
🔢 NumPy
- 고성능의 수치 계산을 위한 라이브러리
- 장점
- 파이썬 리스트보다 메모리 소모량이 적음
- 파이썬 리스트보다 실행 시간이 빠름
◽ np.ndarray
- N-dimensional Array
- ndarray.shape : 배열의 크기
- ndarray.dtype : 배열 안 요소의 데이터 타입
- ndarray.size : 배열 안의 데이터 수
- ndarray.ndim : 배열의 차원
ex 1 )
# 벡터 (1d)
vector = np.array([1, 2, 3, 4, 5])
print('vector :', vector)
print('vector.shape :', vector.shape)
print('vector.dtype :', vector.dtype)
print('vector.size :', vector.size)
print('vector.ndim :', vector.ndim) vector : [1 2 3 4 5]
vector.shape : (5,)
vector.dtype : int32
vector.size : 5
vector.ndim : 1ex 2)
# 행렬 (2d)
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print('matrix :\n', matrix)
print('matrix.shape :', matrix.shape)
print('matrix.dtype :', matrix.dtype)
print('matrix.size :', matrix.size)
print('matrix.ndim :', matrix.ndim)
print('matrix[0][1] or [0, 1] :', matrix[0][1], matrix[0, 1])matrix :
[[1 2 3]
[4 5 6]
[7 8 9]]
matrix.shape : (3, 3)
matrix.dtype : int32
matrix.size : 9
matrix.ndim : 2
matrix[0][1] or [0, 1] : 2 2◽ 차원
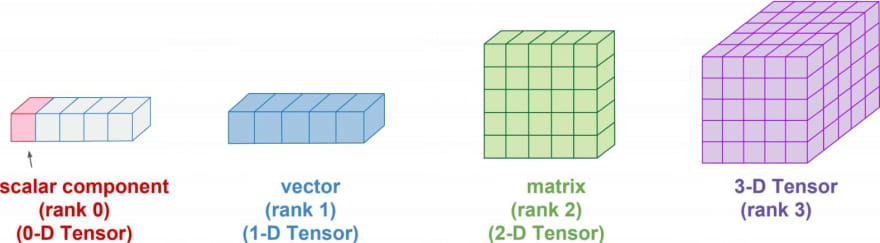
- 0d tensor (0차원) : 스칼라
- 1d tensor (1차원) : 벡터
- 2d tensor (2차원) : 행렬
- 3d tensor (3차원)
🆒 특수한 배열 생성
◽ np.arange()
- array range
- 지정된 간격 내의 균등한 간격으로 배열을 반환
print(np.arange(10))
print(np.arange(5, 10))[0 1 2 3 4 5 6 7 8 9]
[5 6 7 8 9]◽ np.zeros()
- 0으로 채워진 배열 반환
print(np.zeros((1, 2)))[[0. 0.]]◽ np.ones()
- 1로 채워진 배열 반환
print(np.ones((1, 2)))[[1. 1.]]◽ np.full()
- 주어진 값으로 채워진 배열 반환
print(np.full((1, 2), 5))[[5 5]]◽ np.eye()
n x n형태의 단위 행렬 반환
print(np.eye(3)) [[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]◽ np.random.default_rng()
- 난수 생성자
random_number_generator = np.random.default_rng(seed=10)
rand_int = random_number_generator.integers(low=0, high=2, size=2)
rand_float = random_number_generator.random()
print('rng.integers :', rand_int)
print('rng.random :', rand_float)rng.integers : [1 1]
rng.random : 0.20768181007914688➕ 배열 결합
arr1 = np.array([
[1, 1],
[2, 2]
])
arr2 = np.array([
[3, 3],
[4, 4]
])◽ np.vstack()
- vertical stack (세로 결합)
np.vstack((arr1, arr2)) [[1 1]
[2 2]
[3 3]
[4 4]]◽ np.hstack()
- horizontal stack (가로 결합)
np.hstack((arr1, arr2)) [[1 1 3 3]
[2 2 4 4]]💥 차원 확장
arr = np.arange(9)
print(arr)
print('shape :', arr.shape)[0 1 2 3 4 5 6 7 8]
shape : (9,)◽ np.newaxis
ex 1 ) 행 벡터 (행 자리에 np.newaxis)
newaxis = arr[np.newaxis, :]
print(newaxis)
print('shape :', newaxis.shape)[[0 1 2 3 4 5 6 7 8]]
shape : (1, 9)ex 2 ) 열 벡터로 만들기 (열 자리에 np.newaxis)
newaxis = arr[:, np.newaxis]
print(newaxis)
print('shape :', newaxis.shape)[[0]
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]]
shape : (9, 1)◽ np.expand_dims()
ex 1 ) 행 벡터 (axis = 0)
expand_row = np.expand_dims(arr, axis=0)
print(expand_row)
print('shape :', expand_row.shape)[[0 1 2 3 4 5 6 7 8]]
shape : (1, 9)ex 2 ) 열 벡터 (axis = 1)
expand_col = np.expand_dims(arr, axis=1)
