 가진다.
1. Introduction
NeRF와 같은 Neural volumetric representation 방식은 새로운 view에 대한 사실적인 이미지를 렌더링하였지만, 흐림현상과 계단현상에 취약했다. 기존 NeRF방식은 training과 test이미지가 거의 일정한 거리에서 관찰된 장면일 때 잘 작동했지만 training 이미지가 여러 해상도로 관찰된 이미지일 경우, 가까운 곳에서는 지나치게 흐릿하고 먼 곳에서는 에일리어징 아티팩트를 포함하게 되었다. 이를 해결하기 위한 간단한 방식으로 한 픽셀을 렌더링할 때 여러 ray를 사용하면 되지만 굉장한 시간과 자원이 필요하다.
mipmapping approach
이 논문에서는 컴퓨터 그래픽에서 계단현상을 방지하는 기법인 mipmapping approach를 사용하였다.(mipmapping이란?) 이 기법은 pre-filtering이라고도 알려져있다.
mip-NeRF는 NeRF가 연속적인 스케일 공간에 대한 prefiltered radiance field를 동시에 나타낼 수 있도록 확장하였다.
mip-NeRF는 radiance field가 통합되여야하는 영역을 나타내는 3D Gaussian을 입력으로 받는다. (?)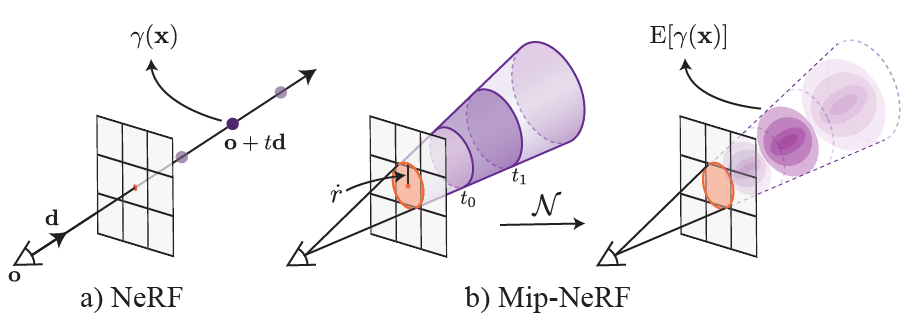
NeRF vs Mip-NeRF
NeRF (a) samples points x along rays that are traced from the camera center of projection through each pixel, then encodes those points with a positional encoding (PE) γ to produce a feature γ(x). Mip-NeRF (b) instead reasons about the 3D conical frustum defined by a camera pixel. These conical frustums are then featurized with our integrated positional encoding (IPE), which works by approximating the frustum with a multivariate Gaussian and then computing the (closed form) integral E[γ(x)] over the positional encodings of the coordinates within the Gaussian.
위의 그림에서와 같이 mip-NeRF는 원뿔을 따라 간격을 두고 쿼리하여 prefiltering된 픽셀을 렌더링 할 수 있다.
새로운 feature representation 방식
3D위치와 그 주변의 Gaussian 영역을 인코딩하기 위해서,
- Integrated Positional Encoding(IPE) :
positional encoding의 일반화로, 공간의 single point가 아니라 공간 영역을 feature화 할 수 있다.

2. Related Work
Anti-aliasing in Rendering

 aliasing artifacts를 줄이는 방법은 주로
aliasing artifacts를 줄이는 방법은 주로 supersampling이나 pre-filtering을 통해 이루어진다.
-
Supersampling-based
렌더링 하는 동안 한 픽셀당 여러 rays를 casting해서 Nyquist frequency에 더 가까운 샘플을 추출한다. 샘플레이트를 높이는 것으로, 수퍼 샘플링은 본래 이미지보다 높은 해상도에서 한 장면을 렌더링하고 사이즈를 줄이는 방법이다. 이러한 방법은 적용하기가 쉬운데 이것은 가속기가 원본보다 고해상도에서 렌더링하고 스케일을 줄이는 것만 하면 되기 때문이다. 이 방법이 많이 사용되지 않는 이유는 화질이 중요한 작업의 경우(즉 16개 이상의 서브 픽셀 방법이 필요한 것과 비슷한 경우) 수퍼 샘플링 방법은 속도는 축적 버퍼 방법에 맞먹으면서 메모리는 서브 픽셀 방법이 필요한 것만큼 요구하기 때문이다. 그런데 대부분 이러한 경우이므로, 수퍼 샘플링은 앤티-앨리어싱에서 가장 쉽기는 하지만 가장 비효율적이다. 그러나 이 방법은 expensive하다.
