오늘 리뷰할 논문은 유명한 StyleGAN 논문이다. PGGAN을 바탕으로 Style transfer를 적용해서 style을 scale 별로 조절할 수 있다고 한다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰] StyleGAN: A Style-Based Generator Architecture for GANs
- [GAN 시리즈][StyleGAN] A Style-Based Generator Architecture for Generative Adversarial Networks -1편
- [논문리뷰]StyleGAN : A Style-Based Generator Architecture for Generative Adversarial Networks
Summary
논문은 generated image의 high-level attributes (사람 얼굴을 학습했을 때 pose와 identity 등)와 stochastic variation (주근깨, hair 등)를 unsupervised하게 분리하고 이미지 합성의 intuitive, scale-specific control이 가능하게 하는 대안적인 generator architecture을 소개한다. 새로운 generator은 전통적인 distribution quality metrics의 측면에서 SOTA를 달성하고 더 좋은 interpolation property를 나타내며 variation의 latent factors도 더 잘 disentangle한다. interpolation quality와 disentanglement를 양적으로 평가하기 위해 모든 generator에 적용 가능한 두 개의 새로운 자동화된 방법을 제안한다. 마지막으로 human face의 highly varied, high-quality dataset를 소개한다.
generator은 resolution과 quality가 많이 발전했지만 여전히 image synthesis process와 latent space에 대한 이해가 부족하고 여러 generator 간 latent space interpolations를 비교할 정량적 수단도 존재하지 않는다.
논문은 style transfer 문헌들에 영감을 받아 image synthesis process를 조절하는 generator architecture을 디자인한다. generator은 learned constant input에서 시작해서 latent code에 기반해 각 convolution layer마다 이미지에 style을 조정하여 다양한 scale에서 image strength의 강도를 조절한다. 이는 high-level attributes와 stochastic variation을 automatic, unsupervised separation하고 intuitive scale-specific mixing와 interpolation operations을 가능하게 한다. discriminator와 loss function은 (baseline인 PGGAN에서) 바꾸지 않으며 논문의 work는 GAN loss functions, regularization, hyperparameters에 orthogonal하다.
generator은 input latent code를 intermediate latent space로 embed하며 이는 network 내에서 factors of variation가 어떻게 표현되는지에 중요한 효과가 있다. input latent space는 반드시 training data의 probability density를 따라야 하며 논문은 이것이 어느 정도의 unavoidable entanglement를 야기한다고 주장한다. 논문의 intermediate latent space은 이 제약에서 자유로우므로 disentangle이 허용된다. latent space disentanglement 정도를 측정하는 기존의 방법은 논문의 경우에 적용할 수 없기 때문에 두 새로운 metric인 perceptual path length와 linear separability을 제안한다. 이 metric들을 사용해 전통적인 generator보다 more linear, less entangled representation of different factors of variation을 인정함을 보인다.
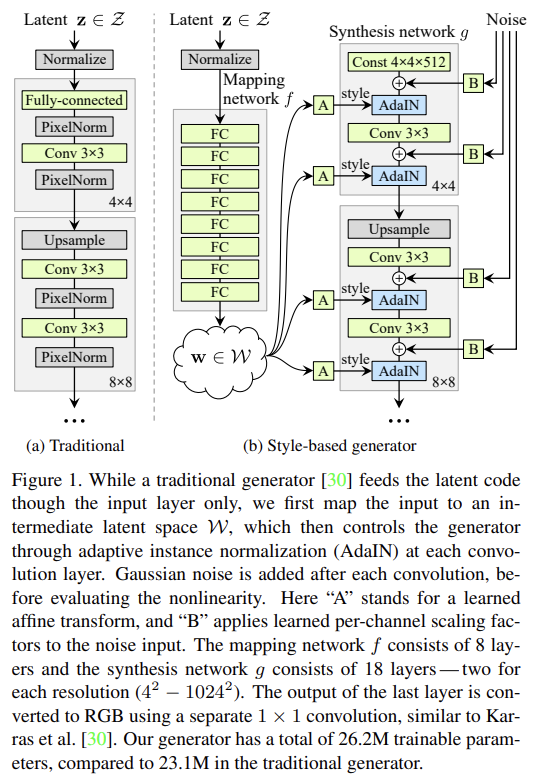
전통적으로 latent code는 input layer을 통해 generator에 제공된다. 논문은 input layer을 생략하고 대신 learned constant에서 시작하는 방식으로 generator 구조를 바꾼다. input latent space Z에 latent code z가 주어졌을 때 non-linear mapping network f : Z → W 는 먼저 w ∈ W 를 생산한다. simplicity를 위해 두 space 모두 dimensionality를 512로 두었고 mapping f는 8-layer MLP로 구현됐다.
