오늘 리뷰할 논문은 PGGAN 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- PGGAN 개인정리(논문 리뷰 Progressive Growing of GANs for Improved Quality, Stability, an
- [DL - 논문 리뷰] Progressive Growing of GANs for Improved Quality, Stability, and Variation (PGGAN)
Summary
논문은 GAN을 학습하는 새로운 방법론을 제시한다. 핵심 아이디어는 G와 D를 낮은 resolution에서 시작해서 점진적으로 layers를 추가하며 해상도를 높이는 것이다. 이는 학습 속도도 늘려주고 안정성도 높인다. (기존 GAN은 고해상도 이미지 생성이 어려웠는데, 해상도가 낮으면 G가 D를 속이기 쉽지만 해상도가 높을수록 D를 속이기 어렵기 때문이다. 그래서 PGGAN은 낮은 해상도부터 학습하고 점차 높은 해상도를 학습한다.) 또 생성된 이미지의 variation을 높이는 방법을 제안하여 CIFAR 10 데이터셋에서 record inception score of 8.80을 얻었다. 추가로 G와 D 사이 불건전한 경쟁을 줄이는 몇 implementation detail을 설명한다. 마지막으로 image quality와 variation의 관점에서 GAN의 결과를 평가할 수 있는 새로운 metric을 제안한다.
GAN에서 training distribution와 generated distribution의 거리를 측정할 때 두 distribution이 상당한 공통부분(overlap)이 없다면 gradient가 랜덤한 방향을 가리키게 되는데, 즉 두 분포가 떨어져있다고 말하기는 너무 쉽다는 것이다(too easy to tell apart). 기존엔 distance metric으로 Jensen-Shannon divergence이 사용됐는데 least squares, Wasserstein distance 등 다른 metric도 제안됐다. 논문의 성과는 distance metric과 독립적이며(orthogonal) improved Wasserstein loss와 least-squares loss로 실험한다.
high-resolution image를 생성하는 것은 어려운데 생성된 이미지가 training image와 많이 떨어져 있어 gradient problem을 심화하기 때문이다. 또 이미지가 클수록 메모리 제약으로 인해 minibatch 크기도 작아져 학습 안정성이 떨어진다. 그래서 논문은 G와 D 모두 작은 resolution에서 시작해서 higher-resolution details을 도입하기 위한 layer을 추가한다.
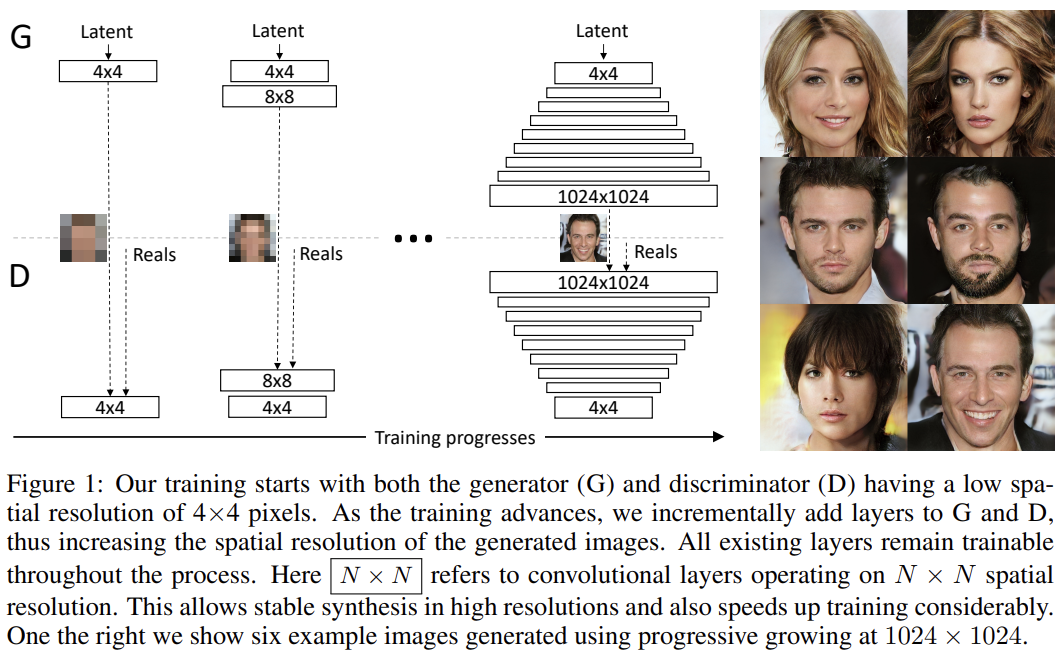
resolution을 점진적으로 키우는 방법은 모든 scale을 동시에 배우는 게 아니라 처음에는 image distribution의 large-scale structure을 발견하고 관심을 increasingly finer scale detail로 옮길 수 있게 한다.