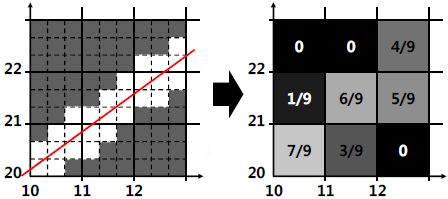
실제보다 더 미세한 격자로 구성되어 있는 것처럼 간주하여 표본화율을 증가시키는 방법
-
Pre-filtered-based
scene 콘텐츠의 lowpass-filterd 버전을 사용하여 aliase없이 렌더링하기 위해 필요한 Nyquist frequency를 줄인다.
이 방식은 real time rendering에 적합하다.(scene 콘텐츠의 filtered버전은 미리 계산이 가능하기 때문)
렌더링 상황에서 prefiltering은 각 픽셀을 통과하는 ray가 아니라 cone을 추적하는 것으로 생각할 수 있다. cone이 scene content와 교차하는 장소에서는 미리 계산된 multiscale representation(e.g. sparse voxel octree | mipmap)이 cone의 footprint에 대응되는 스케일로 조회된다.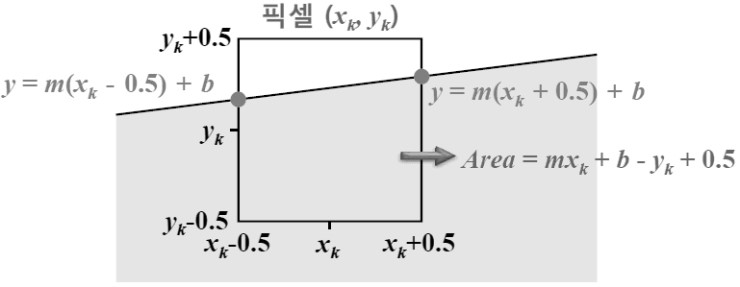
물체가 차지하는 픽셀 면적을 기준으로 픽셀의 밝기를 조절하는 방법. 영역 샘플링(area sampling)이라고도 한다.
 바로 이미지를 다운샘플링하면 위와 같이 aliasing artifacts가 나타난다. 이를 해결하기 위해 아래와 같이 미리 filtering(gaussian blur)을 거치고 다운샘플링을 한다.
바로 이미지를 다운샘플링하면 위와 같이 aliasing artifacts가 나타난다. 이를 해결하기 위해 아래와 같이 미리 filtering(gaussian blur)을 거치고 다운샘플링을 한다.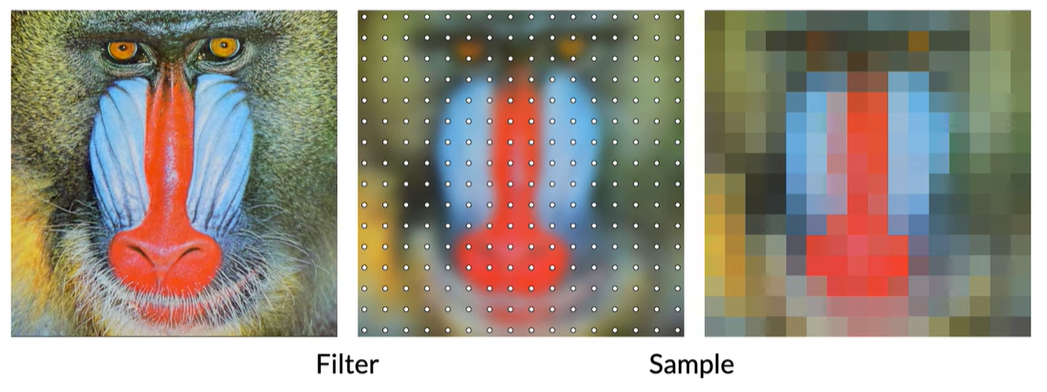
 여러 이미지 사이즈에 항상 빠르게 대응할 수 있도록 미리 여러 사이즈에 대해 filtering한 결과를 나열해 놓고 그것을 바로 사용한다.