style transfer와 비교했을 때 논문의 방식은 spatially invariant style y를 exmample image가 아니라 vector w에서부터 계산한다. Learned affine transformations는 w를 styles y = ()로 specialize한다. style y는 generator의 각 convolution layer 이후 나오는 adaptive instance normalization (AdaIN) operations을 조절한다.
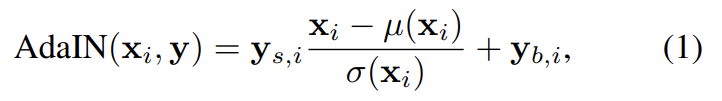
각 feature map 는 따로 normalize되며 style y에서 온 상응하는 scalar component를 사용해서 scale, bias 된다. 따라서 y의 dimensionality는 그 layer의 feature maps 수의 2배가 된다.
그리고 명시적인 noise inputs을 도입함으로써 stochastic detail을 생성할 직접적인 수단을 제공한다. inputs는 uncorrelated Gaussian noise로 이루어진 single-channel images이며 네트워크의 각 층에 dedicated noise image를 먹인다. noise image는 learned per-feature scaling factors를 사용해 모든 feature map에 broadcast되고 상응하는 convolution의 output에 더해진다.
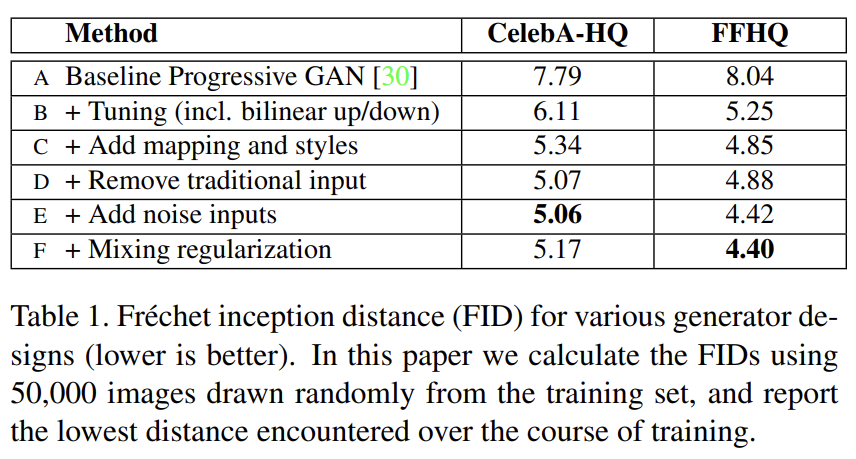
이 디자인은 image quality를 타협하는 게 아니라 상당히 향상시킨다. (중략)
논문의 generator은 style에 scale-specific modifications를 통해 image synthesis를 조절할 수 있다. mapping network와 affine transformations은 learned distribution에서부터 각 style을 그리는 방법으로 볼 수 있으며 synthesis network는 style의 집합으로 새로운 이미지를 생성하는 방법으로 볼 수 있다. 각 style의 효과가 network에 localize되어있는 것이다. 즉, styles의 특정 부분집합을 수정하는 것은 이미지의 그 특정 aspect에만 영향을 끼칠 것을 기대할 수 있다.
localization에 대한 근거는 AdaIN에 있으며, 각 channel을 먼저 zero mean, unit variance로 normalize한 후 style에 기반해 scale, bias한다. style로 인해 유도된 새로운 per-channel statistics는 뒤이을 convolution layer을 위한 features의 상대적 중요도를 수정하지만 normalization 덕분에 기존의 statistics에 의존하지 않는다. 따라서 각 style이 (다음 AdaIN operation에 덮어씌이기 전에) 오직 하나의 convolution만을 조절한다.