G와 D network는 서로의 거울상(mirror images)을 사용하고 대칭적으로 자라게 했다. 두 network의 모든 layer은 trainable하며 새로운 layer가 network에 추가되면 Fig 2처럼 smooth하게 fade in했다. 이는 already well-trained, smaller-resolution layers에 대한 갑작스러운 충격을 피하게 한다.
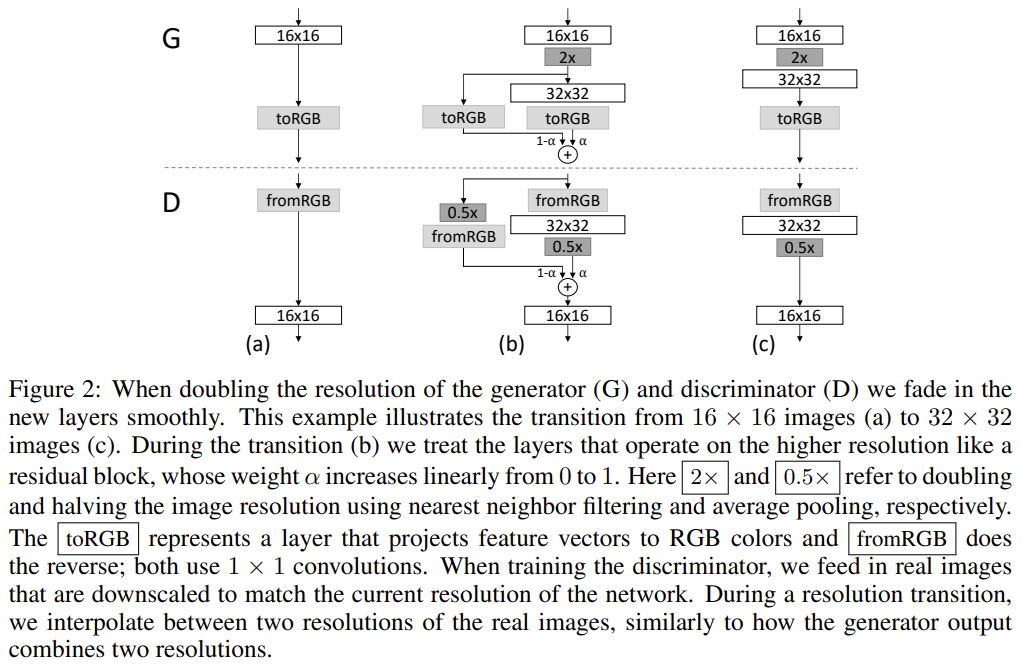
progressive training은 몇 가지 장점이 있다. 우선 초기에 작은 이미지 생성이 더 안정적인데, class information과 modes가 적기 때문이다. 또 감소된 학습 속도도 장점이다.
이제 MINIBATCH STANDARD DEVIATION를 사용해서 variation을 증가시키는 법을 알아보자. GAN은 training data에서 subset of the variation만 포착하는 경향이 있는데 Salimans et al.은 “minibatch discrimination”을 해결책으로 제시한다. feature statistics를 개별 이미지 뿐만이 아니라 minibatch에서도 계산하여 generated/training image minibatch의 statistics가 비슷하게 부추기는 것이다. 이는 D의 마지막에 minibatch layer을 붙이는 식으로 구현되며, 여기서 layer은 input activation을 statistics의 array로 project하는 큰 tensor을 학습한다. minibatch 내의 각 example에 대해 separate set of statistics이 생성되며 D가 내부적으로 statistics를 사용할 수 있도록 layer의 output에 concatenate된다. 논문은 이 방식을 간략화하여 사용하며 동시에 variation도 향상시킨다.