여러 이미지 사이즈에 항상 빠르게 대응할 수 있도록 미리 여러 사이즈에 대해 filtering한 결과를 나열해 놓고 그것을 바로 사용한다.
Our work
- 위의 방식과 다르게 multiscale representation을 미리 계산할 수 없다.(scene의 geometry가 알려져있지 않음) 따라서 scene의 prefiltered representation을 training과정에서 학습해야한다.
- (이해 못했음.) Our notion of scale is continuous instead of discrete. Instead of representing the scene using multiple copies at a fixed number of scales (like in a mipmap), mip-NeRF learns a single neural scene model that can be queried at arbitrary scales.
Nyquist frequency
는 sampling period의 절반 이상의 주파수는 측정할 수 없다는 이론입니다. 쉽게 말해 프로세서의 측정 속도에 비해 주파수가 너무 빠른 신호는 해당 프로세서로 측정하기 어렵다는 이야기입니다. 예를 들어 프로세서의 sampling period가 0.001sec 일 때 500Hz 이상의 신호는 측정할 수 없다는 뜻입니다.
3. Method
 NeRF는 객체로부터 동일한 거리에 있는 이미지를 사용하여 scale에 상관이 없지만 만약 위의 그림처럼 객체로부터 다른 거리에 있는 카메라들이 있다면(multi-scale)이라면 NeRF는 매우 안 좋은 성능을 낸다.
NeRF는 객체로부터 동일한 거리에 있는 이미지를 사용하여 scale에 상관이 없지만 만약 위의 그림처럼 객체로부터 다른 거리에 있는 카메라들이 있다면(multi-scale)이라면 NeRF는 매우 안 좋은 성능을 낸다.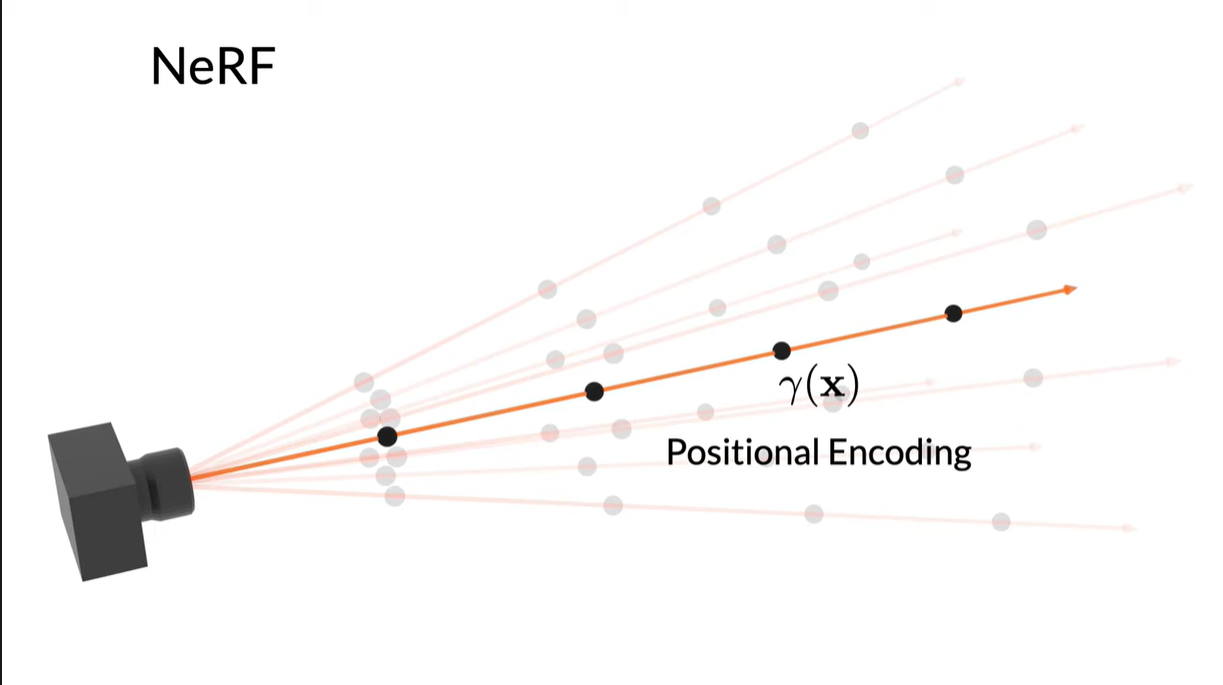 NeRF는 픽셀당 무한히 좁은 단일 광선을 가지고 계산하기 때문에 alias가 발생한다.