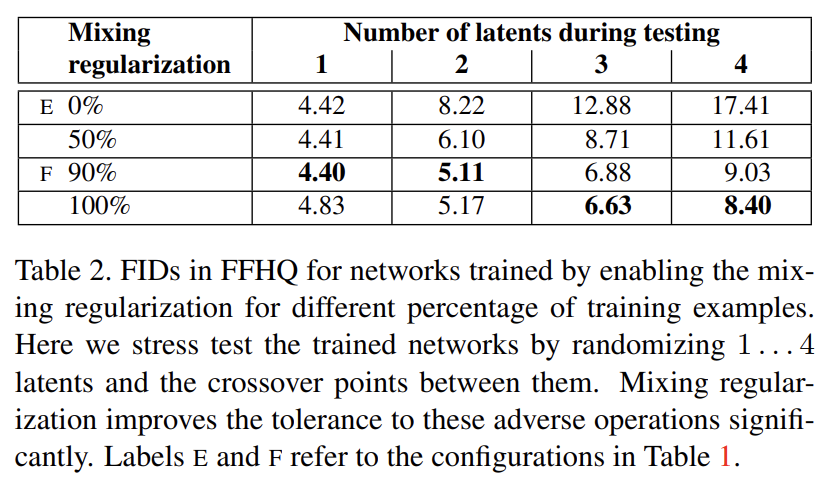
style의 localize을 더 격려하기 위해 "mixing regularization"을 사용한다. 이는 학습 도중 주어진 퍼센티지의 이미지가 (하나의 latent code가 아니라) 두 개의 random latent codes를 사용해 생성되는 것이다. 그런 image를 생성할 때는 syntehsis network의 랜덤하게 고른 지점에서 단순히 한 latent code에서 다른 latent code로 switch한다(이 operation을 style mixing라고 부른다). 다시 말해 두 latent code z1, z2와 상응하는 w1, w2를 가져 crossover point 이전에는 w1를 사용하고 이후부턴 w2를 사용해 style을 조절한다는 것이다. 이 regularization technique은 network가 인접한 style들이 상관관계가 있다는 가정을 못하게 방지한다.
Tab 2가 (test에서 여러 latent를 사용할 때 향상된 FID를 통해) training 중 mixing regularization이 localization을 상당히 향상시킴을 보여준다. Fig 3는 여러 scale에서 두 latent code를 사용해 이미지를 합성한 결과다. styles의 각 부분집합이 의미있는 high-level attributes를 조절함을 볼 수 있다.

human portrait에는 hair 위치, stubble, freckles, skin pores처럼 stochastic하다고 간주할 수 있는 측면이 많다. 이는 그들이 올바른 distribution을 따르는 한 우리의 perception에 영향을 끼치지 않고 randomize될 수 있다. 전통적인 GAN은 stochastic variation을 얻으려면 초기 activation에서 spatially-varying pseudorandom numbers를 생성해야 했다. 그러나 이는 network capacity를 소모하며 생성된 signal(=image)의 규칙성(periodicity)을 숨기기도 어렵다. 즉, generated image에서 반복적인 패턴이 자주 보인다는 것이다. 논문의 architecture은 각 convolution 이후마다 per-pixel noise를 더하는 방식으로 이 문제를 우회한다.

Fig 4는 같은 underlying image에 대해 한 generator가 서로 다른 noise realization을 사용한 stochastic realization을 보여준다. noise가 전체적인 구성과 identity intact 같은 high-level aspect는 보존하면서 stochastic aspect만 영향줌을 확인할 수 있다.

Fig 5는 서로 다른 subsets of layers에 stochastic variation을 적용한 결과다.