논문의 간략화한 방식은 learnable parameters나 hyperparameters가 필요하지 않다. 우선 minibatch 상에서 각 spatial location 내의 각 feature의 standard deviation을 계산한다. 그리고 모든 feature와 spatial location에서 평균을 내 하나의 값을 낸다. 이 값을 모든 spatial location으로 복사해서 concatenate하여 one additional (constant) feature map를 산출한다. 이 layer은 D의 어디에나 삽입될 수 있지만 끝에 붙이는 게 가장 성능이 좋았다.
GAN은 G와 D의 unhealthy competition로 인해 signal magnitude의 증가에 취약하다. 이 문제를 다루기 위한 초기 방법은 batch normalization의 변형을 G에 (종종 D에도) 적용하는 것이다. 이 normalization 방법은 본래 covariate shift를 제거하기 위해 도입된 것이다. 그러나 논문은 covariate shift를 문제라고 보지 않았고, signal magnitude와 competition을 제약하는 것이 실제 문제라고 보았다. 논문은 (어느쪽도 learnable parameter을 가지지 않는) 두 요소로 이루어진 방법을 제안한다.
첫째는 EQUALIZED LEARNING RATE이다. careful weight initialization라는 현재 트렌드에서 벗어나 논문은 trivial N (0, 1) initialization을 하며 runtime에 명시적으로 weight을 scale한다. 로 세팅했으며 는 weight, c는 He's initializer에서 온 per-layer normalization constant이다. initialization 중이 아니라 dynamically 이렇게 하는 이점은 subtle하며, 흔히 사용되는 RMSProps나 Adam 같은 adaptive stochastic gradient descent methods의 scale-invariance와 관련된다. 이 방법들은 gradient update를 estimated standard deviation으로 normalize하여 update를 parameter의 scale과 무관(independent)하게 만든다. 결과적으로 어떤 parameter가 남들보다 larger dynamic range를 가진다면 adjust하는데 오래 걸릴 것이다. 이것이 요즘 initializer들의 문제이며 따라서 learning rate가 동시에 너무 크면서 너무 작을 수 있다. 논문의 방법은 dynamic range가 (따라서 learning speed도) 모든 weights에서 동일할 것을 보장한다.
둘째로 competition의 결과로 G와 D의 magnitude가 통제불능이 되는 것을 막기 위해 G에서 각 convolutional layer 이후에 각 픽셀의 feature vector를 unit length로 normalize한다. 이는 variant of “local response normalization” (Krizhevsky et al., 2012)를 사용하는 것인데, 다음과 같이 설정된다.
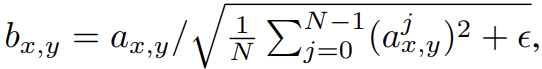
, N은 feature maps의 수, 는 pixel (x, y)에서 original/normalized feature vector이다. 놀랍게도 heavy-handed constraint는 G에 나쁜 영향을 끼치지 않았고 대부분 데이터셋에서 결과를 많이 바꾸지 않았으며 필요한 경우 signal magnitude의 증가를 방지했다.
논문은 GAN을 평가하기 위한 metric도 제시한다. 성공적인 generator라면 생성된 sample이 training set과 모든 scale에서 local image structure이 비슷할 것이라는 직관에 바탕을 둔다. low-pass resolution (16 × 16 pixels)부터 시작해서 generated/target image의 Laplacian pyramid (Burt & Adelson, 1987) representations에서 얻은 local image patches의 distribution 간 multi-scale statistical similarity를 고려한다. pyramid는 full resolution에 도달할 때까지 점진적으로 2배가 되며 연속적인 각 level이 이전 level의 up-sampled version와 차이를 encode한다.
single Laplacian pyramid level은 특정 spatial frequency band에 상응한다. 랜덤하게 16384 image를 sample하고 Laplacian pyramid의 각 level에서 128 descriptors를 추출하여 level당 (2.1M) descriptors을 얻는다. 각 descriptor은 3 color channels을 가진 7 × 7 pixel neighborhood이며 로 표기한다. training set과 generated set의 level l에서 온 patches를 로 표기한다. 우선 각 color channel의 mean과 standard deviation으로 을 normalize하고 그들의 sliced Wasserstein distance SWD()를 계산하는 것으로 statistical similarity를 추정한다. sliced Wasserstein distance는 512 projections를 사용해 효율적으로 계산가능한 earthmovers distance의 randomized approximation이다.