NeRF는 픽셀당 무한히 좁은 단일 광선을 가지고 계산하기 때문에 alias가 발생한다.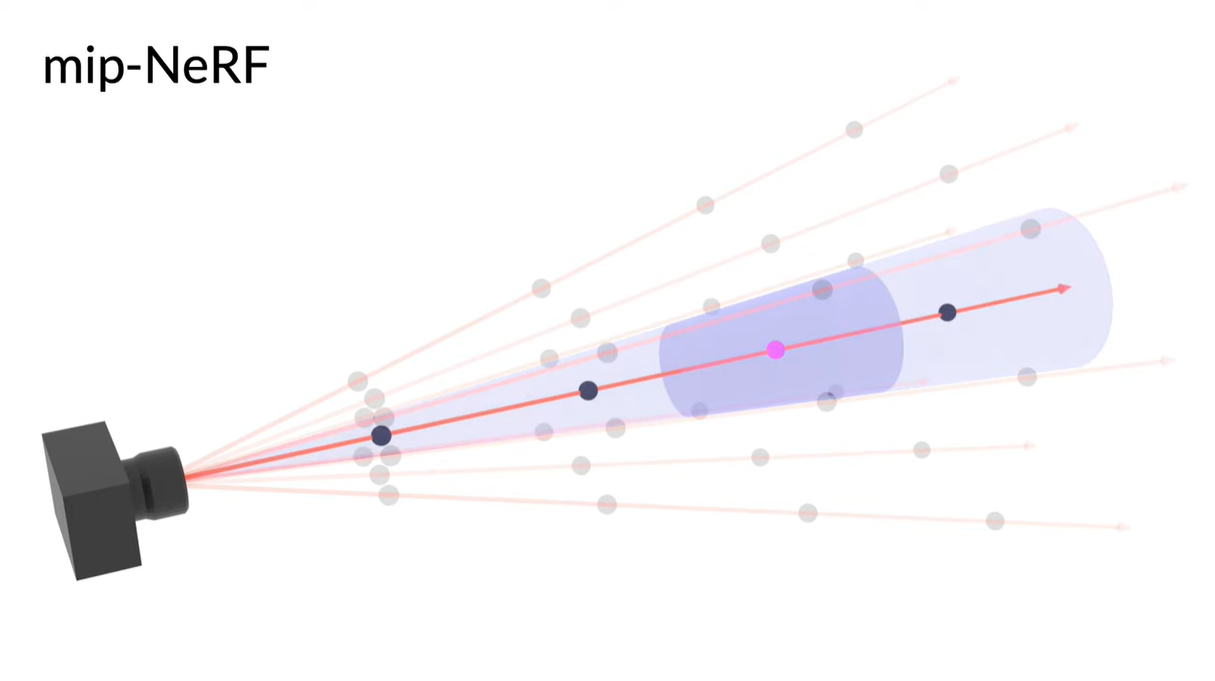 Mip-NeRF는 각 픽셀에서 원뿔모양을 만들어 이 문제를 해결한다.
Mip-NeRF는 각 픽셀에서 원뿔모양을 만들어 이 문제를 해결한다.