흥미로운 점은 noise의 효과가 network 내에서 단단히 localize되어있다는 점이다. 논문은 generator의 어떠한 지점에서든 새로운 content를 가능한 빨리 도입하려는 압력이 존재한다고 가설을 세웠다. StyleGAN이 stochastic variation를 만드는 가장 쉬운(그리고 빠른) 방법이 제공된 noise에 기반하는 것이라는 의미다. 모든 층마다 신선한 noise가 주어지니 stochastic variation을 초기 activation에서 생성할 필요가 없으므로 localize 효과가 나타나는 것이다.
style의 변화는 global effect가 있지만 noise는 오직 inconsequential stochastic variation만을 변화시킨다. 이는 spatially invariant statistics (Gram matrix, channel-wise mean, variance, etc.)가 이미지의 style을 encode하고 spatially varying features가 specific instance를 encode하는 기존의 style transfer literature와 같은 결에 있다.
논문의 style-based generator에서 style은 이미지 전체에 영향을 주는데 전체(complete) feature maps가 같은 값으로 scale되고 bias되기 때문이다. 반면 noise는 각 pixel에 독립적으로 더해지므로 stochastic variation을 조절하는 데 적합하다.
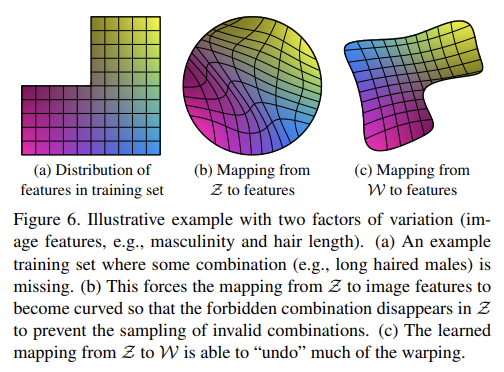
이제 disentanglement에 대해 알아보자. 보통 disentanglement의 목표는 각각 하나의 factors of variation을 조절하는 linear subspaces로 이루어진 latent space를 만드는 것이다. 그러나 Z 내 각 factors의 각 조합의 probability를 sampling하는 일은 training data에서 상응하는 density를 match해야한다. 이는 typical datasets와 input latent distributions이 factors와 완전히 disentangle되는 것을 불가능하게 한다.
논문의 generator architecture의 주요 장점은 intermediate latent space W가 어떤 fixed distribution에 따라 sampling하지 않아도 된다는 것이다. sampling density는 learned piecewise continuous mapping f(z)에 의해 유도된다. (다시 말해 input vector z로부터 직접 distribution을 맞추고 이미지를 생성하는 게 아니라 mapping network를 거쳐 intermediate vector W로 먼저 변환한 후 이미지를 생성하기 때문에 distribution은 f가 맞춰주면 된다) 이런 mapping은 W를 "unwarp"해서 factors of variation이 더 linear해진다. (Fig 6a의 고정된 input distribution을 Z에서 직접 변환하면 b처럼 entangle되어있고 nonlinear한데 논문의 방식은 c처럼 disentangle되어있고 linear하다) 논문은 generator에 그렇게 하는 압력이 존재하여 representation들이 entangle되어있을 때보다 더 쉽게 realistic image를 생성할 수 있다고 주장한다.
그러나 disentanglement를 정량적으로 평가하는 기존의 metric은 input image를 latent code로 map하는 encoder가 필요하다. 그러나 논문의 baseline GAN은 encoder가 없기 때문에 이 metric을 사용할 수 없다. 그래서 논문은 encoder나 known factors of variation를 필요로 하지 않는, 어떤 dataset이나 generator에도 계산 가능한 두 metric을 제안한다.