작은 Wasserstein distance는 patches의 distribution이 비슷하다는 뜻이며 이 spatial resolution에서 training images와 generated samples이 appearance와 variation이 비슷하다는 것을 의미한다. 특히 lowest-resolution 16 × 16 images에서 추출한 patch sets 사이 거리는 large-scale image structures에서 similarity를 의미하며 finest-level patch는 edge의 shaprness나 noise처럼 pixel-level attributes에 대한 정보를 encode한다.
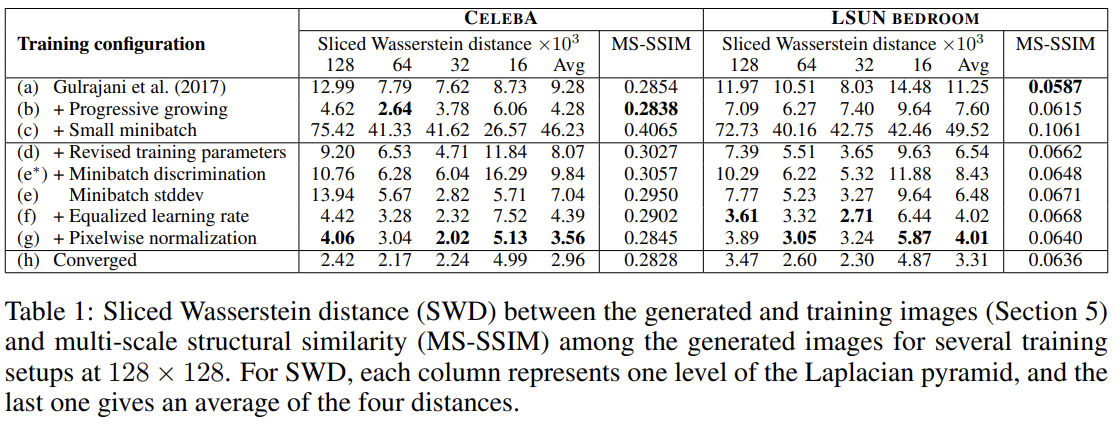

실험은 논문의 각 contribution을 평가하고 SWD의 유효성을 입증하기 위해 sliced Wasserstein distance (SWD)와 multi-scale structural similarity (MS-SSIM)를 사용한다. 이전 state-of-theart loss function (WGAN-GP)과 training configuration (Gulrajani et al., 2017)을 unsupervised setting에서 사용하고 resolution에서 CELEBA, LSUN BEDROOM datasets를 사용한다. Table 1은 여러 training configuration에서 SWD와 MS-SSIM을 계산한 것이다. 직관적으로 좋은 metric이라면 colors, textures, viewpoints에서 variation을 보이는 image를 reward해야 한다. 그러나 MS-SSIM은 이를 잘 포착하지 못한다. configuration (h)에서 (a)보다 더 좋은 이미지를 생성하는데 MS-SSIM은 output 간 variation만 측정하고 training set과의 유사도는 측정하지 않기 때문에 두 configuration에서 수치가 거의 똑같다. 반면 SWD는 확실한 improvement를 보인다.
또 (a)와 비교해 progressive growing을 허용한 (b)는 sharper, believable output image를 만들며 SWD가 training set과 generated image의 distribution이 비슷하단 것을 올바르게 포착한다.
논문의 목표는 high resolution output을 만드는 것이었고 이는 메모리 제한으로 인해 minibatch 크기를 줄일 것을 요구한다. (c)는 minibatch 크기를 64에서 16으로 줄였고 이로 인해 생성한 이미지는 두 metric 모두 비현실적이라고 말한다. (d)에선 hyperparameters을 조정하고 batch normalization과 layer normalization을 제거하는 것으로 training process를 안정시킨다. 논문의 minibatch standard deviation (e) 는 average SWD scores를 향상시킨다.