Mip-NeRF에서는 각 ray를 따라 point-sampling을 하는 대신에 conical frustums(축과 수직인 면으로 원뿔을 절단함)로 분할한다.(위 그림에서 진한 파란색 공간)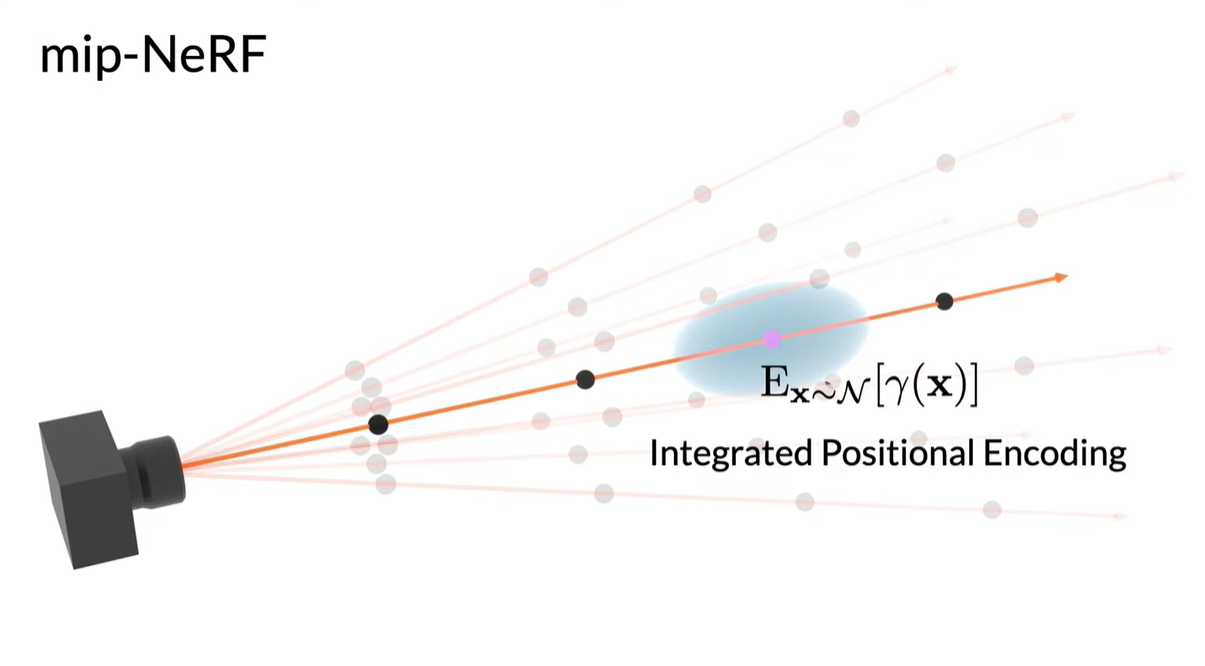 그리고 각 conical frustum으로 덮인 volume에 대해 Multivariate Gaussian을 적용하고 IPE방식을 사용하여 encoding을 진행한다. 이러한 방식으로 MLP는 centroid뿐만 아니라 각 원추형 좌골의 크기와 모양을 추론할 수 있다. 그리고 NeRF의 두개의 분리된
그리고 각 conical frustum으로 덮인 volume에 대해 Multivariate Gaussian을 적용하고 IPE방식을 사용하여 encoding을 진행한다. 이러한 방식으로 MLP는 centroid뿐만 아니라 각 원추형 좌골의 크기와 모양을 추론할 수 있다. 그리고 NeRF의 두개의 분리된 coarse, fine MLP를 한개의 multiscale MLP로 줄일 수 있다.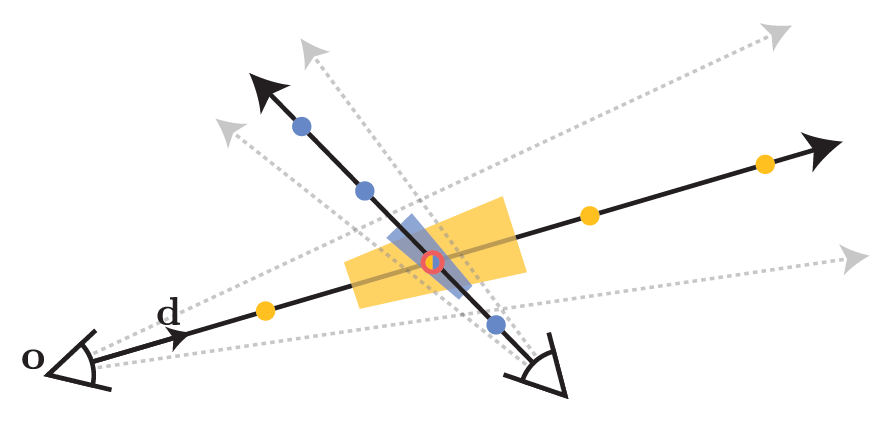
NeRF는 point-sampling을 하기 때문에 각 ray로 보는 볼륨의 모양과 크기를 무시한다. 이때문에 서로 다른 scale로 동일한 위치를 이미징하는 두 다른 카메라에서 동일하게 모호한 point-sampled feature을 생성하여 성능이 크게 저하될 수 있다.