- Perceptual path length
latent-space vectors의 interpolation은 이미지에 non-linear 변화를 일으킬 수 있다. 예를 들어 양 endpoint에 존재하지 않는 feature가 interpolation 중간에 튀어나올 수도 있다. 이는 latent space가 entangle되어있다는 신호다. 이 효과를 quantify하기 위해 이미지가 interpolation 도중 얼마나 급격한 변화를 겪는지 측정할 수 있다. 직관적으로 less curved latent space가 highly curved latent space보다 smoother transition을 보여야 한다.
metric의 근원으로 두 VGG16 embeddings 사이 weighted difference로 계산되는 perceptually-based pairwise image distance를 사용하며 human perceptual similarity judgments에 metric이 동의하도록 weight가 fit되어있다. image difference metric에 보고된 바와 같이 latent space interpolation path를 linear segments로 구분하면 각 segment의 perceptual differences의 합으로 이 segmented path의 전체 perceptual length를 계산할 수 있다. perceptual path length의 정의는 무한히 미세한 subdivision의 합의 극한이겠지만 실제로는 small subdivision epsilon 를 사용한다. latent space Z에서 모든 가능한 endpoint에 대한 average perceptual path length는 다음과 같다.
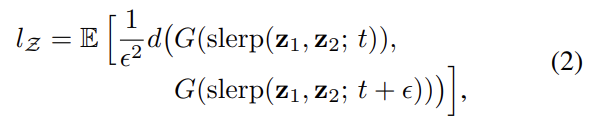
, G는 generator, d는 resulting image 간 perceptual distance이다. slerp는 spherical interpolation이다. background 대신 facial features에 집중하기 위해 생성된 이미지가 face만을 가지도록 crop한 후 pairwise image metric을 평가한다. metric d가 quatratic하기 때문에 로 나눈다. 기댓값은 100,000 samples로 구한다.
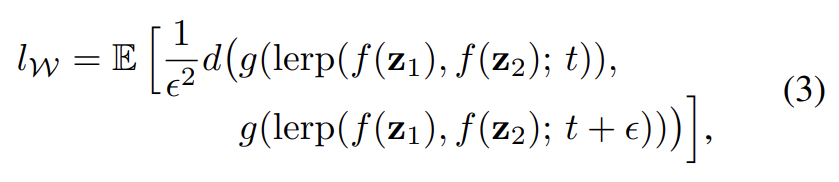
W 내의 average perceptual path length도 비슷하게 구한다. 유일한 차이는 interpolation이 W space에서 발생한다는 것이다. W가 normalize되어있지 않으므로 linear interpolation(lerp)를 사용한다.
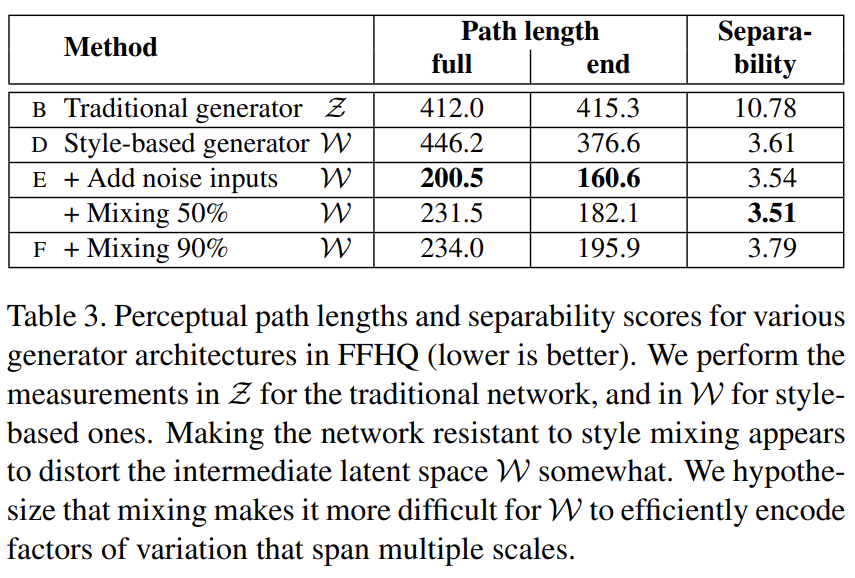