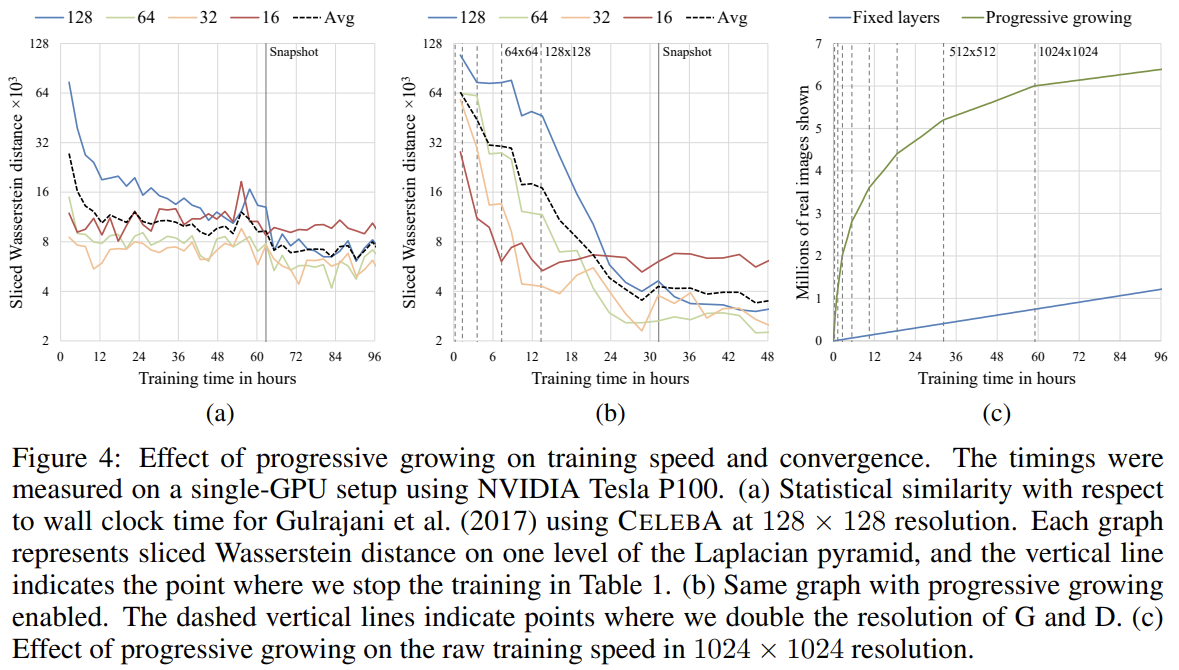
Fig 4는 SWD metric과 raw image throughput의 관점에서 progressive growing의 효과를 보여준다. 첫 두 그래프는 Gulrajani et al.의 configuration에서 progressive growing이 없을 때와 있을 때에 해당한다. 여기서 두 이점을 볼 수 있는데, 더 좋은 optimum에 도달한다는 것과 total training time이 2배 짧다는 것이다. 향상된 수렴 정확도는 점진적으로 증가한 network capacity로 설명할 수 있으며, existing low-resolution layers가 이미 수렴했기 때문에 새 layer가 추가되더라도 representation을 increasingly smaller-scale effects로 정제할 수 있으므로 속도도 빠르다.

high resolution output을 생성하기 위해선 sufficiently varied high-quality dataset가 필요하다. 그래서 논문은 (30000장의 1024 × 1024 resolution 이미지를 가진) CELEBA의 high-quality version을 만들어 실험한다.


그 외에도 LSUN과 CIFAR 10 데이터셋에도 실험한다. 설명은 생략한다.
Strengths
- 점진적으로 resolution을 상승시키는 참신한 방법을 통해 high resolution에서 학습이 안정적이었고 좋은 결과를 얻었다.
- GAN의 양적 평가가 가능한 새로운 metric을 소개했다. (그런데 PGGAN 말고 다른 GAN에서는 못 쓸 것 같기는 하다)
