참고 사이트

Abstract
적은 이미지로도 scene representation 성능 향상이 가능한 DietNeRF를 소개한다. 보조 의미 일관성 손실(auxiliary semantic consistency loss)를 도입하여 사실적인 렌더링을 돕는다. 이 loss는 임의의 포즈로부터 DietNeRF를 지도(supervise)할 수 있게 해준다. 미리 학습된 visual encoder(e.g. Vision Transformer CLIP)를 사용하여 이 의미(sementic)을 추출한다.
DietNeRF는 CLIP 비전 트랜스포머를 사용하여 렌더링이 일관된 높은 수준의 의미를 갖도록 하여 NeRF를 임의 포즈로부터 지도(supervise)한다.
- Problem: NeRF is only trained to render observed poses, leading to artifacts when few are available.
- Key insight: Scenes share high-level semantic properties across viewpoints, and pre-trained 2D visual encoders can extract these semantics. "An X is an X from any viewpoint." 어디서 봐도 불도저는 불도저다!
1. Introduction
NeRF는 여전히 장면별로 추정하기 때문에 다른 이미지나 객체로부터 얻은 prior knowledge를 사용하여 이득을 볼 수 없다. prior가 없기 때문에 좋은 퀄리티의 장면을 생성하기 위해서 NeRF는 매우 많은 input views가 필요하다. NeRF는 관찰된 포즈에서만 정확한 솔루션을 찾기 때문에 8개의 views로만 렌더링하면 아티팩트가 많이 생긴다. 즉 only supervised at known poses! 이 때문에 적은 포즈만 주어지면 overfit된다..
NeRF는 관찰된 포즈에서만 정확한 솔루션을 찾기 때문에 8개의 views로만 렌더링하면 아티팩트가 많이 생긴다. 즉 only supervised at known poses! 이 때문에 적은 포즈만 주어지면 overfit된다..
-
Multi-view datasets
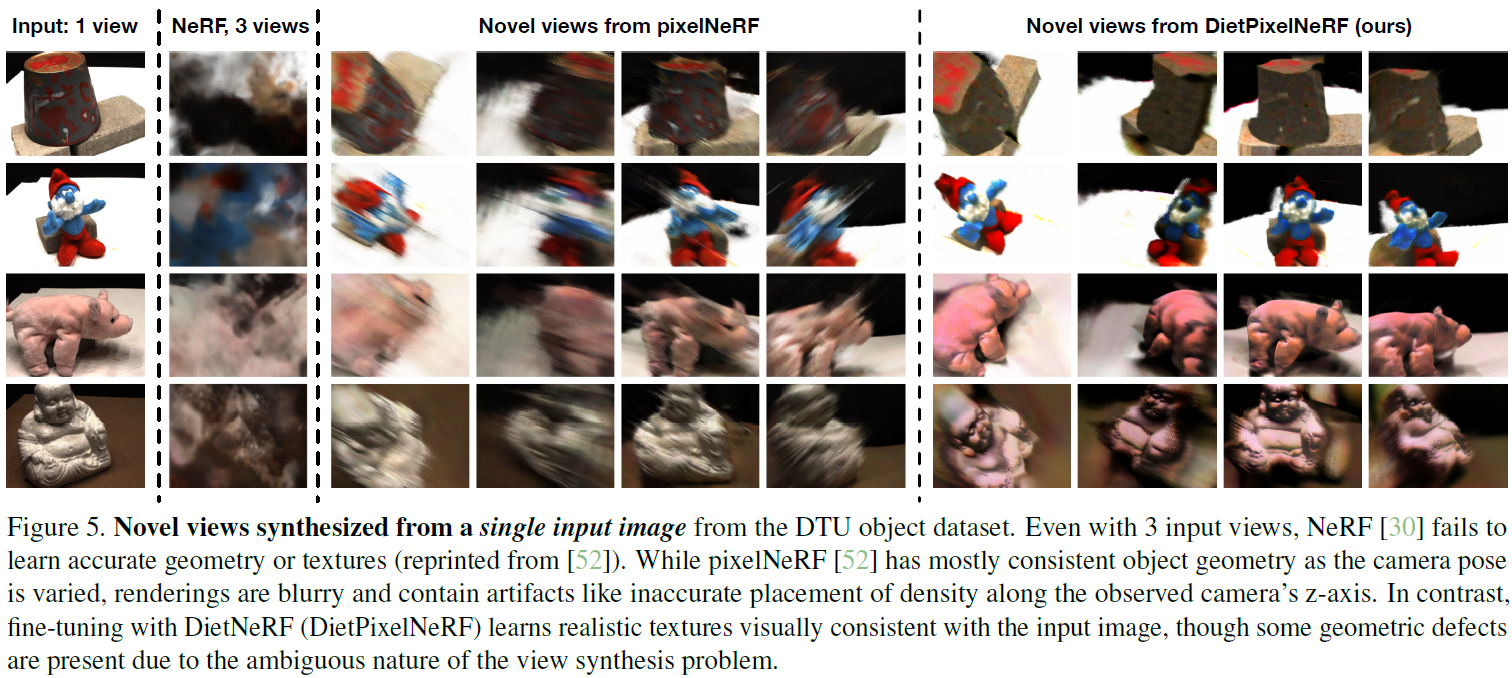
pixel-NeRF와 같은 최근 연구는 새로운 장면의 재생산을 편향하도록 유사한 장면의 multi-view datasets로 NeRF를 train했다. 그러나 이러한 모델은 불확실성으로 인해 흐릿한 이미지를 생성하거나, 크고 다양한 multi-view 데이터를 캡처하기 어렵기 때문에 단일 객체 카테고리에 제한된다. -
볼도저는 어디서 보아도 불도저이다
객체는 views사이에서 서로 의미를 공유한다.