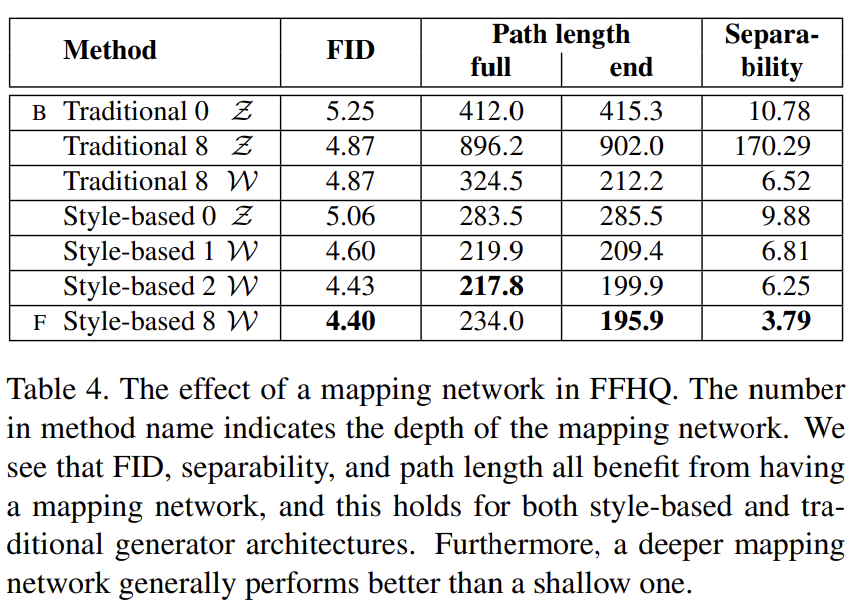
(Tab 3, 4 설명 생략)
- Linear separability
latent space가 충분히 disentangle되어 있다면 개별 factors of variation에 해당하는 direction vector을 찾을 수 있어야 한다. 논문은 latent-space points가 linear hyperplane을 통해 얼마나 잘 두 집합으로 구분될 수 있는지(각 집합은 이미지의 특정 binary attribute에 상응한다) 측정하는 metric을 제안한다.
우선 생성된 이미지에 label을 붙이기 위해서 여러 binary attributes를 구분하는 auxiliary classification network를 학습시킨다. classifier은 discriminator와 같은 architecture을 사용했고 40개의 attributes를 가진 CELEBA-HQ dataset로 학습시켰다.
각 attribute에 대해 linear SVM을 fit시켜 latent-space point에 기반해 label을 예측하고 이 plane으로 point를 분류하게 했다. 그리고 SVM으로 예측한 class를 X, pre-trained classifier로 결정한 class를 Y라 할 때 conditional entropy H(Y |X)를 계산했다. 이는 sample이 hyperplane의 어떤 쪽에 위치하는지 알 때 sample의 true class를 결정하려면 얼마나 추가 정보가 필요한지를 나타낸다. 값이 작을수록 상응하는 factor(s) of variation에 대해 latent space가 일관적임을 의미한다.
final separability score를 로 계산하며 i는 40 attributes를 enumerate한다. inception score처럼 여기서도 exponentation이 값을 logarithmic에서 linear domain으로 가져와 비교하기 쉽게 만든다. (Tab 3, 4 설명 생략)
Strengths
- 아이디어가 몹시 참신하고 뛰어났다. z를 바로 변환하는 게 아니라 w와 mapping을 거쳐 여러 layer에 broadcast함으로써 style을 scale별로 조절하고, 미세한 variation은 noise를 여러 층에 먹임으로써 얻을 수 있었다. 또 층별로 style을 구분해 적용하는 기법을 통해 disentanglement도 이룰 수 있었다.
- disentanglement를 정량화하는 두 가지 기법을 제안했다.
Weaknesses
- linear separability metric의 경우 범용적으로 사용하기 힘들 것 같다. pre-trained classifier를 CELEBA-HQ dataset라는 특정 데이터셋에 학습시켰기 때문에 다른 데이터셋을 사용하는 연구와는 점수를 비교할 수 없다.