print(expand_col)
print('shape :', expand_col.shape)[[0]
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]]
shape : (9, 1)🔄 차원 변형
arr = np.arange(9)
print(arr)
print('shape :', arr.shape)[0 1 2 3 4 5 6 7 8]
shape : (9,)◽ ndarray.resize()
- 지정된 형태로 배열 형태 변형
- 변형된 걸 반환하지 않고 행렬 자체를 변형시킴
arr.resize((3, 3))
print(arr)
print('shape :', arr.shape)[[0 1 2]
[3 4 5]
[6 7 8]]
shape : (3, 3)◽ np.transpose() 또는 ndarray.T
- 해당 행렬의 전치행렬(행과 열을 바꿈) 반환
# 위 3x3 행렬의 전치행렬
transpose = np.transpose(arr)
transpose = arr.T
print(transpose)
print('shape :', transpose.shape)[[0 3 6]
[1 4 7]
[2 5 8]]
shape : (3, 3)◽ ndarray.ravel() 또는 ndarray.flatten()
- n차원 데이터를 1차원으로 변형
flatten = arr.ravel()
flatten = arr.flatten()
print(flatten)
print('shape :', flatten.shape)[0 1 2 3 4 5 6 7 8]
shape : (9,)📚 데이터 타입
- int8 : 1바이트 크기의 부호 있는 정수 (-128 ~ 127)
- uint8 : 1바이트 크기의 부호 없는 정수 (0~255)
- int32 : 4바이트 크기의 정수
- float64 : 8바이트 크기의 실수
◽ ndarray.dtype
- 배열 안 원소의 데이터 타입 반환
arr = np.arange(20)
print('arr 배열의 타입 :', type(arr))
print('arr 배열 안의 원소의 타입 :', arr.dtype)arr 배열의 타입 : <class 'numpy.ndarray'>
arr 배열 안의 원소의 타입 : int32◽ ndarray.astype()
- 배열 안의 요소를 지정한 데이터 타입으로 변형
arr_float32 = arr.astype(np.float32)
print('arr_float32 배열 안의 원소의 타입 :', arr_float32.dtype)arr_float32 배열 안의 원소의 타입 : float32◽ np.iinfo()
- integer info
- 정수형 데이터 타입의 범위
np.iinfo('int32')
# iinfo(min=-2147483648, max=2147483647, dtype=int32)◽ np.finfo()
- float info
- 실수형 데이터 타입의 범위
np.finfo('float32')
# finfo(resolution=1e-06, min=-3.4028235e+38, max=3.4028235e+38, dtype=float32)🧮 배열 조건 연산
arr = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
condition = (arr < 5) # 조건
print(arr)[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]◽ np.any()
- 조건에 하나라도 만족하는 원소가 있으면
True반환
np.any(condition) # True◽ np.all()
- 조건에 모두 만족하면
True반환
np.all(condition) # False◽ np.where()
- 인자를 1개 쓸 경우 : 조건
np.where(condition)(array([0, 0, 0, 0], dtype=int64), array([0, 1, 2, 3], dtype=int64))- 인자를 3개 쓸 경우 : 조건, 참일 경우, 거짓일 경우
np.where(condition, ' 참 ', '거짓')[[' 참 ' ' 참 ' ' 참 ' ' 참 ']
['거짓' '거짓' '거짓' '거짓']
['거짓' '거짓' '거짓' '거짓']]◽ np.clip()
- 인자 : 배열, 최솟값, 최댓값
- 배열의 요소가 최솟값보다 작으면 최솟값으로 변경
- 배열의 요소가 최댓값보다 크면 최댓값으로 변경
np.clip(arr, 5, 8)[[5 5 5 5]
[5 6 7 8]
[8 8 8 8]]◽ 그 외의 조건 확인
np.isinf(): 무한한 값인지 확인np.isnan(): 결측치인지 확인np.isfinite(): 유한한 값인지 확인
😷 마스킹
- bool 배열을 마스크로 사용하여 데이터의 특정 부분 선택 가능
arr = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
# 열의 개수가 같아야 함
mask = [True, False, True]
print(arr[:, mask])[[1 3]
[4 6]
[7 9]]📢 브로드캐스팅
- 배열의 모양이 다르더라도 어떠한 조건을 만족하면 작은 배열을 자동으로 큰 배열의 크기에 맞춤
- 열의 개수가 같아야 함
ex 1 ) 행렬 & 스칼라
big = np.array([
[1, 2, 3],
[10, 20, 30]
])
small = 2
print(big * small)[[ 2 4 6]
[20 40 60]]ex 2 ) 행렬 & 벡터
big = np.array([
[1, 2, 3],
[10, 20, 30]
])
small = np.array([1, 2, 3])
print(big * small)[[ 1 4 9]
[10 40 90]]
울레일라