그래서 논문에서는 매우 다양한 2D single-view 이미지 데이터(e.g. ImageNet)에 대해 학습한 prior knowledge를 사용했다.
NeRF의 Loss에 추가적으로 semantic consistency loss를 사용하였다.
2. Background on Neural Radiance Fields
3. NeRF Struggles at Few-Shot View Synthesis
View 합성은 scene이 드문드문 관찰될 때 굉장히 어렵다.
-
NeRF는 training views에 과적합된다.
NeRF는
training image와 pose인 와 같은 pose에서의 이미지 를 렌더링하고, 둘 사이의 MSE를 최소화시킨다.불행하게, NeRF의 high-frequency가 적은 input view만 존재할때, 각 input view에 과적합된다.
-
Regularization은 geometry를 수정하지만, detail을 손상시킨다.
-
Prior knowledge가 없으면, unseen views에 일반화 할 수 없다.
NeRF는 객체에 대한 prior knowledge가 없다.(물체 부분이나, 객체의 대칭성 등)
4. Semantically Consistent Radiance Fields
Diet-NeRF는 pre-trained image encoder로부터 prior knowledge를 얻어와 few-shot에 대한 NeRF의 최적화를 돕는다.
4.1 Semantic consistency loss
DietNeRF는 semantic loss로 학습하는 과정에서 임의의 카메라 포즈에서의 를 supervise한다. 일반적으로, 우리는 다른 viewpoints에서의 재생산된 이미지를 비교할 수 있다.
그러나, ID 매핑은 view에 의존한다. 따라서 같은 객체에 대해 여러 view에서 유사하고, object class와 같이 중요한 높은수준의 의미 속성을 포착하는 표현이 필요하다.
Vision Transformer
ViT는 매우 방대한 2D데이터에 대해 성능이 좋다. 방대한 이미지의 학습을 통해 학습 과정에서 multi-views 데이터 없이 객체 클래스의 multi-views를 볼 수 있다.
ViT는 첫번째 레이어에서 non-overlapping 이미지 패치들로부터 features를 추출하고, global self-attention에 기반한 Transformer blocks로 점점 추상화되는 representations를 합친다. 이를 통해 하나의 global한 임베딩 벡터를 생성한다.
실제로, loss weight 를 사용하여 semantic consistency loss를 구하면,
가 된다. 이는 관찰한 view와 렌더링한 view의 high-level의 의미 features의 유사도를 측정한다.
4.2 Interpreting representations across views
캡션과 함께 있는 이미지들로 학습된 CLIP모델은 하나의 단어 캡션이 아닌 high-level 의미를 갖는 캡션으로 이루어져있다.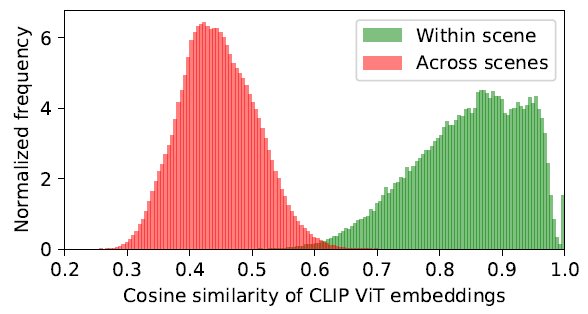 위 그림은 객체 주변 views에서의 CLIP representation들의 pairwise cosine similarity이다.
위 그림은 객체 주변 views에서의 CLIP representation들의 pairwise cosine similarity이다.
4.3 Pose sampling distribution
학습 iteration마다 관찰 데이터셋에서 랜덤샘플링한 학습이미지 와 렌더링한 이미지 사이의를 랜덤 포즈 에 대해 계산한다.
4.4 Improving efficiency and quality
성능향상을 위해 낮은 해상도에서 semantic consistency를 위한 이미지를 렌더링한다.
실험적으로, 가 보다 빠르게 수렴하였다.
5. Experiments