그러나 Mip-NeRF는 ray대신 원뿔을 만들어 각 원추형좌골(그림에서는 사다리꼴)의 부피를 명시적으로 모델링하여 이 모호성을 해결한다.
3.1 Cone Tracing and Positional Encoding
먼저 cone을 캐스팅하고, 그 cone을 따라 conical frustums을 featurize한다. 각 픽셀의 중심을 지나도록하는 카메라의 중심 와 방향 를 중심으로 하는 cone을 캐스팅한다. cone의 꼭짓점은 이고, 에서의 반지름은 이라고 하였다. 두개의 값 사이인 의 conical frustum 내에 있는 위치 의 집합은 아래와 같다.
그리고 이 conical frustum의 volume에 대한 featurized representation을 만들어내기 위해, conical frustum에 있는 모든 좌표의 expected positional encoding을 계산하였다.
그러나 분자에 있는 적분식이 이 문제에 대해 닫혀있지 않으므로 multivariate Gaussian을 통해 conical frustum을 근사한다.
.gif)
기존의 positional encoding
.gif)
Integrated positional encoding
IPE방식은 point가 아니라 Gaussian regions를 사용하여 좌표기반의 neural network에 지역을 input으로 넣어줄 수 있다. 만약 더 넓은 지역을 본다면, higher frequency features는 자동으로 zero를 향해 줄어들어 network에게 lower-frequency inputs를 제공한다. 반대로 좁은 지역에서 이 features는 기존의 positional encoding과 비슷한 features를 제공한다.
Multivariate Gaussian
multivariate gaussian을 통해 conical frustum을 근사하기 위해서 먼저 의 mean과 covariance를 계산해야한다.
위 과정은 논문을 참조하면 된다.
즉, IPE는 일정 간격으로 일정한 frequencies를 유지하고, 간격에 따라 변화하는 frequencies를 부드럽게 제거한다. 반면에 PE는 모든 frequencies를 수동으로 조정되었던 하이퍼파라미터 L까지 유지한다. IPE는 또한, L을 하이퍼파라미터로 사용하지 않는다. 매우 큰 값으로 설정되고 절대로 tuning되지 않는다.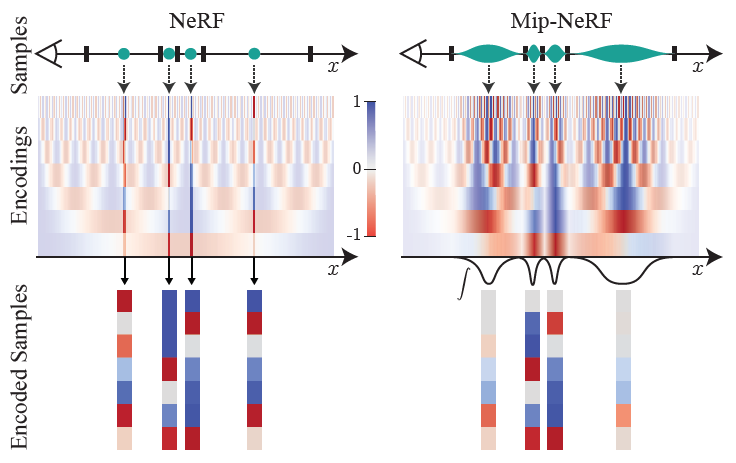
Toy 1D visualizations of the positional encoding (PE) used by NeRF (left) and our integrated positional encoding (IPE) (right). Because NeRF samples points along each ray and encodes all frequencies equally, the highfrequency PE features are aliased, which results in rendering artifacts. By integrating PE features over each interval, the high frequency dimensions of IPE features shrink towards zero when the period of the frequency is small compared to the size of the interval being integrated, resulting in anti-aliased features that implicitly encode the size (and in higher dimensions, the shape) of the interval.
3.2 Architecture
한 픽셀 당 ray 대신에 cone을 캐스팅 하는 것 빼고 NeRF와 거의 비슷하게 작동한다. 그러나 Mip-NeRF는 cone 캐스팅과 IPE features를 사용하여 MLP가 scene의 multiscale representation을 학습할 수 있다. 따라서 parameters 로 된 single MLP만 사용한다.
Optimization problem
coarse samples 는 stratified sampling을 통해 생성되고, fine samples 는 alpha compositing weights 에서 생성된다. NeRF와 다르게 coarse와 fine 둘다 128개의 샘플을 사용한다.
* 참고로 coarse(파라미터 )와 fine(파라미터 ) 두개의 MLP를 사용하던 기존 NeRF는
는 coarse모델에서 생성된 compositing weights
에 의해 생성된다.
4. Results

.gif)
.gif)
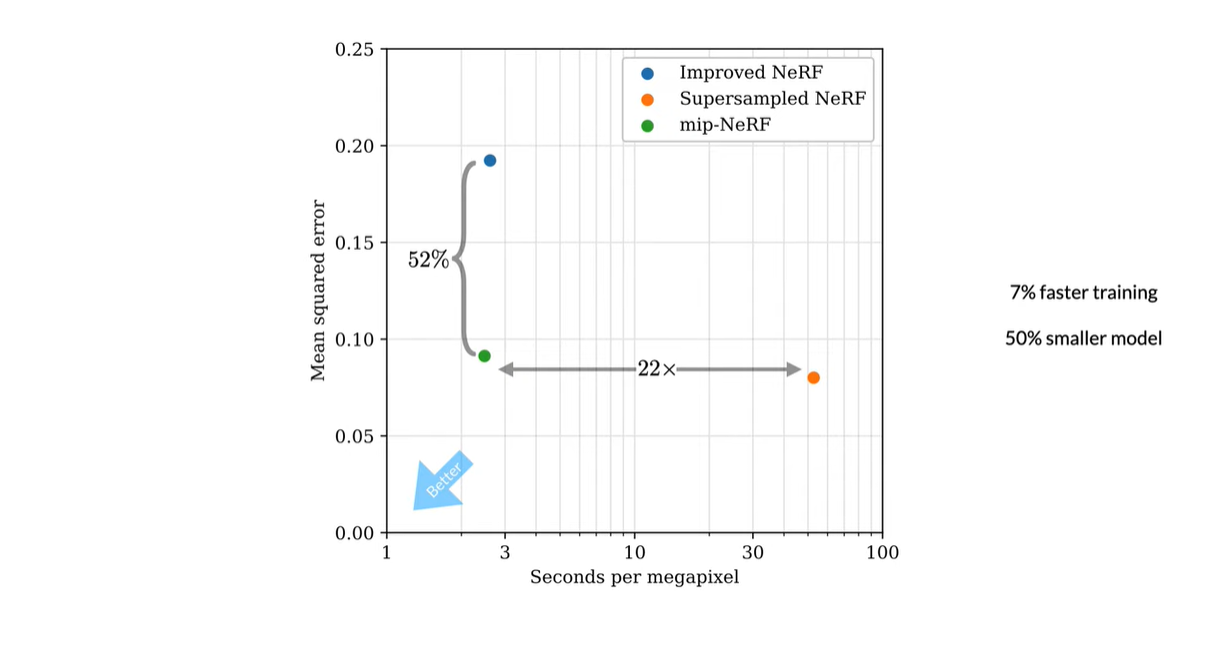 Supersampled NeRF에 비해 22배 빠르게 렌더링한다.
Supersampled NeRF에 비해 22배 빠르게 렌더링한다.

잘 보고 갑니다~